Incomplete Features
When this image was assembled, these features were not yet completed. Therefore, only the Jira Cards included here are part of this release
Epic Goal
The EPIC purpose is to hold all the required works to integrate CAPI & CAPI providers (CAPA & CAPZ) into MCE
Why is this important?
It is important for end users to be able to have life cycle management for ROSA-HCP and ARO-HCP clusters
Scenarios
...
Acceptance Criteria
...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub
Issue> - DEV - Upstream documentation merged: <link to meaningful PR or GitHub
Issue> - DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Doc issue opened with a completed template. Separate doc issue
opened for any deprecation, removal, or any current known
issue/troubleshooting removal from the doc, if applicable.
We need to test using the redhat cert-manager operator instead of using the upstream helm chart for certificate manager as our doc mentioned here
Placeholder feature for ccx-ocp-core maintenance tasks.
This is epic tracks "business as usual" requirements / enhancements / bug fixing of Insights Operator.
The following Insights APIs use duration attributes:
- insightsoperator.operator.openshift.io
- datagathers.insights.openshift.io
The kubebuilder validation patterns are defined as
^0|([1-9][0-9]*(\\.[0-9]+)?(ns|us|µs|ms|s|m|h))+$
and
^([1-9][0-9]*(\\.[0-9]+)?(ns|us|µs|ms|s|m|h))+$
Unfortunately this is not enough and it fails in case of updating the resource e.g with value "2m0s".
The validation pattern must allow these values.
It looks like the insights-operator doesn't work with IPv6, there are log errors like this:
E1209 12:20:27.648684 37952 run.go:72] "command failed" err="failed to run groups: failed to listen on secure address: listen tcp: address fd01:0:0:5::6:8000: too many colons in address"
It's showing up in metal techpreview jobs.
The URL isn't being constructed correctly, use NetJoinHostPort over Sprintf. Some more details here https://github.com/stbenjam/no-sprintf-host-port. There's a non-default linter in golangci-lint for this.
Component Readiness has found a potential regression in the following test:
[sig-architecture] platform pods in ns/openshift-insights should not exit an excessive amount of times
Test has a 56.36% pass rate, but 95.00% is required.
Sample (being evaluated) Release: 4.18
Start Time: 2024-12-02T00:00:00Z
End Time: 2024-12-09T16:00:00Z
Success Rate: 56.36%
Successes: 31
Failures: 24
Flakes: 0
View the test details report for additional context.
Background
In order for customers or internal teams to troubleshoot better, they need to be able to see the dashboards created using Perses inside the OpenShift console. We will use the monitoring plugin which already supports console dashboards comming from Grafana, to provide the Perses dashboard funcionallity
Outcomes
Create a component in the monitoring plugin that can render a Perses dashboard based on the dashboard schema returned by the Perses API.
There are 2 dropdowns, one for selecting namespaces and another for selecting the dashboards in the selected namespace.
Steps
- Use the same dashboards route for the Perses dashboards component
- Use the monitoring-console-plugin proxy to call the Perses API, this was covered by https://issues.redhat.com/browse/OU-432
- Choose the component being rendered: Dashboards or Perses Dashboards if Perses is detected in the cluster
- Perses dashboards
- Add the namespace dropdown, visible only if Perses is detected on the cluster using an API call to the proxy
- Create a Perses: hello world component to be rendered in the dashboard page
- When selecting a Perses project on the dropdown, render the Perses hello world component.
- When selecting the legacy namespace, render the current Dashboard component
- The implementation of the Perses component will be done in https://issues.redhat.com/browse/OU-618
- Dashboards. Keep the page as it is
- Perses dashboards
Previous work
Create dashboard flow chart
Background
In order to allow customers and internal teams to see dashboards created using Perses, we must add them as new elements on the current dashboard list
Outcomes
- When navigating to the Monitoring / Dashboards. Perses dashboards are listed with the current console dashboards. The extension point is backported to 4.14
Steps
- COO (monitoring-console-plugin)
- Add the Perses dashboards feature called "perses-dashboards" in the monitoring plugin.
- Create a function to fetch dashboards from the Perses API
- CMO (monitoring-plugin)
- An extension point is added to inject the function to fetch dashboards from Perses API and merge the results with the current console dashboards
Background
In order for customers or internal teams to troubleshoot better, they need to be able to see the dashboards created using Perses inside the OpenShift console. We will use the monitoring plugin which already supports console dashboards coming from Grafana, to provide the Perses dashboard functionality
Outcomes
Create a component in the monitoring plugin that can render a Perses dashboard based on the dashboard schema returned by the Perses API.
There are 2 dropdowns, one for selecting namespaces and another for selecting the dashboards in the selected namespace.
Steps
- From the Perses Hello world component created in
OU-433 - Copy the dashboard selector, variables, time range and auto refresh from the current Dashboard component to Perses component
- Use the DashboardView component from Perses to render the perses dashboard, based on the Perses dashboard definition.
- Create a single PersesWrapper and include all the Perses providers like in the Distributed tracing plugin. Wrap also the variables in this provider.
- Use the Patternfly theme for Perses (ECharts) charts
- Adjust the Grid to use Patternfly grid instead of material UI Grid
Previous work
Create dashboard flow chart
1. Proposed title of this feature request:
Insights Operator Entitlements for Multi-Arch Clusters
2. What is the nature and description of the request?
When the Insights Operator syncs the cluster's Simple Content Access (SCA) certificate, it should survey the architectures of the worker nodes on the cluster and enable repositories for the appropriate architectures.
3. Why does the customer need this? (List the business requirements here)
Konflux and other customers needs this to produce multi-arch container images that install RHEL content via yum/dnf.
4. List any affected packages or components.
- Insights Operator
- Candlepin
Insights Operator periodically pulls down the entitlements certificates into the cluster. Technically it means there's a HTTP POST request to the
https://api.openshift.com/api/accounts_mgmt/v1/certificates. The payload of the POST requests looks like:
`{"type": "sca","arch": "x86_64"}`
And this is currently the limitation. It prevents builds using the entitlement certificates on different architectures as s390x, ppc64le, arm64.
https://kubernetes.io/docs/reference/labels-annotations-taints/#kubernetes-io-arch label can be used
1. Proposed title of this feature request:
Insights Operator Entitlements for Multi-Arch Clusters
2. What is the nature and description of the request?
When the Insights Operator syncs the cluster's Simple Content Access (SCA) certificate, it should survey the architectures of the worker nodes on the cluster and enable repositories for the appropriate architectures.
3. Why does the customer need this? (List the business requirements here)
Konflux and other customers needs this to produce multi-arch container images that install RHEL content via yum/dnf.
4. List any affected packages or components.
- Insights Operator
- Candlepin
tldr: three basic claims, the rest is explanation and one example
- We cannot improve long term maintainability solely by fixing bugs.
- Teams should be asked to produce designs for improving maintainability/debugability.
- Specific maintenance items (or investigation of maintenance items), should be placed into planning as peer to PM requests and explicitly prioritized against them.
While bugs are an important metric, fixing bugs is different than investing in maintainability and debugability. Investing in fixing bugs will help alleviate immediate problems, but doesn't improve the ability to address future problems. You (may) get a code base with fewer bugs, but when you add a new feature, it will still be hard to debug problems and interactions. This pushes a code base towards stagnation where it gets harder and harder to add features.
One alternative is to ask teams to produce ideas for how they would improve future maintainability and debugability instead of focusing on immediate bugs. This would produce designs that make problem determination, bug resolution, and future feature additions faster over time.
I have a concrete example of one such outcome of focusing on bugs vs quality. We have resolved many bugs about communication failures with ingress by finding problems with point-to-point network communication. We have fixed the individual bugs, but have not improved the code for future debugging. In so doing, we chase many hard to diagnose problem across the stack. The alternative is to create a point-to-point network connectivity capability. this would immediately improve bug resolution and stability (detection) for kuryr, ovs, legacy sdn, network-edge, kube-apiserver, openshift-apiserver, authentication, and console. Bug fixing does not produce the same impact.
We need more investment in our future selves. Saying, "teams should reserve this" doesn't seem to be universally effective. Perhaps an approach that directly asks for designs and impacts and then follows up by placing the items directly in planning and prioritizing against PM feature requests would give teams the confidence to invest in these areas and give broad exposure to systemic problems.
Relevant links:
- Documentation:
- Edge Diagnostics Scratchpad, our team's internal diagnostic guide.
- Troubleshooting OCP networking issues - The complete guide, the SDN team's diagnostic guide.
- Linux Performance, Brendan Gregg's guide to analyzing Linux performance issues.
- RFC: A proper feedback loop on Alerts.
- OpenShift Router Reload Technical Overview on Access.
- Performance Scaling HAProxy with OpenShift on Access.
- How to collect worker metrics to troubleshoot CPU load, memory pressure and interrupt issues and networking on worker nodes in OCP 4 on Access.
- OpenShift Performance and Scale Knowledge Base on Mojo, results from OpenShift scalability testing.
- Scalability and performance, OCP 4.5 documentation about the router's currently known scalability limits.
- Scaling OpenShift Container Platform HAProxy Router, OCP 3.11 documentation about the manual performance configuration that was possible in OCP 3.
- Timing web requests with cURL and Chrome from the Cloudflare blog.
- tcpdump advanced filters, some useful tcpdump commands.
- OpenShift SDN - Networking, OCP 3.11 documentation on the SDN (useful background reading).
- Ingress Operator and Controller Status Conditions, design document for improved status condition reporting.
- Observability tips for HAProxy, a slide deck by Willy Tarreau.
- Interesting Traces - Out of Order versus Retransmissions, analysis using tshark.
- The PCP Book: A Complete Documentation of Performance Co-Pilot, by Yogesh Babar.
- Debugging kernel networking bug, brief guide to using SystemTap on RHCOS.
- Troubleshooting throughput issues from the OCP 4.5 documentation.
- Troubleshooting OpenShift Clusters and Workloads.
- Red Hat Enterprise Linux Network Performance Tuning Guide (PDF).
- openshift/enhancements#289 stability: point to point network check, a diagnostic built into the kube-apiserver operator.
- Diagnostic tools:
- dropwatch to watch for packet drops.
- ethtool to check NIC configuration.
- iovisor/bcc: BCC - Tools for BPF-based Linux IO analysis, networking, monitoring, and more to trace and diagnose various issues in the networking stack.
- r-curler to gather timing information about HTTP/HTTPS connections.
- route-monitor, to monitor routes for reachability.
- hping(3), a programmable packet generator.
- OpenTracing / Jaeger in OpenShift.
- node-problem-detector, a possible integration point for new diagnostics.
- Using SystemTap by Brendan Gregg.
- DTrace SystemTap cheatsheet (PDF).
- Visualization and more sophisticated diagnostic tools:
- eldadru/ksniff, kubectl plugin for tcpdump & Wireshark.
- ironcladlou/ditm, Dan's "Dan in the Middle" tool.
- Skydive, network diagnostic and visualization tool.
- ali, a "load testing tool capable of performing real-time analysis" with visualization.
- Testing tools:
- Case studies:
- BZ1763206 is an example of diagnosing DNS latency/timeouts.
- BZ1829779 Investigation details the diagnosis of route latency.
- BZ1845545 is an example of diagnosing misconfigured DNS for an external LB.
- Debugging network stalls on Kubernetes, from the GitHub Blog, about diagnosing Kubernetes performance issues related to ksoftirqd.
Add a NID alias to OWNERS_ALIASES and update the OWNERS file in test/extended/router and add OWNERS file to test/extended/dns
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision IBM Cloud VPC infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The IBM Cloud VPC IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing IBM Cloud VPC Terraform provider. Specifically, we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Feature Overview
As a cluster-admin, I want to run update in discrete steps. Update control plane and worker nodes independently.
I also want to back-up and restore incase of a problematic upgrade.
Background:
This Feature is a continuation of https://issues.redhat.com/browse/OCPSTRAT-180.
Customers are asking for improvements to the upgrade experience (both over-the-air and disconnected). This is a feature tracking epics required to get that work done.Below is the list of done tasks.
OTA-700Reduce False Positives (such as Degraded)OTA-922- Better able to show the progress made in each discrete step- [Cover by status command]Better visibility into any errors during the upgrades and documentation of what they error means and how to recover.
Goals
- Have an option to do upgrades in more discrete steps under admin control. Specifically, these steps are:
- Control plane upgrade
- Worker nodes upgrade
- Workload enabling upgrade (i..e. Router, other components) or infra nodes
- An user experience around an end-2-end back-up and restore after a failed upgrade
- MCO-530 - Support in Telemetry for the discrete steps of upgrades
References
Epic Goal
- Eliminate the gap between measured availability and Available=true
Why is this important?
- Today it's not uncommon, even for CI jobs, to have multiple operators which blip through either Degraded=True or Available=False conditions
- We should assume that if our CI jobs do this then when operating in customer environments with higher levels of chaos things will be even worse
- We have had multiple customers express that they've pursued rolling back upgrades because the cluster is telling them that portions of the cluster are Degraded or Unavailable when they're actually not
- Since our product is self-hosted, we can reasonably expect that the instability that we experience on our platform workloads (kube-apiserver, console, authentication, service availability), will also impact customer workloads that run exactly the same way: we're just better at detecting it.
Scenarios
- In all of the following, assume standard 3 master 0 worker or 3 master 2+ worker topologies
- Add/update CI jobs which ensure 100% Degraded=False and Available=True for the duration of upgrade
- Add/update CI jobs which measure availability of all components which are not explicitly defined as non-HA (ex: metal's DHCP server is singleton)
- Address all identified issues
Acceptance Criteria
- openshift/enhancements CONVENTIONS outlines these requirements
- CI - Release blocking jobs include these new/updated tests
- Release Technical Enablement - N/A if we do this we should need no docs
- No outstanding identified issues
Dependencies (internal and external)
- ...
Previous Work (Optional):
- Clayton, David, and Trevor identified many issues early in 4.8 development but were unable to ensure all teams addressed them that list is in this query, teams will be asked to address everything on this list as a 4.9 blocker+ bug and we will re-evaluate status closer to 4.9 code freeze to see which may be deferred to 4.10
https://bugzilla.redhat.com/buglist.cgi?columnlist=product%2Ccomponent%2Cassigned_to%2Cbug_severity%2Ctarget_release%2Cbug_status%2Cresolution%2Cshort_desc%2Cchangeddate&f1=longdesc&f2=cf_environment&j_top=OR&list_id=12012976&o1=casesubstring&o2=casesubstring&query_based_on=ClusterOperator%20conditions&query_format=advanced&v1=should%20not%20change%20condition%2F&v2=should%20not%20change%20condition%2F
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- DEV - Tests in place
- DEV - No outstanding failing tests
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
These are alarming conditions which may frighten customers, and we don't want to see them in our own, controlled, repeatable update CI. This example job had logs like:
Feb 18 21:11:25.799 E clusteroperator/openshift-apiserver changed Degraded to True: APIServerDeployment_UnavailablePod: APIServerDeploymentDegraded: 1 of 3 requested instances are unavailable for apiserver.openshift-apiserver ()
And the job failed, but none of the failures were "something made openshift-apiserver mad enough to go Degraded".
Definition of done:
- Same as
OTA-362 - File bugs or the existing issues
- If bug exists then add the tests to the exception list.
- Unless tests are in exception list , they should fail if we see degraded != false.
Feature Overview
This feature aims to enable customers of OCP to integrate 3rd party KMS solutions for encrypting etcd values at rest in accordance with:
https://kubernetes.io/docs/tasks/administer-cluster/kms-provider/
Goals
- Bring KMS v2 API to beta|stable level
- Create/expose mechanisms for customers to plug in containers/operators which can serve the API server's needs (can it be an operator, something provided via CoreOS layering, vanilla container spec provided to API server operator?)
- Provide similar UX experience for all of self-hosted, hypershift, SNO scenarios
- Provide example container/operator for the mechanism
General Prioritization for the Feature
- Approved design for detection & actuation for stand-alone OCP clusters.
- How to detect a problem like an expired/lost key and no contact with the KMS provider?
- How to inform/notify the situation, even at node level, of the situation
- Tech Preview (Feature gated) enabling Kube-KMS v2 for partners to start working on KMS plugin provider integrations:
- Cloud: (priority Azure > AWS > Google)
- Azure KMS
- Azure Dedicated HSM
- AWS KMS
- AWS CloudHSM
- Google Cloud HSM
- On-premise:
- HashiCorp Vault
- EU FSI & EU Telco KMS/HSM top-2 providers
- Cloud: (priority Azure > AWS > Google)
- GA after at least one stable KMS plugin provider
Scenario:
For an OCP cluster with external KMS enabled:
- The customer loses the key to the external KMS
- The external KMS service is degraded or unavailable
How doe the above scenario(s) impact the cluster? The API may be unavailable
Goal:
- Detection: The ability to detect these failure condition(s) and make it visible to the cluster admin.
- Actuation: To what extent can we restore the cluster? ( API availability, Control Plane operators). Recovering customer data is outside of the scope
Investigation Steps:
Detection:
- How do we detect issues with the external KMS?
- How do we detect issues with the KMS plugins?
- How do we surface the information that an issue happened with KMS?
- Metrics / Alerts? Will not work with SNO
- ClusterOperatorStatus?
Actuation:
- Is the control-plane self-recovering?
- What actions are required for the user to recover the cluster partially/completely?
- Complete: kube-apiserver? KMS plugin?
- Partial: kube-apiserver? Etcd? KMS plugin?
User stories that might result in KCS:
- KMS / KMS plugin unavailable
- Is there any degradation? (most likely not with kms v2)
- KMS unavailable and DEK not in cache anymore
- Degradation will most likely occur, but what happens when the KMS becomes available again? Is the cluster self-recovering?
- Key has been deleted and later recovered
- Is the cluster self-recovering?
- KMS / KMS plugin misconfigured
- Is the apiserver rolled-back to the previous healthy revision?
- Is the misconfiguration properly surfaced?
Plugins research:
- What are the pros and cons of managing the plugins ourselves vs leaving that responsibility to the customer?
- What is the list of KMS we need to support?
- Do all the KMS plugins we need to use support KMS v2? If not reach out to the provider
- HSMs?
POCs:
- Have a running POC of KMS on OCP to iterate over the user stories and start testing things out
- Have a hacked version of o/k with https://github.com/kubernetes/enhancements/tree/master/keps/sig-auth/3926-handling-undecryptable-resources to be able to easily take actions to fix the clusters as it will be for the customers in 4.17.
Acceptance Criteria:
- Document the detection and actuation process in a KEP.
- Generate new Jira work items based on the new findings.
We did something similar for the aesgcm encryption type in https://github.com/openshift/api/pull/1413/.
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Provide a long term solution to SELinux context labeling in OCP. Continue the implementation with RWO/RWX PVs which are the most expected from the field. Start with a TechPreview support grade.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
As of today when selinux is enabled, the PV's files are relabeled when attaching the PV to the pod, this can cause timeout when the PVs contains lot of files as well as overloading the storage backend.
https://access.redhat.com/solutions/6221251 provides few workarounds until the proper fix is implemented. Unfortunately these workaround are not perfect and we need a long term seamless optimised solution.
This feature tracks the long term solution where the PV FS will be mounted with the right selinux context thus avoiding to relabel every file. This covers RWO/RWX PVs, RWOP is already being implemented and should GA in 4.17.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Should pass all regular regression CI. All the drivers we ship should have it enabled and partners may enable it if they want it to be consumed.
Performances should drascillaly improved and security should remain the same as the legacy chcon approach.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | both |
| Classic (standalone cluster) | Y |
| Hosted control planes | Y |
| Multi node, Compact (three node), or Single node (SNO), or all | all |
| Connected / Restricted Network | Both |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all |
| Operator compatibility | AWS EBS, Azure Disk, GCP PD, IBM VPC block, OSP cinder, vSphere |
| Backport needed (list applicable versions) | no |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | No need |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- Apply new context when there is none
- Change context of all files/folders when changing context
- RWO & RWX PVs
As we are relying on mount context there should not be any relabeling (chcon) because all files / folders will inherit the context from the mount context
More on design & scenarios in the KEP
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
RWOP PVs
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Lots of support cases due to pod taking too long to start because of selinux relabeling with chcon. This epics covers the most "unpopular" RWX case specially for PVs with lots of files and backends that are "slow" at updating metadata.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Most cases / concerns are on RWX, RWOP was the first step and has limited customer's impact though it is easier to implement first and gather feedback / metrics. https://access.redhat.com/solutions/6221251
This feature track TP for RWO/RWX PVs
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Relnotes + table of drivers supporting it.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Partners may want to enable the feature.
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
Tracking upstream beta promotion of the SELinux context mounts for RWX/RWO PVs
Why is this important? (mandatory)
What are the benefits to the customer or Red Hat? Does it improve security, performance, supportability, etc? Why is work a priority?
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Description of problem:
Seeing this error occasionally when using the agent-based installer in 4.19.0-ec.2. This causes the installation to fail.
