Complete Features
These features were completed when this image was assembled
Currently the Get started with on-premise host inventory quickstart gets delivered in the Core console. If we are going to keep it here we need to add the MCE or ACM operator as a prerequisite, otherwise it's very confusing.
Epic Goal
- Make it possible to disable the console operator at install time, while still having a supported+upgradeable cluster.
Why is this important?
- It's possible to disable console itself using spec.managementState in the console operator config. There is no way to remove the console operator, though. For clusters where an admin wants to completely remove console, we should give the option to disable the console operator as well.
Scenarios
- I'm an administrator who wants to minimize my OpenShift cluster footprint and who does not want the console installed on my cluster
Acceptance Criteria
- It is possible at install time to opt-out of having the console operator installed. Once the cluster comes up, the console operator is not running.
Dependencies (internal and external)
- Composable cluster installation
Previous Work (Optional):
- https://docs.google.com/document/d/1srswUYYHIbKT5PAC5ZuVos9T2rBnf7k0F1WV2zKUTrA/edit#heading=h.mduog8qznwz
- https://docs.google.com/presentation/d/1U2zYAyrNGBooGBuyQME8Xn905RvOPbVv3XFw3stddZw/edit#slide=id.g10555cc0639_0_7
Open questions::
- The console operator manages the downloads deployment as well. Do we disable the downloads deployment? Long term we want to move to CLI manager: https://github.com/openshift/enhancements/blob/6ae78842d4a87593c63274e02ac7a33cc7f296c3/enhancements/oc/cli-manager.md
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Update the cluster-authentication-operator to not go degraded when it can’t determine the console url. This risks masking certain cases where we would want to raise an error to the admin, but the expectation is that this failure mode is rare.
Risk could be avoided by looking at ClusterVersion's enabledCapabilities to decide if missing Console was expected or not (unclear if the risk is high enough to be worth this amount of effort).
AC: Update the cluster-authentication-operator to not go degraded when console config CRD is missing and ClusterVersion config has Console in enabledCapabilities.
We need to continue to maintain specific areas within storage, this is to capture that effort and track it across releases.
Goals
- To allow OCP users and cluster admins to detect problems early and with as little interaction with Red Hat as possible.
- When Red Hat is involved, make sure we have all the information we need from the customer, i.e. in metrics / telemetry / must-gather.
- Reduce storage test flakiness so we can spot real bugs in our CI.
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| Telemetry | No | |
| Certification | No | |
| API metrics | No | |
Out of Scope
n/a
Background, and strategic fit
With the expected scale of our customer base, we want to keep load of customer tickets / BZs low
Assumptions
Customer Considerations
Documentation Considerations
- Target audience: internal
- Updated content: none at this time.
Notes
In progress:
- CSI certification flakes a lot. We should fix it before we start testing migration.
- In progress (API server restarts...) https://bugzilla.redhat.com/show_bug.cgi?id=1865857
- Get local-storage-operator and AWS EBS CSI driver operator logs in must-gather (OLM-managed operators are not included there)
- In progress for LSO (must-gather script being included in image) https://bugzilla.redhat.com/show_bug.cgi?id=1756096
- CI flakes:
- Configurable timeouts for e2e tests
- Azure is slow and times out often
- Cinder times out formatting volumes
- AWS resize test times out
- Configurable timeouts for e2e tests
High prio:
- Env. check tool for VMware - users often mis-configure permissions there and blame OpenShift. If we had a tool they could run, it might report better errors.
- Should it be part of the installer?
- Spike exists
- Add / use cloud API call metrics
-
- Helps customers to understand why things are slow
- Helps build cop to understand a flake
- With a post-install step that filters data from Prometheus that’s still running in the CI job.
- Ideas:
- Cloud is throttling X% of API calls longer than Y seconds
- Attach / detach / provisioning / deletion / mount / unmount / resize takes longer than X seconds?
- Capture metrics of operations that are stuck and won’t finish.
- Sweep operation map from executioner???
- Report operation metric into the highest bucket after the bucket threshold (i.e. if 10minutes is the last bucket, report an operation into this bucket after 10 minutes and don’t wait for its completion)?
- Ask the monitoring team?
- Include in CSI drivers too.
- With alerts too
- Report events for cloud issues
- E.g. cloud API reports weird attach/provision error (e.g. due to outage)
- What volume plugins actually users use the most? https://issues.redhat.com/browse/STOR-324
Unsorted
- As the number of storage operators grows, it would be grafana board for storage operators
- CSI driver metrics (from CSI sidecars + the driver itself + its operator?)
- CSI migration?
- Get aggregated logs in cluster
- They're rotated too soon
- No logs from dead / restarted pods
- No tools to combine logs from multiple pods (e.g. 3 controller managers)
- What storage issues customers have? it was 22% of all issues.
- Insufficient docs?
- Probably garbage
- Document basic storage troubleshooting for our supports
- What logs are useful when, what log level to use
- This has been discussed during the GSS weekly team meeting; however, it would be beneficial to have this documented.
- Common vSphere errors, their debugging and fixing.
- Document sig-storage flake handling - not all failed [sig-storage] tests are ours
Epic Goal
- Update all images that we ship with OpenShift to the latest upstream releases and libraries.
- Exact content of what needs to be updated will be determined as new images are released upstream, which is not known at the beginning of OCP development work. We don't know what new features will be included and should be tested and documented. Especially new CSI drivers releases may bring new, currently unknown features. We expect that the amount of work will be roughly the same as in the previous releases. Of course, QE or docs can reject an update if it's too close to deadline and/or looks too big.
Traditionally we did these updates as bugfixes, because we did them after the feature freeze (FF). Trying no-feature-freeze in 4.12. We will try to do as much as we can before FF, but we're quite sure something will slip past FF as usual.
Why is this important?
- We want to ship the latest software that contains new features and bugfixes.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
There is a new driver release 5.0.0 since the last rebase that includes snapshot support:
https://github.com/kubernetes-sigs/ibm-vpc-block-csi-driver/releases/tag/v5.0.0
Rebase the driver on v5.0.0 and update the deployments in ibm-vpc-block-csi-driver-operator.
There are no corresponding changes in ibm-vpc-node-label-updater since the last rebase.
Background and Goal
Currently in OpenShift we do not support distributing hotfix packages to cluster nodes. In time-sensitive situations, a RHEL hotfix package can be the quickest route to resolving an issue.
Acceptance Criteria
- Under guidance from Red Hat CEE, customers can deploy RHEL hotfix packages to MachineConfigPools.
- Customers can easily remove the hotfix when the underlying RHCOS image incorporates the fix.
Before we ship OCP CoreOS layering in https://issues.redhat.com/browse/MCO-165 we need to switch the format of what is currently `machine-os-content` to be the new base image.
The overall plan is:
- Publish the new base image as `rhel-coreos-8` in the release image
- Also publish the new extensions container (https://github.com/openshift/os/pull/763) as `rhel-coreos-8-extensions`
- Teach the MCO to use this without also involving layering/build controller
- Delete old `machine-os-content`
We need something in our repo /docs that we can point people to that briefly explains how to use "layering features" via the MCO in OCP ( well, and with the understanding that OKD also uses the MCO ).
Maybe this ends up in its own repo like https://github.com/coreos/coreos-layering-examples eventually, maybe it doesn't.
I'm thinking something like https://github.com/openshift/machine-config-operator/blob/layering/docs/DemoLayering.md back from when we did the layering branch, but actually matching what we have in our main branch
This is separate but probably related to what Colin started in the Docs Tracker.
Feature Overview
- Follow up work for the new provider, Nutanix, to extend extisting capabilities with new ones
Goals
- Make Nutanix CSI Driver part of the CVO once the driver and the Operator has been open sourced by the vendor
- Enable IPI for disconnected environments
- Enable the UPI workflow
- Nutanix CCM for the Node Controller
- Enable Egress IP for the provider
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Allow users to have nutanix platfrom integration choice (similar to vsphere) from AI SaaS
Why is this important?
- Expend RH offering beyond IPI
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Description of the problem:
BE 2.13.0, In Nutanix, UMN flow, If machine_network = [] , bootstrap validation failed.
How reproducible:
Trying to reproduce
Steps to reproduce:
1.
2.
3.
Actual results:
Expected results:
Why?
- Decouple control and data plane.
- Customers do not pay Red Hat more to run HyperShift control planes and supporting infrastructure than Standalone control planes and supporting infrastructure.
- Improve security
- Shift credentials out of cluster that support the operation of core platform vs workload
- Improve cost
- Allow a user to toggle what they don’t need.
- Ensure a smooth path to scale to 0 workers and upgrade with 0 workers.
Assumption
- A customer will be able to associate a cluster as “Infrastructure only”
- E.g. one option: management cluster has role=master, and role=infra nodes only, control planes are packed on role=infra nodes
- OR the entire cluster is labeled infrastructure , and node roles are ignored.
- Anything that runs on a master node by default in Standalone that is present in HyperShift MUST be hosted and not run on a customer worker node.
Doc: https://docs.google.com/document/d/1sXCaRt3PE0iFmq7ei0Yb1svqzY9bygR5IprjgioRkjc/edit
Epic Goal
- To improve debug-ability of ovn-k in hypershift
- To verify the stability of of ovn-k in hypershift
- To introduce a EgressIP reach-ability check that will work in hypershift
Why is this important?
- ovn-k is supposed to be GA in 4.12. We need to make sure it is stable, we know the limitations and we are able to debug it similar to the self hosted cluster.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
Dependencies (internal and external)
- This will need consultation with the people working on HyperShift
Previous Work (Optional):
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
CNCC was moved to the management cluster and it should use proxy settings defined for the management cluster.
In testing dual stack on vsphere we discovered that kubelet will not allow us to specify two ips on any platform except baremetal. We have a couple of options to deal with that:
- Wait for https://github.com/kubernetes/enhancements/pull/3706 to merge and be implemented upstream. This almost certainly means we miss 4.13.
- Wait for https://github.com/kubernetes/enhancements/pull/3706 to merge and then implement the design downstream. This involves risk of divergence from the eventual upstream design. We would probably only ship this way as tech preview and provide support exceptions for major customers.
- Remove the setting of nodeip for kubelet. This should get around the limitation on providing dual IPs, but it means we're reliant on the default kubelet IP selection logic, which is...not good. We'd probably only be able to support this on single nic network configurations.
GA CgroupV2 in 4.13
Default with RHEL 9
- Day 0 support for 4.13 where customer is able to change V1(default) to V2
- Day 1 where customer is able to change v1(default) to V2
- documentation on migration
- Pinning existing clusters to V1 before upgrade to 4.13
From OCP - 4.13, the RCOS nodes by default come up with the "CGroupsV2" configuration
Command to verify on any OCP cluster node
stat -c %T -f /sys/fs/cgroup/
So, to avoid unexpected complications, if the `cgroupMode` is found to be empty in the `nodes.config` resource, `CGroupsv1` configuration needs to be explicitly set using the `machine-config-operator`
This user tracks the changes required to remove the TechPreview related checks in the MCO code to graduate the CGroupsV2 feature to GA.
Feature
As an Infrastructure Administrator, I want to deploy OpenShift on vSphere with supervisor (aka Masters) and worker nodes (from a MachineSet) across multiple vSphere data centers and multiple vSphere clusters using full stack automation (IPI) and user provided infrastructure (UPI).
MVP
Install OpenShift on vSphere using IPI / UPI in multiple vSphere data centers (regions) and multiple vSphere clusters in 1 vCenter, all in the same IPv4 subnet (in the same physical location).
- Kubernetes Region contains vSphere datacenter and (single) vCenter name
- Kubernetes Zone contains vSphere cluster, resource pool, datastore, network (port group)
Out of scope
- There are no support the conversion of a non-zonal configuration (i.e. an existing OpenShift installation without 1+ zones) to a zonal configuration (1+ zones), but zonal UPI installation by the Infrastructure Administrator is permitted.
Scenarios for consideration:
- OpenShift in vSphere across different zones to avoid single points of failure, whereby each node is in different ESX clusters within the same vSphere datacenter, but in different networks.
- OpenShift in vSphere across multiple vSphere datacenter, while ensuring workers and masters are spread across 2 different datacenter in different subnets. (
RFE-845,RFE-459).
Acceptance criteria:
- Ensure vSphere IPI can successfully be deployed with ODF across the 3 zones (vSphere clusters) within the same vCenter [like we do with AWS, GCP & Azure].
- Ensure zonal configuration in vSphere using UPI is documented and tested.
References:
Epic Goal*
We need SPLAT-594 to be reflected in our CSI driver operator to support vSphere topology of storage GA.
Why is this important? (mandatory)
See SPLAT-320.
Scenarios (mandatory)
As user, I want to edit Infrastructure object after OCP installation (or upgrade) to update cluster topology, so all newly provisioned PVs will get the new topology labels.
(With vSphere topology GA, we expect that users will be allowed to edit Infrastructure and change the cluster topology after cluster installation.)
Dependencies (internal and external) (mandatory)
- SPLAT: [vsphere] Support Multiple datacenters and clusters GA.
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
It's possible that Infrastructure will remain read-only. No code on Storage side is expected then.
Done - Checklist (mandatory)
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
When STOR-1145 is merged, make sure that these new metrics are reported via telemetry to us.
Exit criteria:
- verify that metrics are reported in telemetry? I am not sure we have capabilities to test that, all code will be in monitoring repos.
I was thinking we will probably need a detailed metric for topology information about the cluster. Such as - how many failure-domains, how many datacenter and how many datastores.
In a zonal deployments, it is possible that new failure-domains are added to the cluster.
In that case, we will have to most likely discover these new failure-domains and tag datastores in them, so as topology aware provisioning can work.
We should create a metric and an alert if both ClusterCSIDriver and Infra object specify a topology.
Although such configuration is supported and Infra object will take precedence but it indicates an user error and hence user should be alerted about them.
As an openshift engineer make changes to various openshift components so that vSphere zonal installation is considered GA.
As a openshift engineer implement a new job for upi zonal so that method of installation is tested.
As a openshift engineer create an additional UPI terraform for zonal so that it can be tested in CI.
As a openshift engineer depreciate existing vSphere platform spec parameters so that they can eventually be removed in favor of zonal.
As a openshift engineer I need to follow the process to move the api from tech preview to ga so it can be used by clusters not installed with TechPreviewNoUpgrade.
more to follow...
Feature Goal*
What is our purpose in implementing this? What new capability will be available to customers?
The goal of this feature is to provide a consistent, predictable and deterministic approach on how the default storage class(es) is managed.
Why is this important? (mandatory)
The current default storage class implementation has corner cases which can result in PVs staying in pending because there is either no default storage class OR multiple storage classes are defined
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
No default storage class
In some cases there is no default SC defined, this can happen during OCP deployment where components such as the registry request a PV whereas the SC are not been defined yet. This can also happen during a change in default SC, there won't be any between the admin unset the current one and set the new on.
- The admin marks the current default SC1 as non-default.
Another user creates PVC requesting a default SC, by leaving pvc.spec.storageClassName=nil. The default SC does not exist at this point, therefore the admission plugin leaves the PVC untouched with pvc.spec.storageClassName=nil.
The admin marks SC2 as default.
PV controller, when reconciling the PVC, updates pvc.spec.storageClassName=nil to the new SC2.
PV controller uses the new SC2 when binding / provisioning the PVC.
- The installer creates PVC for the image registry first, requesting the default storage class by leaving pvc.spec.storageClassName=nil.
The installer creates a default SC.
PV controller, when reconciling the PVC, updates pvc.spec.storageClassName=nil to the new default SC.
PV controller uses the new default SC when binding / provisioning the PVC.
Multiple Storage Classes
In some cases there are multiple default SC, this can be an admin mistake (forget to unset the old one) or during the period where a new default SC is created but the old one is still present.
New behavior:
- Create a default storage class A
- Create a default storage class B
- Create PVC with pvc.spec.storageCLassName = nil
-> the PVC will get the default storage class with the newest CreationTimestamp (i.e. B) and no error should show.
-> admin will get an alert that there are multiple default storage classes and they should do something about it.
CSI that are shipped as part of OCP
The CSI drivers we ship as part of OCP are deployed and managed by RH operators. These operators automatically create a default storage class. Some customers don't like this approach and prefer to:
- Create their own default storage class
- Have no default storage class in order to disable dynamic provisioning
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
No external dependencies.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - STOR
- Documentation - STOR
- QE - STOR
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Can bring confusion to customer as there is a change in the default behavior customer are used to. This needs to be carefully documented.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
- https://github.com/openshift/alibaba-disk-csi-driver-operator/pull/41
- https://github.com/openshift/aws-ebs-csi-driver-operator/pull/173
- https://github.com/openshift/azure-disk-csi-driver-operator/pull/63
- https://github.com/openshift/azure-file-csi-driver-operator/pull/42
- https://github.com/openshift/gcp-pd-csi-driver-operator/pull/58
- https://github.com/openshift/ibm-vpc-block-csi-driver-operator/pull/48
- https://github.com/openshift/openstack-cinder-csi-driver-operator/pull/103
- https://github.com/openshift/ovirt-csi-driver-operator/pull/111
- https://github.com/openshift/vmware-vsphere-csi-driver-operator/pull/126
Feature Overview
Much like core OpenShift operators, a standardized flow exists for OLM-managed operators to interact with the cluster in a specific way to leverage AWS STS authorization when using AWS APIs as opposed to insecure static, long-lived credentials. OLM-managed operators can implement integration with the CloudCredentialOperator in well-defined way to support this flow.
Goals:
Enable customers to easily leverage OpenShift's capabilities around AWS STS with layered products, for increased security posture. Enable OLM-managed operators to implement support for this in well-defined pattern.
Requirements:
- CCO gets a new mode in which it can reconcile STS credential request for OLM-managed operators
- A standardized flow is leveraged to guide users in discovering and preparing their AWS IAM policies and roles with permissions that are required for OLM-managed operators
- A standardized flow is defined in which users can configure OLM-managed operators to leverage AWS STS
- An example operator is used to demonstrate the end2end functionality
- Clear instructions and documentation for operator development teams to implement the required interaction with the CloudCredentialOperator to support this flow
Use Cases:
See Operators & STS slide deck.
Out of Scope:
- handling OLM-managed operator updates in which AWS IAM permission requirements might change from one version to another (which requires user awareness and intervention)
Background:
The CloudCredentialsOperator already provides a powerful API for OpenShift's cluster core operator to request credentials and acquire them via short-lived tokens. This capability should be expanded to OLM-managed operators, specifically to Red Hat layered products that interact with AWS APIs. The process today is cumbersome to none-existent based on the operator in question and seen as an adoption blocker of OpenShift on AWS.
Customer Considerations
This is particularly important for ROSA customers. Customers are expected to be asked to pre-create the required IAM roles outside of OpenShift, which is deemed acceptable.
Documentation Considerations
- Internal documentation needs to exists to guide Red Hat operator developer teams on the requirements and proposed implementation of integration with CCO and the proposed flow
- External documentation needs to exist to guide users on:
- how to become aware that the cluster is in STS mode
- how to become aware of operators that support STS and the proposed CCO flow
- how to become aware of the IAM permissions requirements of these operators
- how to configure an operator in the proposed flow to interact with CCO
Interoperability Considerations
- this needs to work with ROSA
- this needs to work with self-managed OCP on AWS
Market Problem
This Section: High-Level description of the Market Problem ie: Executive Summary
- As a customer of OpenShift layered products, I need to be able to fluidly, reliably and consistently install and use OpenShift layered product Kubernetes Operators into my ROSA STS clusters, while keeping a STS workflow throughout.
- As a customer of OpenShift on the big cloud providers, overall I expect OpenShift as a platform to function equally well with tokenized cloud auth as it does with "mint-mode" IAM credentials. I expect the same from the Kubernetes Operators under the Red Hat brand (that need to reach cloud APIs) in that tokenized workflows are equally integrated and workable as with "mint-mode" IAM credentials.
- As the managed services, including Hypershift teams, offering a downstream opinionated, supported and managed lifecycle of OpenShift (in the forms of ROSA, ARO, OSD on GCP, Hypershift, etc), the OpenShift platform should have as close as possible, native integration with core platform operators when clusters use tokenized cloud auth, driving the use of layered products.
- .
- As the Hypershift team, where the only credential mode for clusters/customers is STS (on AWS) , the Red Hat branded Operators that must reach the AWS API, should be enabled to work with STS credentials in a consistent, and automated fashion that allows customer to use those operators as easily as possible, driving the use of layered products.
Why it Matters
- Adding consistent, automated layered product integrations to OpenShift would provide great added value to OpenShift as a platform, and its downstream offerings in Managed Cloud Services and related offerings.
- Enabling Kuberenetes Operators (at first, Red Hat ones) on OpenShift for the "big3" cloud providers is a key differentiation and security requirement that our customers have been and continue to demand.
- HyperShift is an STS-only architecture, which means that if our layered offerings via Operators cannot easily work with STS, then it would be blocking us from our broad product adoption goals.
Illustrative User Stories or Scenarios
- Main success scenario - high-level user story
- customer creates a ROSA STS or Hypershift cluster (AWS)
- customer wants basic (table-stakes) features such as AWS EFS or RHODS or Logging
- customer sees necessary tasks for preparing for the operator in OperatorHub from their cluster
- customer prepares AWS IAM/STS roles/policies in anticipation of the Operator they want, using what they get from OperatorHub
- customer's provides a very minimal set of parameters (AWS ARN of role(s) with policy) to the Operator's OperatorHub page
- The cluster can automatically setup the Operator, using the provided tokenized credentials and the Operator functions as expected
- Cluster and Operator upgrades are taken into account and automated
- The above steps 1-7 should apply similarly for Google Cloud and Microsoft Azure Cloud, with their respective token-based workload identity systems.