Feb 24 19:56:00 master-0 node-image-pull.sh[5150]: Currently on CoreOS version 9.6.20250121-0 Feb 24 19:56:00 master-0 node-image-pull.sh[5150]: Target node image is quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:3b38df9ee395756ff57e9fdedd5c366ac9b129330aea9d3b07f1431fe9bcbab1 Feb 24 19:56:00 master-0 ostree-containe[5317]: Fetching ostree-unverified-registry:quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:3b38df9ee395756ff57e9fdedd5c366ac9b129330aea9d3b07f1431fe9bcbab1 Feb 24 19:56:01 master-0 node-image-pull.sh[5317]: layers already present: 11; layers needed: 40 (691.0 MB) Feb 24 19:56:01 master-0 ostree-containe[5317]: layers already present: 11; layers needed: 40 (691.0 MB) Feb 24 19:56:01 master-0 node-image-pull.sh[5317]: error: Importing: Unencapsulating base: Layer sha256:2cda1fda6bb7b2171d8d65eb2f66101e513f33808a5e5ce0bf31fa0314e442ed: mkdirat: Read-only file system Feb 24 19:56:01 master-0 node-image-pull.sh[5150]: Failed to fetch release image; retrying...
Version-Release number of selected component (if applicable):
openshift 4.19.0-ec.2
How reproducible: Happens occasionally and inconsistently.
Steps to Reproduce:
1. Create the agent-installer iso via 'openshift-install agent create image'
2. Boot the ISO on 3 hosts - compact cluster
3.
Actual results:
Two of the hosts are installed correctly, in the 3rd host running bootstrap we see the error as above.
Expected results:
Installation succeeds.
As part of https://issues.redhat.com/browse/COS-2572, the OpenShift installer needs to be adapted so that it can work with bootimages which have no OCP content.
We want to ship OpenShift 4.19 with CAPO synced to upstream 0.12.x.
Two tasks:
1. In openshift/release, update merge-bot to sync CAPO main (current 4.19) to sync with upstream release-0.12 (instead of release-0.11)
2. In openshift/cluster-api-provider-openstack, wait for the bot to submit a sync and work out the PR to pass CI and merge.
This depends on OSASINFRA-3717. Per the discussion here, once that is complete and ORC is built by ART, we will need to update the PR for 2 to override the image.
Condition of satisfaction: ART has produced an image of CAPO synced to upstream 0.12.x.
Feature Overview (aka. Goal Summary)
- Initial Tech Preview of Next-Gen OLM UX: This ticket introduces the initial Tech Preview release of the next-generation OLM (OLM v1) user experience in the console.
- Unified Catalog UX: This ticket focuses on enabling a unified catalog UX in the console. This will allow customers to manage layered capabilities delivered through operators and partners' workloads, including OpenShift certified Helm charts, using the next-generation OLM (OLM v1) in the OpenShift console.
- In-Cluster Catalog Content Service: This is enabled through the novel in-cluster efficient catalog content service designed in
OCPSTRAT-1655and delivered in the 4.18 timeframe.
Goals (aka. expected user outcomes)
In essence, customers can:
- discover collections of k8s extension/operator contents released in the FBC format with richer visibility into their release channels, versions, update graphs, and the deprecation information (if any) to make informed decisions about installation and/or update them.
- install a k8s extension/operator declaratively and potentially automate with GitOps to ensure predictable and reliable deployments.
- update a k8s extension/operator to a desired target version or keep it updated within a specific version range for security fixes without breaking changes.
- remove a k8s extension/operator declaratively and entirely including cleaning up its CRDs and other relevant on-cluster resources (with a way to opt out of this coming up in a later release).
Requirements (aka. Acceptance Criteria):
1) Pre-installation:
- Both cluster-admins or non-privileged end-users can explore and discover the layered capabilities or workloads delivered by k8s extensions/operators or plain helm charts from a unified ecosystem catalog UI in the ‘Administrator Perspective’ in the console.
- Users can filter the available offerings based on the delivery mechanism/source type (i.e., operator-backed or plain helm charts), providers (i.e., from Red Hat or ISVs), valid subscriptions, infrastructure features, etc.
- Users can discover all versions in all channels that an offering/package defines in a catalog, select a version from a channel, and see its detailed description, provided APIs, and other metadata before the installation.
2) Installation:
- Users (who have access to OLM v1’s user facing ‘ClusterExtension’ API) using a ServiceAccount with sufficient permissions can install a k8s extension/operator with a desired target version or the latest version within a specific version range (from the associated channel) to get the latest security fixes.
- Users can see the recommended installation namespace if provided by the package authors for installation.
- Users get notified through error messages from the OLM API whenever two conflicting k8s extensions/operators (will be) owning the same API objects, i.e., no conflicting ownership, after triggering the installation.
- During the installation, users can see the installation progress reported from the ‘ClusterExtension’ API object.
- After installed, users (who have access to OLM v1’s user-facing ‘ClusterExtension’ API) can see can access the metadata of the installed k8s extension/operator to see essential information such as its provided APIs, example YAMLs of its provided APIs, descriptions, infrastructure features, valid subscriptions, etc.
3) Update:
- Users (who have access to OLM v1’s user facing ‘ClusterExtension’ API) can see what updates are available for their k8s extension/operators in the form of immediate target versions and the associated update channels.
- Users can trigger the update of a k8s extension/operator with a desired target version or the latest version within a specific version range (from the associated channel) to get the latest security fixes.
- Users get notified through error messages whenever a k8s extension/operator is prevented from updating to a newer version that has a backward incompatible CustomResourceDefinition (CRD) that will cause workload or k8s extension/operator breakage.
- During OpenShift cluster update, users get Informed when installed k8s extensions/operators do not support the next OpenShift version (when annotated by the package author/provider). Customers must update those k8s extensions/operators to a newer/compatible version before OLM unblocks the OpenShift cluster update.
- During the update, users can see the progress reported from the ‘ClusterExtension’ API object.
4) Uninstallation/Deletion:
- Users are made aware of OLM v1 by default cleanly remove an installed k8s extension/operator including deleting CustomResourceDefinitions (CRDs), custom resource objects (CRs) of the CRDs, and other relevant resources to revert the cluster to its original state before the installation.
- Users can see a list of resources that are relevant to the installed k8s extension/operator they are about to remove and then explicitly confirm the deletion.
Questions to Answer (Optional):
- What impact will the console's "perspective consolidation" initiative have on this?
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Our customers will experience a streamlined approach to managing layered capabilities and workloads delivered through operators, operators packaged in Helm charts, or even plain Helm charts. The next generation OLM will power this central distribution mechanism within the OpenShift in the future.
Customers will be able to explore and discover the layered capabilities or workloads, and then install those offerings and make them available on their OpenShift clusters. Similar to the experience with the current OperatorHub, customers will be able to sort and filter the available offerings based on the delivery mechanism (i.e., operator-backed or plain helm charts), source type (i.e., from Red Hat or ISVs), valid subscriptions, infrastructure features, etc. Once click on a specific offering, they see the details which include the description, usage, and requirements of the offering, the provided services in APIs, and the rest of the relevant metadata for making the decisions.
The next-gen OLM aims to unify workload management. This includes operators packaged for current OLM, operators packaged in Helm charts, and even plain Helm charts for workloads. We want to leverage the current support for managing plain Helm charts within OpenShift and the console for leveraging our investment over the years.
Documentation Considerations
Refer to the “Documentation Considerations” section of the OLM v1 GA feature.
Relevant documents
- Next-gen OLM UX: Unifying workload management
- Next-gen OLM UX: Unifying workload management
- Operator Framework F2F - PM Session
- PRD OLM 1.0
- OLM F2F Discussion - Roadmap
- Post F2F Roadmap
The RFC written for https://github.com/operator-framework/catalogd/issues/426 identified a desire to formalize the catalogd web API, and divided work into a set of v1.0-blocking changes to enable versioned web interfaces ([phase 1](https://github.com/operator-framework/catalogd/issues/427)) and non-blocking changes to express and extend a formalized API specification (phase 2).
This epic is to track the design and implementation work associated with phase 2. During phase 1 RFC review we identified that we needed more work to capture the extensibility design but didn't want to slow progress on the v1.0 blocking changes so the first step should be an RFC to capture the design goals for phase 2, and then any implementation trackers we feel are necessary.
Work here will be behind a feature gate.
- catalogd web api performance improvements RFC #1569
- implementing feature-gated, caching catalogd web query API #1603
- serve catalog content based on supplied parameters #1606
- catalogd web api benchmarking #1607
Downstreaming this feature
We need to follow this guide to downstream this feature: https://docs.google.com/document/d/1krN-4vwaE47aLRW9QjwD374-0Sh80taa_7goqVNi_-s/edit?tab=t.0#heading=h.9l63b4k04g9e
Modify cluster-olm-operator to watch for the new catalogd web api feature gate and implement reconciliation logic (openshift/ cluster-olm-operator)
See dev guide for more info: https://docs.google.com/document/d/1krN-4vwaE47aLRW9QjwD374-0Sh80taa_7goqVNi_-s/edit?tab=t.0#heading=h.th7069vduyim
Goal
This goals of this features are:
- As part of a Microsoft guideline/requirement for implementing ARO HCP, we need to design a shared-ingress to kube-apiserver because MSFT has internal restrictions on IPv4 usage.
Background
Given Microsoft's constraints on IPv4 usage, there is a pressing need to optimize IP allocation and management within Azure-hosted environments.
Interoperability Considerations
- Impact: Which versions will be impacted by the changes?
- Test Scenarios: Must test across various network and deployment scenarios to ensure compatibility and scale (perf/scale)
There's currently multiple ingress strategies we support for hosted cluster service endpoints (kas, nodePort, router...).
In a context of uncertainty about what use cases would be more critical to support, we initially exposed this in a flexible API that enables to potentially choose any combination of ingress strategies and endpoints.
ARO has internal restrictions on IPv4 usage. Because of this, to simplify the above and to be more cost effective in terms of infra we'd want to have a common shared ingress solution for all hosted clusters fleet.
Goal:
Graduate to GA (full support) Gateway API with Istio to unify the management of cluster ingress with a common, open, expressive, and extensible API.
Description:
Gateway API is the evolution of upstream Kubernetes Ingress APIs. The upstream project is part of Kubernetes, working under SIG-NETWORK. OpenShift is contributing to the development, building a leadership position, and preparing OpenShift to support Gateway API, with Istio as our supported implementation.
The plug-able nature of the implementation of Gateway API enables support for additional and optional 3rd-party Ingress technologies.
The team agrees, we should be running the upstream GWAPI conformance tests, as they are readily available and we are an integration product with GWAPI.
We need to answer these questions asked at the March 23, 2023 GWAPI team meeting:
Would it make sense to do it as an optional job in the cluster-ingress-operator?
Is OSSM running the Gateway Conformance test in their CI?
Review what other implementers do with conformance tests to understand what we should do (Do we fork the repo? Clone it? Make a new repo?)
Overview
Gateway API is the next generation of the Ingress API in upstream Kubernetes.
OpenShift Service Mesh (OSSM) and several other offering of ours like Kuadrant, Microshift and OpenShift AI all have critical dependencies on Gateway API's API resources. However, even though Gateway API is an official Kubernetes project its API resources are not available in the core API (like Ingress) and instead require the installation of Custom Resource Definitions (CRDs).
OCP will be fully in charge of managing the life-cycle of the Gateway API CRDs going forward. This will make the Gateway API a "core-like" API on OCP. If the CRDs are already present on a cluster when it upgrades to the new version where they are managed, the cluster admin is responsible for the safety of existing Gateway API implementations. The Cluster Ingress Operator (CIO) enacts a process called "CRD Management Succession" to ensure the transfer of control occurs safely, which includes multiple pre-upgrade checks and CIO startup checks.
Acceptance Criteria
- If not present the Gateway API CRDs should be deployed at the install-time of a cluster, and management thereafter handled by the platform
- Any existing CRDs not managed by the platform should be removed, or management and control transferred to the platform
- Only the platform can manage or make any changes to the Gateway API CRDs, others will be blocked
- Documentation about these APIs, and the process to upgrade to a version where they are being managed needs to be provided
Cross-Team Coordination
The organization as a whole needs to be made aware of this as new projects will continue to pop up with Gateway API support over the years. This includes (but is not limited to)
- OSSM Team (Istio)
- Connectivity Link Team (Kuadrant)
- MicroShift Team
- OpenShift AI Team (KServe)
Importantly our cluster infrastructure work with Cluster API (CAPI) is working through similar dilemmas for CAPI CRDs, and so we need to make sure to work directly with them as they've already broken a lot of ground here. Here are the relevant docs with the work they've done so far:
- lifecycling-cluster-api-crds-within-openshift - HackMD
OCPCLOUD-2114Investigate lifecycle of Cluster API APIs within OpenShift
What?
The purpose of this task is to provide API validation on OCP that blocks upgrades to Gateway API CRDs from all entities except the platform itself.
Why?
See the description of NE-1898.
How?
We will use a Validating Admission Policy (VAP) to block ALL actions on the Gateway API CRDs from ALL entities besides the Cluster Ingress Operator (CIO).
Blocking in the VAP should occur at the group level, meaning only the CIO is capable of creating or changing any CRDs across the entire group at any version. As such this VAP will block access to ALL Gateway API CRDs, not just the ones we use (GatewayClass, Gateway, HTTPRoute, GRPCRoute, ReferenceGrant). Note that this means experimental APIs (e.g. TCPRoute, UDPRoute, TLSRoute) and older versions of APIs (e.g. v1beta1.HTTPRoute) are restricted as well from creation/modification. The effect should be that only the standard versions of GatewayClass, Gateway, HTTPRoute, GRPCRoute and ReferenceGrant (at the time of writing, these fully represent the standard APIs) are present and nobody can modify those, or deploy any others.
This VAP should be deployed alongside the CIO manifests, such that it is deployed along with the CIO itself.
Prior Art
Example of a VAP restricting actions to a single entity: https://github.com/openshift/cluster-cloud-controller-manager-operator/blob/master/pkg/cloud/azure/assets/validating-admission-policy.yaml
Helpful Links
Here's where the current operator manifests can be found: https://github.com/openshift/cluster-ingress-operator/tree/edf5e71e8b08ef23a4d8f0b3fee5630c66625967/manifests
As a developer, I need a featuregate to develop behind so that the Gateway API work does not impact other development teams until tests pass.
The featuregate is currently in the DevPreviewNoUpgrade featureset. We need to graduate it to the TechPreviewNoUpgrade featureset to give us more CI signal and testing. Ultimately the featuregate needs to graduate to GA (default on) once tests pass so that the feature can GA.
See also:
- https://github.com/openshift/api/blob/master/README.md
- https://github.com/openshift/api/blob/master/features.md
- https://github.com/openshift/api/blob/master/config/v1/types_feature.go
Update the existing feature gate to enable Gateway API in clusters with either the DevPreviewNoUpgrade or TechPreviewNoUpgrade feature set.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Support BYOPKI for image verification in OCP
Why is this important?
- As an administrator of an independent org, I would like to verify our container images using our own CA.
Scenarios
- Verify container images using own CA
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
As an openshift developer, I want to extend the fields of ClusterImagePolicy CRD for BYOPKI verification, so the containerruntimeconfig controller can roll out the configurationto policy.json for verification.
Feature Overview (aka. Goal Summary)
OVN Kubernetes BGP support as a routing protocol for User Defined Network (Segmentation) pod and VM addressability.
Goals (aka. expected user outcomes)
OVN-Kubernetes BGP support enables the capability of dynamically exposing cluster scoped network entities into a provider’s network, as well as program BGP learned routes from the provider’s network into OVN.
OVN-Kubernetes currently has no native routing protocol integration, and relies on a Geneve overlay for east/west traffic, as well as third party operators to handle external network integration into the cluster. This enhancement adds support for BGP as a supported routing protocol with OVN-Kubernetes. The extent of this support will allow OVN-Kubernetes to integrate into different BGP user environments, enabling it to dynamically expose cluster scoped network entities into a provider’s network, as well as program BGP learned routes from the provider’s network into OVN. In a follow-on release, this enhancement will provide support for EVPN, which is a common data center networking fabric that relies on BGP.
Requirements (aka. Acceptance Criteria):
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
- Integration with 3rdparty load balancers that send packets directly to OpenShift nodes with the destination IP address of a targeted pod, without needing custom operators to detect which node a pod is scheduled to and then add routes into the load balancer to send the packet to the right node.
Questions to Answer (Optional):
Out of Scope
- Support of any other routing protocol
- Running separate BGP instances per VRF network
- Support for any other type of L3VPN with BGP, including MPLS
- Providing any type of API or operator to automatically connect two Kubernetes clusters via L3VPN
- Replacing the support that MetalLB provides today for advertising service IPs
- Asymmetric Integrated Routing and Bridging (IRB) with EVPN
Background
BGP
Importing Routes from the Provider Network
Today in OpenShift there is no API for a user to be able to configure routes into OVN. In order for a user to change how cluster traffic is routed egress into the cluster, the user leverages local gateway mode, which forces egress traffic to hop through the Linux host's networking stack, where a user can configure routes inside of the host via NM State. This manual configuration would need to be performed and maintained across nodes and VRFs within each node.
Additionally, if a user chooses to not manage routes within the host and use local gateway mode, then by default traffic is always sent to the default gateway. The only other way to affect egress routing is by using the Multiple External Gateways (MEG) feature. With this feature the user may choose to have multiple different egress gateways per namespace to send traffic to.
As an alternative, configuring BGP peers and which route-targets to import would eliminate the need to manually configure routes in the host, and would allow dynamic routing updates based on changes in the provider’s network.
Exporting Routes into the Provider Network
There exists a need for provider networks to learn routes directly to services and pods today in Kubernetes. Metal LB is already one solution whereby load balancer IPs are advertised by BGP to provider networks, and this feature development does not intend to duplicate or replace the function of Metal LB. Metal LB should be able to interoperate with OVN-Kubernetes, and be responsible for advertising services to a provider’s network.
However, there is an alternative need to advertise pod IPs on the provider network. One use case is integration with 3rd party load balancers, where they terminate a load balancer and then send packets directly to OCP nodes with the destination IP address being the pod IP itself. Today these load balancers rely on custom operators to detect which node a pod is scheduled to and then add routes into its load balancer to send the packet to the right node.
By integrating BGP and advertising the pod subnets/addresses directly on the provider network, load balancers and other entities on the network would be able to reach the pod IPs directly.
EVPN
Extending OVN-Kubernetes VRFs into the Provider Network
This is the most powerful motivation for bringing support of EVPN into OVN-Kubernetes. A previous development effort enabled the ability to create a network per namespace (VRF) in OVN-Kubernetes, allowing users to create multiple isolated networks for namespaces of pods. However, the VRFs terminate at node egress, and routes are leaked from the default VRF so that traffic is able to route out of the OCP node. With EVPN, we can now extend the VRFs into the provider network using a VPN. This unlocks the ability to have L3VPNs that extend across the provider networks.
Utilizing the EVPN Fabric as the Overlay for OVN-Kubernetes
In addition to extending VRFs to the outside world for ingress and egress, we can also leverage EVPN to handle extending VRFs into the fabric for east/west traffic. This is useful in EVPN DC deployments where EVPN is already being used in the TOR network, and there is no need to use a Geneve overlay. In this use case, both layer 2 (MAC-VRFs) and layer 3 (IP-VRFs) can be advertised directly to the EVPN fabric. One advantage of doing this is that with Layer 2 networks, broadcast, unknown-unicast and multicast (BUM) traffic is suppressed across the EVPN fabric. Therefore the flooding domain in L2 networks for this type of traffic is limited to the node.
Multi-homing, Link Redundancy, Fast Convergence
Extending the EVPN fabric to OCP nodes brings other added benefits that are not present in OCP natively today. In this design there are at least 2 physical NICs and links leaving the OCP node to the EVPN leaves. This provides link redundancy, and when coupled with BFD and mass withdrawal, it can also provide fast failover. Additionally, the links can be used by the EVPN fabric to utilize ECMP routing.
Customer Considerations
- For customers using MetalLB, it will continue to function correctly regardless of this development.
Documentation Considerations
Interoperability Considerations
- Multiple External Gateways (MEG)
- Egress IP
- Services
- Egress Service
- Egress Firewall
- Egress QoS
Epic Goal
OVN Kubernetes support for BGP as a routing protocol.
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
 Priority+ is set by engineering
Priority+ is set by engineering- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
CNO should deploy the new RouteAdvertisements OVN-K CRD.
When the OCP API flag to enable BGP support in the cluster is set, CNO should enable support on OVN-K through a CLI arg.
Feature Overview (aka. Goal Summary)
Customers in highly regulated environments are required to adopt strong ciphers. For control-plane components, this means all components must support the modern TLSProfile with TLS 1.3.
Note: Post-Quantum Cryptography support in TLS will ONLY be available with TLS 1.3, thus support is required. For more information about PQC support, see https://issues.redhat.com/browse/OCPSTRAT-1858)
During internal discussions [1] for RFE-4992 and follow-up conversations, it became clear we need a dedicated CI job to track and validate that OpenShift control-plane components are aligned and functional with the TLSProfiles configured on the system.
[1] https://redhat-internal.slack.com/archives/CB48XQ4KZ/p1713288937307359
Goals (aka. expected user outcomes)
- The resulting user outcome from this internal CI validation will be the support of TLS 1.3 in the OpenShift control-plane components.
Requirements (aka. Acceptance Criteria):
- Create a CI job that would test that the cluster stays fully operational when enabling the Modern TLS profile
- This requires updates to our docs
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | both |
| Classic (standalone cluster) | yes |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | all |
| Connected / Restricted Network | all |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all |
| Operator compatibility | ?? |
| Backport needed (list applicable versions) | n/a |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | n/a |
| Other (please specify) | unknown |
If we try to enable a Modern TLS profile:
EnvVarControllerDegraded: no supported cipherSuites not found in observedConfig
also, if we do manage to pass along the Modern TLS profile cipher suit, we see:
http2: TLSConfig.CipherSuites is missing an HTTP/2-required AES_128_GCM_SHA256 cipher (need at least one of TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 or TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256)
Feature Overview
This is Image mode on OpenShift. It uses the rpm-ostree native containers interface and not bootc but that is an implementation detail.
In the initial delivery of CoreOS Layering, it is required that administrators provide their own build environment to customize RHCOS images. That could be a traditional RHEL environment or potentially an enterprising administrator with some knowledge of OCP Builds could set theirs up on-cluster.
The primary virtue of an on-cluster build path is to continue using the cluster to manage the cluster. No external dependency, batteries-included.
On-cluster, automated RHCOS Layering builds are important for multiple reasons:
- One-click/one-command upgrades of OCP are very popular. Many customers may want to make one or just a few customizations but also want to keep that simplified upgrade experience.
- Customers who only need to customize RHCOS temporarily (hotfix, driver test package, etc) will find off-cluster builds to be too much friction for one driver.
- One of OCP's virtues is that the platform and OS are developed, tested, and versioned together. Off-cluster building breaks that connection and leaves it up to the user to keep the OS up-to-date with the platform containers. We must make it easy for customers to add what they need and keep the OS image matched to the platform containers.
Goals & Requirements
- The goal of this feature is primarily to bring the 4.14 progress (
OCPSTRAT-35) to a Tech Preview or GA level of support. - Customers should be able to specify a Containerfile with their customizations and "forget it" as long as the automated builds succeed. If they fail, the admin should be alerted and pointed to the logs from the failed build.
- The admin should then be able to correct the build and resume the upgrade.
- Intersect with the Custom Boot Images such that a required custom software component can be present on every boot of every node throughout the installation process including the bootstrap node sequence (example: out-of-box storage driver needed for root disk).
- Users can return a pool to an unmodified image easily.
- RHEL entitlements should be wired in or at least simple to set up (once).
- Parity with current features – including the current drain/reboot suppression list, CoreOS Extensions, and config drift monitoring.
This work describes the tech preview state of On Cluster Builds. Major interfaces should be agreed upon at the end of this state.
As a cluster admin of user provided infrastructure,
when I apply the machine config that opts a pool into On Cluster Layering,
I want to also be able to remove that config and have the pool revert back to its non-layered state with the previously applied config.
As a cluster admin using on cluster layering,
when an image build has failed,
I want it to retry 3 times automatically without my intervention and show me where to find the log of the failure.
As a cluster admin,
when I enable On Cluster Layering,
I want to know that the builder image I am building with is stable and will not change unless I change it
so that I keep the same API promises as we do elsewhere in the platform.
To test:
As a cluster admin using on cluster layering,
when I try to upgrade my cluster and the Cluster Version Operator is not available,
I want the upgrade operation to be blocked.
As a cluster admin,
when I use a disconnected environment,
I want to still be able to use On Cluster Layering.
As a cluster admin using On Cluster layering,
When there has been config drift of any sort that degrades a node and I have resolved the issue,
I want to it to resync without forcing a reboot.
As a cluster admin using on cluster layering,
when a pool is using on cluster layering and references an internal registry
I want that registry available on the host network so that the pool can successfully scale up
(MCO-770, MCO-578, MCO-574 )
As a cluster admin using on cluster layering,
when a pool is using on cluster layering and I want to scale up nodes,
the nodes should have the same config as the other nodes in the pool.
Maybe:
Entitlements: MCO-1097, MCO-1099
Not Likely:
As a cluster admin using on cluster layering,
when I try to upgrade my cluster,
I want the upgrade operation to succeed at the same rate as non-OCL upgrades do.
As a follow up to https://issues.redhat.com/browse/MCO-1284, the one field we identified that is best updated pre-GA is to make the baseImagePullSecret optional. The builder pod should have the logic to fetch from baseImagePullSecret if the user does not specify this via a MachineOSConfig object.
To make OCL ready for GA, the first step would be graduating the MCO's APIs from v1alpha1 to v1. This requires changes in the openshift/api repo.
This work describes the tech preview state of On Cluster Builds. Major interfaces should be agreed upon at the end of this state.
As a cluster admin of user provided infrastructure,
when I apply the machine config that opts a pool into On Cluster Layering,
I want to also be able to remove that config and have the pool revert back to its non-layered state with the previously applied config.
As a cluster admin using on cluster layering,
when an image build has failed,
I want it to retry 3 times automatically without my intervention and show me where to find the log of the failure.
As a cluster admin,
when I enable On Cluster Layering,
I want to know that the builder image I am building with is stable and will not change unless I change it
so that I keep the same API promises as we do elsewhere in the platform.
To test:
As a cluster admin using on cluster layering,
when I try to upgrade my cluster and the Cluster Version Operator is not available,
I want the upgrade operation to be blocked.
As a cluster admin,
when I use a disconnected environment,
I want to still be able to use On Cluster Layering.
As a cluster admin using On Cluster layering,
When there has been config drift of any sort that degrades a node and I have resolved the issue,
I want to it to resync without forcing a reboot.
As a cluster admin using on cluster layering,
when a pool is using on cluster layering and references an internal registry
I want that registry available on the host network so that the pool can successfully scale up
(MCO-770, MCO-578, MCO-574 )
As a cluster admin using on cluster layering,
when a pool is using on cluster layering and I want to scale up nodes,
the nodes should have the same config as the other nodes in the pool.
Maybe:
Entitlements: MCO-1097, MCO-1099
Not Likely:
As a cluster admin using on cluster layering,
when I try to upgrade my cluster,
I want the upgrade operation to succeed at the same rate as non-OCL upgrades do.
The original scope of this task is represented across this story & MCO-1494.
With OCL GA'ing soon, we'll need a blocking path within our e2e test suite that must pass before a PR can be merged. This story represents the first stage in creating the blocking path:
- Migrate the tests from e2e-gcp-op-techpreview into a new test suite called e2e-ocl. This can be done by moving the tests in the MCO repo from the test/e2e-techpreview folder to a new test/e2e-ocl folder. There might be some minor cleanups such as fixing duplicate function names, etc. but it should be fairly straightforward to do.
- Make a new e2e-gcp-op-ocl job to call the newly created e2e-ocl test suite. This test should first be added as optional for 4.19 so it can be stability tested before it is made blocking for 4.18 & 4.19. This will require a PR to the openshift/release repo to call the new test for 4.19 & master. This should be a pretty straightforward config change.
Description of problem:
Intermittently, when OCL is disabled and the nodes are updated with the new non-ocl image the process is not honoring the maxUnavailable value in the MCP.
Version-Release number of selected component (if applicable):
4.18
How reproducible:
Intermittent
Steps to Reproduce:
In the second must-gather file the issue happened when we did:
1. Enable OCL in the worker pool
2. Remove the MOSC resource to disable OCL
The result was that the worker pool had 2 nodes being drained at the same time.
Actual results:
The worker pool has 2 nodes being drained at the same time.
Expected results:
Since MCP has no maxUnavailable value defined, the default value is 1. Hence, there should be only 1 node being drained at a time.
Moreover, they should be updated in the right order.
Additional info:
[REGRESSION] We need to reinvent the wheel for triggering rebuild functionality and the rebuild mechanism as pool labeling and annotation is no longer a favorable way to interact with layered pools
There are a few situations in which a cluster admin might want to trigger a rebuild of their OS image in addition to situations where cluster state may dictate that we should perform a rebuild. For example, if the custom Dockerfile changes or the machine-config-osimageurl changes, it would be desirable to perform a rebuild in that case. To that end, this particular story covers adding the foundation for a rebuild mechanism in the form of an annotation that can be applied to the target MachineConfigPool. What is out of scope for this story is applying this annotation in response to a change in cluster state (e.g., custom Dockerfile change).
Done When:
- BuildController is aware of and recognizes a special annotation on layered MachineConfigPools (e.g., machineconfiguration.openshift.io/rebuildImage).
- Upon recognizing that a MachineConfigPool has this annotation, BuildController will clear any failed build attempts, delete any failed builds and their related ephemeral objects (e.g., rendered Dockerfile / MachineConfig ConfigMaps), and schedule a new build to be performed.
- This annotation should be removed when the build process completes, regardless of outcome. In other words, should the build success or fail, the annotation should be removed.
- [optional] BuildController keeps track of the number of retries for a given MachineConfigPool. This can occur via another annotation, e.g., machineconfiguration.openshift.io/buildRetries=1 . For now, this can be a hard-coded value (e.g., 5), but in the future, this could be wired up to an end-user facing knob. This annotation should be cleared upon a successful rebuild. If the rebuild is reached, then we should degrade.
Feature Overview (aka. Goal Summary)
Today VMs for a single nodepool can “clump” together on a single node after the infra cluster is updated. This is due to live migration shuffling around the VMs in ways that can result in VMs from the same nodepool being placed next to each other.
Through a combination of TopologySpreadConstraints and the De-Scheduler, it should be possible to continually redistributed VMs in a nodepool (via live migration) when clumping occurs. This will provide stronger HA guarantees for nodepools
Goals (aka. expected user outcomes)
VMs within a nodepool should re-distribute via live migration in order to best satisfy topology spread constraints.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
<enter general Feature acceptance here>
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Feature Overview (aka. Goal Summary)
Today VMs for a single nodepool can “clump” together on a single node after the infra cluster is updated. This is due to live migration shuffling around the VMs in ways that can result in VMs from the same nodepool being placed next to each other.
Through a combination of TopologySpreadConstraints and the De-Scheduler, it should be possible to continually redistributed VMs in a nodepool (via live migration) when clumping occurs. This will provide stronger HA guarantees for nodepools
Goals (aka. expected user outcomes)
VMs within a nodepool should re-distribute via live migration in order to best satisfy topology spread constraints.
In the hypershift upstream documentation, outline how the de-scheduler can be used to continually redistribute VMs in a nodepool when clumping of VMs occur after live migration.
Feature Overview
As a cluster admin for standalone OpenShift, I want to customize the prefix of the machine names created by CPMS due to company policies related to nomenclature. Implement the Control Plane Machine Set (CPMS) feature in OpenShift to support machine names where user can set custom names prefixes. Note the prefix will always be suffixed by "<5-chars>-<index>" as this is part of the CPMS internal design.
Acceptance Criteria
A new field called machineNamePrefix has been added to CPMS CR.
This field would allow the customer to specify a custom prefix for the machine names.
The machine names would then be generated using the format: <machineNamePrefix><5-chars><index>
Where:
<machineNamePrefix> is the custom prefix provided by the customer
<5-chars> is a random 5 character string (this is required and cannot be changed)
<index> represents the index of the machine (0, 1, 2, etc.)
Ensure that if the machineNamePrefix is changed, the operator reconciles and succeeds in rolling out the changes.
Epic Goal
- Provide a new field to the CPMS that allows to define a Machine name prefix
- This prefix will supersede the current usage of the control plane label and role combination we use today
- The names must still continue to be suffixed with <chars>-<idx> as this is important to the operation of CPMS
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- DEV - Downstream code and tests merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Bump openshift/api to vendor machineNamePrefix field and CPMSMachineNamePrefix feature-gate into cpms-operator
- Utilize the new field added in openshift/api and add the implementation so that custom name (prefix) formats can be assigned to Control Plane Machines via CPMS.
- All the changes should be behind the feature gate.
- This prefix will supersede the current usage of the control plane label and role combination we use today
- The names must still continue to be suffixed with <chars><idx> as this is important to the operation of CPMS
- Add unit tests and E2E tests.
Define a new feature gate in openshift/api for this feature so that all the implementation can be safe guarded behind this gate.
To be able to gather test data for this feature, we will need to introduce tech preview periodics, so we need to duplicate each of https://github.com/openshift/release/blob/8f8c7c981c3d81c943363a9435b6c48005eec6e3[…]control-plane-machine-set-operator-release-4.19__periodics.yaml and add the techpreview configuration.
It's configured as an env var, so copy each job, add the env var, and change the name to include -techpreview as a suffic
env: FEATURE_SET: TechPreviewNoUpgrade
Description of problem:
Consecutive points are not allowed in machineNamePrefix, but from the prompt "spec.machineNamePrefix: Invalid value: "string": a lowercase RFC 1123 subdomain must consist of lower case alphanumeric characters, '-' or '.', and must start and end with an alphanumeric character.", consecutive points should be allowed. And I can create machine on providers console with consecutive points https://drive.google.com/file/d/1p5QLhkL4VI3tt3viO98zYG8uqb1ePTnB/view?usp=sharing
Version-Release number of selected component (if applicable):
4.19.0-0.nightly-2025-01-08-165032
How reproducible:
Always
Steps to Reproduce:
1.Update machineNamePrefix containing consecutive points in controlplanemachineset, like
machineNamePrefix: huliu..azure
2.Cannot save, get prompt
# * spec.machineNamePrefix: Invalid value: "string": a lowercase RFC 1123 subdomain must consist of lower case alphanumeric characters, '-' or '.', and must start and end with an alphanumeric character.
3. If change to
machineNamePrefix: huliu.azure
then it can save successfully, and rollout succeed.
Actual results:
Cannot save, get prompt
Expected results:
Can save successfully
Additional info:
New feature testing for https://issues.redhat.com/browse/OAPE-22
Provide a new field to the CPMS that allows to define a Machine name prefix
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Placeholder to track GA activities for OAPE-16 feature.
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- Moving the feature to default feature set.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Include `CPMSMachineNamePrefix` feature gate name in e2e tests.
This is required for sippy tool to filter the e2e tests specific to this featuregate.
xRef: https://github.com/openshift/api?tab=readme-ov-file#defining-featuregate-e2e-tests
Feature Overview (aka. Goal Summary)
Enable OpenShift to be deployed on Confidential VMs on GCP using Intel TDX technology
Goals (aka. expected user outcomes)
Users deploying OpenShift on GCP can choose to deploy Confidential VMs using Intel TDX technology to rely on confidential computing to secure the data in use
Requirements (aka. Acceptance Criteria):
As a user, I can choose OpenShift Nodes to be deployed with the Confidential VM capability on GCP using Intel TDX technology at install time
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Background
This is a piece of a higher-level effort to secure data in use with OpenShift on every platform
Documentation Considerations
Documentation on how to use this new option must be added as usual
Epic Goal
- Add support to deploy Confidential VMs on GCP using Intel TDX technology
Why is this important?
- As part of the Zero Trust initiative we want to enable OpenShift to support data in use protection using confidential computing technologies
Scenarios
- As a user I want all my OpenShift Nodes to be deployed as Confidential VMs on Google Cloud using Intel TDX technology
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Previous Work (Optional):
- We enabled Confidential VMs for GCP using SEV technology already -
OCPSTRAT-690
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
Edge customers requiring computing on-site to serve business applications (e.g., point of sale, security & control applications, AI inference) are asking for a 2-node HA solution for their environments. Only two nodes at the edge, because the 3d node induces too much cost, but still they need HA for critical workload. To address this need, a 2+1 topology is introduced. It supports a small cheap arbiter node that can optionally be remote/virtual to reduce onsite HW cost.
Goals (aka. expected user outcomes)
Support OpenShift on 2+1 topology, meaning two primary nodes with large capacity to run workload and control plan, and a third small “arbiter” node which ensure quorum. See requirements for more details.
Requirements (aka. Acceptance Criteria):
- Co-located arbiter node - 3d node in same network/location with low latency network access, but the arbiter node is much smaller compared to the two main nodes. Initial resource requirements for the arbiter node documented as with Compact CLusters: 4 cores / 8 vcpu, 16G RAM, 120G disk (non-spinning), 1x1 GbE network ports, no BMC. To be refined and hopefully reduced for GA.
- OCP Virt fully functionally, incl. Live migration of VMs (assuming RWX CSI Driver is available) - Could slip into GA release
- Single Control Plane Node outage is handled seamlessly the same way as a compact cluster (cluster remains quorum, workload can be scheduled). If one of the worker nodes is down, scheduling failures might occur if the cluster is over provisioned.
- In case the arbiter node is down , a reboot/restart of the two remaining nodes has to work, i.e. the two remaining nodes re-gain quorum (in degraded states because arbiter is still down) and spin-up the workload. Or differently formulated: total power outage, all nodes down. Then node 1 and node 2 are restarted, but not the arbiter. The expectation is that the nodes gain quorum and start the workload in this scenario.
Scale out of the cluster by adding additional worker nodes should be possible(Deferred to GA)Transition the cluster into a regular 3 node compact cluster, e.g. by adding a new node as control plane node, then removing the arbiter node, should be possible.Deferred to GA or even Post-GA, has OpenShift currently does not support any control plane topology changes.- Regular workload should not be scheduled to the arbiter node (e.g by making it un-schedulabe, or introduce a new node role “arbiter”). Only essential control plane workload (etcd components) should run on the arbiter node. Non-essential control plan workload (i.e. router, registry, console, monitoring etc) should also not be scheduled to the arbiter nodded.
- It must be possible to explicitly schedule additional workload to the arbiter node. That is important for 3d party solutions (e.g. storage provider) which also have quorum based mechanisms.
- must seamlessly integrate into existing installation/update mechanisms, esp. zero touch provisioning etc.
- OpenShift Installer UPI
- OpenShift Installer IPI
- Assistent Installer
Agent Based Installer--> Deferred to GAACM Cluster Lifecycle Manager--> Deferred to GA
- Added: ability to track TNA usage in the fleet of connected clusters via OCP telemetry data (e.g. number of clusters with TNA topology) - This is a stretch goal for TP.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | self-managed |
| Classic (standalone cluster) | yes |
| Hosted control planes | no |
| Multi node, Compact (three node), or Single node (SNO), or all | Multi node and Compact (three node) |
| Connected / Restricted Network | both |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86_86 and ARM |
| Operator compatibility | full |
| Backport needed (list applicable versions) | no |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | no |
| Other (please specify) | n/a |
Questions to Answer (Optional):
- How to implement the scheduling restrictions to the arbiter node? New node role “arbiter”?
Can this be delivered in one release, or do we need to split, e.g. TechPreview + GA? -->Yes, multiple releases needed, see linked feature for GA tracking
Out of Scope
- Storage driver providing RWX shared storage
- …
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
- Two node support is in high demand by telco, industrial and retail customers.
- VMWare supports a two node VSan solution: https://core.vmware.com/resource/vsan-2-node-cluster-guide
- Example edge hardware frequently used for edge deployments with a co-located small arbiter node: Dell PowerEdge XR4000z Server is an edge computing device that allows restaurants, retailers, and other small to medium businesses to set up local computing for data-intensive workloads.
Customer Considerations
See requirements - there are two main groups of customers: co-located arbiter node, and remote arbiter node.
Documentation Considerations
- Topology needs to be documented, esp. The requirements of the arbiter node.
Interoperability Considerations
- OCP Virt needs to be explicitly tested on this scenario to support VM HA (live migration, restart on other node)
Authentication Operator will need to be updated to take in the newly created `HighlyAvailableArbiter` topology flag, and allow the minimum of kube-apiservers running to equal 2.
We need to add the `HighlyAvailableArbiter` value to the controlPlaneTopology in ocp/api package as a TechPreview
https://github.com/openshift/api/blob/master/config/v1/types_infrastructure.go#L95-L103
We need to update the installer to support the machines for the arbiter node during install.
This will be flushed out with explicit direction, currently discussing next steps in EP comments.
Bump the openshift/api dependency to latest for the arbiter node enum.
We will need to make sure the MCO contains the bootstrap files for the arbiter node similar to the files it contains for master nodes.
The console operator performs a check for HighlyAvailable, we will need to add the HighlyAvailableArbiter check there so that it supports it on the same level as HA
The console operand checks for valid infra control plane topology fields.
We'll need to add the HighlyAvailableArbiter flag to that check
Once the HighlyAvailableArbiter has been added to the ocp/api, we need to update the cluster-config-operator dependencies to reference the new change, so that it propagates to cluster installs in our payloads.
If arbiter is set in the install config, then we want to set it's default values.
We need to update CEO (cluster etcd operator) to understand what an arbiter/witness node is so it can properly assign an etcd member on our less powerful node.
Update the dependencies for CEO for library-go and ocp/api to support the Arbiter additions, doing this in a separate PR to keep things clean and easier to test.