- Alternate flow/scenarios - high-level user stories
- The same as above, but the ROSA CLI would assist with AWS role/policy management
- The same as above, but the oc CLI would assist with cloud role/policy management (per respective cloud provider for the cluster)
- ...
Expected Outcomes
This Section: Articulates and defines the value proposition from a users point of view
- See SDE-1868 as an example of what is needed, including design proposed, for current-day ROSA STS and by extension Hypershift.
- Further research is required to accomodate the AWS STS equivalent systems of GCP and Azure
- Order of priority at this time is
- 1. AWS STS for ROSA and ROSA via HyperShift
- 2. Microsoft Azure for ARO
- 3. Google Cloud for OpenShift Dedicated on GCP
Effect
This Section: Effect is the expected outcome within the market. There are two dimensions of outcomes; growth or retention. This represents part of the “why” statement for a feature.
- Growth is the acquisition of net new usage of the platform. This can be new workloads not previously able to be supported, new markets not previously considered, or new end users not previously served.
- Retention is maintaining and expanding existing use of the platform. This can be more effective use of tools, competitive pressures, and ease of use improvements.
- Both of growth and retention are the effect of this effort.
- Customers have strict requirements around using only token-based cloud credential systems for workloads in their cloud accounts, which include OpenShift clusters in all forms.
- We gain new customers from both those that have waited for token-based auth/auth from OpenShift and from those that are new to OpenShift, with strict requirements around cloud account access
- We retain customers that are going thru both cloud-native and hybrid-cloud journeys that all inevitably see security requirements driving them towards token-based auth/auth.
- Customers have strict requirements around using only token-based cloud credential systems for workloads in their cloud accounts, which include OpenShift clusters in all forms.
References
As an engineer I want the capability to implement CI test cases that run at different intervals, be it daily, weekly so as to ensure downstream operators that are dependent on certain capabilities are not negatively impacted if changes in systems CCO interacts with change behavior.
Acceptance Criteria:
Create a stubbed out e2e test path in CCO and matching e2e calling code in release such that there exists a path to tests that verify working in an AWS STS workflow.
OC mirror is GA product as of Openshift 4.11 .
The goal of this feature is to solve any future customer request for new features or capabilities in OC mirror
In 4.12 release, a new feature was introduced to oc-mirror allowing it to use OCI FBC catalogs as starting point for mirroring operators.
Overview
As a oc-mirror user, I would like the OCI FBC feature to be stable
so that I can use it in a production ready environment
and to make the new feature and all existing features of oc-mirror seamless
Current Status
This feature is ring-fenced in the oc mirror repository, it uses the following flags to achieve this so as not to cause any breaking changes in the current oc-mirror functionality.
- --use-oci-feature
- --oci-feature-action (copy or mirror)
- --oci-registries-config
The OCI FBC (file base container) format has been delivered for Tech Preview in 4.12
Tech Enablement slides can be found here https://docs.google.com/presentation/d/1jossypQureBHGUyD-dezHM4JQoTWPYwiVCM3NlANxn0/edit#slide=id.g175a240206d_0_7
Design doc is in https://docs.google.com/document/d/1-TESqErOjxxWVPCbhQUfnT3XezG2898fEREuhGena5Q/edit#heading=h.r57m6kfc2cwt (also contains latest design discussions around the stories of this epic)
Link to previous working epic https://issues.redhat.com/browse/CFE-538
Contacts for the OCI FBC feature
- Sherine Khoury
- Luigi Mario Zuccarelli
- IBM John Hunkins
- CFE PM Heather Heffner
- WRKLDS PM Tomas Smetana
As IBM user, I'd like to be able to specify the destination of the OCI FBC catalog in ImageSetConfig
So that I can control where that image is pushed to on the disconnected destination registry, because the path on disk to that OCI catalog doesn't make sense to be used in the component paths of the destination catalog.
Expected Inputs and Outputs - Counter Proposal
Examples provided assume that the current working directory is set to /tmp/cwdtest.
Instead of introducing a targetNamespace which is used in combination with targetName, this counter proposal introduces a targetCatalog field which supersedes the existing targetName field (which would be marked as deprecated). Users should transition from using targetName to targetCatalog, but if both happen to be specified, the targetCatalog is preferred and targetName is ignored. Any ISC that currently uses targetName alone should continue to be used as currently defined.
The rationale for targetCatalog is that some customers will have restrictions on where images can be placed. All IBM images always use a namespace. We therefore need a way to indicate where the CATALOG image is located within the context of the target registry... it can't just be placed in the root, so we need a way to configure this.
The targetCatalog field consists of an optional namespace followed by the target image name, described in extended Backus–Naur form below:
target-catalog = [namespace '/'] target-name target-name = path-component namespace = path-component ['/' path-component]* path-component = alpha-numeric [separator alpha-numeric]* alpha-numeric = /[a-z0-9]+/ separator = /[_.]|__|[-]*/
The target-name portion of targetCatalog represents the the image name in the final destination registry, and matches the definition/purpose of the targetName field. The namespace is only used for "placement" of the catalog image into the right "hierarchy" in the target registry. The target-name portion will be used in the catalog source metadata name, the file name of the catalog source, and target image reference.
Examples:
- with namespace:
targetCatalog: foo/bar/baz/ibm-zcon-zosconnect-example
- without namespace:
targetCatalog: ibm-zcon-zosconnect-example
Simple Flow
FBC image from docker registry
Command:
oc mirror -c /Users/jhunkins/go/src/github.com/jchunkins/oc-mirror/ImageSetConfiguration.yml --dest-skip-tls --dest-use-http docker://localhost:5000
ISC
/Users/jhunkins/go/src/github.com/jchunkins/oc-mirror/ImageSetConfiguration.yml
kind: ImageSetConfiguration apiVersion: mirror.openshift.io/v1alpha2 storageConfig: local: path: /tmp/localstorage mirror: operators: - catalog: icr.io/cpopen/ibm-zcon-zosconnect-catalog@sha256:6f02ecef46020bcd21bdd24a01f435023d5fc3943972ef0d9769d5276e178e76
ICSP
/tmp/cwdtest/oc-mirror-workspace/results-1675716807/imageContentSourcePolicy.yaml
apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: labels: operators.openshift.org/catalog: "true" name: operator-0 spec: repositoryDigestMirrors: - mirrors: - localhost:5000/cpopen source: icr.io/cpopen - mirrors: - localhost:5000/openshift4 source: registry.redhat.io/openshift4
CatalogSource
/tmp/cwdtest/oc-mirror-workspace/results-1675716807/catalogSource-ibm-zcon-zosconnect-catalog.yaml
apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: ibm-zcon-zosconnect-catalog namespace: openshift-marketplace spec: image: localhost:5000/cpopen/ibm-zcon-zosconnect-catalog:6f02ec sourceType: grpc
Simple Flow With Target Namespace
FBC image from docker registry (putting images into a destination "namespace")
Command:
oc mirror -c /Users/jhunkins/go/src/github.com/jchunkins/oc-mirror/ImageSetConfiguration.yml --dest-skip-tls --dest-use-http docker://localhost:5000/foo
ISC
/Users/jhunkins/go/src/github.com/jchunkins/oc-mirror/ImageSetConfiguration.yml
kind: ImageSetConfiguration apiVersion: mirror.openshift.io/v1alpha2 storageConfig: local: path: /tmp/localstorage mirror: operators: - catalog: icr.io/cpopen/ibm-zcon-zosconnect-catalog@sha256:6f02ecef46020bcd21bdd24a01f435023d5fc3943972ef0d9769d5276e178e76
ICSP
/tmp/cwdtest/oc-mirror-workspace/results-1675716807/imageContentSourcePolicy.yaml
apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: labels: operators.openshift.org/catalog: "true" name: operator-0 spec: repositoryDigestMirrors: - mirrors: - localhost:5000/foo/cpopen source: icr.io/cpopen - mirrors: - localhost:5000/foo/openshift4 source: registry.redhat.io/openshift4
CatalogSource
/tmp/cwdtest/oc-mirror-workspace/results-1675716807/catalogSource-ibm-zcon-zosconnect-catalog.yaml
apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: ibm-zcon-zosconnect-catalog namespace: openshift-marketplace spec: image: localhost:5000/foo/cpopen/ibm-zcon-zosconnect-catalog:6f02ec sourceType: grpc
Simple Flow With TargetCatalog / TargetTag
FBC image from docker registry (overriding the catalog name and tag)
Command:
oc mirror -c /Users/jhunkins/go/src/github.com/jchunkins/oc-mirror/ImageSetConfiguration.yml --dest-skip-tls --dest-use-http docker://localhost:5000
ISC
/Users/jhunkins/go/src/github.com/jchunkins/oc-mirror/ImageSetConfiguration.yml
kind: ImageSetConfiguration apiVersion: mirror.openshift.io/v1alpha2 storageConfig: local: path: /tmp/localstorage mirror: operators: - catalog: icr.io/cpopen/ibm-zcon-zosconnect-catalog@sha256:6f02ecef46020bcd21bdd24a01f435023d5fc3943972ef0d9769d5276e178e76 targetCatalog: cpopen/ibm-zcon-zosconnect-example # NOTE: namespace now has to be provided along with the # target catalog name to preserve the namespace in the resulting image targetTag: v123
ICSP
/tmp/cwdtest/oc-mirror-workspace/results-1675716807/imageContentSourcePolicy.yaml
apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: labels: operators.openshift.org/catalog: "true" name: operator-0 spec: repositoryDigestMirrors: - mirrors: - localhost:5000/cpopen source: icr.io/cpopen - mirrors: - localhost:5000/openshift4 source: registry.redhat.io/openshift4
CatalogSource
/tmp/cwdtest/oc-mirror-workspace/results-1675716807/catalogSource-ibm-zcon-zosconnect-example.yaml
apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: ibm-zcon-zosconnect-example namespace: openshift-marketplace spec: image: localhost:5000/cpopen/ibm-zcon-zosconnect-example:v123 sourceType: grpc
OCI Flow
FBC image from OCI path
In this example we're suggesting the use of a targetCatalog field.
Command:
oc mirror -c /Users/jhunkins/go/src/github.com/jchunkins/oc-mirror/ImageSetConfiguration.yml --dest-skip-tls --dest-use-http --use-oci-feature docker://localhost:5000
ISC
/Users/jhunkins/go/src/github.com/jchunkins/oc-mirror/ImageSetConfiguration.yml
kind: ImageSetConfiguration apiVersion: mirror.openshift.io/v1alpha2 storageConfig: local: path: /tmp/localstorage mirror: operators: - catalog: oci:///foo/bar/baz/ibm-zcon-zosconnect-catalog/amd64 # This is just a path to the catalog and has no special meaning targetCatalog: foo/bar/baz/ibm-zcon-zosconnect-example # <--- REQUIRED when using OCI and optional for docker images # value is used within the context of the target registry # targetTag: v123 # <--- OPTIONAL
ICSP
/tmp/cwdtest/oc-mirror-workspace/results-1675716807/imageContentSourcePolicy.yaml
apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: labels: operators.openshift.org/catalog: "true" name: operator-0 spec: repositoryDigestMirrors: - mirrors: - localhost:5000/cpopen source: icr.io/cpopen - mirrors: - localhost:5000/openshift4 source: registry.redhat.io/openshift4
CatalogSource
/tmp/cwdtest/oc-mirror-workspace/results-1675716807/catalogSource-ibm-zcon-zosconnect-example.yaml
apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: ibm-zcon-zosconnect-example namespace: openshift-marketplace spec: image: localhost:5000/foo/bar/baz/ibm-zcon-zosconnect-example:6f02ec # Example uses "targetCatalog" set to # "foo/bar/baz/ibm-zcon-zosconnect-example" at the # destination registry localhost:5000 sourceType: grpc
OCI Flow With Namespace
FBC image from OCI path (putting images into a destination "namespace" named "abc")
Command:
oc mirror -c /Users/jhunkins/go/src/github.com/jchunkins/oc-mirror/ImageSetConfiguration.yml --dest-skip-tls --dest-use-http --use-oci-feature docker://localhost:5000/abc
ISC
/Users/jhunkins/go/src/github.com/jchunkins/oc-mirror/ImageSetConfiguration.yml
kind: ImageSetConfiguration apiVersion: mirror.openshift.io/v1alpha2 storageConfig: local: path: /tmp/localstorage mirror: operators: - catalog: oci:///foo/bar/baz/ibm-zcon-zosconnect-catalog/amd64 # This is just a path to the catalog and has no special meaning targetCatalog: foo/bar/baz/ibm-zcon-zosconnect-example # <--- REQUIRED when using OCI and optional for docker images # value is used within the context of the target registry # targetTag: v123 # <--- OPTIONAL
ICSP
/tmp/cwdtest/oc-mirror-workspace/results-1675716807/imageContentSourcePolicy.yaml
apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: labels: operators.openshift.org/catalog: "true" name: operator-0 spec: repositoryDigestMirrors: - mirrors: - localhost:5000/abc/cpopen source: icr.io/cpopen - mirrors: - localhost:5000/abc/openshift4 source: registry.redhat.io/openshift4
CatalogSource
/tmp/cwdtest/oc-mirror-workspace/results-1675716807/catalogSource-ibm-zcon-zosconnect-example-catalog.yaml
apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: ibm-zcon-zosconnect-example namespace: openshift-marketplace spec: image: localhost:5000/abc/foo/bar/baz/ibm-zcon-zosconnect-example:6f02ec # Example uses "targetCatalog" set to # "foo/bar/baz/ibm-zcon-zosconnect-example" at the # destination registry localhost:5000/abc sourceType: grpc
As IBM, I would like to use oc-mirror with the --use-oci-feature flag and ImageSetConfigs containing OCI-FBC operator catalogs to mirror these catalogs to a connected registry
so that , regarding OCI FBC catalog:
- all bundles specified in the ImageSetConfig and their related images are mirrored from their source registry to the destination registry
- and the catalogs are mirrored from the local disk to the destination registry
- and the ImageContentSourcePolicy and CatalogSource files are generated correctly
and that regarding releases, additional images, helm charts:
- The images that are selected for mirroring are mirrored to the destination registry using the MirrorToMirror workflow
As an oc-mirror user I want a well documented and intuitive process
so that I can effectively and efficiently deliver image artifacts in both connected and disconnected installs with no impact on my current workflow
Glossary:
- OCI-FBC operator catalog: catalog image in oci format saved to disk, referenced with oci://path-to-image
- registry based operator catalog: catalog image hosted on a container registry.
References:
Acceptance criteria:
- No regression on oc-mirror use cases that are not using OCI-FBC feature
- mirrorToMirror use case with oci feature flag should be successful when all operator catalogs in ImageSetConfig are OCI-FBC:
- oc-mirror -c config.yaml docker://remote-registry --use-oci-feature succeeds
- All release images, helm charts, additional images are mirrored to the remote-registry in an incremental manner (only new images are mirrored based on contents of the storageConfig)
- All catalogs OCI-FBC, selected bundles and their related images are mirrored to the remote-registry and corresponding catalogSource and ImageSourceContentPolicy generated
- All registry based catalogs, selected bundles and their related images are mirrored to the remote-registry and corresponding catalogSource and ImageSourceContentPolicy generated
- mirrorToDisk use case with the oci feature flag is forbidden. The following command should fail:
- oc-mirror --from=seq_xx_tar docker://remote-registry --use-oci-feature
- diskToMirror use case with oci feature flag is forbidden. The following command should fail:
- oc-mirror --config=isc.yaml file://file-dir --use-oci-feature
WHAT
Refer engineering notes document https://docs.google.com/document/d/1zZ6FVtgmruAeBoUwt4t_FoZH2KEm46fPitUB23ifboY/edit#heading=h.6pw5r5w2r82 steps 2-7
Acceptance Criteria
- Code clean up and formating into functions
- Ensure good commenting
- Implement correct code functionality
- Ensure to oci mirrorTomirror functionality works correctly
- Update unit tests
Feature Overview
Customers are asking for improvements to the upgrade experience (both over-the-air and disconnected). This is a feature tracking epics required to get that work done.
Goals
- Have an option to do upgrades in more discrete steps under admin control. Specifically, these steps are:
- Control plane upgrade
- Worker nodes upgrade
- Workload enabling upgrade (i..e. Router, other components) or infra nodes
- Better visibility into any errors during the upgrades and documentation of what they error means and how to recover.
- An user experience around an end-2-end back-up and restore after a failed upgrade
OTA-810- Better Documentation:- Backup procedures before upgrades.
- More control over worker upgrades (with tagged pools between user Vs admin)
- The kinds of pre-upgrade tests that are run, the errors that are flagged and what they mean and how to address them.
- Better explanation of each discrete step in upgrades, and what each CVO Operator is doing and potential errors, troubleshooting and mitigating actions.
References
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Revamp our Upgrade Documentation to include an appropriate level of detail for admins
Why is this important?
- Currently Admins have nothing which explains to them how upgrades actually work and as a result when things don't go perfectly they panic
- We do not sufficiently, or at least within context of Upgrade Docs, explain the differences between Degraded and Available statuses
- We do not explain order of operations
- We do not explain protections built into the platform which protect against total cluster failure, ie halting when components do not return to healthy state within exp
Scenarios
- Move out channel management to its own chapter
- Explain or link to existing documentation which addresses the differences between Degraded=True and Available=False
- Explain Upgradeable=False conditions and other aspects of upgrade preflight strategy that Operators should be indicating when its unsafe to upgrade
- Explain basics of how the upgrade is applied
- CVO fetches release image
- CVO updates operators in the following order
- Each operator is expected to monitor for success
- Provide example ordering of manifests and command to extract release specific manifests and infer the ordering
- Explain how operators indicate problems and generic processes for investigating them
- Explain the special role of MCO and MCP mechanisms such as pausing pools
- Provide some basic guidance for Control Plane duration, that is exclude worker pool rollout duration (90-120 minutes is normal)
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- There was an effort to write up how to use MachineConfig Pools to partition and optimize worker rollout in https://issues.redhat.com/browse/OTA-375
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
The CVO README is currently aimed at CVO devs. But there are way more CVO consumers than there are CVO devs. We should aim the README at "what does the CVO do for my clusters?", and push the dev docs down under docs/dev/.
Feature Overview
- Support OpenShift to be deployed on AWS Local Zones
Goals
- Support OpenShift to be deployed from day-0 on AWS Local Zones
- Support an existing OpenShift cluster to deploy compute Nodes on AWS Local Zones (day-2)
AWS Local Zones support - feature delivered in phases:
- Phase 0 (
OCPPLAN-9630): Document how to create compute nodes on AWS Local Zones in day-0 (SPLAT-635) - Phase 1 (
OCPBU-2): Create edge compute pool to generate MachineSets for node with NoSchedule taints when installing a cluster in existing VPC with AWS Local Zone subnets (SPLAT-636) - Phase 2 (
OCPBU-351): Installer automates network resources creation on Local Zone based on the edge compute pool (SPLAT-657)
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Epic Goal
- Admins can create compute pool named `edge` on the AWS platform to setting up Local Zone MachineSets.
- Admins can select and configure subnets on Local Zones before cluster creation.
- Ensure the installer allows creating a new machine pool for `edge` workloads
- Ensure the installer can create the MachineSet with `NoSchedule` taints on edge machine pools.
- Ensure Local Zone subnets will not be used on `worker` compute pools or control planes.
- Ensure the Wavelength zone will not be used in any compute pool
- Ensure the Cluster Network MTU manifest is created when Local Zone subnets are added when installing a cluster in existing VPC
Why is this important?
- …
Scenarios
User Stories
- As a cluster admin, I want the ability to specify a set of subnets on the AWS
Local Zone locations to deploy worker nodes, so I can further create custom
applications to deliver low latency to my end users.
- As a cluster admin, I would like to create a cluster extending worker nodes to
the edge of the AWS cloud provider with Local Zones, so I can further create
custom applications to deliver low latency to my end users.
- As a cluster admin, I would like to select existing subnets from the local and
the parent region zones, to install a cluster, so I can manage networks with
my automation.
- As a cluster admin, I would like to install OpenShift clusters, extending the
compute nodes to the Local Zones in my day zero operations without needing to
set up the network and compute dependencies, so I can speed up the edge adoption
in my organization using OKD/OCP.
Acceptance Criteria
- The enhancement must be accepted and merged
- Release Technical Enablement - Provide necessary release enablement details and documents.
- The installer implementation must be merged
Dependencies (internal and external)
Previous Work (Optional):
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
- Support deploying OCP in “GCP Service Project” while networks are defined in “GCP Host Project”.
- Enable OpenShift IPI Installer to deploy OCP in “GCP Service Project” while networks are defined in “GCP Host Project”
- “GCP Service Project” is from where the OpenShift installer is fired.
- “GCP host project” is the target project where the deployment of the OCP machines are done.
- Customer using shared VPC and have a distributed network spanning across the projects.
Goals
- As a user, I want to be able to deploy OpenShift on Google Cloud using XPN, where networks and other resources are deployed in a shared "Host Project" while the user bootstrap the installation from a "Sevice Project" so that I can follow Google's architecture best practices
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Epic Goal
- Enable OpenShift IPI Installer to deploy OCP to a shared VPC in GCP.