We need to make sure kubelet respects the new node role type for arbiter. This will be a simple update on the well_known_openshift_labels.go list to include the new node role.
Make sure pacemaker configured in TNF controls etcd.
Verify the following scenarios:
- Etcd agent created: start/stop/promote/demote
- Cold boot
- Graceful shutdown
For TNF we need to replace our currently running etcd after the installation with the one that is managed by pacemaker.
This allows us to keep the following benefits:
- installation can stay the way it is
- upgrade paths are not blocked
- we can keep existing operator functionality around (cert rotation, defrags etc)
- pacemaker can control etcd without any other interference
AC:
- on a (later specified) signal, we roll out a static pod revision without the etcd container
As a developer of TNF, I need:
- Pacemaker and Corosync to be available during cluster deployment
Acceptance Criteria
- Pacemaker and corosync are made available in CoreOS via MCO extension
As a developer of 2NO, I need:
- To be able to configure the installer to update CoreOS to have pacemaker and corosync installed by default
Acceptance Criteria
- Implementation PR is merged
This epic is used to track tasks/stories delivered from OCP core engineering control plane gorup.
As a developer of TNF, I need:
- To include a new scaling strategy for TNF that allows bootstrap to allows 1 etcd at bootstrap but 2 when running (assisted/ABI flow)
- To include a new scaling strategy for TNF that requires 2 etcd nodes at bootstrap and when running (core installer flow)
- For CEO to propagate updates to pacemaker controlled etcd pod (e.g. version changes, cert updates)
- For cert rotations to be disallowed during pacemaker etcd updates
Acceptance Criteria
- Pacemaker is intialized by CEO when it starts and detects that it's running in 2-node topology
- etcd is running under pacemaker post transition and this transition keeps CEO in a supported state
- CEO now has scaling strategies to handle TNF installs in a supported way for both 3-node (core installer) and 2-node (assisted installer, ABI) based deployments
- CEO can now notify pacemaker of etcd updates & restarting the etcd pod
- Tests are added to cover new CEO functionality
- Cert rotation tests are run on TNF topology to ensure this can never overlap with etcd-pod update events
As a developer of TNF, I need:
- To update etcd to use a pair of new scaling strategies for TNF: one to handle core-installer, and the other for assisted installer and ABI
Acceptance Criteria
- PR is merged to openshift/cluster-etcd-operator
- Unit tests are added for new scaling strategies
As a developer of TNF, I need:
- To have a feature gate ensuring clusters are not upgradable while in dev or tech preview
- To have a new control plane topology for TNF set in the installer
- To fix any operator logic that is sensitive to topology declarations
Acceptance Criteria
- Feature gate is added for TNF
- New control plane topology is added to the infrastructure spec
- Topology-sensitive operators are updated with TNF specific logic
- Installer is updated to set the new topology in the infra config
We need to bump the go.mod for the cluster-config-operator to make sure the DualReplica CRD is applied at bootstrap after we merge in the topology change to the ocp/api repo.
As a developer of 2NO, I need:
- To have a way for the cluster to know it cannot upgrade when deployed in 2NO topology
- To have an indication that dev and tech preview releases of 2NO are not supported
Acceptance Criteria
- PR is merged in relevant openshift repo
- Unit test is added (as required)
Feature Overview (aka. Goal Summary)
As an OpenShift Container Platform (OCP) user, I will be able to install the GA version of OpenShift Lightspeed (OLS) from the Operator Hub and access information about OLS in the OCP documentation.
1) disconnected
2) FIPS
3) Multi arch -> Arm for GA
4) HCP
5) Konflux
Description:
As a OLS developer, I want to verify if OLS can be configured on custom namespace on 2 different HCP clusters provisioned from same Management Cluster, so that SD team can run on their HCP clusters.
Acceptance Criteria :
- verify that OLS can run on custom namespace on 2 different HCP clusters provisioned from same Management Cluster
Feature Overview
Support mapping OpenShift zones to vSphere host groups, in addition to vSphere clusters.
When defining zones for vSphere administrators can map regions to vSphere datacenters and zones to vSphere clusters.
There are use cases where vSphere clusters have only one cluster construct with all their ESXi hosts but the administrators want to divide the ESXi hosts in host groups. A common example is vSphere stretched clusters, where there is only one logical vSphere cluster but the ESXi nodes are distributed across to physical sites, and grouped by site in vSphere host groups.
In order for OpenShift to be able to distribute its nodes on vSphere matching the physical grouping of hosts, OpenShift zones have to be able to map to vSphere host groups too.
Requirements{}
- Users can define OpenShift zones mapping them to host groups at installation time (day 1)
- Users can use host groups as OpenShift zones post-installation (day 2)
Epic Goal
Support mapping OpenShift zones to vSphere host groups, in addition to vSphere clusters.
When defining zones for vSphere administrators can map regions to vSphere datacenters and zones to vSphere clusters.
There are use cases where vSphere clusters have only one cluster construct with all their ESXi hosts but the administrators want to divide the ESXi hosts in host groups. A common example is vSphere stretched clusters, where there is only one logical vSphere cluster but the ESXi nodes are distributed across to physical sites, and grouped by site in vSphere host groups.
In order for OpenShift to be able to distribute its nodes on vSphere matching the physical grouping of hosts, OpenShift zones have to be able to map to vSphere host groups too.
Requirements{}
- Users can define OpenShift zones mapping them to host groups at installation time (day 1)
- Users can use host groups as OpenShift zones post-installation (day 2)
{}USER STORY:{}
As someone that installs openshift on vsphere, I want to install zonal via host and vm groups so that I can use a stretched physical cluster or use a cluster as a region and hosts as zones .
{}DESCRIPTION:{}
{}Required:{}
{}Nice to have:{}
{}ACCEPTANCE CRITERIA:{}
- start validating tag naming
- validate tags exist
- validate host group exists
- update platform spec
- unit tests
- create capv deployment and failure domain manifests
- per failure domain, create vm group and vm host rule
{}ENGINEERING DETAILS:{}
Configuration steps:
- Create tag and tag categories
- Attach zonal tags to ESXi hosts - capv will complain extensively if this is not done
- Host groups {}MUST{} be created and populated prior to installation (maybe, could we get the hosts that are attached or vice versa hosts in host group are attached?)
one per zone
- vm groups wil be created by the installer one per zone
- vm / host rule will be created by the installer one per zone
https://github.com/openshift/installer/compare/master...jcpowermac:installer:test-vm-host-group
As an openshift engineer enable host vm group zonal in mao so that compute nodes properly are deployed
Acceptance Criteria:
- Modify workspace to include vmgroup
- properly configure vsphere cluster to add vm into vmgroup
As an openshift engineer enable host vm group zonal in CPMS so that control plane nodes properly are redeployed
Acceptance Criteria:
- Control plane nodes properly roll out when requried
- Control plane nodes do not roll out when not needed
As an openshift engineer update the infrastructure and the machine api objects so it can support host vm group zonal
Acceptance criteria
- Add the appropriate fields for host vm group zonal
- Add the appropriate documentation for the above fields
- Add a new feature gate for host vm zonal
Feature Overview (aka. Goal Summary)
Overarching Goal
Move to using the upstream Cluster API (CAPI) in place of the current implementation of the Machine API for standalone Openshift.
Phase 1 & 2 covers implementing base functionality for CAPI.
Phase 2 also covers migrating MAPI resources to CAPI.
Phase 2 Goal:
- Complete the design of the Cluster API (CAPI) architecture and build the core operator logic
- attach and detach of load balancers for internal and external load balancers for control plane machines on AWS, Azure, GCP and other relevant platforms
- manage the lifecycle of Cluster API components within OpenShift standalone clusters
- E2E tests
for Phase-1, incorporating the assets from different repositories to simplify asset management.
Background, and strategic fit
- Initially CAPI did not meet the requirements for cluster/machine management that OCP had the project has moved on, and CAPI is a better fit now and also has better community involvement.
- CAPI has much better community interaction than MAPI.
- Other projects are considering using CAPI and it would be cleaner to have one solution
- Long term it will allow us to add new features more easily in one place vs. doing this in multiple places.
Acceptance Criteria
There must be no negative effect to customers/users of the MAPI, this API must continue to be accessible to them though how it is implemented "under the covers" and if that implementation leverages CAPI is open
Epic Goal
- To prepare the openshift cluster-api project for general availability
- Ensure proper testing of the CAPI installer operator
Why is this important?
- We need to be able to install and lifecycle the Cluster API ecosystem within standalone OpenShift
- We need to make sure that we can update the components via an operator
- We need to make sure that we can lifecycle the APIs via an operator
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Update: We did this for the corecluster controller, we will create separate cards to do it for the other cluster-capi-operator controllers too.
–
The current ClusterOperator status conditions—Available, Progressing, Upgradeable, and Degraded—are set by the corecluster controller independently of the status of other controllers.
This approach does not align with the intended purpose of these conditions, which are meant to reflect the overall status of the operator, considering all the controllers it manages.
To address this, we should introduce controller-level conditions similar to the top-level ones. These conditions would influence an aggregated top-level status, which a new controller (the ClusterOperator controller) would then consolidate into the Available, Progressing, Upgradeable, and Degraded conditions.
Moreover, when running `oc get co` against the cluster-capi-operator, only the name and version are returned. The status is not rolled up into the additional columns as expected.
Before GA, this state information should be visible from `oc get co`
Feature Overview (aka. Goal Summary)
OpenShift is traditionally a single-disk system, meaning the OpenShift installer is designed to install the OpenShift filesystem on one disk. However, new customer use cases have highlighted the need for the ability to configure additional disks during installation. Here are the specific use cases:
- Dedicated Disk for etcd:
-
- As a user, I would like to install a cluster with a dedicated disk for etcd.
- Our recommended practices for etcd suggest using a dedicated disk for optimal performance.
- Managing disk mounting through MCO can be challenging and may introduce additional issues.
- Cluster-API supports running etcd on a dedicated disk.
- Dedicated Disk for Swap Partitions:
-
- As a user, I would like to install a cluster with swap enabled on each node and utilize a dedicated disk for swap partitions.
- A dedicated disk for swap would help prevent swap activity from impacting node performance.
- Dedicated Disk for Container Runtime:
-
- As a user, I would like to install a cluster and assign a separate disk for the container runtime.
- Dedicated Disk for Image Storage:
-
- As a user, I would like to install a cluster with images stored on a dedicated disk, while keeping ephemeral storage on the node's main filesystem.
User Story:
As an OpenShift administrator, I need to be able to configure my OpenShift cluster to have additional disks on each vSphere VM so that I can use the new data disks for various OS needs.
Description:
This goal of this epic is to be able to allow the cluster administrator to install and configure after install new machines with additional disks attached to each virtual machine for various OS needs.
Required:
- Installer allows configuring additional disks for control plane and compute virtual machines
- Control Plane Machine Sets (CPMS) allows configuring control plane virtual machines with additional disks
- Machine API (MAPI) allows for configuring Machines and MachineSets with additional disks
- Cluster API (CAPI) allows for configuring Machines and MachineSets with additional disks
Nice to Have:
Acceptance Criteria:
Notes:
User Story:
As an OpenShift Engineer I need to create a new feature gate and CRD changes for vSphere multi disk so that we can gate the new function until all bugs are ironed out.
Description:
This task is to create the new feature gate to be used by all logical changes around multi disk support for vSphere. We also need to update the types for vsphere machine spec to include new array field that contains data disk definitions.
Acceptance Criteria:
- New feature gate exists for components to use.
- Initial changes to the CRD for data disks are present for components to start using.
User Story:
As an OpenShift Engineer I need to ensure the the MAPI Operator.
Description:
This task is to verify if any changes are needed in the MAPI Operator to handle the change data disk definitions in the CPMS.
Acceptance Criteria:
- Adding a disk to MachineSet does not result in new machines being rolled out.
- Removing a disk from MachineSet does not result in new machines being rolled out.
- After making changes to a MachineSet related to data disks, when MachineSet is scaled down and then up, new machines contain the new data disk configurations.
- All attempts to modify existing data disk definitions in an existing Machine definition are blocked by the webhook.
Notes:
The behaviors for the data disk field should be the same as all other provider spec level fields. We want to make sure that the new fields are no different than the others. This field is not hot swap capable for running machines. A new VM must be created for this feature to work.
User Story:
As an OpenShift Engineer I need to enhance the OpenShift installer to support creating a cluster with additional disks added to control plane and compute nodes so that I can use the new data disks for various OS needs.
Description:
This task is to enhance the installer to allow configuring data disks in the install-config.yaml. This will also require setting the necessary fields in machineset and machine definitions. The important one being for CAPV to do the initial creation of disks for the configured masters.
Acceptance Criteria:
- install-config.yaml supports configuring data disks in all machinepools.
- CAPV has been updated with new multi disk support.
- CAPV machines are created that result in control plane nodes with data disks.
- MachineSet definitions for compute nodes are created correctly with data disk values from compute pool.
- CPMS definition for masters has the data disks configured correctly.
Notes:
We need to be sure that after installing a cluster, the cluster remains stable and has all correct configurations.
User Story:
As an OpenShift Engineer I need to ensure the the CPMS Operator now works with detecting any changes needed when data disks are added to the CPMS definition.
Description:
This task is to verify if any changes are needed in the CPMS Operator to handle the change data disk definitions in the CPMS.
Acceptance Criteria:
- CPMS does not roll out changes when initial install is performed.
- Adding a disk to CPMS results in control plane roll out.
- Removing a disk from CPMS results in control plane roll out.
- No errors logged as a result of data disks being present in the CPMS definition.
Notes:
Ideally we just need to make sure the operator is updated to pull in the new CRD object definitions that contain the new data disk field.
Feature Overview (aka. Goal Summary)
GA User Name Space in OpenShift 4.19
continue work from https://issues.redhat.com/browse/OCPSTRAT-207
Epic Goal
- Prepare user namespaces for GA by enhancing SCC support and testing
Why is this important?
- Enable nested containers use cases and enhance security
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
https://github.com/openshift/kubernetes/pull/2104 and https://github.com/openshift/cluster-kube-apiserver-operator/pull/1754 have some updated comments
Background
As part of being a first party Azure offering, ARO HCP needs to adhere to Microsoft secure supply chain software requirements. In order to do this, we require setting a label on all pods that run in the hosted cluster namespace.
Goal
Implement Mechanism for Labeling Hosted Cluster Control Plane Pods
Use-cases
- Adherance to Microsoft 1p Resource Provider Requirements
Components
- Any pods that hypershift deploys or run in the hosted cluster namespace.
Goal
- Hypershift has a mechanism for Labeling Control Plane Pods
- Cluster service should be able to set the label for a given hosted cluster
Why is this important?
- As part of being a first party Azure offering, ARO HCP needs to adhere to Microsoft secure supply chain software requirements. In order to do this, we require setting a label on all pods that run in the hosted cluster namespace.
See Documentation: https://eng.ms/docs/more/containers-secure-supply-chain/other
Scenarios
- Given a subscriptionID of "1d3378d3-5a3f-4712-85a1-2485495dfc4b", there needs to be the following label on all pods hosted on behalf of the customer:
kubernetes.azure.com/managedby: sub_1d3378d3-5a3f-4712-85a1-2485495dfc4b
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
Review, refine and harden the CAPI-based Installer implementation introduced in 4.16
Goals (aka. expected user outcomes)
From the implementation of the CAPI-based Installer started with OpenShift 4.16 there is some technical debt that needs to be reviewed and addressed to refine and harden this new installation architecture.
Requirements (aka. Acceptance Criteria):
Review existing implementation, refine as required and harden as possible to remove all the existing technical debt
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Documentation Considerations
There should not be any user-facing documentation required for this work
Epic Goal
- This epic includes tasks the team would like to tackle to improve our process, QOL, CI. It may include tasks like updating the RHEL base image and vendored assisted-service.
Why is this important?
We need a place to add tasks that are not feature oriented.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Most of the platform subdirectories don't have OWNERS files
we should add the aliases for everything that's missing
backport to 4.16
Feature Overview (aka. Goal Summary)
This feature aims to comprehensively refactor and standardize various components across HCP, ensuring consistency, maintainability, and reliability. The overarching goal to increase customer satisfaction by increasing speed to market and saving engineering budget by reducing incidents/bugs. This will be achieved by reducing technical debt, improving code quality, and simplifying the developer experience across multiple areas, including CLI consistency, NodePool upgrade mechanisms, networking flows, and more. By addressing these areas holistically, the project aims to create a more sustainable and scalable codebase that is easier to maintain and extend.
Goals (aka. Expected User Outcomes)
- Unified Codebase: Achieve a consistent and unified codebase across different HCP components, reducing redundancy and making the code easier to understand and maintain.
- Enhanced Developer Experience: Streamline the developer workflow by reducing boilerplate code, standardizing interfaces, and improving documentation, leading to faster and safer development cycles.
- Improved Maintainability: Refactor large, complex components into smaller, modular, and more manageable pieces, making the codebase more maintainable and easier to evolve over time.
- Increased Reliability: Enhance the reliability of the platform by increasing test coverage, enforcing immutability where necessary, and ensuring that all components adhere to best practices for code quality.
- Simplified Networking and Upgrade Mechanisms: Standardize and simplify the handling of networking flows and NodePool upgrade triggers, providing a clear, consistent, and maintainable approach to these critical operations.
Requirements (aka. Acceptance Criteria)
- Standardized CLI Implementation: Ensure that the CLI is consistent across all supported platforms, with increased unit test coverage and refactored dependencies.
- Unified NodePool Upgrade Logic: Implement a common abstraction for NodePool upgrade triggers, consolidating scattered inputs and ensuring a clear, consistent upgrade process.
- Refactored Controllers: Break down large, monolithic controllers into modular, reusable components, improving maintainability and readability.
- Improved Networking Documentation and Flows: Update networking documentation to reflect the current state, and refactor network proxies for simplicity and reusability.
- Centralized Logic for Token and Userdata Generation: Abstract the logic for token and userdata generation into a single, reusable library, improving code clarity and reducing duplication.
- Enforced Immutability for Critical API Fields: Ensure that immutable fields within key APIs are enforced through proper validation mechanisms, maintaining API coherence and predictability.
- Documented and Clarified Service Publish Strategies: Provide clear documentation on supported service publish strategies, and lock down the API to prevent unsupported configurations.
Use Cases (Optional)
- Developer Onboarding: New developers can quickly understand and contribute to the HCP project due to the reduced complexity and improved documentation.
- Consistent Operations: Operators and administrators experience a more predictable and consistent platform, with reduced bugs and operational overhead due to the standardized and refactored components.
Out of Scope
- Introduction of new features or functionalities unrelated to the refactor and standardization efforts.
- Major changes to user-facing commands or APIs beyond what is necessary for standardization.
Background
Over time, the HyperShift project has grown organically, leading to areas of redundancy, inconsistency, and technical debt. This comprehensive refactor and standardization effort is a response to these challenges, aiming to improve the project's overall health and sustainability. By addressing multiple components in a coordinated way, the goal is to set a solid foundation for future growth and development.
Customer Considerations
- Minimal Disruption: Ensure that existing users experience minimal disruption during the refactor, with clear communication about any changes that might impact their workflows.
- Enhanced Stability: Customers should benefit from a more stable and reliable platform as a result of the increased test coverage and standardization efforts.
Documentation Considerations
Ensure all relevant project documentation is updated to reflect the refactored components, new abstractions, and standardized workflows.
This overarching feature is designed to unify and streamline the HCP project, delivering a more consistent, maintainable, and reliable platform for developers, operators, and users.
Goal
Refactor and modularize controllers and other components to improve maintainability, scalability, and ease of use.
User Story:
As a (user persona), I want to be able to:
- As an external dev I want to be able to add new components to the CPO easily
- As a core dev I want to feel safe when adding new components to the CPO
- As a core dev I want to add new components to the CPO with our copy/pasting big chunks of code
https://issues.redhat.com//browse/HOSTEDCP-1801 introduced a new abstraction to be used by ControlPlane components. However, when a component or a sub-resources predicate changes to false, the resources are not removed from the cluster. All resources should be deleted from the cluster.
docs: https://github.com/openshift/hypershift/blob/main/support/controlplane-component/README.md
User Story:
As a (user persona), I want to be able to:
- As an external dev I want to be able to add new components to the CPO easily
- As a core dev I want to feel safe when adding new components to the CPO
- As a core dev I want to add new components to the CPO with our copy/pasting big chunks of code
https://issues.redhat.com//browse/HOSTEDCP-1801 introduced a new abstraction to be used by ControlPlane components. We need to refactor every component to use this abstraction.
Acceptance Criteria:
Description of criteria:
All ControlPlane Components are refactored:
HCCOkube-apiserver (Mulham)kube-controller-manager (Mulham)ocm (Mulham)etcd (Mulham)oapi (Mulham)scheduler (Mulham)clusterpolicy (Mulham)CVO (Mulham)oauth (Mulham)hcp-router (Mulham)storage (Mulham)CCO (Mulham)- CNO (Jparrill)
- CSI (Jparrill)
- dnsoperator
- ignition (Ahmed)
- ingressoperator
- machineapprover
- nto
- olm
- pkioperator
- registryoperator
- snapshotcontroller
Example PR to refactor cloud-credential-operator : https://github.com/openshift/hypershift/pull/5203
docs: https://github.com/openshift/hypershift/blob/main/support/controlplane-component/README.md
Provide a PR with a CSI standard refactor
Example PR to refactor HCCO: https://github.com/openshift/hypershift/pull/4860
docs: https://github.com/openshift/hypershift/blob/main/support/controlplane-component/README.md
Provide a PR with a CNO standard refactor
Example PR to refactor HCCO: https://github.com/openshift/hypershift/pull/4860
docs: https://github.com/openshift/hypershift/blob/main/support/controlplane-component/README.md
Goal
Improve the consistency and reliability of APIs by enforcing immutability and clarifying service publish strategy support.
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
Allow customers to migrate CNS volumes (i.e vsphere CSI volumes) from one datastore to another.
This operator relies on a new VMware CNS API and requires 8.0.2 or 7.0 Update 3o minimum versions
https://docs.vmware.com/en/VMware-vSphere/8.0/rn/vsphere-vcenter-server-802-release-notes/index.html
In 4.17 we shipped a devpreview CLI tool (OCPSTRAT-1619) to cover existing urgent requests. This CLI tool will be removed as soon as this feature is available in OCP.
Goals (aka. expected user outcomes)
Often our customers are looking to migrate volumes between datastores because they are running out of space in current datastore or want to move to more performant datastore. Previously this was almost impossible or required modifying PV specs by hand to accomplish this. It was also very error prone.
As a first version, we developed a CLI tool that is shipped as part of the vsphere CSI operator. We keep this tooling internal for now, support can guide customers on a per request basis. This is to manage current urgent customer's requests, a CLI tool is easier and faster to develop it can also easily be used in previous OCP releases.
After multiple discussion with VMware we now have confidence that we can rely on their built-in vSphere UI tool to migrate CNS volume from one datastore to another. This includes attached and detached volumes. Vmware confirmed they have confidence in this scenario and they fully support this operation for attached volumes.
Requirements (aka. Acceptance Criteria):
SInce the feature is external to OCP, it is mostly a matter of testing it works as expected with OCP but customers will be redirected to Vmware documentation as all the steps are done through the vSphere UI.
Perform testing for attached and detached volumes + special cases such as RWX, zonal, encrypted.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | both |
| Classic (standalone cluster) | Yes |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | Yes |
| Connected / Restricted Network | both |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86 |
| Operator compatibility | vsphere CSI operator but feature is external to OCP |
| Backport needed (list applicable versions) | no |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | no done through vsphere UI |
| Other (please specify) | OCP on vsphere only |
Use Cases (Optional):
As a admin - want to migrate all my PVs or optional PVCs belonging to certain namespace to a different datastore within cluster without potentially requiring extended downtime.
- I want to move volumes to another datastore that has better performances
- I want to move volumes to another datastore current the current one is getting full
- I want to move all volumes to another datastore because the current one is being decommissioned.
Questions to Answer (Optional):
Get full support confirmation from vmware that their CNS volume migration feature
- Can be supported for OCP - YES
- is supported with attached volumes - YES
- Should detect if a volume is not migreable - YES
Out of Scope
Limited to what VMware supports. At the moment only one volume can be migrated at a time.
Background
We had a lot of requests to migrate volumes between datastore for multiple reason. Up until now it was not natively supported by VMware. In 8.0.2 they added a CNS API and a vsphere UI feature to perform volume migration.
In 4.17 we shipped a devpreview CLI tool (OCPSTRAT-1619) to cover existing urgent requests. This CLI tool will be removed as soon as this feature is available in OCP.
This feature also includes the work needed to remove the CLI tool
Customer Considerations
Need to be explicit on requirements and limitations.
Documentation Considerations
Documented as part of the vsphere CSI OCP documentation.
Specify min vsphere version. Document any limitation found during testing
Redirect to vmware documentation.
Announce removal of the CLI tool + update KB.
Interoperability Considerations
OCP on vSphere only
Epic Goal*
We need to document and support CNS volume migration using native vCenter UI, so as customers can migrate volumes between datastores.
Why is this important? (mandatory)
Often our customers are looking to migrate volumes between datastores because they are running out of space in current datastore or want to move to more performant datastore. Previously this was almost impossible or required modifying PV specs by hand to accomplish this. It was also very error prone.
Scenarios (mandatory)
As an vCenter/Openshift admin, I want to migrate CNS volumes between datastores for existing vSphere CSI persistent volumes (PVs).
This should cover attached and detached volumes. Special cases such as RWX, zonal or encrypted should also be tested to confirm is there is any limitation we should document.
Dependencies (internal and external) (mandatory)
This feature depends on VMware vCenter Server 7.0 Update 3o or vCenter Server 8.0 Update 2.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - STOR
- Documentation - STOR
- QE - STOR
- PX -
- Others -
Acceptance Criteria (optional)
This is mostly a testing / documentation epic, which will change current wording about unsupported CNS volume migration using vCenter UI.
As part of this epic, we also want to remove the CLI tool we developed for https://github.com/openshift/vmware-vsphere-csi-driver-operator/blob/master/docs/cns-migration.md from the payload.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be "Release Pending"
We have decided to remove cns-migration CLI tool for now.
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Upgrade the OCP console to Pattern Fly 6.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
The core OCP Console should be upgraded to PF 6 and the Dynamic Plugin Framework should add support for PF6 and deprecate PF4.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Console, Dynamic Plugin Framework, Dynamic Plugin Template, and Examples all should be upgraded to PF6 and all PF4 code should be removed.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
As a company we have all agreed to getting our products to look and feel the same. The current level is PF6.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Problem:
Console is adopting PF6 and removing the PF4 support. It creates lots of UI issues in the Developer Console which we need to support to fix.
Goal:
Fix all the UI issues in the ODC related to PF6 upgrade
Why is it important?
Acceptance criteria:
- Fix all the ODC issues https://docs.google.com/spreadsheets/d/1J7udCkoCks7Pc_jIRdDDBDtbY4U5OOZu_kG4aqX1GlU/edit?gid=0#gid=0
Dependencies (External/Internal):
Design Artifacts:
Exploration:
Note:
Description of problem:
Label/tag on software catalog card is left align but it should be align right.
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1. Navigate to software catalog
2.
3.
Actual results:
Label/tag on software catalog card is left align
Expected results:
Label/tag on software catalog card should be right align
Additional info:
Epic Goal
- ...
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Per slack discussion, the following files contain invalid tokens that need to be fixed/updated/removed:
knative-plugin/src/components/functions/GettingStartedSection.scss
pipelines-plugin/src/components/pipelineruns/PipelineRunDetailsPage.scss
pipelines-plugin/src/components/pipelineruns/list-page/PipelineRunList.scss
pipelines-plugin/src/components/pipelines/detail-page-tabs/pipeline-details/PipelineVisualizationStepList.scss
pipelines-plugin/src/components/taskruns/TaskRunDetailsPage.scss
pipelines-plugin/src/components/taskruns/list-page/TaskRunsRow.scss
topology/src/components/graph-view/components/GraphComponent.scss
topology/src/components/graph-view/components/edges/ServiceBinding.scss
topology/src/components/graph-view/components/groups/GroupNode.scss
topology/src/components/page/TopologyView.scss
The background color of the tab should be solid and not transparent 
The layout and functionality of the Edit upstream configuration modal could be improved.
- Add space between the two radio options
- Use PatternFly components instead of custom ones
- Focus text input when "Custom" is selected
https://github.com/patternfly/patternfly/issues/7256 is a bug in PatternFly that impacts console. Once it is fixed upstream, we need to update PatternFly to a version that includes the fix.
Some of the PatternFly releases in https://github.com/openshift/console/pull/14621 are prereleases. Once final releases are available (v.6.2.0 is scheduled for the end of March), we should update to them.
Also update https://github.com/openshift/console/blob/900c19673f6f3cebc1b57b6a0a9cadd1573950d9/dynamic-demo-plugin/package.json#L21-L24, and https://github.com/openshift/console-crontab-plugin to the same versions.
- there is a bullet for each step of the quickstart
- the steps are indented but should't be
- ordered list items are missing their numbers

Before we can adopt PatternFly 6, we need to drop PatternFly 4. We should drop 4 first so we can understand what impact if any that will have on plugins.
AC:
- Remove PF4 package. Console should not load any PF4 assets during the runtime.
- Remove PF4 support for DynamicPlugins - SharedModules + webpack configuration
https://github.com/openshift/console/blob/master/frontend/packages/console-shared/src/components/actions/menu/ActionMenuItem.tsx#L3 contains a reference to `@patternfly/react-core/deprecated`. In order to drop PF4 and adopt PF6, this reference needs to be removed.
This component was never finished and should be removed as it includes a reference to `@patternfly/react-core/deprecated`, which blocks the removal of PF4 and the adoption of PF6.
AC:
- Vendor PF6
- Remove all the unecessary PF5 packages and keep the patternfly/patternfly as a npm dependancy
- Remove the overpass font from webpack config
- Follow the PF6 upgrade guide. Run the codemods to automatically identify and fix major issues.
- Create a followUp stories for addressing the remaining update issues, presumably per console package.
- Update docs
Check https://www.patternfly.org/get-started/upgrade/#potential-test-failures

The API Explorer > Resource details > Access review page utilizes a custom Checkbox filter. This custom component is unnecessary as PatternFly offers comparable functionality. We should replace this customer component with a PatternFly one.
AC: Replace the CheckBox component for the Switch in the API Explorer
Instances of LogViewer are hard coded to use the dark theme. We should make that responsive to the user's choice the same we we are with the CodeEditor.
- Visit `k8s/all-namespaces/core~v1~Secret` with browser width 768px or greater.
- Click the `Create` button in the upper right of the page.
- Note the dropdown is bleeding off the page as it is aligned left and not right.

The checkboxes at the top of the ResourceLog component should be changed to Switches as that same change is being made for the YAMLEditor.
AC: Replace CheckBox component in the ResourceLog component with Switch from PF6
Throughout the code base, there are many instances of `<h1>` - `<h6>`. As a result, we have to manually style these elements to align with PatternFly. By replacing the html elements with a PatternFly component, we get the correct styling for free.
PopupKebabMenu is orphaned and contains a reference to `@patternfly/react-core/deprecated`. It and related code should be removed so we can drop PF4 and adopt PF6.
The dynamic-demo-plugin in the openshift/console repository currently relies on PatternFly 5. To align with the latest design standards and to ensure consistency with other parts of the platform, the plugin must be upgraded to use PatternFly 6.
This involves updating dependencies, refactoring code where necessary to comply with PatternFly 6 components and APIs, and testing to ensure that functionality and UI are not disrupted by the changes.
AC:
- PatternFly 5 is replaced with PatternFly 6 in dynamic-demo-plugin. Follow the PF6 upgrade guide.
- All affected components and styles are updated to comply with PatternFly 6 standards.
- Update integration tests, if necessary
- Plugin functionality is tested to ensure no regressions.
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
<your text here>
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
<your text here>
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
<enter general Feature acceptance here>
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Epic Goal
- Base on user analytics many of customers switch back and fourth between perspectives, and average15 times per session.
- The following steps will be need:
- Surface all Dev specific Nav items in the Admin Console
- Disable the Dev perspective by default but allow admins to enable via console setting
- All quickstarts need to be updated to reflect the removal of the dev perspective
- Guided tour to show updated nav for merged perpspective
Why is this important?
- We need to alleviate this pain point and improve the overall user experience for our users.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Description
As a user, I want to use Topology components in the dynamic plugin
Acceptance Criteria
- Should expose the below Topology components and utils to dynamic-plugin-sdk
getModifyApplicationAction
baseDataModelGetter
getWorkloadResources
contextMenuActions
CreateConnector
createConnectorCallback (e
Description:
Update ODC e2e automation tests
Acceptance Criteria
- Should add/update the test case to test default behaviour in console i.e only admin perspective is enabled and no perspective switcher is there (Should add tests for ODC component in admin perspective which are visible in navigation.)
- Should add/update the tests for the scenario where dev perspective is enabled by user - Test dev persona
Description
As a user, I want to favorite pages in the Console admin perspective
Acceptance Criteria
- Should favorite the pages in the console
- Favorite pages can be accessible from the left navigation
Additional Details:
Design https://www.figma.com/design/CMGLcRam4M523WVDqdugWz/Favoriting?node-id=0-1&p=f&t=y07SBX01YxDa6pTv-0
Description of problem:
Namespace does not persist when switching to developer view from the topology page of the admin page. This is based on the changes from pr https://github.com/openshift/console/pull/14588
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1. Go to topology page on ain view after login
2. Select/Create a namespace
3. Switch to developer perspective
Actual results:
Namespace do not persist
Expected results:
Namespace should persist
Additional info:
https://drive.google.com/file/d/1VYg-pWt4ZCYKtmPx4bIK6L2Lkt3WpOPv/view?usp=sharing
Description
As a user, I want to see actions regarding the merge perspective in getting started resources section
Acceptance Criteria
- Update getting started resources action on the cluster overview page
- Update getting started resources action on the project overview page in admin perspective
- content for cluster overview page and project overview page will be same
Additional Details:
Description
As a user, I want to know how I can enable the developer perspective in the Web console
Acceptance Criteria
- Add a quick start to let the user know about the steps to enable the Developer perspective in the web console
Additional Details:
Steps to enable dev perspective through UI
- search for console (console.operator.openshift.io/cluster) on search page
- open cluster details page
- click on action menu and select Customize option. It will open Cluster configuration page
- under General tab there is Perspectives option to enable and disabled
Description of problem:
Disable Guided tour in admin perspective for now as e2e is failing because of it and will re-enable it once we fix the e2e.
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1.
2.
3.
Actual results:
Expected results:
Additional info:
Description
As a user, I want to know about the nav option added to the Admin perspective from the Developer perspective.
Acceptance Criteria
- Add guided tour to the Admin perspective to let the user know about the unified perspective
Additional Details:
https://www.figma.com/proto/xSf03qhQdjL1JP0VXegckQ/Navigation?node-id=262-2537
Description
As a user, I want to use Topology components in the dynamic plugin
Acceptance Criteria
- Should expose the Topology components and utils to dynamic-plugin-sdk
Additional Details:
Utils and component needs to be exposed
https://docs.google.com/spreadsheets/d/1B0TLMtRY9uUR-ma0po3ma0rwgEE7T5w-v-k6f0Ak_tk/edit?gid=0#gid=0
Description
As a developer, I do not want to maintain the code for a project already dead.
Acceptance Criteria
- Remove RHOAS plugin https://github.com/openshift/console/tree/master/frontend/packages/rhoas-plugin
- Remove RHOAS-catalog-source https://github.com/openshift/console/blob/master/frontend/packages/dev-console/integration-tests/testData/yamls/operator-installtion/RHOAS-catalog-source.yaml
- Check if there is dependencies in other package and fix it
Additional Details:
Feature Overview (aka. Goal Summary)
K8s 1.31 introduces VolumeAttributesClass as beta (code in external provisioner). We should make it available to customers as tech preview.
VolumeAttributesClass allows PVC to be modified after their creation and while attached. There is as vast number of parameters that can be updated but the most popular is to change the QoS values. Parameters that can be changed depend on the driver.
Goals (aka. expected user outcomes)
Productise VolumeAttributesClass as TP in anticipation for GA. Customer can start testing VolumeAttributesClass.
Requirements (aka. Acceptance Criteria):
- Disabled by default
- put it under TechPreviewNoUpgrade
- make sure VolumeAttributeClass object is available in beta APIs
- enable the feature in external-provisioner and external-resizer at least in AWS EBS CSI driver, check the other drivers.
- Add RBAC rules for these objects
- make sure we run its tests in one of TechPreviewNoUpgrade CI jobs (with hostpath CSI driver)
- reuse / add a job with AWS EBS CSI driver + tech preview.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | both |
| Classic (standalone cluster) | yes |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | all |
| Connected / Restricted Network | both |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all |
| Operator compatibility | N/A core storage |
| Backport needed (list applicable versions) | None |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | TBD for TP |
| Other (please specify) | n/A |
Use Cases (Optional):
As an OCP user, I want to change parameters of my existing PVC such as the QoS attributes.
Questions to Answer (Optional):
Get list of drivers that supports it (from the ones we ship)
Out of Scope
No UI for TP
Background
There's been some limitations and complains on the fact that PVC attributes are sealed after their creation avoiding customers to update them. This is particularly impacting for a specific QoS is set and the volume requirements are changing.
Customer Considerations
Customer should not use it in production atm. The driver used by customers must support this feature.
Documentation Considerations
Document VolumeAttributesClass creation and how to update PVC. Mention any limitation. Mention it's tech preview no upgrade. Add drivers support if needed.
Interoperability Considerations
Check which drivers support it for which parameters.
Epic Goal
Support upstream feature "VolumeAttributesClass" in OCP as Beta, i.e. test it and have docs for it.
Why is this important?
- We get this upstream feature through Kubernetes rebase. We should ensure it works well in OCP and we have docs for it.
Upstream links
- Enhancement issue: https://github.com/kubernetes/enhancements/issues/3751
- KEP: https://github.com/kubernetes/enhancements/pull/3780
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
- https://github.com/openshift/csi-operator/pull/314
- https://github.com/openshift/cluster-storage-operator/pull/550
- https://github.com/openshift/cluster-storage-operator/pull/549
- https://github.com/openshift/cluster-storage-operator/pull/545
- https://github.com/openshift/cluster-storage-operator/pull/542
Red Hat Product Security recommends that pods be deployed with readOnlyRootFilesystem set to true in the SecurityContext, but does not require it because a successful attack can only be carried out with a combination of weaknesses and OpenShift runs with a variety of mitigating controls.
However, customers are increasingly asking questions about why pods from Red Hat, and deployed as part of OpenShift, do not follow common hardening recommendations.
Note that setting readOnlyRootFilesystem to true ensures that the container's root filesystem is mounted as read-only. This setting has nothing to do with host access.
For more information, see
https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
Setting the readOnlyRootFilesystem flag to true reduces the attack surface of your containers, preventing an attacker from manipulating the contents of your container and its root file system.
If your container needs to write temporary files, you can specify the ability to mount an emptyDir in the Security Context for your pod as described here. https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#set-the-security-context-for-a-pod
The following containers have been identified by customer scans as needing remediation. If your pod will not function with readOnlyRootFilesystem set to true, please document why so that we can document the reason for the exception.
- Service Mesh operator with sidecar-injector (this needs some additional investigation as we no longer ship the sidecar-injector with Service Mesh)
- S2I and Build operators: webhook
- tekton-pipelines-controller
- tekton-chains-controller
- openshift-pipelines-operator-cluster-operations
- tekton-operator-webhook
- openshift-pipelines-operator-lifecycle-event-listener
- Pac-webhook (part of Pipelines)
- Cluster ingress operator: serve-healthcheck-canary
- Node tuning operator: Tuned
- Machine Config Operator: Machine-config-daemon
- ACM Operator: Klusterlet-manifestwork-agent. This was fixed in ACM 2.10. https://github.com/stolostron/ocm/blob/backplane-2.5/manifests/klusterlet/management/klusterlet-work-deployment.yaml
1. Proposed title of this feature request
[openshift-cloud-credential-operator] - readOnlyRootFilesystem should be explicitly to true and if required to false for security reason
2. What is the nature and description of the request?
According to security best practice, it's recommended to set readOnlyRootFilesystem: true for all containers running on kubernetes. Given that openshift-cloud-credential-operator does not set that explicitly, it's requested that this is being evaluated and if possible set to readOnlyRootFilesystem: true or otherwise to readOnlyRootFilesystem: false with a potential explanation why the file-system needs to be write-able.
3. Why does the customer need this? (List the business requirements here)
Extensive security audits are run on OpenShift Container Platform 4 and are highlighting that many vendor specific container is missing to set readOnlyRootFilesystem: true or else justify why readOnlyRootFilesystem: false is set.
4. List any affected packages or components.
openshift-cloud-credential-operator
Enable readOnlyRootFilesystem on all of the cloud-credential-operator pods. This will require reverting prior changes that caused the tls-ca-bundler.pem to be mounted in a temporary location and then moved to the default location as part of the cloud-credential-operator pod's command.