- The host project is where the VPC and subnets are defined. Those networks are shared to one or more service projects.
- Objects created by the installer are created in the service project where possible. Firewall rules may be the only exception.
- Documentation outlines the needed minimal IAM for both the host and service project.
Why is this important?
- Shared VPC's are a feature of GCP to enable granular separation of duties for organizations that centrally manage networking but delegate other functions and separation of billing. This is used more often in larger organizations where separate teams manage subsets of the cloud infrastructure. Enterprises that use this model would also like to create IPI clusters so that they can leverage the features of IPI. Currently organizations that use Shared VPC's must use UPI and implement the features of IPI themselves. This is repetative engineering of little value to the customer and an increased risk of drift from upstream IPI over time. As new features are built into IPI, organizations must become aware of those changes and implement them themselves instead of getting them "for free" during upgrades.
Scenarios
- Deploy cluster(s) into service project(s) on network(s) shared from a host project.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a developer, I want to be able to:
- specify a project for the public and private DNS managedZones
so that I can achieve
- enable DNS zones in alternate projects, such as the GCP XPN Host Project
Acceptance Criteria:
Description of criteria:
- cluster-ingress-operator can parse the project and zone name from the following format
- projects/project-id/managedZones/zoneid
- cluster-ingress-operator continues to accept names that are not relative resource names
- zoneid
(optional) Out of Scope:
All modifications to the openshift-installer is handled in other cards in the epic.
Engineering Details:
- https://github.com/openshift/api/blob/0ee1471bcabbfefade29abeae5aab53366d0493f/config/v1/types_dns.go#L43
- https://github.com/openshift/cluster-ingress-operator/blob/14f40c789e4e851aae2d812ea8e6fc1e70d9977f/pkg/dns/gcp/provider.go#L51-L60 oller.go#L562-L571
- https://cloud.google.com/dns/docs/reference/v1/managedZones/get#parameters
- https://cloud.google.com/apis/design/resource_names#relative_resource_name
Feature Overview
Allow users to interactively adjust the network configuration for a host after booting the agent ISO.
Goals
Configure network after host boots
The user has Static IPs, VLANs, and/or bonds to configure, but has no idea of the device names of the NICs. They don't enter any network config in agent-config.yaml. Instead they configure each host's network via the text console after it boots into the image.
Epic Goal
- Allow users to interactively adjust the network configuration for a host after booting the agent ISO, before starting processes that pull container images.
Why is this important?
- Configuring the network prior to booting a host is difficult and error-prone. Not only is the nmstate syntax fairly arcane, but the advent of 'predictable' interface names means that interfaces retain the same name across reboots but it is nearly impossible to predict what they will be. Applying configuration to the correct hosts requires correct knowledge and input of MAC addresses. All of these present opportunities for things to go wrong, and when they do the user is forced to return to the beginning of the process and generate a new ISO, then boot all of the hosts in the cluster with it again.
Scenarios
- The user has Static IPs, VLANs, and/or bonds to configure, but has no idea of the device names of the NICs. They don't enter any network config in agent-config.yaml. Instead they configure each host's network via the text console after it boots into the image.
- The user has Static IPs, VLANs, and/or bonds to configure, but makes an error entering the configuration in agent-config.yaml so that (at least) one host will not be able to pull container images from the release payload. They correct the configuration for that host via the text console before proceeding with the installation.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
In the console service from AGENT-453, check whether we are able to pull the release image, and display this information to the user before prompting to run nmtui.
If we can access the image, then exit the service if there is no user input after some timeout, to allow the installation to proceed in the automation flow.
As a user, I need information about common misconfigurations that may be preventing the automated installation from proceeding.
If we are unable to access the release image from the registry, provide sufficient debugging information to the user to pinpoint the problem. Check for:
- DNS
- ping
- HTTP
- Registry login
- Release image
The openshift-install agent create image will need to fetch the agent-tui executable so that it could be embedded within the agent ISO. For this reason the agent-tui must be available in the release payload, so that it could be retrieved even when the command is invoked in a disconnected environment.
The node zero ip is currently hard-coded inside set-node-zero.sh.template and in the ServiceBaseURL template string.
ServiceBaseURL is also hard-coded inside:
- apply-host-config.service.template
- create-cluster-and-infraenv-service.template
- common.sh.template
- start-agent.sh.template
- start-cluster-installation.sh.template
- assisted-service.env.template
We need to remove this hard-coding and to allow a user to be able to set the node zero ip through the tui and have it be reflected by the agent services and scripts.
Currently the agent-tui displays always the additional checks (nslookup/ping/http get), even when the primary check (pull image) passes. This may cause some confusion to the user, due the fact that the additional checks do not prevent the agent-tui to complete successfully but they are just informative, to allow a better troubleshooting of the issue (so not needed in the positive case).
The additional checks should then be shown only when the primary check fails for any reason.
Right now all the connectivity checks are executed simultaneously, and it doesn't seem necessary especially in the positive scenario, ie when the release image can be pulled without any issue.
So, the connectivity related checks should be performed only when the release image is not accessible, to provide further infos to to the user.
The initial condition for allowing to continue (or not) the installation should be related then just to result of the primary check (right now, just the pull image) and not the secondary ones (http/dns/ping), that are just informative checks.
Note: this approach will also help to manage those cases where, currently, the release image can be pulled but the host doesn't answer to the ping
Enhance the openshift-install agent create image command so that the agent-nmtui executable will be embedded in the agent ISO
After having created the agent ISO, the agent-nmtui must be added to the ISO using the following approach:
1. Unpack the agent ISO in a temporary folder
2. Unpack the /images/ignition.img compressed cpio archive in a temporary folder
3. Create a new ignition.img compressed cpio archive by appending the agent-nmtui
2. Create a new agent ISO with the updated ignition.img
Implementation note
Portions of code from a PoC located at https://github.com/andfasano/gasoline could be re-used
When running the openshift-install agent create image command, first of all it needs to extract the agent-tui executable from the release payload in a temporary folder
When the agent-tui is shown during the initial host boot, if the pull release image check fails then an additional checks box is shown along with a details text view.
The content of the details view gets continuosly updated with the details of failed check, but the user cannot move the focus over the details box (using the arrow/tab keys), thus cannot scroll its content (using the up/down arrow keys)
Create a systemd service that runs at startup prior to the login prompt and takes over the console. This should start after the network-online target, and block the login prompt appearing until it exits.
This should also block, at least temporarily, any services that require pulling an image from the registry (i.e. agent + assisted-service).
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
Epic Goal
- The goal of this epic to begin the process of expanding support of OpenShift on ppc64le hardware to include IPI deployments against the IBM Power Virtual Server (PowerVS) APIs.
Why is this important?
The goal of this initiative to help boost adoption of OpenShift on ppc64le. This can be further broken down into several key objectives.
- For IBM, furthering adopt of OpenShift will continue to drive adoption on their power hardware. In parallel, this can be used for existing customers to migrate their old power on-prem workloads to a cloud environment.
- For the Multi-Arch team, this represents our first opportunity to develop an IPI offering on one of the IBM platforms. Right now, we depend on IPI on libvirt to cover our CI needs; however, this is not a supported platform for customers. PowerVS would address this caveat for ppc64le.
- By bringing in PowerVS, we can provide customers with the easiest possible experience to deploy and test workloads on IBM architectures.
- Customers already have UPI methods to solve their OpenShift on prem needs for ppc64le. This gives them an opportunity for a cloud based option, further our hybrid-cloud story.
Scenarios
- As a user with a valid PowerVS account, I would like to provide those credentials to the OpenShift installer and get a full cluster up on IPI.
Technical Specifications
Some of the technical specifications have been laid out in MULTIARCH-75.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
- Images are built in the RHCOS pipeline and pushed in the OVA format to the IBM Cloud.
- Installer is extended to support PowerVS as a new platform.
- Machine and cluster APIs are updated to support PowerVS.
- A terraform provider is developed against the PowerVS APIs.
- A load balancing strategy is determined and made available.
- Networking details are sorted out.
Open questions::
- Load balancing implementation?
- Networking strategy given the lack of virtual network APIs in PowerVS.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- Improve IPI on Power VS in the 4.13 cycle
Running doc to describe terminologies and concepts which are specific to Power VS - https://docs.google.com/document/d/1Kgezv21VsixDyYcbfvxZxKNwszRK6GYKBiTTpEUubqw/edit?usp=sharing
Recently, the image registry team decided with this change[1] that major cloud platforms cannot have `emptyDir` as the storage backend. IBMCloud uses ibmcos, which we would ideally need to do. There have been few issues identified with using ibmcos as is in the cluster image registry operator and some solutions identified here[2]. Basically, we would need the PowerVS platform to be supported for ibmcos and an API related to change to add resourceGroup in the infra API. This only affects 4.13 and is not an issue for 4.12.
[1] https://github.com/openshift/cluster-image-registry-operator/pull/820
BU Priority Overview
As our customers create more and more clusters, it will become vital for us to help them support their fleet of clusters. Currently, our users have to use a different interface(ACM UI) in order to manage their fleet of clusters. Our goal is to provide our users with a single interface for managing a fleet of clusters to deep diving into a single cluster. This means going to a single URL – your Hub – to interact with your OCP fleet.
Goals
The goal of this tech preview update is to improve the experience from the last round of tech preview. The following items will be improved:
- Improved Cluster Picker: Moved to Masthead for better usability, filter/search
- Support for Metrics: Metrics are now visualized from Spoke Clusters
- Avoid UI Mismatch: Dynamic Plugins from Spoke Clusters are disabled
- Console URLs Enhanced: Cluster Name Add to URL for Quick Links
- Security Improvements: Backend Proxy and Auth updates
An epic we can duplicate for each release to ensure we have a place to catch things we ought to be doing regularly but can tend to fall by the wayside.
As a developer I want a github pr template that allows me to provide:
- functionality explanation
- assignee
- screenshots or demo
- draft test cases
Key Objective
Providing our customers with a single simplified User Experience(Hybrid Cloud Console)that is extensible, can run locally or in the cloud, and is capable of managing the fleet to deep diving into a single cluster.
Why customers want this?
- Single interface to accomplish their tasks
- Consistent UX and patterns
- Easily accessible: One URL, one set of credentials
Why we want this?
- Shared code - improve the velocity of both teams and most importantly ensure consistency of the experience at the code level
- Pre-built PF4 components
- Accessibility & i18n
- Remove barriers for enabling ACM
Phase 2 Goal: Productization of the united Console
- Enable user to quickly change context from fleet view to single cluster view
- Add Cluster selector with “All Cluster” Option. “All Cluster” = ACM
- Shared SSO across the fleet
- Hub OCP Console can connect to remote clusters API
- When ACM Installed the user starts from the fleet overview aka “All Clusters”
- Share UX between views
- ACM Search —> resource list across fleet -> resource details that are consistent with single cluster details view
- Add Cluster List to OCP —> Create Cluster
As a Dynamic Plugin developer I would render version of my Dynamic plugin in the About modal. For that we would need to check the `
LoadedDynamicPluginInfo` instances. There we need to check the `metadata.name` and `metadata.version` that we need to surface to the About modal.
AC: Render name and version for each Dynamic Plugin into the About modal.
Original description: When ACM moved to the unified console experience, we lost the ability in our standalone console to display our version information in our own About modal. We would like to be able to add our product and version information into the OCP About modal.
In order for hub cluster console OLM screens to behave as expected in a multicluster environment, we need to gather "copiedCSVsDisabled" flags from managed clusters so that the console backend/frontend can consume this information.
AC:
- The console operator syncs "copiedCSVsDisabled" flags from managed clusters into the hub cluster managed cluster config.
Mock a multicluster environment in our CI using Cypress, without provisioning multiple clusters using a combination of cy.intercept and updating window.SERVER flags in the before section of the test scenarios.
Acceptance Criteria:
Without provisioning additional clusters:
- mock server flags to render a cluster dropdown
- mock sample pod data for a fictional cluster
Installed operators, operator details, operand details, and operand create pages should work as expected in a multicluster environment when copied CSVs are disabled on any cluster in the fleet.
AC:
- Console backend consumes "copiedCSVsDisabled" flags for each cluster in the fleet
- Frontend handles copiedCSVsDisabled behavior "per-cluster" and OLM pages work as expected no matter which cluster is selected
Description of problem:
When viewing a resource that exists for multiple clusters, the data may be from the wrong cluster for a short time after switching clusters using the multicluster switcher.
Version-Release number of selected component (if applicable):
4.10.6
How reproducible:
Always
Steps to Reproduce:
1. Install RHACM 2.5 on OCP 4.10 and enable the FeatureGate to get multicluster switching 2. From the local-cluster perspective, view a resource that would exist on all clusters, like /k8s/cluster/config.openshift.io~v1~Infrastructure/cluster/yaml 3. Switch to a different cluster in the cluster switcher
Actual results:
Content for resource may start out correct, but then switch back to the local-cluster version before switching to the correct cluster several moments later.
Expected results:
Content should always be shown from the selected cluster.
Additional info:
Migrated from bugzilla: https://bugzilla.redhat.com/show_bug.cgi?id=2075657
Description of problem:
When multi-cluster is enabled and the console can display data from other clusters, we should either change or disable how we filter the OperatorHub catalog by arch / OS. We assume that the arch and OS of the pod running the console is the same as the cluster, but for managed clusters, it could be something else, which would cause us to incorrectly filter operators.
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1. 2. 3.
Actual results:
Expected results:
Additional info:
Migrated from https://bugzilla.redhat.com/show_bug.cgi?id=2089939
Description of problem:
There is a possible race condition in the console operator where the managed cluster config gets updated after the console deployment and doesn't trigger a rollout.
Version-Release number of selected component (if applicable):
4.10
How reproducible:
Rarely
Steps to Reproduce:
1. Enable multicluster tech preview by adding TechPreviewNoUpgrade featureSet to FeatureGate config. (NOTE THIS ACTION IS IRREVERSIBLE AND WILL MAKE THE CLUSTER UNUPGRADEABLE AND UNSUPPORTED) 2. Install ACM 2.5+ 3. Import a managed cluster using either the ACM console or the CLI 4. Once that managed cluster is showing in the cluster dropdown, import a second managed cluster
Actual results:
Sometimes the second managed cluster will never show up in the cluster dropdown
Expected results:
The second managed cluster eventually shows up in the cluster dropdown after a page refresh
Additional info:
Migrated from bugzilla: https://bugzilla.redhat.com/show_bug.cgi?id=2055415
Feature Overview
Allow to configure compute and control plane nodes on across multiple subnets for on-premise IPI deployments. With separating nodes in subnets, also allow using an external load balancer, instead of the built-in (keepalived/haproxy) that the IPI workflow installs, so that the customer can configure their own load balancer with the ingress and API VIPs pointing to nodes in the separate subnets.
Goals
I want to install OpenShift with IPI on an on-premise platform (high priority for bare metal and vSphere) and I need to distribute my control plane and compute nodes across multiple subnets.
I want to use IPI automation but I will configure an external load balancer for the API and Ingress VIPs, instead of using the built-in keepalived/haproxy-based load balancer that come with the on-prem platforms.
Background, and strategic fit
Customers require using multiple logical availability zones to define their architecture and topology for their datacenter. OpenShift clusters are expected to fit in this architecture for the high availability and disaster recovery plans of their datacenters.
Customers want the benefits of IPI and automated installations (and avoid UPI) and at the same time when they expect high traffic in their workloads they will design their clusters with external load balancers that will have the VIPs of the OpenShift clusters.
Load balancers can distribute incoming traffic across multiple subnets, which is something our built-in load balancers aren't able to do and which represents a big limitation for the topologies customers are designing.
While this is possible with IPI AWS, this isn't available with on-premise platforms installed with IPI (for the control plane nodes specifically), and customers see this as a gap in OpenShift for on-premise platforms.
Functionalities per Epic
| Epic | Control Plane with Multiple Subnets | Compute with Multiple Subnets | Doesn't need external LB | Built-in LB |
|---|---|---|---|---|
| ✓ | ✓ | ✓ | ✓ | |
| ✓ | ✓ | ✓ | ✕ | |
| ✓ | ✓ | ✓ | ✓ | |
| ✓ | ✓ | ✓ | ✓ | |
| ✓ | ✓ | ✓ | ||
| ✓ | ✓ | ✓ | ✕ | |
| ✓ | ✓ | ✓ | ✕ | |
| ✓ | ✓ | ✓ | ✓ | |
| ✕ | ✓ | ✓ | ✓ | |
| ✕ | ✓ | ✓ | ✓ | |
| ✕ | ✓ | ✓ | ✓ |
Previous Work
Workers on separate subnets with IPI documentation
We can already deploy compute nodes on separate subnets by preventing the built-in LBs from running on the compute nodes. This is documented for bare metal only for the Remote Worker Nodes use case: https://docs.openshift.com/container-platform/4.11/installing/installing_bare_metal_ipi/ipi-install-installation-workflow.html#configure-network-components-to-run-on-the-control-plane_ipi-install-installation-workflow
This procedure works on vSphere too, albeit no QE CI and not documented.
External load balancer with IPI documentation
- Bare Metal: https://docs.openshift.com/container-platform/4.11/installing/installing_bare_metal_ipi/ipi-install-post-installation-configuration.html#nw-osp-configuring-external-load-balancer_ipi-install-post-installation-configuration
- vSphere: https://docs.openshift.com/container-platform/4.11/installing/installing_vsphere/installing-vsphere-installer-provisioned.html#nw-osp-configuring-external-load-balancer_installing-vsphere-installer-provisioned
Scenarios
- vSphere: I can define 3 or more networks in vSphere and distribute my masters and workers across them. I can configure an external load balancer for the VIPs.
- Bare metal: I can configure the IPI installer and the agent-based installer to place my control plane nodes and compute nodes on 3 or more subnets at installation time. I can configure an external load balancer for the VIPs.
Acceptance Criteria
- Can place compute nodes on multiple subnets with IPI installations
- Can place control plane nodes on multiple subnets with IPI installations
- Can configure external load balancers for clusters deployed with IPI with control plane and compute nodes on multiple subnets
- Can configure VIPs to in external load balancer routed to nodes on separate subnets and VLANs
- Documentation exists for all the above cases
Epic Goal
As an OpenShift installation admin I want to use the Assisted Installer, ZTP and IPI installation workflows to deploy a cluster that has remote worker nodes in subnets different from the local subnet, while my VIPs with the built-in load balancing services (haproxy/keepalived).
While this request is most common with OpenShift on bare metal, any platform using the ingress operator will benefit from this enhancement.
Customers using platform none run external load balancers and they won't need this, this is specific for platforms deployed via AI, ZTP and IPI.
Why is this important?
Customers and partners want to install remote worker nodes on day1. Due to the built-in network services we provide with Assisted Installer, ZTP and IPI that manage the VIP for ingress, we need to ensure that they remain in the local subnet where the VIPs are configured.
Previous Work
The bare metal IPI tam added a workflow that allows to place the VIPs in the masters. While this isn't an ideal solution, this is the only option documented:
Configuring network components to run on the control plane
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
- https://github.com/openshift/baremetal-runtimecfg/pull/224
- https://github.com/openshift/baremetal-runtimecfg/pull/207
- https://github.com/openshift/cluster-ingress-operator/pull/858
- https://github.com/openshift/machine-config-operator/pull/3540
- https://github.com/openshift/machine-config-operator/pull/3431
Epic Goal
As an OpenShift infrastructure owner I need to deploy OCP on OpenStack with the installer-provisioned infrastructure workflow and configure my own load balancers
Why is this important?
Customers want to use their own load balancers and IPI comes with built-in LBs based in keepalived and haproxy.
Scenarios
- A large deployment routed across multiple failure domains without stretched L2 networks, would require to dynamically route the control plane VIP traffic through load-balancers capable of living in multiple L2.
- Customers who want to use their existing LB appliances for the control plane.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- QE - must be testing a scenario where we disable the internal LB and setup an external LB and OCP deployment is running fine.
- Documentation - we need to document all the gotchas regarding this type of deployment, even the specifics about the load-balancer itself (routing policy, dynamic routing, etc)
- For Tech Preview, we won't require Fixed IPs. This is something targeted for 4.14.
Dependencies (internal and external)
- For GA, we'll need Fixed IPs, already WIP by vsphere: https://issues.redhat.com/browse/OCPBU-179
Previous Work:
vsphere has done the work already via https://issues.redhat.com/browse/SPLAT-409
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Test the feature with e2e.
We basically want to check that the Keepalived & HAproxy pods don't run when an external LB is being deployed.
The test have to run on all on-prem platforms, for all the jobs, so we can test the default LB as well.
This is needed once the API patch for External LB has merged.
OC mirror is GA product as of Openshift 4.11 .
The goal of this feature is to solve any future customer request for new features or capabilities in OC mirror
Overview
This epic is a simple tracker epic for the proposed work and analysis for 4.14 delivery
Goal:
As a cluster administrator, I want OpenShift to include a recent HAProxy version, so that I have the latest available performance and security fixes.
Description:
We should strive to follow upstream HAProxy releases by bumping the HAProxy version that we ship in OpenShift with every 4.y release, so that OpenShift benefits from upstream performance and security fixes, and so that we avoid large version-number jumps when an urgent fix necessitates bumping to the latest HAProxy release. This bump should happen as early as possible in the OpenShift release cycle, so as to maximize soak time.
For OpenShift 4.13, this means bumping to 2.6.
As a cluster administrator,
I want OpenShift to include a recent HAProxy version,
so that I have the latest available performance and security fixes.