Feature Overview (aka. Goal Summary)
A common concern with dealing with escalations/incidents in Managed OpenShift Hosted Control Planes is the resolution time incurred when the fix needs to be delivered in a component of the solution that ships within the OpenShift release payload. This is because OpenShift's release payloads:
- Have a hotfix process that is customer/support-exception targeted rather than fleet targeted
- Can take weeks to be available for Managed OpenShift
This feature seeks to provide mechanisms that put the upper time boundary in delivering such fixes to match the current HyperShift Operator <24h expectation
Goals (aka. expected user outcomes)
- Hosted Control Plane fixes are delivered through Konflux builds
- No additional upgrade edges
- Release specific
- Adequate, fleet representative, automated testing coverage
- Reduced human interaction
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
- Overriding Hosted Control Plane components can be done automatically once the PRs are ready and the affected versions have been properly identified
- Managed OpenShift Hosted Clusters have their Control Planes fix applied without requiring customer intervention and without workload disruption beyond what might already be incurred because of the incident it is solving
- Fix can be promoted through integration, stage and production canary with a good degree of observability
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | managed (ROSA and ARO) |
| Classic (standalone cluster) | No |
| Hosted control planes | Yes |
| Multi node, Compact (three node), or Single node (SNO), or all | All supported ROSA/HCP topologies |
| Connected / Restricted Network | All supported ROSA/HCP topologies |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | All supported ROSA/HCP topologies |
| Operator compatibility | CPO and Operators depending on it |
| Backport needed (list applicable versions) | TBD |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | No |
| Other (please specify) | No |
Use Cases (Optional):
- Incident response when the engineering solution is partially or completely in the Hosted Control Plane side rather than in the HyperShift Operator
Out of Scope
- HyperShift Operator binary bundling
Background
Discussed previously during incident calls. Design discussion document
Customer Considerations
- Because the Managed Control Plane version does not change but it is overridden, customer visibility and impact should be limited as much as possible.
Documentation Considerations
SOP needs to be defined for:
- Requesting and approving the fleet wide fixes described above
- Building and delivering them
- Identifying clusters with deployed fleet wide fixes
Goal
- Have a Konflux build for every supported branch on every pull request / merge that modifies the Control Plane Operator
Why is this important?
- In order to build the Control Plane Operator images to be used for management cluster wide overrides.
- To be able to deliver managed Hosted Control Plane fixes to managed OpenShift with a similar SLO as the fixes for the HyperShift Operator.
Scenarios
- A PR that modifies the control plane in a supported branch is posted for a fix affecting managed OpenShift
Acceptance Criteria
- Dev - Konflux application and component per supported release
- Dev - SOPs for managing/troubleshooting the Konflux Application
- Dev - Release Plan that delivers to the appropriate AppSre production registry
- QE - HyperShift Operator versions that encode an override must be tested with the CPO Konflux builds that they make
Dependencies (internal and external)
- Konflux
Previous Work (Optional):
Open questions:
- Antoni Segura Puimedon How long or how many times should the CPO override be tested?
Done Checklist
- CI - CI is running, tests are automated and merged.
- DEV - Konflux App link: <link to Konflux App for CPO>
- DEV - SOP: <link to meaningful PR or GitHub Issue>
- QE - Test plan in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
The default PR posting and pushing tekton file that Konflux generates builds always. We can be more efficient with resources.
It is necessary to get the builds off of main for CPO overrides.
Feature Overview (aka. Goal Summary)
Rolling out new versions of HyperShift Operator or Hosted Control Plane components such as HyperShift's Control Plane Operator will no longer carry the possibility of triggering a Node rollout that can affect customer workloads running on those nodes
Goals (aka. expected user outcomes)
Customer Nodepool rollouts exhaustive cause list will be:
- Due to customer direct scaling up/down of the Nodepool
- Due to customer change of Hosted Cluster or Nodepool configuration that is documented to incur in a rollout
Customers will have visibility on rollouts that are pending so that they can effect a rollout of their affected nodepools at their earliest convenience
Requirements (aka. Acceptance Criteria):
- Observability:
- It must be possible to account for all Nodepools with pending rollouts
- It must be possible to identify all the Hosted Clusters with Nodepools with pending rollouts
- It must be possible for a customer to see that a Nodepool has pending rollouts
- Kubernetes expectations on resource reconciliation must be upheld
- Queued rollouts must survive HyperShift restarts
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Managed (ROSA and ARO) |
| Classic (standalone cluster) | No |
| Hosted control planes | Yes |
| Multi node, Compact (three node), or Single node (SNO), or all | All supported Managed Hosted Control Plane topologies and configurations |
| Connected / Restricted Network | All supported Managed Hosted Control Plane topologies and configurations |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | All supported Managed Hosted Control Plane topologies and configurations |
| Operator compatibility | N/A |
| Backport needed (list applicable versions) | All supported Managed Hosted Control Plane releases |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | Yes. Console represtation of Nodepools/Machinepools should indicate pending rollouts and allow them to be triggered |
| Other (please specify) |
Use Cases (Optional):
- Managed OpenShift fix requires a Node rollout to be applied
Questions to Answer (Optional):
- Bryan Cox
- Should we explicitly call out the OCP versions in Backport needed (list applicable versions)?
- Antoni Segura Puimedon: Depends on what the supported OCP versions are in Managed OpenShift by the time this feature is delivered
- Is there a missing Goal of this feature, to force a rollout at a particular date? My line of thinking is what about CVE issues on the NodePool OCP version - are we giving them a warning like "hey you have a pending rollout because of a CVE; if you don't update the nodes yourself, we will on such & such date"?
- Antoni Segura Puimedon: Date based rollouts are out of scope (see its section).
- Should we explicitly call out the OCP versions in Backport needed (list applicable versions)?
- Juan Manuel Parrilla Madrid
- What’s the expectations on a regular customer nodePool upgrade? The change will be directly applied or queued following the last requested change?
- Antoni Segura Puimedon: Combinded single rollout.
- This only applies to NodePool changes or also would affect CP upgrades (thinking of OVN changes that could also affect the data plane)?
- Antoni Segura Puimedon: CP upgrades that would trigger Nodepool rollouts are in scope. OVN changes should only apply if CNO or its daemonsets are going to cause reboots
- How the customer will trigger the pending rollouts? An alert will trigger in the hosted cluster console?
- Antoni Segura Puimedon: I guess there are multiple options like scaling down and up and also adding some API to Nodepool
- I assume we will use a new status condition to reflect the current queue of pending rollouts, it’s that the case?.
- Antoni Segura Puimedon: That's a good guess. Hopefully we can represent all we want with it or we constrain ourselves to what it can express
- With "Queued rollouts must survive HyperShift restarts"... What kind of details we wanna store there (“there” should be the place to persist the changes queued), the order, the number of rollouts, the destination Hashes, more info…?
- What’s the expectations on a regular customer nodePool upgrade? The change will be directly applied or queued following the last requested change?
-
-
- Antoni Segura Puimedon: I'll leave that as an open question to refine
I'll If there are more than one change pending, we asume there will be more than one reboot?
- Antoni Segura Puimedon: I'll leave that as an open question to refine
-
Out of Scope
- Maintenance windows
- Queuing of rollouts on user actions (as that does not meet the Kubernetes reconciliation expectations and is better addressed at either the Cluster Service API level or better yet, at the customer automation side).
- Forced rollouts of pending updates on a certain date. That is something that should be handled at the Cluster Service level if there is desire to provide it.
Background
Past incidents with fixes to ignition generation resulting in rollout unexpected by the customer with workload impact
Customer Considerations
There should be an easy way to see, understand the content and trigger queued updates
Documentation Considerations
SOPs for the observability above
ROSA documentation for queued updates
Interoperability Considerations
ROSA/HCP and ARO/HCP
Goal
- Nodepools can hold off on performing a rollout of their nodes until said roll-out is triggered
Why is this important?
- Allows Managed Service to implement their policies or Node rollouts regardless if that is:
- Node maintenance windows
- Explicit user confirmation
Scenarios
- HyperShift upgrade fixes/adds reconciliation of some NodePool spec fields that result in ignition changes. Said upgrade should respect the Nodepool contract of not triggering node replacement/reboot without user/service intervention
- An important fix for the Nodes (potentially a CVE) comes up and the user wants to trigger a rollout at any given point in time to receive the benefits of the fix.
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- SD QE - covered in SD promotion testing
- Release Technical Enablement - Must have TE slides
Open questions:
- What is the right UX to trigger the roll-out in these cases? Should Cluster service just scale down and up or can we offer a more powerful/convenient UX to the service operators.
Done Checklist
- CI - CI is running, tests are automated and merged.
- * Documentation and SRE enablement
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
test to capture HO updates causing nodePool reboots
Feature Overview
The OpenShift IPsec implementation will be enhanced for a growing set of enterprise use cases, and for larger scale deployments.
Goals
The OpenShift IPsec implementation was originally built for purpose-driven use cases from telco NEPs, but was also be useful for a specific set of other customer use cases outside of that context. As customer adoption grew and it was adopted by some of the largest (by number of cluster nodes) deployments in the field, it became obvious that some redesign is necessary in order to continue to deliver enterprise-grade IPsec, for both East-West and North-South traffic, and for some of our most-demanding customer deployments.
Key enhancements include observability and blocked traffic across paths if IPsec encryption is not functioning properly.
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Questions to answer…
Out of Scope
- Configuration of external-to-cluster IPsec endpoints for N-S IPsec.
Background, and strategic fit
The OpenShift IPsec feature is fundamental to customer deployments for ensuring that all traffic between cluster nodes (East-West) and between cluster nodes and external-to-the-cluster entities that also are configured for IPsec (North-South) is encrypted by default. This encryption must scale to the largest of deployments.
Assumptions
Customer Considerations
- Customers require the option to use their own certificates or CA for IPsec.
- Customers require observability of configuration (e.g. is the IPsec tunnel up and passing traffic)
- If the IPsec tunnel is not up or otherwise functioning, traffic across the intended-to-be-encrypted network path should be blocked.
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
While running IPsec e2e tests in the CI, the data plane traffic is not flowing with desired traffic type esp or udp. For example, ipsec mode external, the traffic type seems to seen as esp for EW traffic, but it's supposed to be geneve (udp) taffic.
This issue was reproducible on a local cluster after many attempts and noticed ipsec states are not cleanup on the node which is a residue from previous test run with ipsec full mode.
[peri@sdn-09 origin]$ kubectl get networks.operator.openshift.io cluster -o yaml
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
creationTimestamp: "2024-05-13T18:55:57Z"
generation: 1362
name: cluster
resourceVersion: "593827"
uid: 10f804c9-da46-41ee-91d5-37aff920bee4
spec:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
defaultNetwork:
ovnKubernetesConfig:
egressIPConfig: {}
gatewayConfig:
ipv4: {}
ipv6: {}
routingViaHost: false
genevePort: 6081
ipsecConfig:
mode: External
mtu: 1400
policyAuditConfig:
destination: "null"
maxFileSize: 50
maxLogFiles: 5
rateLimit: 20
syslogFacility: local0
type: OVNKubernetes
deployKubeProxy: false
disableMultiNetwork: false
disableNetworkDiagnostics: false
logLevel: Normal
managementState: Managed
observedConfig: null
operatorLogLevel: Normal
serviceNetwork:
- 172.30.0.0/16
unsupportedConfigOverrides: null
useMultiNetworkPolicy: false
status:
conditions:
- lastTransitionTime: "2024-05-13T18:55:57Z"
status: "False"
type: ManagementStateDegraded
- lastTransitionTime: "2024-05-14T10:13:12Z"
status: "False"
type: Degraded
- lastTransitionTime: "2024-05-13T18:55:57Z"
status: "True"
type: Upgradeable
- lastTransitionTime: "2024-05-14T11:50:26Z"
status: "False"
type: Progressing
- lastTransitionTime: "2024-05-13T18:57:13Z"
status: "True"
type: Available
readyReplicas: 0
version: 4.16.0-0.nightly-2024-05-08-222442
[peri@sdn-09 origin]$ oc debug node/worker-0
Starting pod/worker-0-debug-k6nlm ...
To use host binaries, run `chroot /host`
Pod IP: 192.168.111.23
If you don't see a command prompt, try pressing enter.
sh-5.1# chroot /host
sh-5.1# toolbox
Checking if there is a newer version of registry.redhat.io/rhel9/support-tools available...
Container 'toolbox-root' already exists. Trying to start...
(To remove the container and start with a fresh toolbox, run: sudo podman rm 'toolbox-root')
toolbox-root
Container started successfully. To exit, type 'exit'.
[root@worker-0 /]# tcpdump -i enp2s0 -c 1 -v --direction=out esp and src 192.168.111.23 and dst 192.168.111.24
dropped privs to tcpdump
tcpdump: listening on enp2s0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
16:07:01.854214 IP (tos 0x0, ttl 64, id 20451, offset 0, flags [DF], proto ESP (50), length 152)
worker-0 > worker-1: ESP(spi=0x52cc9c8d,seq=0xe1c5c), length 132
1 packet captured
6 packets received by filter
0 packets dropped by kernel
[root@worker-0 /]# exit
exit
sh-5.1# ipsec whack --trafficstatus
006 #20: "ovn-1184d9-0-in-1", type=ESP, add_time=1715687134, inBytes=206148172, outBytes=0, maxBytes=2^63B, id='@1184d960-3211-45c4-a482-d7b6fe995446'
006 #19: "ovn-1184d9-0-out-1", type=ESP, add_time=1715687112, inBytes=0, outBytes=40269835, maxBytes=2^63B, id='@1184d960-3211-45c4-a482-d7b6fe995446'
006 #27: "ovn-185198-0-in-1", type=ESP, add_time=1715687419, inBytes=71406656, outBytes=0, maxBytes=2^63B, id='@185198f6-7dde-4e9b-b2aa-52439d2beef5'
006 #26: "ovn-185198-0-out-1", type=ESP, add_time=1715687401, inBytes=0, outBytes=17201159, maxBytes=2^63B, id='@185198f6-7dde-4e9b-b2aa-52439d2beef5'
006 #14: "ovn-922aca-0-in-1", type=ESP, add_time=1715687004, inBytes=116384250, outBytes=0, maxBytes=2^63B, id='@922aca42-b893-496e-bb9b-0310884f4cc1'
006 #13: "ovn-922aca-0-out-1", type=ESP, add_time=1715686986, inBytes=0, outBytes=986900228, maxBytes=2^63B, id='@922aca42-b893-496e-bb9b-0310884f4cc1'
006 #6: "ovn-f72f26-0-in-1", type=ESP, add_time=1715686855, inBytes=115781441, outBytes=98, maxBytes=2^63B, id='@f72f2622-e7dc-414e-8369-6013752ea15b'
006 #5: "ovn-f72f26-0-out-1", type=ESP, add_time=1715686833, inBytes=9320, outBytes=29002449, maxBytes=2^63B, id='@f72f2622-e7dc-414e-8369-6013752ea15b'
sh-5.1# ip xfrm state; echo ' '; ip xfrm policy
src 192.168.111.21 dst 192.168.111.23
proto esp spi 0x7f7ddcf5 reqid 16413 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0x6158d9a0f4a28598500e15f81a40ef715502b37ecf979feb11bbc488479c8804598011ee 128
lastused 2024-05-14 16:07:11
anti-replay esn context:
seq-hi 0x0, seq 0x18564, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
ffffffff ffffffff ffffffff ffffffff
sel src 192.168.111.21/32 dst 192.168.111.23/32 proto udp dport 6081
src 192.168.111.23 dst 192.168.111.21
proto esp spi 0xda57e42e reqid 16413 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0x810bebecef77951ae8bb9a46cf53a348a24266df8b57bf2c88d4f23244eb3875e88cc796 128
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.23/32 dst 192.168.111.21/32 proto udp sport 6081
src 192.168.111.21 dst 192.168.111.23
proto esp spi 0xf84f2fcf reqid 16417 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0x0f242efb072699a0f061d4c941d1bb9d4eb7357b136db85a0165c3b3979e27b00ff20ac7 128
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.21/32 dst 192.168.111.23/32 proto udp sport 6081
src 192.168.111.23 dst 192.168.111.21
proto esp spi 0x9523c6ca reqid 16417 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0xe075d39b6e53c033f5225f8be48efe537c3ba605cee2f5f5f3bb1cf16b6c53182ecf35f7 128
lastused 2024-05-14 16:07:11
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0x10fb2
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.23/32 dst 192.168.111.21/32 proto udp dport 6081
src 192.168.111.20 dst 192.168.111.23
proto esp spi 0x459d8516 reqid 16397 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0xee778e6db2ce83fa24da3b18e028451bbfcf4259513bca21db832c3023e238a6b55fdacc 128
lastused 2024-05-14 16:07:13
anti-replay esn context:
seq-hi 0x0, seq 0x3ec45, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
ffffffff ffffffff ffffffff ffffffff
sel src 192.168.111.20/32 dst 192.168.111.23/32 proto udp dport 6081
src 192.168.111.23 dst 192.168.111.20
proto esp spi 0x3142f53a reqid 16397 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0x6238fea6dffdd36cbb909f6aab48425ba6e38f9d32edfa0c1e0fc6af8d4e3a5c11b5dfd1 128
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.23/32 dst 192.168.111.20/32 proto udp sport 6081
src 192.168.111.20 dst 192.168.111.23
proto esp spi 0xeda1ccb9 reqid 16401 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0xef84a90993bd71df9c97db940803ad31c6f7d2e72a367a1ec55b4798879818a6341c38b6 128
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.20/32 dst 192.168.111.23/32 proto udp sport 6081
src 192.168.111.23 dst 192.168.111.20
proto esp spi 0x02c3c0dd reqid 16401 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0x858ab7326e54b6d888825118724de5f0c0ad772be2b39133c272920c2cceb2f716d02754 128
lastused 2024-05-14 16:07:13
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0x26f8e
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.23/32 dst 192.168.111.20/32 proto udp dport 6081
src 192.168.111.24 dst 192.168.111.23
proto esp spi 0xc9535b47 reqid 16405 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0xd7a83ff4bd6e7704562c597810d509c3cdd4e208daabf2ec074d109748fd1647ab2eff9d 128
lastused 2024-05-14 16:07:14
anti-replay esn context:
seq-hi 0x0, seq 0x53d4c, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
ffffffff ffffffff ffffffff ffffffff
sel src 192.168.111.24/32 dst 192.168.111.23/32 proto udp dport 6081
src 192.168.111.23 dst 192.168.111.24
proto esp spi 0xb66203c8 reqid 16405 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0xc207001a7f1ed7f114b3e327308ddbddc36de5272a11fe0661d03eaecc84b6761c7ec9c4 128
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.23/32 dst 192.168.111.24/32 proto udp sport 6081
src 192.168.111.24 dst 192.168.111.23
proto esp spi 0x2e4d4deb reqid 16409 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0x91e399d83aa1c2626424b502d4b8dae07d4a170f7ef39f8d1baca8e92b8a1dee210e2502 128
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.24/32 dst 192.168.111.23/32 proto udp sport 6081
src 192.168.111.23 dst 192.168.111.24
proto esp spi 0x52cc9c8d reqid 16409 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0xb605451f32f5dd7a113cae16e6f1509270c286d67265da2ad14634abccf6c90f907e5c00 128
lastused 2024-05-14 16:07:14
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0xe2735
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.23/32 dst 192.168.111.24/32 proto udp dport 6081
src 192.168.111.22 dst 192.168.111.23
proto esp spi 0x973119c3 reqid 16389 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0x87d13e67b948454671fb8463ec0cd4d9c38e5e2dd7f97cbb8f88b50d4965fb1f21b36199 128
lastused 2024-05-14 16:07:14
anti-replay esn context:
seq-hi 0x0, seq 0x2af9a, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
ffffffff ffffffff ffffffff ffffffff
sel src 192.168.111.22/32 dst 192.168.111.23/32 proto udp dport 6081
src 192.168.111.23 dst 192.168.111.22
proto esp spi 0x4c3580ff reqid 16389 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0x2c09750f51e86d60647a60e15606f8b312036639f8de2d7e49e733cda105b920baade029 128
lastused 2024-05-14 14:36:43
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0x1
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.23/32 dst 192.168.111.22/32 proto udp sport 6081
src 192.168.111.22 dst 192.168.111.23
proto esp spi 0xa3e469dc reqid 16393 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0x1d5c5c232e6fd4b72f3dad68e8a4d523cbd297f463c53602fad429d12c0211d97ae26f47 128
lastused 2024-05-14 14:18:42
anti-replay esn context:
seq-hi 0x0, seq 0xb, oseq-hi 0x0, oseq 0x0
replay_window 128, bitmap-length 4
00000000 00000000 00000000 000007ff
sel src 192.168.111.22/32 dst 192.168.111.23/32 proto udp sport 6081
src 192.168.111.23 dst 192.168.111.22
proto esp spi 0xdee8476f reqid 16393 mode transport
replay-window 0 flag esn
aead rfc4106(gcm(aes)) 0x5895025ce5b192a7854091841c73c8e29e7e302f61becfa3feb44d071ac5c64ce54f5083 128
lastused 2024-05-14 16:07:14
anti-replay esn context:
seq-hi 0x0, seq 0x0, oseq-hi 0x0, oseq 0x1f1a3
replay_window 128, bitmap-length 4
00000000 00000000 00000000 00000000
sel src 192.168.111.23/32 dst 192.168.111.22/32 proto udp dport 6081
src 192.168.111.23/32 dst 192.168.111.21/32 proto udp sport 6081
dir out priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16413 mode transport
src 192.168.111.21/32 dst 192.168.111.23/32 proto udp dport 6081
dir in priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16413 mode transport
src 192.168.111.23/32 dst 192.168.111.21/32 proto udp dport 6081
dir out priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16417 mode transport
src 192.168.111.21/32 dst 192.168.111.23/32 proto udp sport 6081
dir in priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16417 mode transport
src 192.168.111.23/32 dst 192.168.111.20/32 proto udp sport 6081
dir out priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16397 mode transport
src 192.168.111.20/32 dst 192.168.111.23/32 proto udp dport 6081
dir in priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16397 mode transport
src 192.168.111.23/32 dst 192.168.111.20/32 proto udp dport 6081
dir out priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16401 mode transport
src 192.168.111.20/32 dst 192.168.111.23/32 proto udp sport 6081
dir in priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16401 mode transport
src 192.168.111.23/32 dst 192.168.111.24/32 proto udp sport 6081
dir out priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16405 mode transport
src 192.168.111.24/32 dst 192.168.111.23/32 proto udp dport 6081
dir in priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16405 mode transport
src 192.168.111.23/32 dst 192.168.111.24/32 proto udp dport 6081
dir out priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16409 mode transport
src 192.168.111.24/32 dst 192.168.111.23/32 proto udp sport 6081
dir in priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16409 mode transport
src 192.168.111.23/32 dst 192.168.111.22/32 proto udp sport 6081
dir out priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16389 mode transport
src 192.168.111.22/32 dst 192.168.111.23/32 proto udp dport 6081
dir in priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16389 mode transport
src 192.168.111.23/32 dst 192.168.111.22/32 proto udp dport 6081
dir out priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16393 mode transport
src 192.168.111.22/32 dst 192.168.111.23/32 proto udp sport 6081
dir in priority 1360065 ptype main
tmpl src 0.0.0.0 dst 0.0.0.0
proto esp reqid 16393 mode transport
src ::/0 dst ::/0
socket out priority 0 ptype main
src ::/0 dst ::/0
socket in priority 0 ptype main
src ::/0 dst ::/0
socket out priority 0 ptype main
src ::/0 dst ::/0
socket in priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket out priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket in priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket out priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket in priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket out priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket in priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket out priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket in priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket out priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket in priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket out priority 0 ptype main