We should strive to follow upstream HAProxy releases by bumping the HAProxy version that we ship in OpenShift with every 4.y release, so that OpenShift benefits from upstream performance and security fixes, and so that we avoid large version-number jumps when an urgent fix necessitates bumping to the latest HAProxy release. This bump should happen as early as possible in the OpenShift release cycle, so as to maximize soak time.
For OpenShift 4.14, this means bumping to 2.6.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Review the OVN Interconnect proposal, figure out the work that needs to be done in ovn-kubernetes to be able to move to this new OVN architecture.
Why is this important?
OVN IC will be the model used in Hypershift.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
OVN IC changes are in progress. A number of metrics have been either moved to a new prometheus subsystem or simply a subsystem change. See this metrics doc for details: https://github.com/martinkennelly/ovn-kubernetes-1/blob/c47ed896d6eef1e78844cc258deafd20502c348b/docs/metrics.md
Epic Goal
- Update all images that we ship with OpenShift to the latest upstream releases and libraries.
- Exact content of what needs to be updated will be determined as new images are released upstream, which is not known at the beginning of OCP development work. We don't know what new features will be included and should be tested and documented. Especially new CSI drivers releases may bring new, currently unknown features. We expect that the amount of work will be roughly the same as in the previous releases. Of course, QE or docs can reject an update if it's too close to deadline and/or looks too big.
Traditionally we did these updates as bugfixes, because we did them after the feature freeze (FF). Trying no-feature-freeze in 4.12. We will try to do as much as we can before FF, but we're quite sure something will slip past FF as usual.
Why is this important?
- We want to ship the latest software that contains new features and bugfixes.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
This includes ibm-vpc-node-label-updater!
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update all OCP and kubernetes libraries in storage operators to the appropriate version for OCP release.
This includes (but is not limited to):
- Kubernetes:
- client-go
- controller-runtime
- OCP:
- library-go
- openshift/api
- openshift/client-go
- operator-sdk
Operators:
- aws-ebs-csi-driver-operator
- aws-efs-csi-driver-operator
- azure-disk-csi-driver-operator
- azure-file-csi-driver-operator
- cinder-csi-driver-operator
- gcp-pd-csi-driver-operator
- gcp-filestore-csi-driver-operator
- manila-csi-driver-operator
- ovirt-csi-driver-operator
- vmware-vsphere-csi-driver-operator
- alibaba-disk-csi-driver-operator
- ibm-vpc-block-csi-driver-operator
- csi-driver-shared-resource-operator
- cluster-storage-operator
- csi-snapshot-controller-operator
- local-storage-operator
- vsphere-problem-detector
- https://github.com/openshift/alibaba-disk-csi-driver-operator/pull/44
- https://github.com/openshift/aws-ebs-csi-driver/pull/217
- https://github.com/openshift/aws-ebs-csi-driver-operator/pull/179
- https://github.com/openshift/azure-disk-csi-driver-operator/pull/66
- https://github.com/openshift/azure-file-csi-driver-operator/pull/46
- https://github.com/openshift/cluster-csi-snapshot-controller-operator/pull/140
- https://github.com/openshift/cluster-storage-operator/pull/333
- https://github.com/openshift/csi-driver-manila-operator/pull/167
- https://github.com/openshift/csi-driver-shared-resource-operator/pull/66
- https://github.com/openshift/gcp-pd-csi-driver-operator/pull/61
- https://github.com/openshift/ibm-vpc-block-csi-driver-operator/pull/51
- https://github.com/openshift/openstack-cinder-csi-driver-operator/pull/107
- https://github.com/openshift/ovirt-csi-driver-operator/pull/113
- https://github.com/openshift/vmware-vsphere-csi-driver-operator/pull/136
- https://github.com/openshift/vsphere-problem-detector/pull/99
Update all CSI sidecars to the latest upstream release from https://github.com/orgs/kubernetes-csi/repositories
- external-attacher
- external-provisioner
- external-resizer
- external-snapshotter
- node-driver-registrar
- livenessprobe
Corresponding downstream repos have `csi-` prefix, e.g. github.com/openshift/csi-external-attacher.
This includes update of VolumeSnapshot CRDs in cluster-csi-snapshot-controller- operator assets and client API in go.mod. I.e. copy all snapshot CRDs from upstream to the operator assets + go get -u github.com/kubernetes-csi/external-snapshotter/client/v6 in the operator repo.
- https://github.com/openshift/csi-external-attacher/pull/49
- https://github.com/openshift/csi-external-provisioner/pull/60
- https://github.com/openshift/csi-external-resizer/pull/136
- https://github.com/openshift/csi-external-snapshotter/pull/88
- https://github.com/openshift/csi-livenessprobe/pull/37
- https://github.com/openshift/csi-node-driver-registrar/pull/41
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned components should be running on Kubernetes 1.26
- This includes
- The cluster autoscaler (+operator)
- Machine API operator
- Machine API controllers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Machine API controllers for:
- Cloud Controller Manager Operator
- Cloud controller managers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Cloud controller managers for:
- Cluster Machine Approver
- Cluster API Actuator Package
- Control Plane Machine Set Operator
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.13 release, dependencies need to be updated to 1.26. This should be done by rebasing/updating as appropriate for the repository
Description of problem:
The Azure cloud controller manager is currently on kubernetes 1.25 dependencies and should be updated to 1.26
To align with the 4.13 release, dependencies need to be updated to 1.26. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.13 release, dependencies need to be updated to 1.26. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.13 release, dependencies need to be updated to 1.26. This should be done by rebasing/updating as appropriate for the repository
Epic Goal
- The goal of this epic is to upgrade all OpenShift and Kubernetes components that WMCO uses to v1.26 which will keep it on par with rest of the OpenShift components and the underlying cluster version.
Why is this important?
- Uncover any possible issues with the openshift/kubernetes rebase before it merges.
- WMCO continues using the latest kubernetes/OpenShift libraries and the kubelet, kube-proxy components.
- WMCO e2e CI jobs pass on each of the supported platform with the updated components.
Acceptance Criteria
- All stories in this epic must be completed.
- Go version is upgraded for WMCO and WMCB components.
- sdn-4.13 branch is created by the SDN team for using latest kube-proxy component.
- CI is running successfully with the upgraded components against the 4.13/master branch.
- Windows nodes must use the same kubelet version as the linux nodes in the cluster.
Dependencies (internal and external)
- ART team creating the go 1.20 image for upgrade to go 1.20.
- OpenShift/kubernetes repository downstream rebase PR merge.
- SDN team for creating the new sdn-4.13 branch.
Open questions::
- Do we need a checklist for future upgrades as an outcome of this epic?-> yes, updated below.
Done Checklist
- Step 1 - Upgrade go version to match rest of the OpenShift and Kubernetes upgraded components.
- Step 2 - Upgrade Kubernetes client and controller-runtime dependencies (can be done in parallel with step 3)
- Step 3 - Upgrade OpenShift client and API dependencies
- Step 4 - Update kubelet and kube-proxy submodules in WMCO repository
- Step 5 - Engage SDN team to create new branch for kube-proxy submodule (can be done in parallel with above steps)
- Step 6 - CI is running successfully with the upgraded components and libraries against the master branch.
User or Developer story
As a WMCO developer, I want the kube-proxy submodule to be pointing to the sdn-4.13-kubernetes-1.26.0 on the openshift/kuberenetes repository so we can pickup the latest kube rebase updates.
Engineering Details
- Update the submodules using hack/submodule.sh script
Acceptance Criteria
- WMCO submodule for kube-proxy should pickup the latest updates for 1.26 rebase.
- Replace deprecated klog flags like --log-dir and --logstostderr in kube-proxy service command with kube-log-runner options.
- Update must-gather log collection script
This Epic is here to track the rebase we need to do when kube 1.26 is GA https://www.kubernetes.dev/resources/release/
https://docs.google.com/document/d/1h1XsEt1Iug-W9JRheQas7YRsUJ_NQ8ghEMVmOZ4X-0s/edit --> this is the link for rebase help
Rebase Openshift SDN to use Kube 1.26
We have a RFE where customer is asking option to run must-gather in its own name space .
Looks like we already have they option but its hidden . The request from customer is un hide the option
https://github.com/openshift/oc/blob/master/pkg/cli/admin/mustgather/mustgather.go#L158-L160
Provide a visible flag to run must-gather in its own name space. Originally an experimental flag.
Feature Overview
- Azure is sunsetting the Azure Active Directory Graph API on June 2022. The OpenShift installer and the in-cluster cloud-credential-operator (CCO) make use of this API. The replacement api is the Microsoft Graph API. Microsoft has not committed to providing a production-ready Golang SDK for the new Microsoft Graph API before June 2022.
Goals
- Replace the existing AD Graph API for Azure we use for the Installer and Cluster components with the new Microsoft Authentication Library and Microsoft Graph API
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
This description is based on the Google Doc by Rafael Fonseca dos Santos : https://docs.google.com/document/d/1yQt8sbknSmF_hriHyMAKPiztSoRIvntSX9i1wtObSYs
Microsoft is deprecating two APIs. The AD Graph API used by Installer destroy code and also used by the CCO to mint credentials. ADAL is also going EOL. ADAL is used by the installer and all cluster components that authenticate to Azure:
Azure Active Directory Authentication Library (ADAL) Retirement **
ADAL end-of-life is December 31, 2022. While ADAL apps may continue to work, no support or security fixes will be provided past end-of-life. In addition, there are no planned ADAL releases planned prior to end-of-life for features or planned support for new platform versions. We recommend prioritizing migration to Microsoft Authentication Library (MSAL).
Azure AD Graph API
Azure AD Graph will continue to function until June 30, 2023. This will be three years after the initial deprecation[ announcement.|https://techcommunity.microsoft.com/t5/microsoft-entra-azure-ad-blog/update-your-applications-to-use-microsoft-authentication-library/ba-p/1257363] Based on Azure deprecation[ guidelines|https://docs.microsoft.com/en-us/lifecycle/], we reserve the right to retire Azure AD Graph at any time after June 30, 2023, without advance notice. Though we reserve the right to turn it off after June 30, 2023, we want to ensure all customers migrate off and discourage applications from taking production dependencies on Azure AD Graph. Investments in new features and functionalities will only be made in[ Microsoft Graph|https://docs.microsoft.com/en-us/graph/overview]. Going forward, we will continue to support Azure AD Graph with security-related fixes. We recommend prioritizing migration to Microsoft Graph.
Takeaways / considerations
- The new Microsoft Authentication Library (MSAL) that we will migrate to requires a new API permission: Graph API ReadWrite.OwnedBy (relevant [slack thread|https://coreos.slack.com/archives/C68TNFWA2/p1644009342019649?thread_ts=1644008944.461989&cid=C68TNFWA2)]. The old ReadWrite.OwnedBy API permissions could be removed to test as well.
- Mint mode was discontinued in Azure, but clusters may exist that have cluster-created service principals from before the retirement. In that case, the service principals will either need to be deleted manually or with a newer version of the installer that has support for MSAL.
- Migration to the new API (see Migration Guide below) entails using the azidentity package. The azidentity package is intended for use with V2 versions of the azure sdk for go, an adapter is required if the SDK packages have not been upgraded to V2, which is the case for our codebase. Only recently have V2 packages become stable. See references below.
- Furthermore, azidentity is tied to Go 1.18, which affects our ability to backport prior to 4.11 or earlier versions.
- Another consideration for backporting is that ADAL is used by the in-tree Azure cloud provider. These legacy cloud providers are generally closed for development, so an upstream patch seems unlikely, as does carrying a patch.
- A path forward for the Azure cloud provider must be determined. Due to the legacy cloud providers freeze mentioned prior to this, it seems that the best path forward is for the out-of-tree provider and CCM, scheduled for 4.14:
OCPCLOUD-1128, but even the upstream out-of-tree provider has not migrated yet: https://github.com/kubernetes-sigs/cloud-provider-azure/issues/430 - AD FS (Active Directory Federation Services) are not yet supported in the Azure SDK for Go: https://github.com/AzureAD/microsoft-authentication-library-for-go/issues/31. There is a very limited user base for AD FS, but exactly how many users is unknown at this moment. Switching to the new API would break these users, so the best approach known at this moment would be to advise this extremely limited number of users to maintain the last supported version of OpenShift that uses ADAL until Microsoft introduces AD FS support. We do not document support for AD FS.
References:
- Migration Guide
- Azure SDK stability
- Azure SDK for Go MSAL Feature Tracker
- https://docs.google.com/document/d/1hvtkUCM8rQn2KYcv1Npp7on7yXdQYDcM1qG36WK6OaA/edit?usp=sharing
- James Russel's guide to writing AD Apps: https://docs.google.com/document/d/1ru57IwMJYd97rukZgjuIgNZidADxQU72al2qbj1PHas/edit?usp=sharing
ADAL is EOL. Update component to use azidentity.
ADAL is being deprecated. Update to use azidentity.
Feature Overview
Upstream Kuberenetes is following other SIGs by moving it's intree cloud providers to an out of tree plugin format at some point in a future Kubernetes release. OpenShift needs to be ready to action this change
Goals
- Common plugin framework to aid development of out of tree cloud providers
- Out of tree providers for AWS, Azure, GCP, vSphere, etc
- Possible certification process for 3rd Party out of tree cloud providers
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| Plugin framework | Yes | |
| AWS out of tree provider | Yes | |
| Other Cloud provider plugins | No | |
Out of Scope
n/a
Background, and strategic fit
Assumptions
Customer Considerations
Documentation Considerations
- Target audience: cluster admins
- Updated content: update docs to clearly show how to install and use the new providers.
Epic Goal
- Implement an out of tree cloud provider for VMware
Why is this important?
- The community is moving to out of tree cloud providers, we need to get ahead of this trend so we are ready when the switch over occurs for this functionality
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Background
The vSphere CCM has a new YAML based cloud config format. We should build a config transformer into CCMO to load the old ini file, drop any storage/unrelated entries, and convert the existing schema to the new YAML schema, before storing it within the CCM namespace.
This will allow us to use the new features from the YAML config and avoid the old, deprecated ini format.
Steps
- Sync up with SPLAT and make sure this is the right way to go,
- Make sure not to introduce dependency on vSphere provider itself
- Evaluate existing configuration and new configuration and plan transformation.
- Implement transformer to transform ini to yaml
- Ensure old storage configuration is dropped
Stakeholders
- Cluster Infra
- SPLAT
Definition of Done
- Configuration for the vSphere CCM in the cloud controller manager namespace is in the new YAML format
- Docs
- N/A
- Testing
- Make sure to test the conversion
- What happens if the existing config is YAML not ini
Background
To make the CCM GA, we need to update the switch case in library go to make sure the vSphere CCM is always considered external.
We then need to update the vendor in KCMO, CCMO, KASO and MCO.
Steps
- Create a PR for updating library go
- Create PRs for updating the vendor in dependent repos
- Leverage an engineer with merge right (eg David Eads) to merge the library go, KCMO and CCMO changes simultaneously
- Merge KASO and MCO changes
Stakeholders
- Cluster Infra
- SPLAT
Definition of Done
- vSphere CCM is enabled by default
- Docs
- N/A
- Testing
- <Explain testing that will be added>
Feature Overview
- As an infrastructure owner, I want a repeatable method to quickly deploy the initial OpenShift cluster.
- As an infrastructure owner, I want to install the first (management, hub, “cluster 0”) cluster to manage other (standalone, hub, spoke, hub of hubs) clusters.
Goals
- Enable customers and partners to successfully deploy a single “first” cluster in disconnected, on-premises settings
Requirements
4.11 MVP Requirements
- Customers and partners needs to be able to download the installer
- Enable customers and partners to deploy a single “first” cluster (cluster 0) using single node, compact, or highly available topologies in disconnected, on-premises settings
- Installer must support advanced network settings such as static IP assignments, VLANs and NIC bonding for on-premises metal use cases, as well as DHCP and PXE provisioning environments.
- Installer needs to support automation, including integration with third-party deployment tools, as well as user-driven deployments.
- In the MVP automation has higher priority than interactive, user-driven deployments.
- For bare metal deployments, we cannot assume that users will provide us the credentials to manage hosts via their BMCs.
- Installer should prioritize support for platforms None, baremetal, and VMware.
- The installer will focus on a single version of OpenShift, and a different build artifact will be produced for each different version.
- The installer must not depend on a connected registry; however, the installer can optionally use a previously mirrored registry within the disconnected environment.
Use Cases
- As a Telco partner engineer (Site Engineer, Specialist, Field Engineer), I want to deploy an OpenShift cluster in production with limited or no additional hardware and don’t intend to deploy more OpenShift clusters [Isolated edge experience].
- As a Enterprise infrastructure owner, I want to manage the lifecycle of multiple clusters in 1 or more sites by first installing the first (management, hub, “cluster 0”) cluster to manage other (standalone, hub, spoke, hub of hubs) clusters [Cluster before your cluster].
- As a Partner, I want to package OpenShift for large scale and/or distributed topology with my own software and/or hardware solution.
- As a large enterprise customer or Service Provider, I want to install a “HyperShift Tugboat” OpenShift cluster in order to offer a hosted OpenShift control plane at scale to my consumers (DevOps Engineers, tenants) that allows for fleet-level provisioning for low CAPEX and OPEX, much like AKS or GKE [Hypershift].
- As a new, novice to intermediate user (Enterprise Admin/Consumer, Telco Partner integrator, RH Solution Architect), I want to quickly deploy a small OpenShift cluster for Poc/Demo/Research purposes.
Questions to answer…
Out of Scope
Out of scope use cases (that are part of the Kubeframe/factory project):
- As a Partner (OEMs, ISVs), I want to install and pre-configure OpenShift with my hardware/software in my disconnected factory, while allowing further (minimal) reconfiguration of a subset of capabilities later at a different site by different set of users (end customer) [Embedded OpenShift].
- As an Infrastructure Admin at an Enterprise customer with multiple remote sites, I want to pre-provision OpenShift centrally prior to shipping and activating the clusters in remote sites.
Background, and strategic fit
- This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- The user has only access to the target nodes that will form the cluster and will boot them with the image presented locally via a USB stick. This scenario is common in sites with restricted access such as government infra where only users with security clearance can interact with the installation, where software is allowed to enter in the premises (in a USB, DVD, SD card, etc.) but never allowed to come back out. Users can't enter supporting devices such as laptops or phones.
- The user has access to the target nodes remotely to their BMCs (e.g. iDrac, iLo) and can map an image as virtual media from their computer. This scenario is common in data centers where the customer provides network access to the BMCs of the target nodes.
- We cannot assume that we will have access to a computer to run an installer or installer helper software.
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
References
Epic Goal
- Ensure the Agent Based Installer - https://github.com/openshift/installer/tree/agent-installer - is enabled for aarch64 from launch.
Why is this important?
- The Agent Based Installer is a new install path targeting fully disconnected installs. We should be looking at adding support for ARM in all install paths to ensure our customers can deploy to disconnected environments.
- We want to start having new projects/products launch with support for ARM by default.
Scenarios
1. …
Acceptance Criteria
- The Agent Installer launches with aarch64 support
- The Agent installer has QE completed & CI for aarch64
Dependencies (internal and external)
1. …
Previous Work (Optional):
1.https://issues.redhat.com/browse/ARMOCP-346
Open questions::
1. …
Done Checklist
- CI - For new features (non-enablement), existing Multi-Arch CI jobs are not broken by the Epic
- Release Enablement: <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR orf GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - If the Epic is adding a new stream, downstream build attached to advisory: <link to errata>
- QE - Test plans in Test Plan tracking software (e.g. Polarion, RQM, etc.): <link or reference to the Test Plan>
- QE - Automated tests merged: <link or reference to automated tests>
- QE - QE to verify documentation when testing
- DOC - Downstream documentation merged: <link to meaningful PR>
- All the stories, tasks, sub-tasks and bugs that belong to this epic need to have been completed and indicated by a status of 'Done'.
As an OCP admistrator, I would like to deploy OCP on arm64 BM with agent installer
Acceptance Criteria
Dev:
- Ensure openshift-installer creates an arm64 agent.iso
- Ensure openshift-installer creates the correct ignition config and supporting files for assisted-api
- Ensure assisted-api can install
Jira Admin
- Additional Jira tickets created (if needed)
QE
- Understand if QE is needed for agent installer (as this Epic is currently a TP)
Docs:
- Understand if ARM documentation needs to be updated (as there is currently no x86 documentation)
Agent Installer
- Investigate if Heterogeneous clusters are feasible for Agent Installer
- Proposed title of this feature request:
Update ETCD datastore encryption to use AES-GCM instead of AES-CBC
2. What is the nature and description of the request?
The current ETCD datastore encryption solution uses the aes-cbc cipher. This cipher is now considered "weak" and is susceptible to padding oracle attack. Upstream recommends using the AES-GCM cipher. AES-GCM will require automation to rotate secrets for every 200k writes.
The cipher used is hard coded.
3. Why is this needed? (List the business requirements here).
Security conscious customers will not accept the presence and use of weak ciphers in an OpenShift cluster. Continuing to use the AES-CBC cipher will create friction in sales and, for existing customers, may result in OpenShift being blocked from being deployed in production.
4. List any affected packages or components.
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
The Kube APIserver is used to set the encryption of data stored in etcd. See https://docs.openshift.com/container-platform/4.11/security/encrypting-etcd.html
Today with OpenShift 4.11 or earlier, only aescbc is allowed as the encryption field type.
RFE-3095 is asking that aesgcm (which is an updated and more recent type) be supported. Furthermore RFE-3338 is asking for more customizability which brings us to how we have implemented cipher customzation with tlsSecurityProfile. See https://docs.openshift.com/container-platform/4.11/security/tls-security-profiles.html
Why is this important? (mandatory)
AES-CBC is considered as a weak cipher
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
The new aesgcm encryption provider was added in 4.13 as techpreview, but as part of https://issues.redhat.com/browse/API-1509, the feature needs to be GA in OCP 4.13.
The new aesgcm encryption provider was added in 4.13 as techpreview, but as part of https://issues.redhat.com/browse/API-1509, the feature needs to be GA in OCP 4.13.
The new aesgcm encryption provider was added in 4.13 as techpreview, but as part of https://issues.redhat.com/browse/API-1509, the feature needs to be GA in OCP 4.13.
AES-GCM encryption was enabled in cluster-openshift-apiserver-operator and cluster-openshift-autenthication-operator, but not in the cluster-kube-apiserver-operator. When trying to enable aesgcm encryption in the apiserver config, the kas-operator will produce an error saying that the aesgcm provider is not supported.
The new aesgcm encryption provider was added in 4.13 as techpreview, but as part of https://issues.redhat.com/browse/API-1509, the feature needs to be GA in OCP 4.13.
Feature Overview
- Extend OpenShift on IBM Cloud integration with additional features to pair the capabilities offered for this provider integration to the ones available in other cloud platforms
Goals
- Extend the existing features while deploying OpenShift on IBM Cloud
Background, and strategic fit
This top level feature is going to be used as a placeholder for the IBM team who is working on new features for this integration in an effort to keep in sync their existing internal backlog with the corresponding Features/Epics in Red Hat's Jira.
Epic Goal
- Make machine phases public so they can be used by controller packages.
Why is this important?
- Recent IBM Cloud VPC provisioning fix in MAPI code manipulated the machine phases. The MAO phase constants were dup'd in the MAPI code since we wanted to minimize blast radius of provisioning fix. Making the phases public in MAO would be a cleaner approach and allow MAPI to use them directly (and not duplicate).
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Open questions::
- ?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Make machine phases public so they can be used by controller packages (https://github.com/openshift/machine-api-operator/blob/6397450f3464ffb875f43011ed8ad7428e50f881/pkg/controller/machine/controller.go#L75-L92)
Epic Goal
With this BYON support:
- shared resources (VPC, subnets) can be placed in the resource group specified by the `networkResourceGroupName` install config parameter.
- installer provisioned cluster resources will be placed in the resource group specified by the `resourceGroupName` install config parameter.
- `networkResourceGroupName` is a required parameter for the BYON scenario
- `resourceGroupName` is an optional parameter
Why is this important?
- This will allow customers (using IBM Cloud VPC BYON support) to organize pre-created / shared resources (VPC, subnets) in a resource group separate from installer provisioned cluster resources.
Scenarios
`networkResourceGroupName` NOT specified ==> non-BYON install scenario
- if `resourceGroupName` is specified, then ALL installer provisioned resources (VPC, subnets, cluster) will be placed in specified resource group (resource group must exist)
- if `resourceGroupName` is NOT specified, then ALL installer provisioned resources (VPC, subnets, cluster) will be placed in a resource group created during the install process
`networkResourceGroupName` specified ==> BYON install scenario (required for BYON scenario)
- `networkResourceGroupName` must contain pre-created/shared resources (VPC, subnets)
- if `resourceGroupName` is specified, then all installer provisioned cluster resources will be placed in specified resource group (resource group must exist)
- if `resourceGroupName` is NOT specified, then all installer provisioned cluster resources will be placed in a resource group created during the install process
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Add support for a NetworkResourceGroup in the MachineProviderSpec, and the logic for performing lookups during machine creation for IBM Cloud.
Goal: Control plane nodes in the cluster can be scaled up or down, lost and recovered, with no more importance or special procedure than that of a data plane node.
Problem: There is a lengthy special procedure to recover from a failed control plane node (or majority of nodes) and to add new control plane nodes.
Why is this important: Increased operational simplicity and scale flexibility of the cluster’s control plane deployment.
See slack working group: #wg-ctrl-plane-resize
Epic Goal
- To add an E2E suite of presubmit and periodic tests for the ControlPlaneMachineSet project
- To improve the integration tests within the ControlPlaneMachineSet repository to cover cases we aren't testing in E2E
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Background
We expect that a generated CPMS should be able to be activated without causing a rollout, that is, the replicas should be equal to the updated replicas.
This should run after OCPCLOUD-1742 in an ordered container
Steps
- Create a test that:
- Checks the CPMS status is as expected
- Activates the CPMS
- Checks that no new machines are created
- Checks that all cluster operators are stable
Stakeholders
- Cluster Infra
Definition of Done
- This is running in an ordered container with the
OCPCLOUD-1742test
- Docs
- N/A
- Testing
- N/A
Background
When Inactive, the CPMS should be updated by the generator controller where applicable.
We should test that we can update the spec of the newest machine, observe the CPMS get updated, and then set it back, and observe the update again.
Steps
- Create a test that:
- Checks the CPMS is inactive
- Modifies the newest, alphabetically last instance to trigger the CPMS to be regenerated
- Check that the CPMS is regenerated
- Check that the CPMS reports 1 updated machine (the other two will need update)
- Reset the Machines spec to original
- Check that the CPMS is regenerated
- Check that the CPMS reports replicas == updatedReplicas
Stakeholders
- Cluster Infra
Definition of Done
- This test is run in an ordered container with
OCPCLOUD-1742
- Docs
- N/A
- Testing
- N/A
Background
Even if a machine does not need an update, the CPMS should replace it when it's been marked for deletion.
Steps
- Create an integration test that:
- Creates a CPMS and 3 control plane machines
- Add finalizers to the machines
- Ensure the CPMS status is as expected
- Delete one of the machines
- Check the CPMS creates a replacement
Stakeholders
- Cluster Infra
Definition of Done
- Integration test runs in the CPMS controllers package
- Docs
- N/A
- Testing
- N/A
Background
We test that we can replace work machines behind a proxy configuration, but we do not test control plane machines.
It would be good to check that the control plane replacement is not going to be disrupted by the proxy
Motivation
We want to make sure that the latency added by having a proxy between resources does not affect replacing control plane machines
Steps
- Create a test that:
- Checks the cluster operators are all stable/waits for them to stabilise
- Creates a cluster wide proxy
- Checks the cluster operators are all stable/waits for them to stabilise
- Modify master-0's spec to cause it to be update
- Checks that the CPMS creates a new instance
- Checks naming of the new machine
- Checks the old machine isn't marked for deletion while the new Machine's phase is not Running
- Waits until the replacement is complete, ie CPMS status reports replicas == updatedReplicas
- Waits until cluster operators stabilise again
- Remove cluster wide proxy
- Wait until cluster operators stabilise again
Stakeholders
- <Who is interested in this/where did they request this>
Definition of Done
- <Add items that need to be completed for this card>
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
Background
We want to make sure that if new failure domains are added, the CPMS rebalances the machines.
This should be automatic with the RollingUpdate strategy.
Steps
- Create an integration test that:
- Creates an Inactive CPMS and 3 machines across 2 failure domains
- Check the CPMS thinks one machine needs an update
- Activate the CPMS
- Check the CPMS creates a new Machine and deletes an old one
- The CPMS should now report all machines are up to date.
Stakeholders
- Cluster Infra
Definition of Done
- Integration test is running in CPMS controllers package
- Docs
- N/A
- Testing
- N/A
Background
Remove e2e common test suite from the control plane machine set E2Es, and adapt presubmit and periodic test setups and teardowns to account for this change.
For more context see this [GitHub conversation](https://github.com/openshift/cluster-control-plane-machine-set-operator/pull/147#discussion_r1035912969)
Definition of Done
- <Add items that need to be completed for this card>
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
Background
To validate the deletion process of the CPMS, we need to create a test that deletes the CPMS and checks that the CPMS eventually goes away (it may come back with a different UID), and that when it goes away, there are no owner references on the control plane machines, there are still 3 control plane machines, and the cluster operators are all stable
Motivation
This is already tested with an integration test, but we should also check this in E2E as it is cheap (assuming it works, no machine changes) and may pick up weird interactions with other components.
Eg in integration we have no GC running.
Steps
- Create a test that:
- Checks that/waits until all clusteroperators are stable
- Checks the ControlPlaneMachineSet is as expected
- Deletes the ControlPlaneMachineSet
- Waits for the CPMS to be removed/ for the UID to change
- Checks that (if present) the new CPMS is inactive
- Checks that all control plane machines are still running
- Checks that all control plane machines have no owner references
- Checks that all control plane machines do not have a deletion timestamp
- Checks that all clusteroperators are stable
Stakeholders
- Cluster Infra
Definition of Done
- Test is merged and running as a presubmit and periodic test
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
Background
For clusters where this appropriate, check that a new CPMS is generated and that it is as expected, ie replicas == updatedReplicas, no errors reported
This will need to be tied to OCPCLOUD-1741 which removes the CPMS, we can run them in an ordered container together
Steps
- Create a test that:
- Checks the CPMS status of the newly created CPMS is as expected
Stakeholders
- Cluster Infra
Definition of Done
- Test is running in an ordered container with
OCPCLOUD-1741
- Docs
- N/A
- Testing
- N/A
Background
We expect once active for the CPMS to own the master machines.
We can check this in tandem with the other activation test OCPCLOUD-1746
Steps
- Create a test that:
- Checks, when activated, that a the Control Plane Machines get owner references
- Check that the Machines do not get garbage collected
- Check all cluster operators are stable
Stakeholders
- Cluster Infra
Definition of Done
- Test is running in an ordered container with
OCPCLOUD-1746
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
Description/Acceptance Criteria:
- Add RBAC for the console-operator so it can GET/LIST/WATCH OLMConfig cluster config. The RBAC should be added to console-operator cluster-role rules
- The console operator should watch the spec.features.disableCopiedCSVs property of the OLM cluster config. When this property is true, the console-config should be updated "clusterInfo.copiedCSVsDisabled" field accordingly, and rollout a new version of console.
Problem
As an Operator author, I want to be able to specify where my Operators to run (on infra, master, or worker nodes) so my end-users can easily install them through OperatorHub in the console without special setups.
Acceptance Criteria
- Operators can assign a Namespace object template in YAML to the provided `operatorframework.io/suggested-namespace-template` CSV annotation to specify how the suggested namespace is being created by the console during the installation.
- During the installation, UI will:
- populate the "Installed Namespace" dropdown using the `metadata.name` field in the attached Namespace YAML manifest
- create the namespace object using the Namespace YAML manifest being assigned to `operatorframework.io/suggested-namespace-template` CSV annotation.
- If end-users change the "Installed Namespace" dropdown to another namespace, the UI shows warning messages so users know the user-selected namespace might not have all the correct setup recommended by the Operator and it might not run correctly/successfully.
- If both `suggested-namespace` and `suggested-namespace-template` annotation are present in CSV template should take precedence.
Details
The console adds support to take the value field of a CSV annotation as the Namespace YAML template to create a Namespace object for installing the Operator.
CSV Annotation Example
apiVersion: v1
kind: Namespace
metadata:
annotations:
openshift.io/node-selector: ""
name: my-operator-namespace
Key Objective
Providing our customers with a single simplified User Experience(Hybrid Cloud Console)that is extensible, can run locally or in the cloud, and is capable of managing the fleet to deep diving into a single cluster.
Why customers want this?
- Single interface to accomplish their tasks
- Consistent UX and patterns
- Easily accessible: One URL, one set of credentials
Why we want this?
- Shared code - improve the velocity of both teams and most importantly ensure consistency of the experience at the code level
- Pre-built PF4 components
- Accessibility & i18n
- Remove barriers for enabling ACM
Phase 2 Goal: Productization of the united Console
- Enable user to quickly change context from fleet view to single cluster view
- Add Cluster selector with “All Cluster” Option. “All Cluster” = ACM
- Shared SSO across the fleet
- Hub OCP Console can connect to remote clusters API
- When ACM Installed the user starts from the fleet overview aka “All Clusters”
- Share UX between views
- ACM Search —> resource list across fleet -> resource details that are consistent with single cluster details view
- Add Cluster List to OCP —> Create Cluster
We need a way to show metrics for workloads running on spoke clusters. This depends on ACM-876, which lets the console discover the monitoring endpoints.
Console operator must discover the external URLs for monitoringConsole operator must pass the URLs and CA files as part of the cluster config to the console backendConsole backend must set up proxies for each endpoint (as it does for the API server endpoints)Console frontend must include the cluster in metrics requests
Open Issues:
We will depend on ACM to create a route on each spoke cluster for the prometheus tenancy service, which is required for metrics for normal users.
Openshift console backend should proxy managed cluster monitoring requests through the MCE cluster proxy addon to prometheus services on the managed cluster. This depends on https://issues.redhat.com/browse/ACM-1188
The console only displays list of `Pending` or `Failed` plugins the Cluster Overview Dynamic Plugin Status card item popover when one or more dynamic plugins has a status of `Pending` or `Failed` (added in https://github.com/openshift/console/pull/11664).
https://issues.redhat.com/browse/HAC-1615 will add additional information regarding why a plugin has a `Failed` status.
The aforementioned popover should be updated to include this additional `Failed` information once it is available.
Additionally, the `Console plugins` tab (e.g., k8s/cluster/operator.openshift.io~v1~Console/cluster/console-plugins) only displays a list of `ConsolePlugin` resources augmented with `Version` and `Description` data culled from `Loaded` dynamic plugins. This page should actually show dynamic plugins with a `status` of `Pending` or `Failed` as well, either through the addition of a `status` column or additional tables (design TBD with UXD). The aforementioned additional information regarding why a plugin has `Failed` should also be added to the page as well.
Acceptance Criteria: Update the popup on the dashboard and update notification drawer with failure reason.
Epic Goal
- Add tech-preview support to install OpenShift on OpenStack with multiple failure domains.
Why is this important?
- Multiple (large) customers are requesting this configuration and installation type to provide a higher level of high availability.
- This could be a blocker for https://issues.redhat.com/browse/OSASINFRA-2999 even though technically that feature should be possible without this
Scenarios
- Spread the control plane across 3 domains (each domain has a defined storage / network / compute configuration)
- Indirectly we'll inherit from the features proposed by https://issues.redhat.com/browse/OCPCLOUD-1372
-
- Automatically add extra node(s) to the control plane
- Remove node(s) from the control plane
- Recover from a lost node incident
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- https://issues.redhat.com/browse/OCPCLOUD-1372 to be finished and delivered in 4.12
Previous Work (Optional):
Open questions::
none for now.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Enhancement - https://github.com/openshift/enhancements/pull/1167
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Description of problem:
This is for backporting the feature to 4.13 past Feature freeze, with the approval of Program management.
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1. 2. 3.
Actual results:
Expected results:
Additional info:
1. Proposed title of this feature request
BYOK encrypts root vols AND default storageclass
2. What is the nature and description of the request?
User story
As a customer spinning up managed OpenShift clusters, if I pass a custom AWS KMS key to the installer, I expect it (installer and cluster-storage-operator) to not only encrypt the root volumes for the nodes in the cluster, but also be applied to encrypt the first/default (gp2 in current case) StorageClass, so that my assumptions around passing a custom key are met.
In current state, if I pass a KMS key to the installer, only root volumes are encrypted with it, and the default AWS managed key is used for the default StorageClass.
Perhaps this could be offered as a flag to set in the installer to further pass the key to the storage class, or not.
3. Why does the customer need this? (List the business requirements here)
To satisfy that customers wish to encrypt their owned volumes with their selected key instead of the AWS default account key, by accident.
4. List any affected packages or components.
- uncertain.
Note: this implementation should take effect on AWS, GCP and Azure (any cloud provider) equally.
User Story:
As a cluster admin, I want OCP to provision new volumes with my custom encryption key that I specified during cluster installation in install-config.yaml so all OCP assets (PVs, VMs & their root disks) use the same encryption key.
Acceptance Criteria:
Description of criteria:
- Check that dynamically provisioned PVs use the key specified in install-config.yaml
- Check that the key can be changed in TBD API and all volumes newly provisioned after the key change use the new key. (Exact API is not defined yet, probably a new field in `Infrastructure`, calling it TBD API now).
(optional) Out of Scope:
Re-encryption of existing PVs with a new key. Only newly provisioned PVs will use the new key.
Engineering Details:
Enhancement (incl. TBD API with encryption key reference) will be provided as part of https://issues.redhat.com/browse/CORS-2080.
"Raw meat" of this story is translation of the key reference in TBD API to StorageClass.Parameters. Azure Disk CSi driver operator should update both the StorageClass it manages (managed-csi) with:
Parameters:
diskEncryptionSetID: /subscriptions/<subs-id>/resourceGroups/<rg-name>/providers/Microsoft.Compute/diskEncryptionSets/<diskEncryptionSet-name>
Upstream docs: https://github.com/kubernetes-sigs/azuredisk-csi-driver/blob/master/docs/driver-parameters.md (CreateVolume parameters == StorageClass.Parameters)
User Story:
As a cluster admin, I want OCP to provision new volumes with my custom encryption key that I specified during cluster installation in install-config.yaml so all OCP assets (PVs, VMs & their root disks) use the same encryption key.
Acceptance Criteria:
Description of criteria:
- Check that dynamically provisioned PVs use the key specified in install-config.yaml
- Check that the key can be changed in TBD API and all volumes newly provisioned after the key change use the new key. (Exact API is not defined yet, probably a new field in `Infrastructure`, calling it TBD API now).
(optional) Out of Scope:
Re-encryption of existing PVs with a new key. Only newly provisioned PVs will use the new key.
Engineering Details:
Enhancement (incl. TBD API with encryption key reference) will be provided as part of https://issues.redhat.com/browse/CORS-2080.
"Raw meat" of this story is translation of the key reference in TBD API to StorageClass.Parameters. GCP PD CSi driver operator should update both StorageClasses that it manages (standard-csi, standard-ssd) with:
Parameters:
disk-encryption-kms-key: projects/<KEY_PROJECT_ID>/locations/<LOCATION>/keyRings/<RING_NAME>/cryptoKeys/<KEY_NAME>
Upstream docs: https://github.com/kubernetes-sigs/gcp-compute-persistent-disk-csi-driver#createvolume-parameters (CreateVolume parameters == StorageClass.Parameters)
User Story:
As a cluster admin, I want OCP to provision new volumes with my custom encryption key that I specified during cluster installation in install-config.yaml so all OCP assets (PVs, VMs & their root disks) use the same encryption key.
Acceptance Criteria:
Description of criteria:
- Check that dynamically provisioned PVs use the key specified in install-config.yaml
- Check that the key can be changed in TBD API and all volumes newly provisioned after the key change use the new key. (Exact API is not defined yet, probably a new field in `Infrastructure`, calling it TBD API now).
(optional) Out of Scope:
Re-encryption of existing PVs with a new key. Only newly provisioned PVs will use the new key.
Engineering Details:
Enhancement (incl. TBD API with encryption key reference) will be provided as part of https://issues.redhat.com/browse/CORS-2080.
"Raw meat" of this story is translation of the key reference in TBD API to StorageClass.Parameters. AWS EBS CSi driver operator should update both the StorageClass it manages (managed-csi) with:
Parameters:
encrypted: "true"
kmsKeyId: "arn:aws:kms:us-east-1:012345678910:key/abcd1234-a123-456a-a12b-a123b4cd56ef"
Upstream docs: https://github.com/kubernetes-sigs/aws-ebs-csi-driver/blob/master/docs/parameters.md
Feature Goal: Unify the management of cluster ingress with a common, open, expressive, and extensible API.
Why is this Important? Gateway API is the evolution of upstream Kubernetes Ingress APIs. The upstream project is part of Kubernetes, working under SIG-NETWORK. OpenShift is contributing to the development, building a leadership position, and preparing OpenShift to support Gateway API, with Istio as our supported implementation.
The plug-able nature of the implementation of Gateway API enables support for additional and optional 3rd-party Ingress technologies.
Functional Requirements
- Add support for Istio as a Gateway API implementation.
NE-1105Management by an operator (possibly cluster-ingress-operator, OSSM operator, or a new operator)- Feature parity with OpenShift Router, where appropriate.
- Performance parity evaluation of Envoy and HAProxy.
- NE-1102 Add oc command line support for Gateway API objects
- NE-1103 Evaluate idling support for Gateway API
- Avoid conflict with partner solutions (such as F5).
- Provide a solution that partners could integrate with (reduce dependencies on Istio by assuming plugins)
Avoid conflict with integrations (such as GKE) for hybrid cloud use cases.
- NE-1106 Advanced routing capabilities currently unavailable in OCP.
- More powerful path-based routing.
- Header-based routing
Traffic mirroringTraffic splitting (single and multi cluster)- Other features, based on time constraints
- Add Gateway API support with OSSM service mesh.
Add Gateway API support for serverless.
Non-Functional Requirements:
NE-1034Installation- NE-1110 Documentation
- Release technical enablement
- OCP CI integration
- Continued upstream development to mature Gateway API and Istio support for the same.
Open Questions:
Integration with HAProxy?- Gateway is more than Ingress 2.0, how do we align with other platform components such as serverless and service mesh to ensure we're providing a complete solution?
Documentation Considerations:
- Explain the resource model
- Explain roles and how they align to Gateway API resources
- Explain the extension points and provide extension point examples.