src 0.0.0.0/0 dst 0.0.0.0/0
socket in priority 0 ptype main
src ::/0 dst ::/0 proto ipv6-icmp type 135
dir out priority 1 ptype main
src ::/0 dst ::/0 proto ipv6-icmp type 135
dir fwd priority 1 ptype main
src ::/0 dst ::/0 proto ipv6-icmp type 135
dir in priority 1 ptype main
src ::/0 dst ::/0 proto ipv6-icmp type 136
dir out priority 1 ptype main
src ::/0 dst ::/0 proto ipv6-icmp type 136
dir fwd priority 1 ptype main
src ::/0 dst ::/0 proto ipv6-icmp type 136
dir in priority 1 ptype main
sh-5.1# cat /etc/ipsec.conf
# /etc/ipsec.conf - Libreswan 4.0 configuration file
#
# see 'man ipsec.conf' and 'man pluto' for more information
#
# For example configurations and documentation, see https://libreswan.org/wiki/
config setup
# If logfile= is unset, syslog is used to send log messages too.
# Note that on busy VPN servers, the amount of logging can trigger
# syslogd (or journald) to rate limit messages.
#logfile=/var/log/pluto.log
#
# Debugging should only be used to find bugs, not configuration issues!
# "base" regular debug, "tmi" is excessive ![]() and "private" will log
and "private" will log
# sensitive key material (not available in FIPS mode). The "cpu-usage"
# value logs timing information and should not be used with other
# debug options as it will defeat getting accurate timing information.
# Default is "none"
# plutodebug="base"
# plutodebug="tmi"
#plutodebug="none"
#
# Some machines use a DNS resolver on localhost with broken DNSSEC
# support. This can be tested using the command:
# dig +dnssec DNSnameOfRemoteServer
# If that fails but omitting '+dnssec' works, the system's resolver is
# broken and you might need to disable DNSSEC.
# dnssec-enable=no
#
# To enable IKE and IPsec over TCP for VPN server. Requires at least
# Linux 5.7 kernel or a kernel with TCP backport (like RHEL8 4.18.0-291)
# listen-tcp=yes
# To enable IKE and IPsec over TCP for VPN client, also specify
# tcp-remote-port=4500 in the client's conn section.
# if it exists, include system wide crypto-policy defaults
include /etc/crypto-policies/back-ends/libreswan.config
# It is best to add your IPsec connections as separate files
# in /etc/ipsec.d/
include /etc/ipsec.d/*.conf
sh-5.1# cat /etc/ipsec.d/openshift.conf
# Generated by ovs-monitor-ipsec...do not modify by hand!
config setup
uniqueids=yes
conn %default
keyingtries=%forever
type=transport
auto=route
ike=aes_gcm256-sha2_256
esp=aes_gcm256
ikev2=insist
conn ovn-f72f26-0-in-1
left=192.168.111.23
right=192.168.111.22
leftid=@cf36db5c-5c54-4329-9141-b83679b18ecc
rightid=@f72f2622-e7dc-414e-8369-6013752ea15b
leftcert="ovs_certkey_cf36db5c-5c54-4329-9141-b83679b18ecc"
leftrsasigkey=%cert
rightca=%same
leftprotoport=udp/6081
rightprotoport=udp
conn ovn-f72f26-0-out-1
left=192.168.111.23
right=192.168.111.22
leftid=@cf36db5c-5c54-4329-9141-b83679b18ecc
rightid=@f72f2622-e7dc-414e-8369-6013752ea15b
leftcert="ovs_certkey_cf36db5c-5c54-4329-9141-b83679b18ecc"
leftrsasigkey=%cert
rightca=%same
leftprotoport=udp
rightprotoport=udp/6081
conn ovn-1184d9-0-in-1
left=192.168.111.23
right=192.168.111.20
leftid=@cf36db5c-5c54-4329-9141-b83679b18ecc
rightid=@1184d960-3211-45c4-a482-d7b6fe995446
leftcert="ovs_certkey_cf36db5c-5c54-4329-9141-b83679b18ecc"
leftrsasigkey=%cert
rightca=%same
leftprotoport=udp/6081
rightprotoport=udp
conn ovn-1184d9-0-out-1
left=192.168.111.23
right=192.168.111.20
leftid=@cf36db5c-5c54-4329-9141-b83679b18ecc
rightid=@1184d960-3211-45c4-a482-d7b6fe995446
leftcert="ovs_certkey_cf36db5c-5c54-4329-9141-b83679b18ecc"
leftrsasigkey=%cert
rightca=%same
leftprotoport=udp
rightprotoport=udp/6081
conn ovn-922aca-0-in-1
left=192.168.111.23
right=192.168.111.24
leftid=@cf36db5c-5c54-4329-9141-b83679b18ecc
rightid=@922aca42-b893-496e-bb9b-0310884f4cc1
leftcert="ovs_certkey_cf36db5c-5c54-4329-9141-b83679b18ecc"
leftrsasigkey=%cert
rightca=%same
leftprotoport=udp/6081
rightprotoport=udp
conn ovn-922aca-0-out-1
left=192.168.111.23
right=192.168.111.24
leftid=@cf36db5c-5c54-4329-9141-b83679b18ecc
rightid=@922aca42-b893-496e-bb9b-0310884f4cc1
leftcert="ovs_certkey_cf36db5c-5c54-4329-9141-b83679b18ecc"
leftrsasigkey=%cert
rightca=%same
leftprotoport=udp
rightprotoport=udp/6081
conn ovn-185198-0-in-1
left=192.168.111.23
right=192.168.111.21
leftid=@cf36db5c-5c54-4329-9141-b83679b18ecc
rightid=@185198f6-7dde-4e9b-b2aa-52439d2beef5
leftcert="ovs_certkey_cf36db5c-5c54-4329-9141-b83679b18ecc"
leftrsasigkey=%cert
rightca=%same
leftprotoport=udp/6081
rightprotoport=udp
conn ovn-185198-0-out-1
left=192.168.111.23
right=192.168.111.21
leftid=@cf36db5c-5c54-4329-9141-b83679b18ecc
rightid=@185198f6-7dde-4e9b-b2aa-52439d2beef5
leftcert="ovs_certkey_cf36db5c-5c54-4329-9141-b83679b18ecc"
leftrsasigkey=%cert
rightca=%same
leftprotoport=udp
rightprotoport=udp/6081
sh-5.1#
The e2e-aws-ovn-ipsec-upgrade job is currently an optional job and always_run: false because the job not reliable and success rate is so low. This must be made as mandatory CI lane after fixing its relevant issues.
The CNO rolls out ipsec mc plugin for rolling out IPsec for the cluster, but it doesn't really check master and work role machine config pools status to confirm if that's successfully installed in the cluster nodes.
Hence CNO should be made to listen for MachineConfigPool status object updates and set network operator condition accordingly based on ipsec mc plugin rollout status.
Epic Goal
- Review design and development PRs that require feedback from NE team.
Why is this important?
- Customer requires certificates to be managed by cert-manager on configured/newly added routes.
Acceptance Criteria
- All PRs are reviewed and merged.
Dependencies (internal and external)
- CFE team dependency for addressing review suggestions.
Done Checklist
- DEV - All related PRs are merged.
Placeholder to track GA work for CFE-811
Update API godoc to document that manual intervention is required for using .spec.tls.externalCertificate. Something simple like: "The Router service account needs to be granted with read-only access to this secret, please refer to openshift docs for additional details."
As a developer, I want to bump o/api into o/kubernetes repo to update API godoc added in OAPE-94
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
Why is this important?
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
- Priority+ is set by engineering
- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the "Discussion Needed: Service Delivery Architecture Overview" checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the "Discussion Needed: Service Delivery Architecture Overview" checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn't have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. ...
Open questions::
1. ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal*
Drive the technical part of the Kubernetes 1.32 upgrade, including rebasing openshift/kubernetes repository and coordination across OpenShift organization to get e2e tests green for the OCP release.
Why is this important? (mandatory)
OpenShift 4.19 cannot be released without Kubernetes 1.32
Scenarios (mandatory)
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Slack Discussion Channel - https://redhat.enterprise.slack.com/archives/C07V32J0YKF
- https://github.com/openshift/cluster-kube-apiserver-operator/pull/1777
- https://github.com/openshift/kubernetes/pull/2209
- https://github.com/openshift/kubernetes/pull/2190
- https://github.com/openshift/kubernetes/pull/2147
- https://github.com/openshift/origin/pull/29549
- https://github.com/openshift/origin/pull/29538
- https://github.com/openshift/origin/pull/29493
- https://github.com/openshift/origin/pull/29376
- https://github.com/openshift/origin/pull/29362
- https://github.com/openshift/oc/pull/1971
- https://github.com/openshift/cluster-openshift-controller-manager-operator/pull/381
- https://github.com/openshift/cluster-policy-controller/pull/160
- https://github.com/openshift/openshift-controller-manager/pull/366
- https://github.com/openshift/origin/pull/29569
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned CAPI components should be running on Kubernetes 1.30
- target is 4.18 since CAPI is always a release behind upstream
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.19 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
Epic Goal
- The goal of this epic is to upgrade all OpenShift and Kubernetes components that CCO uses to v1.32 which keeps it on par with rest of the OpenShift components and the underlying cluster version.
Why is this important?
- To make sure that Hive imports of other OpenShift components do not break when those rebase
- To avoid breaking other OpenShift components importing from CCO.
- To pick up upstream improvements
Acceptance Criteria
- CI - MUST be running successfully with tests automated
Dependencies (internal and external)
- Kubernetes 1.32 is released
Previous Work (Optional):
- Similar previous epic
CCO-595
Done Checklist
- CI - CI is running, tests are automated and merged.
As a developer, I want to upgrade the Kubernetes dependencies to 1.32
- to ensure compatibility with the OpenShift cluster
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned components should be running on Kubernetes 1.32
- This includes
- The cluster autoscaler (+operator)
- Machine API operator
- Machine API controllers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Machine API controllers for:
- Cloud Controller Manager Operator
- Cloud controller managers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Cloud controller managers for:
- Cluster Machine Approver
- Cluster API Actuator Package
- Control Plane Machine Set Operator
Why is this important?
- ...
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.32. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
- https://github.com/openshift/cloud-provider-aws/pull/104
- https://github.com/openshift/cloud-provider-aws/pull/102
- https://github.com/openshift/cloud-provider-aws/pull/98
- https://github.com/openshift/cluster-cloud-controller-manager-operator/pull/384
- https://github.com/openshift/cluster-cloud-controller-manager-operator/pull/383
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.32. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.19 release, dependencies need to be updated to 1.31. This should be done by rebasing/updating as appropriate for the repository
Epic Goal
- The goal of this epic is to upgrade all OpenShift and Kubernetes components that MCO uses to v1.29 which will keep it on par with rest of the OpenShift components and the underlying cluster version.
Why is this important?
- Uncover any possible issues with the openshift/kubernetes rebase before it merges.
- MCO continues using the latest kubernetes/OpenShift libraries and the kubelet, kube-proxy components.
- MCO e2e CI jobs pass on each of the supported platform with the updated components.
Acceptance Criteria
- All stories in this epic must be completed.
- Go version is upgraded for MCO components.
- CI is running successfully with the upgraded components against the 4.18/master branch.
Dependencies (internal and external)
- ART team creating the go 1.31 image for upgrade to go 1.31.
- OpenShift/kubernetes repository downstream rebase PR merge.
Open questions::
- Do we need a checklist for future upgrades as an outcome of this epic?-> yes, updated below.
Done Checklist
- Step 1 - Upgrade go version to match rest of the OpenShift and Kubernetes upgraded components.
- Step 2 - Upgrade Kubernetes client and controller-runtime dependencies (can be done in parallel with step 3)
- Step 3 - Upgrade OpenShift client and API dependencies
- Step 4 - Update kubelet and kube-proxy submodules in MCO repository
- Step 5 - CI is running successfully with the upgraded components and libraries against the master branch.
User or Developer story
As a MCO developer, I want to pick up the openshift/kubernetes updates for the 1.32 k8s rebase to track the k8s version as rest of the OpenShift 1.32 cluster.
Engineering Details
- Update the go.mod, go.sum and vendor dependencies pointing to the kube 1.32 libraries. This includes all direct kubernetes related libraries as well as openshift/api , openshift/client-go, openshift/library-go and openshift/runtime-utils
Acceptance Criteria:
- All k8s.io related dependencies should be upgraded to 1.32.
- openshift/api , openshift/client-go, openshift/library-go and openshift/runtime-utils should be upgraded to latest commit from master branch
- All ci tests must be passing
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Following up this issue, it's added the support for CapacityReservations but missing the support for Capacity Blocks for ML which is essential to launch the capacity-blocks.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
<your text here>
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
<enter general Feature acceptance here>
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- MAPI supports CapacityReservations, but it has the missing functionality that supports AWS capacity bloks.
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
Add support to Dxv6 machine series to be used on OpenShift deployment in Azure
Goals (aka. expected user outcomes)
As a user, I can deploy OpenShift in Azure using Dxv6 machine series so both the Control Plane and Compute Nodes can run on these machine series
Requirements (aka. Acceptance Criteria):
The new machines series that will be available in Azure soon, Dxv6 can be selected at install time to be used to deploy OpenShift on Azure
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Out of Scope
These machines series will be available for OpenShift to be used once they are declared GA by Microsoft
Background
ARO will need to support Dxv6 instance types supported. These are currently in preview. The specific instance types are:
Documentation Considerations
Usual documentation to list these machine series as tested
Interoperability Considerations
This feature will be consumed by ARO later
Epic Goal
- Test, validate and list Dxv6 machine series to be used on OpenShift deployment in Azure as supported machines
Why is this important?
- ARO will need to support Dxv6 instance types supported. These are currently in preview
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
As a customer of self managed OpenShift or an SRE managing a fleet of OpenShift clusters I should be able to determine the progress and state of an OCP upgrade and only be alerted if the cluster is unable to progress. Support a cli-status command and status-API which can be used by cluster-admin to monitor the progress. status command/API should also contain data to alert users about potential issues which can make the updates problematic.
Feature Overview (aka. Goal Summary)
Here are common update improvements from customer interactions on Update experience
- Show nodes where pod draining is taking more time.
Customers have to dig deeper often to find the nodes for further debugging.
The ask has been to bubble up this on the update progress window. - oc update status ?
From the UI we can see the progress of the update. From oc cli we can see this from "oc get cvo"
But the ask is to show more details in a human-readable format.
Know where the update has stopped. Consider adding at what run level it has stopped.
oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.12.0 True True 16s Working towards 4.12.4: 9 of 829 done (1% complete)
Documentation Considerations
Update docs for UX and CLI changes
Reference : https://docs.google.com/presentation/d/1cwxN30uno_9O8RayvcIAe8Owlds-5Wjr970sDxn7hPg/edit#slide=id.g2a2b8de8edb_0_22
Epic Goal*
Add a new command `oc adm upgrade status` command which is backed by an API. Please find the mock output of the command output attached in this card.
Why is this important? (mandatory)
- From the UI we can see the progress of the update. Using OC CLI we can see some of the information using "oc get clusterversion" but the output is not readable and it is a lot of extra information to process.
- Customer as asking us to show more details in a human-readable format as well provide an API which they can use for automation.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Tests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Other
Description of problem:
Upgrade of the ota-stage cluster from 4.14.1 to 4.15.0-ec.2 got stuck because of the operator-lifecycle-manager-packageserver ClusterOperator which never reaches the desired version (likely because its Pods are CrashLooping, which is a separate issue discussed now on Slack and OCPBUGS-23538 was filed for it)
However, I would expect CVO to enter its waiting for operator-lifecycle-manager-packageserver up to 40 minutes state, eventually hit that deadline and signal the upgrade as stuck via a Failing=True condition, but that did not happen and CVO does not signal anything problematic in this stuck state.
Version-Release number of selected component (if applicable):
upgrade from 4.14.1 to 4.15.0-ec.2
How reproducible:
Unsure
Steps to Reproduce:
1. upgrade from 4.14.1 to 4.15.0-ec.2 and hope you get stuck the way ota-stage did
Actual results:
$ OC_ENABLE_CMD_UPGRADE_STATUS=true ./oc adm upgrade status An update is in progress for 2h8m20s: Working towards 4.15.0-ec.2: 695 of 863 done (80% complete), waiting on operator-lifecycle-manager-packageserver
Expected results:
$ oc adm upgrade status Failing=True Reason: operator-lifecycle-manager-packageserver is stuck (or whatever is the message) An update is in progress for 2h8m20s: Working towards 4.15.0-ec.2: 695 of 863 done (80% complete), waiting on operator-lifecycle-manager-packageserver
Additional info
Attached CVO log and the waited-on CO yaml dump
Health insights have a lifecycle that is not suitable for the async producer/consumer architecture USC has right now, where update informers send individual insights to the controller that maintains the API instance. Health insights are expected to disappear and appear following the trigger condition, and this needs to be respected through controller restart, API unavailability etc. Basically this means that the informer should ideally work as a standard, full-reconciliation controller over a set of its insights.
We should also have an easy method to test health insight lifecycle: easy on/off switch for an artificial health insight to be reported or not, to avoid relying on true problematic conditions for testing the controller operation. Something like an existence of a label or an annotation on a resource to trigger a health insight directly.
Definition of Done
- When a resource watched by USC (so ClusterVersion ATM) has a certain annotation, USC should produce an artificial health insight
- The properties of the health insight do not matter but must clearly indicate the health insight is artificial and intended for testing
- All these scenarios must work:
- When insight is not in API, USC is running and the annotation is added to CV -> insight is added to API
- When insight is not in API, USC is running, annotation is not on CV, insight is manually added to API -> insight is removed from API
- When insight is in the API, USC is running, annotation is removed from CV -> insight is removed from API
- When insight is in the API, USC is running, insight is manually removed from API -> insight is added from API
- When insight is not in API, USC is stopped, annotation is added to CV, USC is started -> insight is added to API
- When insight is in the API, USC is stopped, annotation is removed from CV, USC is started -> insight is removed from API
- In all cases where there is an existing insight in the API and the annotation was never observed removed from the CV, any "refresh" by USC must respect the original properties of the insight (start time, uid, etc)
- Identical sync mechanism should be used for Status Insights
After OTA-960 is fixed, ClusterVersion/version and oc adm upgrade can be used to monitor the process of migrating a cluster to multi-arch.
$ oc adm upgrade info: An upgrade is in progress. Working towards 4.18.0-ec.3: 761 of 890 done (85% complete), waiting on machine-config Upgradeable=False Reason: PoolUpdating Message: Cluster operator machine-config should not be upgraded between minor versions: One or more machine config pools are updating, please see `oc get mcp` for further details Upstream: https://api.integration.openshift.com/api/upgrades_info/graph Channel: candidate-4.18 (available channels: candidate-4.18) No updates available. You may still upgrade to a specific release image with --to-image or wait for new updates to be available.