- Xref upstream docs.
User Story: As a cluster admin, I want to create a gatewayclass and a gateway, and OpenShift should configure Istio/Envoy with an LB and DNS, so that traffic can reach httproutes attached to the gateway.
The operator will be one of these (or some combination):
- cluster-ingress-operator
- OSSM operator
- a new operator
Functionality includes DNS (NE-1107), LoadBalancer (NE-1108), , and other operations formerly performed by the cluster-ingress-operator for routers.
- configures GWAPI subcomponents
- Installs GWAPI Gateway CRD
- installs Istio (if needed) when Gateway and GatewayClasses are created
Requires design document or enhancement proposal, breakdown into more specific stories.
(probably needs to be an Epic, will move things around later to accomodate that).
Out of scope for enhanced dev preview:
- Unified Control Plane operations (
NE-1095) - Installs RBAC that restricts who can configure Gateway and GatewayClasses
Epic Goal
- Improve the default configuration the installer uses when the control-plane is single node
Why is this important?
- Starting 4.13 we're going to officially support (
OCPBU-95) SNO on AWS, so our installer defaults need to make sense
Scenarios
- User performs AWS IPI installation with number of control plane node replicas equal to 1. Installer will default instance type to be bigger than it usually would, to align with larger single-node openshift control plane requirements
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Background
- Starting with version 4.13 OCP is going to officially support Single
Node clusters on AWS.
- The minimum documented OCP requirement for single-node control plane
nodes is 8-cores and 16GiB of RAM
- The current default instance type chosen for AWS clusters by the
installer is `xlarge` which is 4 cores and 16GiB of RAM
Issue
The default instance type the installer currently chooses for Single
Node Openshift clusters doesn't follow our documented minimum
requirements
Solution
When the number of replicas of the ControlPlane pool is 1, the installer
will now choose `2xlarge` instead of `xlarge`.
Caveat
`2xlarge` has 32GiB of RAM, which is twice as much as we need, but it's
the best we can do to meet the minimum single-node requirements, because
AWS doesn't offer a 16GiB RAM instance type with 8 cores.
Feature Overview (aka. Goal Summary)
Goal: Control plane nodes in the cluster can be scaled up or down, lost and recovered, with no more importance or special procedure than that of a data plane node.
Problem: There is a lengthy special procedure to recover from a failed control plane node (or majority of nodes) and to add new control plane nodes.
Why is this important: Increased operational simplicity and scale flexibility of the cluster’s control plane deployment.
Goals (aka. expected user outcomes)
To enable full support for control plane machine sets on GCP
Requirements (aka. Acceptance Criteria):
- Generate CPMS for upgraded clusters
- Document support for upgraded clusters
- Ensure E2E testing for GCP clusters
Out of Scope
Any other cloud platforms
Background
Feature created from split of overarching Control Plane Machine Set feature into single release based effort
Customer Considerations
n/a
Documentation Considerations
Nothing outside documentation that shows the Azure platform is supported as part of Control Plane Machine Sets
Interoperability Considerations
n/a
Goal:
Control plane nodes in the cluster can be scaled up or down, lost and recovered, with no more importance or special procedure than that of a data plane node.
Problem:
There is a lengthy special procedure to recover from a failed control plane node (or majority of nodes) and to add new control plane nodes.
Why is this important:
- Increased operational simplicity and scale flexibility of the cluster’s control plane deployment.
Lifecycle Information:
- Core
Previous Work:
Dependencies:
- Etcd operator
Prioritized epics + deliverables (in scope / not in scope):
Estimate (XS, S, M, L, XL, XXL):
User Story:
As a developer, I want to be able to:
- Create Azure control plane nodes using MachineSets.
so that I can achieve
- More control over the nodes using the MachineAPI Operator.
Acceptance Criteria:
Description of criteria:
- New CRD ControlPlaneMachineSet is used and populated.
- New manifest is created for the ControlPlaneMachineSet.
- Fields required for the CRD are set.
(optional) Out of Scope:
Engineering Details:
- The code for Azure creation of control plane nodes is here: https://github.com/openshift/installer/blob/master/pkg/asset/machines/gcp/machines.go
- Instead of using machineapi.Machine, we need to use the machineapi.ControlPlaneMachineSet
- We might need to update our openshift/api version to get the MachineSet object that we need to use.
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
Epic Goal
- Enable the migration from a storage intree driver to a CSI based driver with minimal impact to the end user, applications and cluster
- These migrations would include, but are not limited to:
- CSI driver for Azure (file and disk)
- CSI driver for VMware vSphere
Why is this important?
- OpenShift needs to maintain it's ability to enable PVCs and PVs of the main storage types
- CSI Migration is getting close to GA, we need to have the feature fully tested and enabled in OpenShift
- Upstream intree drivers are being deprecated to make way for the CSI drivers prior to intree driver removal
Scenarios
- User initiated move to from intree to CSI driver
- Upgrade initiated move from intree to CSI driver
- Upgrade from EUS to EUS
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
We need to audit/review and implement all pending feature gates that are implemented in upstream CSI driver - https://github.com/kubernetes-sigs/vsphere-csi-driver/blob/master/manifests/vanilla/vsphere-csi-driver.yaml#L151
Some of this stuff although is necessary but could break the driver, so we have to be careful.
On new installations, we should make the StorageClass created by the CSI operator the default one.
However, we shouldn't do that on an upgrade scenario. The main reason is that users might have set a different quota on the CSI driver Storage Class.
Exit criteria:
- New clusters get the CSI Storage Class as the default one.
- Existing clusters don't get their default Storage Classes changed.
Epic Goal*
Kubernetes upstream has chosen to allow users to opt-out from CSI volume migration in Kubernetes 1.26 (1.27 PR, 1.26 backport). It is still GA there, but allows opt-out due to non-trivial risk with late CSI driver availability.
We want a similar capability in OCP - a cluster admin should be able to opt-in to CSI migration on vSphere in 4.13. Once they opt-in, they can't opt-out (at least in this epic).
Why is this important? (mandatory)
See an internal OCP doc if / how we should allow a similar opt-in/opt-out in OCP.
Scenarios (mandatory)
Upgrade
- Admin upgrades 4.12 -> 4.13 as usual
- Storage CR has CSI migration disabled (or nil), in-tree volume plugin handles in-tree PVs.
- At the same time, external CCM runs, however, due to kubelet running with –cloud-provider=vsphere, it does not do kubelet’s job.
- Admin can opt-in to CSI migration by editing Storage CR. That enables OPENSHIFT_DO_VSPHERE_MIGRATION env. var. everywhere + runs kubelet with –cloud-provider=external.
- If we have time, it should not be hard to opt out, just remove the env. var + update kubelet cmdline. Storage / in-tree volume plugin will handle in-tree PVs again, not sure about implications on external CCM.
- Once opted-in, it’s not possible to opt out.
- Both with opt-in and without it, the cluster is Upgradeable=true. Admin can upgrade to 4.14, CSI migration will be forced there.
New install
- Admin installs a new 4.13 vSphere cluster, with UPI, IPI, Assisted Installer, or Agent-based Installer.
- During installation, Storage CR is created with CSI migration enabled.
- (We want to have it enabled for a new cluster to enable external CCM and have zonal. This avoids new clusters from having in-tree as default and then having to go through migration later.)
- Resulting cluster has OPENSHIFT_DO_VSPHERE_MIGRATION env. var set + kubelet with –cloud-provider=external + topology support.
- Admin cannot opt-out after installation, we expect that they use CSI volumes for everything.
- If the admin really wants, they can opt-out before installation by adding a Storage install manifest with CSI migration disabled.
EUS to EUS (4.12 -> 4.14)
- Will have CSI migration enabled once in 4.14
- During the upgrade, a cluster will have 4.13 masters with CSI migration disabled (see regular upgrade to 4.13 above) + 4.12 kubelets.
- Once the masters are 4.14, CSI migration is force-enabled there, still, 4.14 KCM + in-tree volume plugin in it will handle in-tree volume attachments required by kubelets that still have 4.12 (that’s what kcm --external-cloud-volume-plugin=vsphere does).
- Once both masters + kubelets are 4.14, CSI migration is force enabled everywhere, in-tree volume plugin + cloud provider in KCM is still enabled by --external-cloud-volume-plugin, but it’s not used.
- Keep in-tree storage class by default
- A CSI storage class is already available since 4.10
- Recommend to switch default to CSI
- Can’t opt out from migration
Dependencies (internal and external) (mandatory)
- We need a new FeatureSet in openshift/api that disables CSIMigrationvSphere feature gate.
- We need kube-apiserver-operator, kube-controller-manager-operator, kube-scheduler-operator, MCO must reconfigure their operands to use in-tree vSphere cloud provider when they see CSIMigrationvSphere FeatureGate disabled.
- We need cloud controller manager operator to disable its operand when it sees CSIMigrationvSphere FeatureGate disabled.
Contributing Teams(and contacts) (mandatory)
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
- https://github.com/openshift/cluster-kube-controller-manager-operator/pull/718
- https://github.com/openshift/cluster-storage-operator/pull/351
- https://github.com/openshift/kubernetes/pull/1514
- https://github.com/openshift/machine-config-operator/pull/3655
- https://github.com/openshift/origin/pull/27831
- https://github.com/openshift/vmware-vsphere-csi-driver-operator/pull/145
- https://github.com/openshift/vsphere-problem-detector/pull/108
Feature Overview
RHEL CoreOS should be updated to RHEL 9.2 sources to take advantage of newer features, hardware support, and performance improvements.
Requirements
- RHEL 9.x sources for RHCOS builds starting with OCP 4.13 and RHEL 9.2.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
9.2 Preview via LayeringNo longer necessary assuming we stay the course of going all in on 9.2
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Epic Goal
- The Kernel API was updated for RHEL 9, so the old approach of setting the `sched_domain` in `/sys/kernel` is no longer available. Instead, cgroups have to be worked with directly.
- Both CRI-O and PAO need to be updated to set the cpuset of containers and other processes correctly, as well as set the correct value for sched_load_balance
Why is this important?
- CPU load balancing is a vital piece of real time execution for processes that need exclusive access to a CPU. Without this, CPU load balancing won't work on RHEL 9 with Openshift 4.13
Scenarios
- As a developer on Openshift, I expect my pods to run with exclusive CPUs if I set the PAO configuration correctly
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Part of setting CPU load balancing on RHEL 9 involves disabling sched_load_balance on cgroups that contain a cpuset that should be exclusive. The PAO may be required to be responsible for this piece
This is the Epic to track the work to add RHCOS 9 in OCP 4.13 and to make OCP use it by default.
CURRENT STATUS: Landed in 4.14 and 4.13
Testing with layering
Another option given an existing e.g. 4.12 cluster is to use layering. First, get a digested pull spec for the current build:
$ skopeo inspect --format "{{.Name}}@{{.Digest}}" -n docker://quay.io/openshift-release-dev/ocp-v4.0-art-dev:4.13-9.2
quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:b4cc3995d5fc11e3b22140d8f2f91f78834e86a210325cbf0525a62725f8e099
Create a MachineConfig that looks like this:
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: worker-override
spec:
osImageURL: <digested pull spec>
If you want to also override the control plane, create a similar one for the master role.
We don't yet have auto-generated release images. However, if you want one, you can ask cluster bot to e.g. "launch https://github.com/openshift/machine-config-operator/pull/3485" with options you want (e.g. "azure" etc.) or just "build https://github.com/openshift/machine-config-operator/pull/3485" to get a release image.
Description:
Upstream OKD/FCOS are already using latest ignition that supports [1] writing authorized keys in /home/core/.ssh/authorized_keys.d/ignition . With RHCOS 9, we should also start using new default path /home/core/.ssh/authorized_keys.d/ignition instead of /home/core/.ssh/authorized_keys
[1]https://github.com/openshift/machine-config-operator/pull/2688
Acceptance Criteria:
- ssh key gets written into /home/core/.ssh/authorized_keys.d/ignition on RHCOS 9 nodes and /home/co/.ssh/authorized_keys file doesn't exist
- Upgrade from RHCOS 8 to RHCOS 9 node works as expected and all ssh keys from /home/core/.ssh/authorized_keys gets migrated to /home/core/.ssh/authorized_keys.d/ignition
- MCO e2e test would have to adapt accordingly as today it is looking for ssh key in /home/core/.ssh/authorized_keys
Epic Goal
- Users who disable ssh access in favor of `oc debug` are reliant on the OpenShift API being up between the supervisors and worker nodes. In order to troubleshoot or RCA a node problem, these users would like to be able to use password auth on /dev/console, which they can access via BMC or local keyboard.
Why is this important?
- While setting passwords hasn't been cool in some time, it can make sense if password auth is disabled in sshd (which it is by default).
- There is a workaround: push an /etc/shadow.
Scenarios
- A new node is failing to join the cluster and ssh/api access is not possible but a local console (via cloud provider or bare metal BMC). The administrator would like to pull logs to triage the joining problem.
- sshd is not enabled and the API connection to the kubelet is down (so no `oc debug node`) and the administrator needs to triage the problem and/or collect logs.
Acceptance Criteria
- Users can set and change a password on "core" via ignition (machineconfig).
- Changing the core user password should not cause workload disruption
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- Users who disable ssh access in favor of `oc debug` are reliant on the OpenShift API being up between the supervisors and worker nodes. In order to troubleshoot or RCA a node problem, these users would like to be able to use password auth on /dev/console, which they can access via BMC or local keyboard.
Why is this important?
- While setting passwords hasn't been cool in some time, it can make sense if password auth is disabled in sshd (which it is by default).
- There is a workaround: push an /etc/shadow.
Scenarios
- A new node is failing to join the cluster and ssh/api access is not possible but a local console (via cloud provider or bare metal BMC). The administrator would like to pull logs to triage the joining problem.
- sshd is not enabled and the API connection to the kubelet is down (so no `oc debug node`) and the administrator needs to triage the problem and/or collect logs.
Acceptance Criteria
- Users can set and change a password on "core" via ignition (machineconfig).
- Changing the core user password should not cause workload disruption
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- Users who disable ssh access in favor of `oc debug` are reliant on the OpenShift API being up between the supervisors and worker nodes. In order to troubleshoot or RCA a node problem, these users would like to be able to use password auth on /dev/console, which they can access via BMC or local keyboard.
Why is this important?
- While setting passwords hasn't been cool in some time, it can make sense if password auth is disabled in sshd (which it is by default).
- There is a workaround: push an /etc/shadow.
Scenarios
- A new node is failing to join the cluster and ssh/api access is not possible but a local console (via cloud provider or bare metal BMC). The administrator would like to pull logs to triage the joining problem.
- sshd is not enabled and the API connection to the kubelet is down (so no `oc debug node`) and the administrator needs to triage the problem and/or collect logs.
Acceptance Criteria
- Users can set and change a password on "core" via ignition (machineconfig).
- Changing the core user password should not cause workload disruption
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Done when
- MCD will learn to consider PasswordHash field of passwd as valid change of user core. For example, see https://github.com/openshift/machine-config-operator/blob/master/pkg/daemon/update.go#L844
Feature Overview
- Kubernetes offers different ways to consume, one could request persistent volumes that survive pod termination or ask for a ephemeral storage space that will be consumed during the lifetime of the pod.
- This feature tracks the improvements around ephemeral storage as some workloads rely on reliable temporary storage space such as batch jobs, caching services or any app that does not care whether the data is stored persistently across restarts
Goals
As described in the kubernetes "ephemeral volumes" documentation this features tracks GA and improvements in
- emptyDir: empty at Pod startup, with storage coming locally from the kubelet base directory (usually the root disk) or RAM
- CSI ephemeral volumes: similar to the previous volume kinds, but provided by special CSI drivers which specifically support this feature
- generic ephemeral volumes, which can be provided by all storage drivers that also support persistent volumes
OCPPLAN-9193 Implemented local ephemeral capacity management as well as CSI Generic ephemeral volume. This feature tracks the remaining work to GA CSI ephemeral in-inline volume, specially the admission plugin to make the feature secure and prevent any insecure driver from using it. Ephemeral in-line is required by some CSI as key feature to operate (e.g SecretStore CSI), ODF is also planning to GA ephemeral in-line with ceph CSI.
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Use Cases
This Section:
- As an OCP user I want to consume ephemeral storage for my workload
- As an OCP user I would like to include my PV definition directly in my app definition
- As an OCP admin I would like to offer ephemeral volumes to my users though CSI
- As a partner I would like to onboard a driver that relies on CSI inline volumes
Customer Considerations
- Make sure each ephemeral volume option is clearly identified and documented for each purpose.
- Make sure we highlight ephemeral volume options that require a specific driver support
Goal:
The goal is to provide inline volume support (also known as Ephemeral volumes) via a CSI driver/operator. This epic also track the dev of the new admission plugin required to make inline volumes safe.
Problem:
- The only practical way to extend pods such that node local integrations can happen is with inline volumes. So if we want to integrate with IAM for per pod credentials, we need inline csi volumes. If we want to do better build cache integration, we need inline csi.
Why is this important:
- (from https://kubernetes-csi.github.io/docs/ephemeral-local-volumes.html) Traditionally, volumes that are backed by CSI drivers can only be used with a PersistentVolume and PersistentVolumeClaim object combination. This feature will support ephemeral storage use cases and allows CSI volumes to be specified directly in the pod specification. At runtime, nested inline volumes follow the ephemeral lifecycle of their associated pods where the driver handles all phases of volume operations as pods are created and destroyed.
- Vault integration can be implemented via in-line volumes (see https://github.com/deislabs/secrets-store-csi-driver/blob/master/README.md).
- Inline volumes would allow us to give out tokens for cloud integration and nuke cloud credential operator’s use of secrets.
- In OpenShift we already have Shared Resource CSI driver, which uses in-line CSI volumes to distribute cluster-wide secrets and/or config maps.
Dependencies (internal and external):
- CSI API
Prioritized epics + deliverables (in scope / not in scope):
- In Scope
- A working CSI based inline volume
- Documentation
- Admision plugin
- Not in Scope
- Implementing the use cases for inline volumes (i.e. integration with IAM)
Estimate (XS, S, M, L, XL, XXL):
Previous Work:
Customers:
Open questions:
Notes:
- Couple of useful links:
This flag is currently TechPreviewNoUpgrade:
https://github.com/dobsonj/api/blob/95216a844c16019d4e3aaf396492c95d19bf22c0/config/v1/types_feature.go#L122
Once the admission plugin has had sufficient testing and e2e tests are in place, then this can be promoted to GA and eventually remove the feature gate.
Create a validating admission plugin that allows pods to be created if:
- The pod references CSI volume(s)
- The CSI Driver(s) for the referenced volume(s) are allowed based on the PodSecurity namespace labels.
Enhancement: https://github.com/openshift/enhancements/blob/master/enhancements/storage/csi-inline-vol-security.md
*As OCP user, I want to be able to use in-line CSI volumes in my Pods, so my apps work.
Since we will have admission plugin to filter out dangerous CSI drivers from restricted namespace, all users should be able to use CSI volumes in all SCCs.
Exit criteria:
* an unprivileged user + namespace can use in-line CSI volume of a "safe" CSI driver (e.g. SharedResource CSI driver) without any changes in "restricted-v2" SCC.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Create a new platform type, working name "External", that will signify when a cluster is deployed on a partner infrastructure where core cluster components have been replaced by the partner. “External” is different from our current platform types in that it will signal that the infrastructure is specifically not “None” or any of the known providers (eg AWS, GCP, etc). This will allow infrastructure partners to clearly designate when their OpenShift deployments contain components that replace the core Red Hat components.
This work will require updates to the core OpenShift API repository to add the new platform type, and then a distribution of this change to all components that use the platform type information. For components that partners might replace, per-component action will need to be taken, with the project team's guidance, to ensure that the component properly handles the "External" platform. These changes will look slightly different for each component.
To integrate these changes more easily into OpenShift, it is possible to take a multi-phase approach which could be spread over a release boundary (eg phase 1 is done in 4.X, phase 2 is done in 4.X+1).
Phase 1
- Write platform “External” enhancement.
- Evaluate changes to cluster capability annotations to ensure coverage for all replaceable components.
- Meet with component teams to plan specific changes that will allow for supplement or replacement under platform "External".
Phase 2
- Update OpenShift API with new platform and ensure all components have updated dependencies.
- Update capabilities API to include coverage for all replaceable components.
- Ensure all Red Hat operators tolerate the "External" platform and treat it the same as "None" platform.
Phase 3
- Update components based on identified changes from phase 1
- Update Machine API operator to run core controllers in platform "External" mode.
Why is this important?
- As partners begin to supplement OpenShift's core functionality with their own platform specific components, having a way to recognize clusters that are in this state helps Red Hat created components to know when they should expect their functionality to be replaced or supplemented. Adding a new platform type is a significant data point that will allow Red Hat components to understand the cluster configuration and make any specific adjustments to their operation while a partner's component may be performing a similar duty.
- The new platform type also helps with support to give a clear signal that a cluster has modifications to its core components that might require additional interaction with the partner instead of Red Hat. When combined with the cluster capabilities configuration, the platform "External" can be used to positively identify when a cluster is being supplemented by a partner, and which components are being supplemented or replaced.
Scenarios
- A partner wishes to replace the Machine controller with a custom version that they have written for their infrastructure. Setting the platform to "External" and advertising the Machine API capability gives a clear signal to the Red Hat created Machine API components that they should start the infrastructure generic controllers but not start a Machine controller.
- A partner wishes to add their own Cloud Controller Manager (CCM) written for their infrastructure. Setting the platform to "External" and advertising the CCM capability gives a clear to the Red Hat created CCM operator that the cluster should be configured for an external CCM that will be managed outside the operator. Although the Red Hat operator will not provide this functionality, it will configure the cluster to expect a CCM.
Acceptance Criteria
Phase 1
- Partners can read "External" platform enhancement and plan for their platform integrations.
- Teams can view jira cards for component changes and capability updates and plan their work as appropriate.
Phase 2
- Components running in cluster can detect the “External” platform through the Infrastructure config API
- Components running in cluster react to “External” platform as if it is “None” platform
- Partners can disable any of the platform specific components through the capabilities API
Phase 3
- Components running in cluster react to the “External” platform based on their function.
- for example, the Machine API Operator needs to run a set of controllers that are platform agnostic when running in platform “External” mode.
- the specific component reactions are difficult to predict currently, this criteria could change based on the output of phase 1.
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- Phase 1 requires talking with several component teams, the specific action that will be needed will depend on the needs of the specific component. At the least the components need to treat platform "External" as "None", but there could be more changes depending on the component (eg Machine API Operator running non-platform specific controllers).
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
As defined in the External platform enhancement , a new platform is being added to OpenShift. To accommodate the phase 2 work, the CIRO should be updated, if necessary, to react to the "External" platform in the same manner as it would for platform "None".
Please see the enhancement and the parent plan OCPBU-5 for more details about this process.
Why is this important?
In phase 2 (planned for 4.13 release) of the external platform enhancement, the new platform type will be added to the openshift/api packages. As part of staging the release of this new platform we will need to ensure that all operators react in a neutral way to the platform, as if it were a "None" platform to ensure the continued normal operation of OpenShift.
Scenarios
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- As a user I would like to enable the External platform so that I can supplement OpenShift with my own Image Registry options. To ensure proper operation of OpenShift, the cluster image registry operator should not react to the new platform or prevent my installation of the custom driver so that I can create clusters with my own topology.
Acceptance Criteria
Provide some (testable) examples of how we will know if we have achieved the epic goal.
We are working to create an External platform test which will exercise this mechanism, see OCPCLOUD-1782
Dependencies (internal and external)
This will require OCPCLOUD-1777
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI Testing - we will perform manual test while waiting for
OCPCLOUD-1782 - Documentation - only developer docs need to be updated at this time
- QE - test scenario should be covered by a cluster-wide install with the new platform type
- Technical Enablement - n/a
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Epic Goal
As defined in the External platform enhancement , a new platform is being added to OpenShift. To accommodate the phase 2 work, the CIO should be updated, if necessary, to react to the "External" platform in the same manner as it would for platform "None".
Please see the enhancement and the parent plan OCPBU-5 for more details about this process.
Why is this important?
In phase 2 (planned for 4.13 release) of the external platform enhancement, the new platform type will be added to the openshift/api packages. As part of staging the release of this new platform we will need to ensure that all operators react in a neutral way to the platform, as if it were a "None" platform to ensure the continued normal operation of OpenShift.
Scenarios
- As a user I would like to enable the External platform so that I can supplement OpenShift with my own container network options. To ensure proper operation of OpenShift, the cluster ingress operator should not react to the new platform or prevent my installation of the custom driver so that I can create clusters with my own topology.
Acceptance Criteria
We are working to create an External platform test which will exercise this mechanism, see OCPCLOUD-1782
Dependencies (internal and external)
- This will require
OCPCLOUD-1777
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI Testing - we will perform manual test while waiting for
OCPCLOUD-1782 - Documentation - only developer docs need to be updated at this time
- QE - test scenario should be covered by a cluster-wide install with the new platform type
- Technical Enablement - n/a
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
- ** - Downstream documentation merged: <link to meaningful PR>
as described in the epic, the CIO should be updated to react to the new "External" platform as it would for a "None" platform.
Feature Overview
- Enables OTA updates from OpenShift 4.12.x to OpenShift 4.13.x.
Goals
- As a platform administrator, I want to upgrade my OpenShift cluster from a previous supported release to the current release, i.e. 4.12.x to 4.13.x.
- Ensure upgrades work smoothly without impacting end user workloads (for HA clusters) from the previous release to the latest release for all supported OpenShift environments:
- Connected and disconnected deployments
- All support topologies (SNO, compact cluster, standard HA cluster, RWN)
- All platforms and providers
- Cloud and on-premises
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Epic Goal
- Provide a convenient way to migrate from a homogeneous to a heterogeneous cluster.
Why is this important?
- So customers with an existing cluster can migrate to a heterogeneous payload rather than doing a fresh install, without needing to use oc adm upgrade --allow-explicit-upgrade --to-image "${PULLSPEC}".
OTA-658and maybe some oc side tooling, if folks feel oc patch ... is too heavy (although see discussion inOTA-597about policies for adding new oc subcommands).
- So components (like which?) can make decisions (like what?) based on the "current" cluster architecture.
OTA-659.
Scenarios
- Upgrade from a homogeneous release eg. 4.11.0-x86_64 to a heterogeneous release 4.11.0-multi.
- Ensure that ClusterVersion spec has a new architecture field to denote desired architecture of the cluster
- Ensure ClusterVersionStatus populates a new architecture field denoting the current architecture of the cluster.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- Should the migration also be an upgrade or should it be two separate steps? i.e, migrate to hetero release of same version and then upgrade?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Per spike Add field in ClusterVersion spec to request the target architecture, create "oc adm upgrade" sub-command that allows a convenient way to update a cluster from homogeneous -> heterogeneous while maintaining the current version, i.e. there will not be an option to specify version.
Goal:
Support migration from dual-stack IPv6 to single-stack IPv6.
Why is this important?
We have customers who want to deploy a dual stack cluster and then (eventually) migrate to single stack ipv6 once all of their ipv4 dependencies are eliminated. Currently this isn't possible because we only support ipv4-primary dual stack deployments. However, with the implementation of OPNET-1 we addressed many of the limitations that prevented ipv6-primary, so we need to figure out what remains to make this supported.
At the very least we need to remove the validations in the installer that requires ipv4 to be the primary address. There will also be changes needed in dev-scripts to allow testing (an option to make the v6 subnets and addresses primary, for example).
We have customers who want to deploy a dual stack cluster and then migrate to single stack ipv6 once all of their ipv4 dependencies are eliminated. Currently this isn't possible because we only support ipv4-primary dual stack deployments. However, with the implementation of OPNET-1 we addressed many of the limitations that prevented ipv6-primary, so we need to figure out what remains to make this supported. At the very least we need to remove the validations in the installer that require ipv4 to be the primary address. There will also be changes needed in dev-scripts to allow testing (an option to make the v6 subnets and addresses primary, for example).
In the IPI nodeip-configuration service we always prefer ipv4 as the primary node address. This will need to be made dynamic based on the order of networks configured.
Runtimecfg assumes ipv4-primary in some places today and we need to make that aware of whether a cluster is v4 or v6 primary.
The installer currently enforces ipv4-primary for dual stack deployments. We will need to remove/modify those validations to allow an ipv6-primary configureation.
Goal:
API and implementation work to provide the cluster admin with an option in the IngressController API to use PROXY protocol with IBM Cloud load-balancers.
Description:
This epic extends the IngressController API essentially by copying the option we added in NE-330. In that epic, we added a configuration option to use PROXY protocol when configuring an IngresssController to use a NodePort service or host networking. With this epic (NE-1090), the same configuration option is added to use PROXY protocol when configuring an IngressController to use a LoadBalancer service on IBM Cloud.
This epic tracks the API and implementation work to provide the cluster admin with an option in the IngressController API to use PROXY protocol with IBM Cloud load-balancers.
This epic extends the IngressController API essentially by copying the option we added in NE-330. In that epic, we added a configuration option to use PROXY protocol when configuring an IngresssController to use a NodePort service or host networking. With this epic (NE-1090), the same configuration option is added to use PROXY protocol when configuring an IngressController to use a LoadBalancer service on IBM Cloud.
Feature Overview
Create a Azure cloud specific spec.resourceTags entry in the infrastructure CRD. This should create and update tags (or labels in Azure) on any openshift cloud resource that we create and manage. The behaviour should also tag existing resources that do not have the tags yet and once the tags in the infrastructure CRD are changed all the resources should be updated accordingly.
Tag deletes continue to be out of scope, as the customer can still have custom tags applied to the resources that we do not want to delete.
Due to the ongoing intree/out of tree split on the cloud and CSI providers, this should not apply to clusters with intree providers (!= "external").
Once confident we have all components updated, we should introduce an end2end test that makes sure we never create resources that are untagged.
Goals
- Functionality on Azure Tech Preview
- inclusion in the cluster backups
- flexibility of changing tags during cluster lifetime, without recreating the whole cluster
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
List any affected packages or components.
- Installer
- Cluster Infrastructure
- Storage
- Node
- NetworkEdge
- Internal Registry
- CCO
This epic covers the work to apply user defined tags to Azure created for openshift cluster available as tech preview.
The user should be able to define the azure tags to be applied on the resources created during cluster creation by the installer and other operators which manages the specific resources. The user will be able to define the required tags in the install-config.yaml while preparing with the user inputs for cluster creation, which will then be made available in the status sub-resource of Infrastructure custom resource which cannot be edited but will be available for user reference and will be used by the in-cluster operators for tagging when the resources are created.
Updating/deleting of tags added during cluster creation or adding new tags as Day-2 operation is out of scope of this epic.
List any affected packages or components.
- Installer
- Cluster Infrastructure
- Storage
- Node
- NetworkEdge
- Internal Registry
- CCO
Reference - https://issues.redhat.com/browse/RFE-2017
Enhancement proposed for Azure tags support in OCP, requires machine-api-provider-azure to add azure userTags available in the status sub resource of infrastructure CR, to the azure virtual machines resource and the sub-resources created.
machine-api-provider-azure has a method CreateMachine() which creates below resources and tags should be applied
- ApplicationSecurityGroup
- AvailabilitySet
- Group
- LoadBalancer
- PublicIPAddress
- RouteTable
- SecurityGroup
- VirtualMachineExtension
- Interface
- VirtualMachine
- VirtualNetwork
Acceptance Criteria
- Code linting, validation and best practices adhered to
- UTs and e2e are added/updated
Installer creates below list of resources during create cluster phase and these resources should be applied with the user defined tags and the default OCP tag kubernetes.io/cluster/<cluster_name>:owned
Resources List
| Resource | Terraform API |
|---|---|
| Resource group | azurerm_resource_group |
| Image | azurerm_image |
| Load Balancer | azurerm_lb |
| Network Security Group | azurerm_network_security_group |
| Storage Account | azurerm_storage_account |
| Managed Identity | azurerm_user_assigned_identity |
| Virtual network | azurerm_virtual_network |
| Virtual machine | azurerm_linux_virtual_machine |
| Network Interface | azurerm_network_interface |
| Private DNS Zone | azurerm_private_dns_zone |
| DNS Record | azurerm_dns_cname_record |
Acceptance Criteria:
- Code linting, validation and best practices adhered to
- List of azure resources created by installer should have user defined tags and as well as the default OCP tag.
Installer generates Infrastructure CR in manifests creation step of cluster creation process based on the user provided input recorded in install-config.yaml. While generating Infrastructure CR platformStatus.azure.resourceTags should be updated with the user provided tags(installconfig.platform.azure.userTags).
Acceptance Criteria
- Code linting, validation and best practices adhered to
- Infrastructure CR created by installer should have azure user defined tags if any, in status field.
Issues found by QE team during pre-merge tests are reported in QE Tracker, which should be fixed.
Acceptance criteria:
- Update UTs, if required
- Update enhancement, if required
cluster-config-operator makes Infrastructure CRD available for installer, which is included in it's container image from the openshift/api package and requires the package to be updated to have the latest CRD.
Enhancement proposed for Azure tags support in OCP, requires cluster-ingress-operator to add azure userTags available in the status sub resource of infrastructure CR, to the azure DNS resource created.
cluster-ingress-operator should add Tags to the DNS records created.
Note: dnsrecords.ingress.operator.openshift.io and openshift-ingress CRD, usage to be identified.
Acceptance Criteria
- Code linting, validation and best practices adhered to
- UTs and e2e are added/updated
Overview
HyperShift came to life to serve multiple goals, some are main near-term, some are secondary that serve well long-term.
Main Goals for hosted control planes (HyperShift)
- Optimize OpenShift for Cost/footprint/ which improves our competitive stance against the *KSes
- Establish separation of concerns which makes it more resilient for SRE to manage their workload clusters (be it security, configuration management, etc).
- Simplify and enhance multi-cluster management experience especially since multi-cluster is becoming an industry need nowadays.
Secondary Goals
HyperShift opens up doors to penetrate the market. HyperShift enables true hybrid (CP and Workers decoupled, mixed IaaS, mixed Arch,...). An architecture that opens up more options to target new opportunities in the cloud space. For more details on this one check: Hosted Control Planes (aka HyperShift) Strategy [Live Document]
Hosted Control Planes (HyperShift) Map
To bring hosted control planes to our customers, we need the means to ship it. Today MCE is how HyperShift shipped, and installed so that customers can use it. There are two main customers for hosted-control-planes:
- Self-managed: In that case, Red Hat would provide hosted control planes as a service that is managed and SREed by the customer for their tenants (hence “self”-managed). In this management model, our external customers are the direct consumers of the multi-cluster control plane as a servie. Once MCE is installed, they can start to self-service dedicated control planes.
- Managed: This is OpenShift as a managed service, today we only “manage” the CP, and share the responsibility for other system components, more info here. To reduce management costs incurred by service delivery organizations which translates to operating profit (by reducing variable costs per control-plane), as well as to improve user experience, lower platform overhead (allow customers to focus mostly on writing applications and not concern themselves with infrastructure artifacts), and improve the cluster provisioning experience. HyperShift is shipped via MCE, and delivered to Red Hat managed SREs (same consumption route). However, for managed services, additional tooling needs to be refactored to support the new provisioning path. Furthermore, unlike self-managed where customers are free to bring their own observability stack, Red Hat managed SREs need to observe the managed fleet to ensure compliance with SLOs/SLIs/…
If you have noticed, MCE is the delivery mechanism for both management models. The difference between managed and self-managed is the consumer persona. For self-managed, it's the customer SRE for managed its the RH SRE.
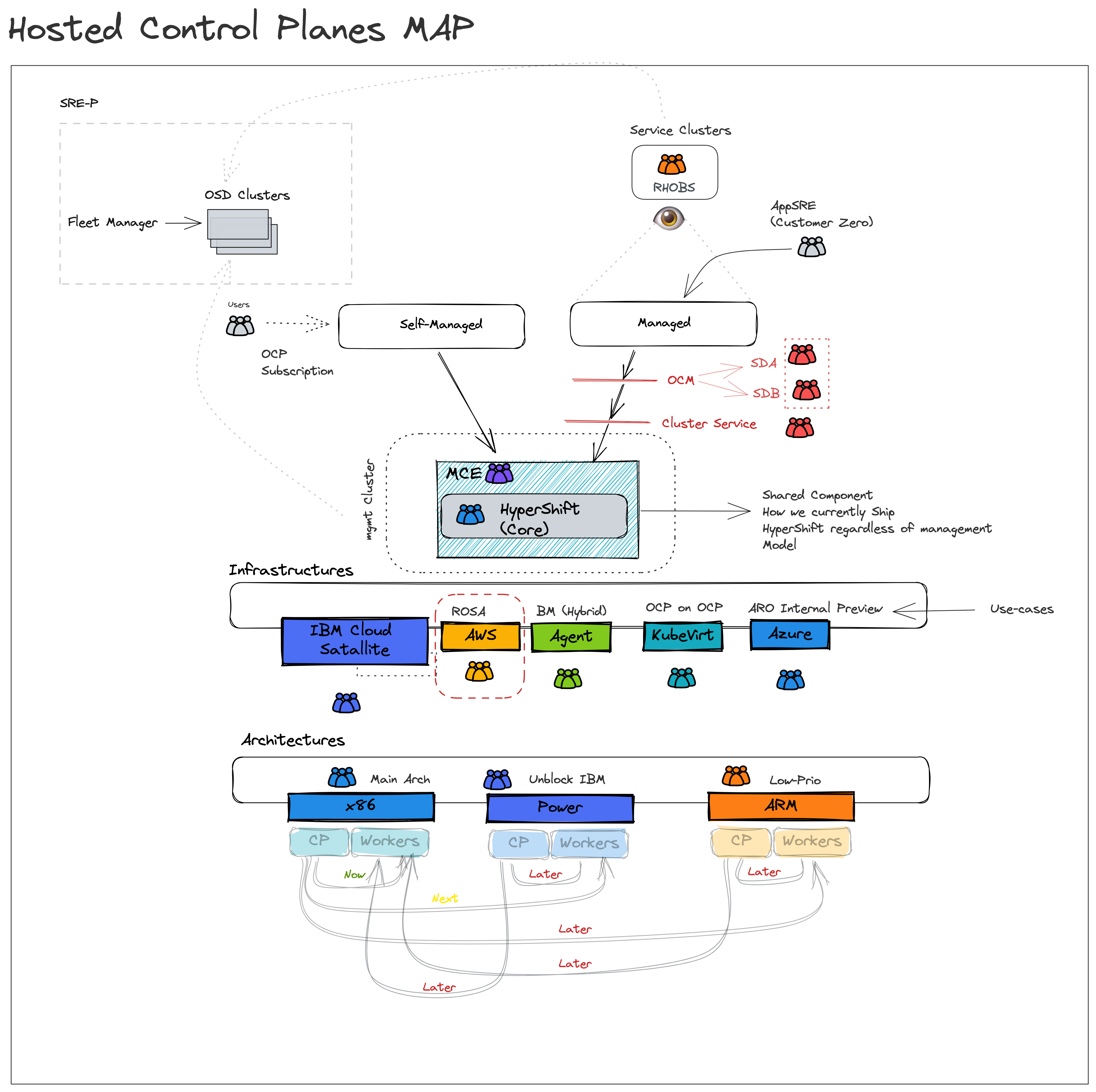
High-level Requirements
For us to ship HyperShift in the product (as hosted control planes) in either management model, there is a necessary readiness checklist that we need to satisfy. Below are the high-level requirements needed before GA:
- Hosted control planes fits well with our multi-cluster story (with MCE)
- Hosted control planes APIs are stable for consumption
- Customers are not paying for control planes/infra components.
- Hosted control planes has an HA and a DR story
- Hosted control planes is in parity with top-level add-on operators
- Hosted control planes reports metrics on usage/adoption
- Hosted control planes is observable
- HyperShift as a backend to managed services is fully unblocked.
Please also have a look at our What are we missing in Core HyperShift for GA Readiness? doc.
Hosted control planes fits well with our multi-cluster story
Multi-cluster is becoming an industry need today not because this is where trend is going but because it’s the only viable path today to solve for many of our customer’s use-cases. Below is some reasoning why multi-cluster is a NEED:
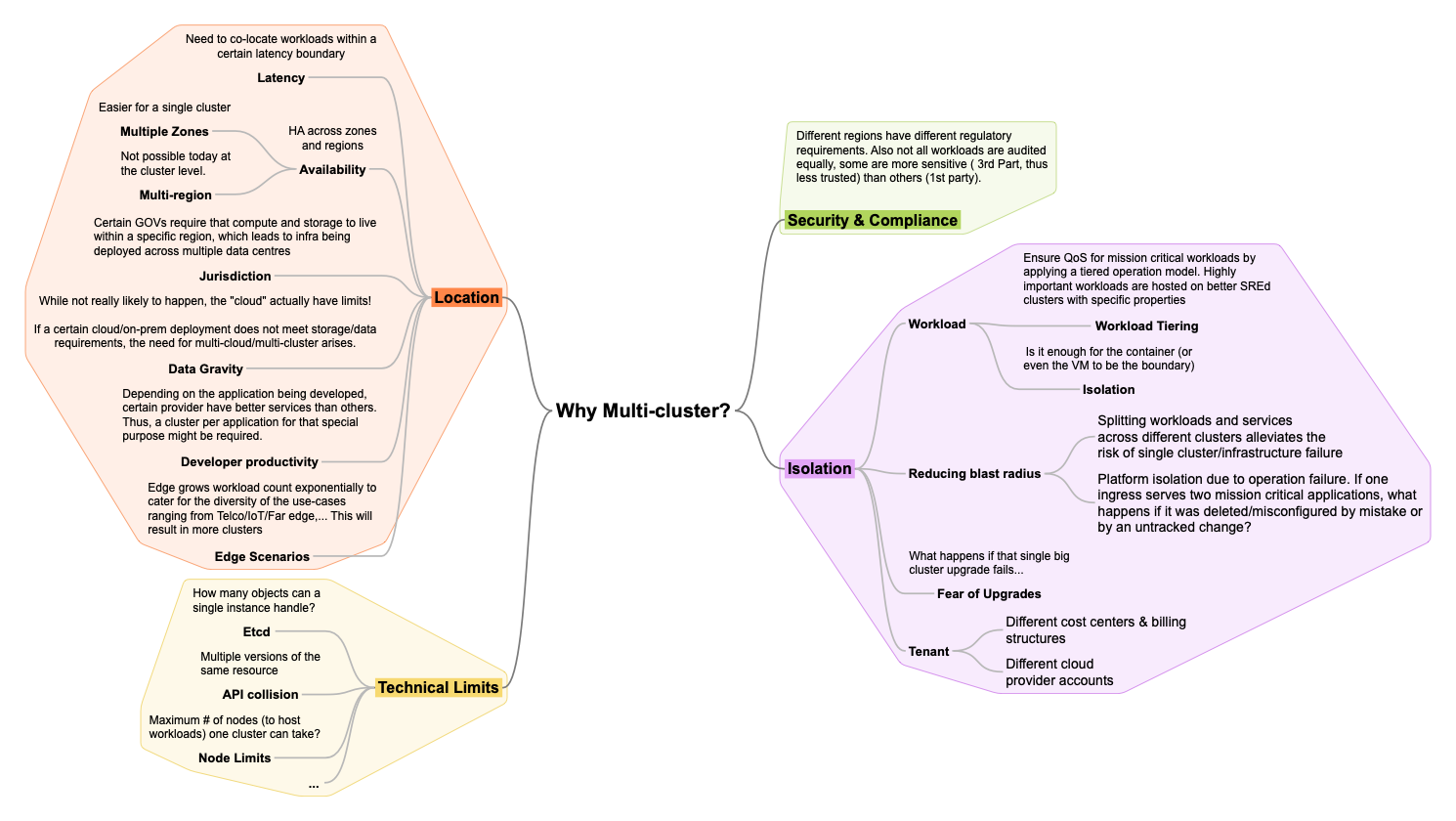
As a result, multi-cluster management is a defining category in the market where Red Hat plays a key role. Today Red Hat solves for multi-cluster via RHACM and MCE. The goal is to simplify fleet management complexity by providing a single pane of glass to observe, secure, police, govern, configure a fleet. I.e., the operand is no longer one cluster but a set, a fleet of clusters.
HyperShift logically centralized architecture, as well as native separation of concerns and superior cluster lifecyle management experience, makes it a great fit as the foundation of our multi-cluster management story.
Thus the following stories are important for HyperShift:
- When lifecycling OpenShift clusters (for any OpenShift form factor) on any of the supported providers from MCE/ACM/OCM/CLI as a Cluster Service Consumer (RH managed SRE, or self-manage SRE/admin):
- I want to be able to use a consistent UI so I can manage and operate (observe, govern,...) a fleet of clusters.
- I want to specify HA constraints (e.g., deploy my clusters in different regions) while ensuring acceptable QoS (e.g., latency boundaries) to ensure/reduce any potential downtime for my workloads.
- When operating OpenShift clusters (for any OpenShift form factor) on any of the supported provider from MCE/ACM/OCM/CLI as a Cluster Service Consumer (RH managed SRE, or self-manage SRE/admin):
- I want to be able to backup any critical data so I am able to restore them in case of hosting service cluster (management cluster) failure.
Refs:
- Agenda/Notes - HyperShift/ACM UX Sync
- https://coreos.slack.com/archives/C02TPGYJ6NN/p1657117542026339
- AWS UI and Agent Provisioning UI mocks
Hosted control planes APIs are stable for consumption.
HyperShift is the core engine that will be used to provide hosted control-planes for consumption in managed and self-managed.
Main user story: When life cycling clusters as a cluster service consumer via HyperShift core APIs, I want to use a stable/backward compatible API that is less susceptible to future changes so I can provide availability guarantees.
Ref: What are we missing in Core HyperShift for GA Readiness?
Customers are not paying for control planes/infra components.
Customers do not pay Red Hat more to run HyperShift control planes and supporting infrastructure than Standalone control planes and supporting infrastructure.
Assumptions:
- A customer will be able to associate a cluster as “Infrastructure only”
- E.g. one option: management cluster has role=master, and role=infra nodes only, control planes are packed on role=infra nodes
- OR the entire cluster is labeled infrastructure , and node roles are ignored.
- Anything that runs on a master node by default in Standalone that is present in HyperShift MUST be hosted and not run on a customer worker node.
HyperShift - proposed cuts from data plane
HyperShift has an HA and a DR story
When operating OpenShift clusters (for any OpenShift form factor) from MCE/ACM/OCM/CLI as a Cluster Service Consumer (RH managed SRE, or self-manage SRE/admin) I want to be able to migrate CPs from one hosting service cluster to another:
- as means for disaster recovery in the case of total failure
- so that scaling pressures on a management cluster can be mitigated or a management cluster can be decommissioned.
More information:
Hosted control planes reports metrics on usage/adoption
To understand usage patterns and inform our decision making for the product. We need to be able to measure adoption and assess usage.
See Hosted Control Planes (aka HyperShift) Strategy [Live Document]
Hosted control plane is observable
Whether it's managed or self-managed, it’s pertinent to report health metrics to be able to create meaningful Service Level Objectives (SLOs), alert of failure to meet our availability guarantees. This is especially important for our managed services path.
HyperShift is in parity with top-level add-on operators
https://issues.redhat.com/browse/OCPPLAN-8901
Unblock HyperShift as a backend to managed services
HyperShift for managed services is a strategic company goal as it improves usability, feature, and cost competitiveness against other managed solutions, and because managed services/consumption-based cloud services is where we see the market growing (customers are looking to delegate platform overhead).
We should make sure our SD milestones are unblocked by the core team.
Note
This feature reflects HyperShift core readiness to be consumed. When all related EPICs and stories in this EPIC are complete HyperShift can be considered ready to be consumed in GA form. This does not describe a date but rather the readiness of core HyperShift to be consumed in GA form NOT the GA itself.
- GA date for self-managed will be factoring in other inputs such as adoption, customer interest/commitment, and other factors.
- GA dates for ROSA-HyperShift are on track, tracked in milestones M1-7 (have a look at https://issues.redhat.com/browse/OCPPLAN-5771)
Epic Goal*
The goal is to split client certificate trust chains from the global Hypershift root CA.
Why is this important? (mandatory)
This is important to:
- assure a workload can be run on any kind of OCP flavor
- reduce the blast radius in case of a sensitive material leak
- separate trust to allow more granular control over client certificate authentication
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- I would like to be able to run my workloads on any OpenShift-like platform.
My workloads allow components to authenticate using client certificates based
on a trust bundle that I am able to retrieve from the cluster.
- I don't want my users to have access to any CA bundle that would allow them
to trust a random certificate from the cluster for client certificate authentication.
Dependencies (internal and external) (mandatory)
Hypershift team needs to provide us with code reviews and merge the changes we are to deliver
Contributing Teams(and contacts) (mandatory)
- Development - OpenShift Auth, Hypershift
- Documentation -OpenShift Auth Docs team
- QE - OpenShift Auth QE
- PX - I have no idea what PX is
- Others - others
Acceptance Criteria (optional)
The serviceaccount CA bundle automatically injected to all pods cannot be used to authenticate any client certificate generated by the control-plane.
Drawbacks or Risk (optional)
Risk: there is a throbbing time pressure as this should be delivered before first stable Hypershift release
Done - Checklist (mandatory)
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
AUTH-311 introduced an enhancement. Implement the signer separation described there.
Feature Overview
Agent-based installer requires to boot the generated ISO on the target nodes manually. Support for PXE booting will allow customers to automate their installations via their DHCP/PXE infrastructure.
This feature allows generating installation ISOs ready to add to a customer-provided DHCP/PXE infrastructure.
Goals
As an OpenShift installation admin I want to PXE-boot the image generated by the openshift-install agent subcommand
Why is this important?
We have customers requesting this booting mechanism to make it easier to automate the booting of the nodes without having to actively place the generated image in a bootable device for each host.
Epic Goal
As an OpenShift installation admin I want to PXE-boot the image generated by the openshift-install agent subcommand
Why is this important?
We have customers requesting this booting mechanism to make it easier to automate the booting of the nodes without having to actively place the generated image in a bootable device for each host.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Only parts of the epic AGENT-356 have landed (in particular, AGENT-438). We shouldn't ship it in a release in its current state due to lack of testing, as well as missing features like iPXE support (AGENT-491). At the moment, it is likely the PXE artifacts don't work at all because AGENT-510 is not implemented.
The agent create pxe-files subcommand should be disabled until the whole Epic is completed in a release.
Feature Overview (aka. Goal Summary)
Goal: Control plane nodes in the cluster can be scaled up or down, lost and recovered, with no more importance or special procedure than that of a data plane node.
Problem: There is a lengthy special procedure to recover from a failed control plane node (or majority of nodes) and to add new control plane nodes.
Why is this important: Increased operational simplicity and scale flexibility of the cluster’s control plane deployment.
Goals (aka. expected user outcomes)
To enable full support for control plane machine sets on Azure
Requirements (aka. Acceptance Criteria):
- Generate CPMS for upgraded clusters
- Document support for upgraded clusters
- Ensure E2E testing for Azure clusters
Out of Scope
Any other cloud platforms
Background
Feature created from split of overarching Control Plane Machine Set feature into single release based effort
Customer Considerations
n/a
Documentation Considerations
Nothing outside documentation that shows the Azure platform is supported as part of Control Plane Machine Sets
Interoperability Considerations
n/a
Goal:
Control plane nodes in the cluster can be scaled up or down, lost and recovered, with no more importance or special procedure than that of a data plane node.
Problem:
There is a lengthy special procedure to recover from a failed control plane node (or majority of nodes) and to add new control plane nodes.
Why is this important:
- Increased operational simplicity and scale flexibility of the cluster’s control plane deployment.
Lifecycle Information:
- Core
Previous Work:
Dependencies:
- Etcd operator
Prioritized epics + deliverables (in scope / not in scope):
Estimate (XS, S, M, L, XL, XXL):
User Story:
As a developer, I want to be able to:
- Create Azure control plane nodes using MachineSets.
so that I can achieve
- More control over the nodes using the MachineAPI Operator.
Acceptance Criteria:
Description of criteria:
- New CRD ControlPlaneMachineSet is used and populated.
- New manifest is created for the ControlPlaneMachineSet.
- Fields required for the CRD are set.
(optional) Out of Scope:
Engineering Details:
- The code for Azure creation of control plane nodes is here: https://github.com/openshift/installer/blob/master/pkg/asset/machines/azure/machines.go
- Instead of using machineapi.Machine, we need to use the machineapi.ControlPlaneMachineSet
- We might need to update our openshift/api version to get the MachineSet object that we need to use.
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
ovnk manifests in CNO is not up-to-date, we want to sync it with manifests in microshift repo .
With the enablement of OpenShift clusters with mixed architecture capable compute nodes it is necessary to have support for manifest listed images so the correct images/binaries can be pulled onto the relevant nodes.
Included in this should be the ability to
- use oc debug successfully on all node types
- support manifest listed images in the internal registry
- have the ability to import manifest listed images
Epic Goal
- Complete manifest lists support on image streams. The work was initiated on epic
IR-192
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
ACCEPTANCE CRITERIA
- Pushing a manifest list to the image registry should result in an image stream created for the manifest list
- Image objects should be created for the manifest list, as well as all of its sub-manifests
- The Image object for the manifest list should contain references to all of its sub-manifests under the dockerImageManifests field
- Pulling a sub-manifest of a manifest list by digest should work when the user has access to the image stream
Notes:
- When a manifest is pushed by sha an Image object should be created
- You can use `skopeo copy` with the `--all` flag to push a manifest list and all its sub-manifests to the registry
- Authorization needs to work the same they do for images created via imagestreamimport
Notes:
- The image registry pull-thru should be aware of the existence of manifest lists so it can pull them and correctly check for permissions
ACCEPTANCE CRITERIA
- The cmd line flag should result in the ImageStreamImport and ImageStream objects specifying the API manifest list flag
DOCUMENTATION
- The new flag should be mentioned in the product documentation.
OPEN QUESTIONS
- What should be the name of the flag and what possible values should it have?
- Should be the same as in https://github.com/openshift/oc/pull/1289 (it's final version)
ACCEPTANCE CRITERIA
- `oc get imagestreamimages` should behave exactly as it currently does
Acceptance Criteria
- The pruner should delete dangling manifest lists (or OCI index) json from storage (dangling manifest lists are manifest lists that are not associated with an image object)
- The pruner should keep manifest lists (or OCI index) json in storage for manifest lists that are associated with an image object
Documentation
Nothing new to document.
ACCEPTANCE CRITERIA
- The cmd line flag should result in the ImageStreamImport and ImageStream objects specifying the API manifest list flag
Notes:
- The image registry pull-thru should be aware of the existence of sub-manifests so it can pull them and correctly check for permissions
Acceptance Criteria
- There should be information about the image index in the web console.
Open Questions
- What kind of information should be there? Should it be for ImageStreamImages, or for Images, or for both? Should child manifests be clickable?
- The answer to showing information about ImageStreamImages or Images depends on what is currently shown in the console - we should go with what's there.
Epic Goal
- Support OpenShift and the IPI workflow on GCP to use Shielded VMs feature from Google Cloud
Why is this important?
- Many Google Cloud customers want to leverage Shielded VMs feature while deploying OpenShift on GCP
Scenarios
- As a user, I want to be able to instruct the OpenShift Installer to use Shield VMs while deploying the platform on Google Cloud so I can use the Shield VMs feature from GCP on every Node
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
OCPBUGS-4522coreos fail to boot on GCP when enabling secure boot
Open questions::
- Should we add API to support all shielded VMs options (Secure Boot, vTPM, Integrity Monitoring) or just Secure Boot?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Reduce CPU
- Remove CPU limits from all containers
- Reduce the CPU requests for all the pods to the "at rest" values shown in the attached analysis document.
- Reduce Memory (same as with CPU)
- Add workload partitioning annotation to the pods so that we can use workload partitioning
- Reduce Image sizes
Resource measurements: https://docs.google.com/spreadsheets/d/1eLBkG4HhlKlxRlB9H8kjuXs5F3zzVOPfkOOhFIOrfzU/edit#gid=0
Why is this important?
- LVMS running on edge systems requires a smaller footprint.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
LVMS requirements are being reduced, so this should be reflected in the Assisted Installer.
Cloned from OCPSTRAT-377 to represent the backport to 4.13
Backport questions:
1) What's the impact/cost to any other critical items on the next release?
Installer and edge are mostly focused on activation/retention and working the list top-to-bottom without release blockers. This is an activation item highly coveted by SD and applicable in existing versions.
2) Is it a breaking change to the existing fleet?
No.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic —
Links:
Enhancement PR: https://github.com/openshift/enhancements/pull/1397
API PR: https://github.com/openshift/api/pull/1460
Ingress Operator PR: https://github.com/openshift/cluster-ingress-operator/pull/928
Background
Feature Goal: Support OpenShift installation in AWS Shared VPC scenario where AWS infrastructure resources (at least the Private Hosted Zone) belong to an account separate from the cluster installation target account.
The ingress operator is responsible for creating DNS records in AWS Route53 for cluster ingress. Prior to the implementation of this epic, the ingress operator doesn't have the capability to add DNS records into an existing Route 53 hosted zone in the shared VPC.
Epic Goal
- Add support to the ingress operator for creating DNS records in preexisting Route53 private hosted zones for Shared VPC clusters
Non-Goals
- Ingress operator support for day-2 operations (i.e. changes to the AWS IAM Role value after installation)
- E2E testing (will be handled by the Installer Team)
Design
As described in the WIP PR https://github.com/openshift/cluster-ingress-operator/pull/928, the ingress operator will consume a new API field that contains the IAM Role ARN for configuring DNS records in the private hosted zone. If this field is present, then the ingress operator will use this account to create all private hosted zone records. The API fields will be described in the Enhancement PR.
The ingress operator code will accomplish this by defining a new provider implementation that wraps two other DNS providers, using one of them to publish records to the public zone and the other to publish records to the private zone.
External DNS Operator Impact
See NE-1299
AWS Load Balancer Operator (ALBO) Impact
See NE-1299
Why is this important?
- Without this ingress operator support, OpenShift users are unable to create DNS records in a preexisting Route53 private hosted zone which means OpenShift users can't share the Route53 component with a Shared VPC
- Shared VPCs are considers AWS best practice
Scenarios
- ...
Acceptance Criteria
- Unit tests must be written and automatically run in CI (E2E tests will be handled by the Installer Team)
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Ingress Operator creates DNS Records in preexisting Route53 private hosted zones for shared VPC Clusters
- Network Edge Team has reviewed all of the related enhancements and code changes for Route53 in Shared VPC Clusters
Dependencies (internal and external)
- Installer Team is adding the new API fields required for enabling sharing Route53 with in Shared VPCs in https://issues.redhat.com/browse/CORS-2613
- Testing this epic requires having access to two AWS account
Previous Work (Optional):
- Significant discussion was done in this thread: https://redhat-internal.slack.com/archives/C68TNFWA2/p1681997102492889?thread_ts=1681837202.378159&cid=C68TNFWA2
- Slack channel #tmp-xcmbu-114
Open questions:
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Enable/confirm installation in AWS shared VPC scenario where Private Hosted Zone belongs to an account separate from the cluster installation target account
Why is this important?
- AWS best practices suggest this setup
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Backport of 4.13 AWS Shared VPC Feature
Backport of 4.13 AWS Shared VPC Feature
Feature Overview
There are specific opportunities to improve the administrative experience when using the machine API, this topic is around the setting up of appropriate default values (saving time and errors) and also early validation of said values to allow quick detection of errors.
There are also specific areas where we lack capabilities that are key to the end user experience.
Goals
- Include reasonable defaults where calls are made to APIs
- Where possible validate calls made to APIs
- Do this for all cloud provider interactions
- Address key parts of missing functionality in subcomponents
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| Implement validation/defaulting for AWS | Yes | |
| Implement validation/defaulting for GCP | ||
| Implement validation/defaulting for Azure | ||
| Implement validation/defaulting for vSphere |
Out of Scope
n/a
Background, and strategic fit
This type of checking can cut down on errors, reducing outages and also time wasted on identifying issues
Assumptions
Customer Considerations
Customers must be ready to handle if their settings are not accepted.
Documentation Considerations
- Target audience: cluster admins
- Updated content: update docs to mention the defaults selected and the validation that occurs, also what to do in the event validation fails.
User Story
As an OpenShift admin on GCP I want to replace my control plane node. Currently, the new control plane machine does not get assigned instance group. This is prevents the internal load balancer working on the new node until you set it manually using the GCP console. This prevents automatic control plane replacement using the CPMSO on GCP.
Background
CAPI implementation:
_https://github.com/openshift/cluster-api-provider-gcp/blob/f6b71187180cb35b93caee08eddbccb66cb28ab6/cloud/services/compute/instances/reconcile.go#L141_
Steps
- Create abstraction around GCP instance group API
- Register machine to instance group on create
- Remove machine from instance group on delete
Stakeholders
- Cluster Infrastructure (CPMSO)
Definition of Done
- Control plane machines are reconciled into correct instance group
- Docs
- N/A
- Testing
- Manual node replacement as CPMS is currently disabled on GCP
Note: Replace text in red with details of your feature request.
Feature Overview
Extend the Workload Partitioning feature to support multi-node clusters.
Goals
Customers running RAN workloads on C-RAN Hubs (i.e. multi-node clusters) that want to maximize the cores available to the workloads (DU) should be able to utilize WP to isolate CP processes to reserved cores.
Requirements
A list of specific needs or objectives that a Feature must deliver to satisfy the Feature. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| requirement | Notes | isMvp? |
Describe Use Cases (if needed)
< How will the user interact with this feature? >
< Which users will use this and when will they use it? >
< Is this feature used as part of current user interface? >
Out of Scope
Background, and strategic fit
< What does the person writing code, testing, documenting need to know? >
Assumptions
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Customer Considerations
< Are there specific customer environments that need to be considered (such as working with existing h/w and software)?>
< Are there Upgrade considerations that customers need to account for or that the feature should address on behalf of the customer?>
<Does the Feature introduce data that could be gathered and used for Insights purposes?>
Documentation Considerations
< What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)? >
< What does success look like?>
< Does this feature have doc impact? Possible values are: New Content, Updates to existing content, Release Note, or No Doc Impact>
< If unsure and no Technical Writer is available, please contact Content Strategy. If yes, complete the following.>
- <What concepts do customers need to understand to be successful in [action]?>
- <How do we expect customers will use the feature? For what purpose(s)?>
- <What reference material might a customer want/need to complete [action]?>
- <Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available. >
- <What is the doc impact (New Content, Updates to existing content, or Release Note)?>
Interoperability Considerations
< Which other products and versions in our portfolio does this feature impact?>
< What interoperability test scenarios should be factored by the layered product(s)?>
Questions
| Question | Outcome |
Since this feature requires that it be turned on ONLY at install time, and can not be turned off, the best place we've found to set the Infrastructure.Status option is through the openshift installer. This has a few benefits, the primary of which being simplifying how this feature get's used by upstream teams such as Assisted Installer and ZTP. If we expose this option as an install config it makes it trivial for those consumers to support turning on this feature at install time.
We'll need to update the openshift installer configuration option to support a flag for CPU Partitioning at install time.
We'll need to add a new flag to the InstallConfig
cpuPartitioningMode: None | AllNode
Update admission controller to remove check for SNO
Add Node Admission controller to stop nodes from joining that do not have CPU Partitioning turned on.
Add support to Installer to bootstrap cluster with the configurations for CPU Partitioning based off of the infrastructure flag and NTO generated configurations.
We need to call NTO bootstrap render during the bootstrap cycle. This will follow the same pattern that MCO follows and other components that render during bootstrap.
Update NTO to apply workload pinning change to the whole cluster.
Repo: https://github.com/openshift/cluster-node-tuning-operator
Incorporate Files workload-pinning