But oc adm upgrade status reports COMPLETION 100% while the migration/upgrade is still ongoing.
$ OC_ENABLE_CMD_UPGRADE_STATUS=true oc adm upgrade status Unable to fetch alerts, ignoring alerts in 'Update Health': failed to get alerts from Thanos: no token is currently in use for this session = Control Plane = Assessment: Completed Target Version: 4.18.0-ec.3 (from 4.18.0-ec.3) Completion: 100% (33 operators updated, 0 updating, 0 waiting) Duration: 15m Operator Status: 33 Healthy Control Plane Nodes NAME ASSESSMENT PHASE VERSION EST MESSAGE ip-10-0-95-224.us-east-2.compute.internal Unavailable Updated 4.18.0-ec.3 - Node is unavailable ip-10-0-33-81.us-east-2.compute.internal Completed Updated 4.18.0-ec.3 - ip-10-0-45-170.us-east-2.compute.internal Completed Updated 4.18.0-ec.3 - = Worker Upgrade = WORKER POOL ASSESSMENT COMPLETION STATUS worker Completed 100% 3 Total, 2 Available, 0 Progressing, 0 Outdated, 0 Draining, 0 Excluded, 0 Degraded Worker Pool Nodes: worker NAME ASSESSMENT PHASE VERSION EST MESSAGE ip-10-0-72-40.us-east-2.compute.internal Unavailable Updated 4.18.0-ec.3 - Node is unavailable ip-10-0-17-117.us-east-2.compute.internal Completed Updated 4.18.0-ec.3 - ip-10-0-22-179.us-east-2.compute.internal Completed Updated 4.18.0-ec.3 - = Update Health = SINCE LEVEL IMPACT MESSAGE - Warning Update Speed Node ip-10-0-95-224.us-east-2.compute.internal is unavailable - Warning Update Speed Node ip-10-0-72-40.us-east-2.compute.internal is unavailable Run with --details=health for additional description and links to related online documentation $ oc get clusterversion version NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.18.0-ec.3 True True 14m Working towards 4.18.0-ec.3: 761 of 890 done (85% complete), waiting on machine-config $ oc get co machine-config NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE machine-config 4.18.0-ec.3 True True False 63m Working towards 4.18.0-ec.3
The reason is that PROGRESSING=True is not detected for co/machine-config as the status command checks only operator.Status.Versions[name=="operator"] and it needs to check ClusterOperator.Status.Versions[name=="operator-image"] as well.
For grooming:
It will be challenging for the status command to check the operator image's pull spec because it does not know the expected value. CVO knows it because CVO holds the manifests (containing the expected value) from the multi-arch payload.
One "hacky" workaround is that the status command gets the pull spec from the MCO deployment:
oc get deployment -n openshift-machine-config-operator machine-config-operator -o json | jq -r '.spec.template.spec.containers[]|select(.name=="machine-config-operator")|.image' quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:787a505ca594b0a727549353c503dec9233a9d3c2dcd6b64e3de5f998892a1d5
Note this co/machine-config -> deployment/machine-config-operator trick may not be feasible if we want to extend it to all cluster operators. But it should work as a hacky workaround to check only MCO.
We may claim that the status command is not designed for monitoring the multi-arch migration and suggest to use oc adm upgrade instead. In that case, we can close this card as Obsolete/Won'tDo.
manifests.zip![]() has the mockData/manifests for the status cmd that are taken during the migration.
has the mockData/manifests for the status cmd that are taken during the migration.
oc#1920 started the work for the status command to recognize the migration and we need to extend the work to cover (the comments from Petr's review):
- "Target Version: 4.18.0-ec.3 (from 4.18.0-ec.3)": confusing. We should tell "multi-arch" migration somehow. Or even better: from the current arch to multi-arch, for example "Target Version: 4.18.0-ec.3 multi (from x86_64)" if we could get the origin arch from CV or somewhere else.
- We have spec.desiredUpdate.architecture since forever, and can use that being Multi as a partial hint.
MULTIARCH-4559is adding tech-preview status properties around architecture in 4.18, but tech-preview, so may not be worth bothering with in oc code. Two history entries with the same version string but different digests is probably a reliable-enough heuristic, coupled with the spec-side hint.
- We have spec.desiredUpdate.architecture since forever, and can use that being Multi as a partial hint.
- "Duration: 6m55s (Est. Time Remaining: 1h4m)": We will see if we could find a simple way to hand this special case. I do not understand "the 97% completion will be reached so fast." as I am not familiar with the algorithm. But it seems acceptable to Petr that we show N/A for the migration.
- I think I get "the 97% completion will be reached so fast." now as only MCO has the operator-image pull spec. Other COs claim the completeness immaturely. With that said, "N/A" sounds like the most possible way for now.
- Node status like "All control plane nodes successfully updated to 4.18.0-ec.3" for control planes and "ip-10-0-17-117.us-east-2.compute.internal Completed". It is technically hard to detect the transaction during migration as MCO annotates only the version. This may become a separate card if it is too big to finish with the current one.
- "targetImagePullSpec := getMCOImagePullSpec(mcoDeployment)" should be computed just once. Now it is in the each iteration of the for loop. We should also comment about why we do it with this hacky way.
Implement a new Informer controller in the Update Status Controller to watch Node resources in the cluster and maintain an update status insight for each. The informer will need to interact with additional resources such as MachineConfigPools and MachineConfigs, e.g. to discover the OCP version tied to config that is being reconciled on the Node, but should not attempt to maintain the MachineConfigPool status insights. Generally the node status insight should carry enough data for any client to be able to render a line that the oc adm upgrade status currently shows:
NAME ASSESSMENT PHASE VERSION EST MESSAGE
build0-gstfj-ci-prowjobs-worker-b-9lztv Degraded Draining 4.16.0-ec.2 ? failed to drain node: <node> after 1 hour. Please see machine-config-controller logs for more informatio
build0-gstfj-ci-prowjobs-worker-d-ddnxd Unavailable Pending ? ? Machine Config Daemon is processing the node
build0-gstfj-ci-tests-worker-b-d9vz2 Unavailable Pending ? ? Not ready
build0-gstfj-ci-tests-worker-c-jq5rk Unavailable Updated 4.16.0-ec.3 - Node is marked unschedulable
The basic expectations for Node status insights are described in the design docs but the current source of truth for the data structure is the NodeStatusInsight structure from https://github.com/openshift/api/pull/2012 .
Definition of Done
- During the upgrade, the status api contains a Node status insight for each Node in the cluster
- Do not bother with the status insight lifecycle (when a Node is removed from the cluster, the status insight should technically disappear, but do not address that in this card, suitable lifecycle mechanism for this does not exist yet and OTA-1418 will address it)
- Overall the functionality should match what oc adm upgrade status client-based checks
- The NodeStatusInsight should have correctly populated: name, resource, poolResource, scopeType, version, estToComplete and message fields, following the existing logic from oc adm upgrade status
- Health insights are out of scope
- Status insights for MCPs are out of scope
- The Updating condition has a similar meaning and interpretation like in the other insights.
- When its status is False, it will contain a reason which needs to be interpreted. Three known reasons are Pending, Updated and Paused:
- Pending: Node will eventually be updated but has not started yet
- Updated: Node already underwent the update.
- Paused: Node is running an outdated version but something is pausing the process (like parent MCP .spec.paused field)
- When Updating=True, there are also three known reasons: Draining, Updating and Rebooting.
- Draining: MCO drains the node so it can be updated and rebooted
- Updating: MCO applies the new config and prepares the node to be rebooted into the new OS version
- Rebooting: MCO is rebooting the node, after which it (hopefully) becomes ready again
- When its status is False, it will contain a reason which needs to be interpreted. Three known reasons are Pending, Updated and Paused:
- The Degraded and Unavailable condition logic should match the existing assessment logic from oc adm upgrade status
- https://github.com/openshift/cluster-version-operator/pull/1164
- https://github.com/openshift/cluster-version-operator/pull/1144
- https://github.com/openshift/cluster-version-operator/pull/1145
- https://github.com/openshift/cluster-version-operator/pull/1136
- https://github.com/openshift/cluster-version-operator/pull/1142
Extend the Control Plane Informer in the Update Status Controller so it watches ClusterOperator resources in the cluster and maintains an update status insight for each.
The actual API structure for an update status insights needs to be taken from whatever state https://github.com/openshift/api/pull/2012 is at the moment. The story does not include the actual API form nor how it is exposed by the cluster (depending on the state of API approval, the USC may still expose the API as a ConfigMap or an actual custom resource), it includes just the logic to watch ClusterOperator resources and producing a matching set of cluster operator status insights.
The basic expectations for cluster operator status insights are described in the design docs
Definition of Done
- During the control plane upgrade, the status api contains a ClusterOperator status insight for each platform (hopefully we can use the same selection logic like we have in the prototype) ClusterOperator in the cluster
- Outside of control plane update, the cluster operator status insights are not present
- Updating condition:
- If a CO is updating right now (Progressing=True && does not have a target operator version), then Updating=True and a suitable reason
- Otherwise, if it has target version, Updating=False and Reason=Updated
- Otherwise, if it does not have target version, Updating=False and Reason=Pending
- Healthy condition
- Corresponds to the existing checks in the client prototype, taking into account the thresholds (Healthy=True if the "bad" condition is not holding long enough yet, but we may invent a special Reason for this case)
- This card does *not* involve creating Health Insights when there are unhealthy operators
- This card does *not* involve updating a ClusterVersion status insight from the CO-related data (such as completeness percentage or duration estimate)
On the call to discuss oc adm upgrade status roadmap to server side-implementation (notes) we agreed on basic architectural direction and we can starting moving in that direction:
- status API will be backed by a new controller
- new controller will be a separate binary but delivered in the CVO image (=release payload) to avoid needing new ClusterOperator
- new operator will maintain a singleton resource of a new UpgradeStatus CRD - this is the interface to the consumers
Let's start building this controller; we can implement the controller perform the functionality currently present in the client, and just expose it through an API. I am not sure how to deal with the fact that we won't have the API merged until it merges into o/api, which is not soon. Maybe we can implement the controller over a temporary fork of o/api and rely on manually inserting the CRD into the cluster when we test the functionality? Not sure.
We need to avoid committing to implementation details and investing effort into things that may change though.
Definition of Done
 CVO repository has a new controller (a new cluster-version-operator cobra subcommand sounds like a good option; an alternative would a completely new binary included in CVO image)
CVO repository has a new controller (a new cluster-version-operator cobra subcommand sounds like a good option; an alternative would a completely new binary included in CVO image)- The payload contains manifests (SA, RBAC, Deployment) to deploy the new controller when DevPreviewNoUpgrade feature set is enabled (but not TechPreview)
- The controller uses properly scoped minimal necessary RBAC through a dedicated SA
- The controller will react on ClusterVersion changes in the cluster through an informer
- The controller will maintain a single ClusterVersion status insight as specified by the Update Health API Draft
- The controller does not need to maintain all fields precisely: it can use placeholders or even ignore fields that need more complicated logic over more resources (estimated finish, completion, assessment)
- The controller will publish the serialized CV status insight (in yaml or json) through a ConfigMap (this is a provisionary measure until we can get the necessary API and client-go changes merged) under a key that identifies the kube resource ("cv-version")
- The controller only includes the necessary types code from o/api PR together with the necessary generated code (like deepcopy). These local types will need to be replaced with the types eventually merged into o/api and vendored to o/cluster-version-operator
Testing notes
This card only brings a skeleton of the desired functionality to the DevPreviewNoUpgrade feature set. Its purpose is mainly to enable further development by putting the necessary bits in place so that we can start developing more functionality. There's not much point in automating testing of any of the functionality in this card, but it should be useful to start getting familiar with how the new controller is deployed and what are its concepts.
For seeing the new controller in action:
1. Launch a cluster that includes both the code and manifests. As of Nov 11, #1107 is not yet merged so you need to use launch 4.18,openshift/cluster-version-operator#1107 aws,no-spot
2. Enable the DevPreviewNoUpgrade feature set. CVO will restart and will deploy all functionality gated by this feature set, including the USC. It can take a bit of time, ~10-15m should be enough though.
3. Eventually, you should be able to see the new openshift-update-status-controller Namespace created in the cluster
4. You should be able to see a update-status-controller Deployment in that namespace
5. That Deployment should have one replica running and being ready. It should not crashloop or anything like that. You can inspect its logs for obvious failures and such. At this point, its log should, near its end, say something like "the ConfigMap does not exist so doing nothing"
6. Create the ConfigMap that mimics the future API (make sure to create it in the openshift-update-status-controller namespace): oc create configmap -n openshift-update-status-controller status-api-cm-prototype
7. The controller should immediately-ish insert a usc-cv-version key into the ConfigMap. Its content is a YAML-serialized ClusterVersion status insight (see design doc). As of OTA-1269 the content is not that important, but the (1) reference to the CV (2) versions field should be correct.
8. The status insight should have a condition of Updating type. It should be False at this time (the cluster is not updating).
9. Start upgrading the cluster (it's a cluster bot cluster with ephemeral 4.18 version so you'll need to use --to-image=pullspec and probably force it
10. While updating, you should be able to observe the controller activity in the log (it logs some diffs), but also the content of the status insight in the ConfigMap changing. The versions field should change appropriately (and startedAt too), and the Updating condition should become True.
11. Eventually the update should finish and the Updating condition should flip to False again.
Some of these will turn into automated testcases, but it does not make sense to implement that automation while we're using the ConfigMap instead of the API.
Spun out of https://issues.redhat.com/browse/MCO-668
This aims to capture the work required to rotate the MCS-ignition CA + cert.
Original description copied from MCO-668:
Today in OCP there is a TLS certificate generated by the installer , which is called "root-ca" but is really "the MCS CA".
A key derived from this is injected into the pointer Ignition configuration under the "security.tls.certificateAuthorities" section, and this is how the client verifies it's talking to the expected server.
If this key expires (and by default the CA has a 10 year lifetime), newly scaled up nodes will fail in Ignition (and fail to join the cluster).
The MCO should take over management of this cert, and the corresponding user-data secret field, to implement rotation.
Reading:
- There is a section in the customer facing documentation that touches on this: https://docs.openshift.com/container-platform/4.13/security/certificate_types_descriptions/machine-config-operator-certificates.html
- There's a section in the customer facing documentation for this: https://docs.openshift.com/container-platform/4.13/security/certificate_types_descriptions/machine-config-operator-certificates.html that needs updating for clarification.
- There's a pending PR to openshift/api: https://github.com/openshift/api/pull/1484/files
- Also see old (related) bug: https://issues.redhat.com/browse/OCPBUGS-9890
- This is also separate to https://issues.redhat.com/browse/MCO-499 which describes the management of kubelet certs
The CA/cert generated by the installer is not currently managed and also does not preserve the signing key; so the cert controller we are adding in the MCO(leveraged from library-go), throws away everything and starts fresh. Normally this happens fairly quickly so both the MCS and the -user-data secrets are updated together. However, in certain cases(such as agent based installations) where a bootstrap node joins the cluster late, it will have the old CA from installer, and unfortunately the MCS will have a TLS cert signed by the new CA - resulting in invalid TLS cert errors.
To account for such cases, we have to ensure the first CA embedded in any machine is matching the format expected by the cert controller. To do this, we'll have to do the following in the installer:
Have the bootstrap MCC generate the CA/TLS cert using the cert controller, and populate them into the right places(this card)Make changes in the installer to remove the creation of the CA/cert, since the bootstrap MCC will now handle this(https://issues.redhat.com/browse/MCO-1458)- Template out all root-ca artifacts in the format expected by the library-go cert controller. This would involve adding certain annotations on the artifacts(with respect to validity of the cert and some other ownership metadata)
- The root CA signing key is currently discarded by the installer, so this will have to be a new template in the installer.
The machinesets in the machine-api namespace reference a user-data secret (per pool and can be customized) which stores the initial ignition stub configuration pointing to the MCS, and the TLS cert. This today doesn't get updated after creation.
The MCO now has the ability to manage some fields of the machineset object as part of the managed bootimage work. We should extend that to also sync in the updated user-data secrets for the ignition tls cert.
The MCC should be able to parse both install-time-generated machinesets as well as user-created ones, so as to not break compatibility. One way users are using this today is to use a custom secret + machineset to do non-MCO compatible ignition fields, for example, to partition disks for different device types for nodes in the same pool. Extra care should be taken not to break this use case
Feature Overview (aka. Goal Summary)
As a cluster-admin I can use a single command to see all upgrade checklist before I trigger an update.
Create a Update precheck command that helps customers identify potential issues before triggering an OpenShift cluster upgrade, without blocking the upgrade process. This tool aims to reduce upgrade failures and support tickets by surfacing common issues beforehand.
Goals (aka. expected user outcomes)
- Enable users (especially those with limited OpenShift expertise) to identify potential upgrade issues before starting the upgrade
- Reduce the number of failed upgrades and support tickets
- Provide clear, actionable information about cluster state relevant to upgrades
- Help customers make informed decisions about when to initiate upgrades
Requirements (aka. Acceptance Criteria):
- Check Pod Disruption Budgets (PDBs):
- Identify existing PDBs that might impact the upgrade
- Display information about PDBs in a way that's understandable to users with limited Kubernetes experience
- workaround - Check DVO PDB checks
- Image Registry Access Verification:
- Validate access to required image repositories
- Pre-check ability to pull images needed for the upgrade
- Verify connectivity to public registries or repository of choice
- workaround : Image pinning GA
- Node Health Verification:
- Check for unavailable nodes
- Identify nodes in maintenance mode
- Detect unscheduled nodes
- Verify overall node health status
- Core Platform Component Health:
- Verify health of control plane workloads
- Check core platform operators' health
- Alert Analysis:
- List any active critical alerts
- Display relevant warning alerts
- Focus on alerts that could impact upgrade success
- Version-Specific Checks:
- Include checks specific to the target upgrade version
- Verify requirements for new features or changes between versions
- Check networking-related requirements (e.g., SDN to OVN migrations)
- Output Requirements:
- Provide clear, understandable output for users without deep OpenShift knowledge
- Don't block upgrades even if issues are found
- Present information in an easily digestible format
==============
{}New additions in 2025{}
- MCP status
- Check the maxUnavailable
- Compare maxUnavailable to the request level or current load level (if above request level) and determine if this is the correct setting
- Check to see if the MCPs are paused
- Make a note if etcd is backed up
- Other operators
- Note which operators are set to manual vs automatic update
- Check to determine the next update of all OLM based operators
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Self-managed |
| Classic (standalone cluster) | standalone |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | All |
| Connected / Restricted Network | All |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | All |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
- Blocking upgrade execution
- Checking entire cluster state
- Verifying non-platform workloads
- Automated issue resolution
- Comprehensive cluster health checking
- Extensive operator compatibility verification beyond core platform
- ACM integration
- Although Operations will use ACM for day 2 operations. Customer Engineering will use cli for patching, updating, precheck etc.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
- Target users may have limited Kubernetes/OpenShift expertise
- Many users coming from VMware background
- Customers often don't have TAM or premium support
- Users may not be familiar with platform-specific concepts
- Need to accommodate users who prefer not to read extensive documentation
Documentation Considerations
Add docs for precheck command
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Epic Goal
OCPSTRAT-1834 is requesting an oc precheck command that helps customers identify potential issues before triggering an OpenShift cluster upgrade. For 4.18, we'd built a tech-preview oc adm upgrade recommend (OTA-1270, product docs) that is in this "Anything I should think about before updating my cluster [to 4.y.z]?" space, and this Epic is about extending that subcommand with alerts to deliver the coverage requested by OCPSTRAT-1834.
Why is this important?
We currently document some manual checks for customer admins to run before launching an update. For example, RFE-5104 is up asking to automate whatever we're hoping customer are supposed to look for vs. critical alerts. But updating the production OpenShift Update Service is complicated, and it's easier to play around in a tech-preview oc subcommand, while we get a better idea of what information is helpful, and which presentation approaches are most accessible. 4.18's OTA-902 / cvo#1907 folded the Upgradeable condition in as a client-side Conditional Update risk, and this Epic proposes to continue in that direction by retrieving update-relevant alerts and folding those in as additional client-side Conditional Update risks.
Scenarios
As a cluster administrator interested in launching an OCP update, I want to run an oc command that talks to me about my next-hop options, including any information related to known regressions with those target releases, and also including any information about things I should consider addressing in my current cluster state.
Dependencies
The initial implementation can be delivered unilaterally by the OTA updates team. The implementation may surface ambiguous or hard-to-actuate alert messages, and those messages will need to be improved by the component team responsible for maintaining that alert.
Contributing Teams (and contacts)
- Development - OTA
- Documentation - no docs required
- QE - OTA
- PX - OTA
- Others -
Acceptance Criteria
OCPSTRAT-1834 customer is happy ![]()
Drawbacks or Risk
Client-side Conditional Update risks are helpful for cluster administrators who use that particular client. But admins who use older oc or who are using the in-cluster web-console and similar will not see risks known only to newer oc. If we can clearly tie a particular cluster state to update risk, declaring that risk via the OpenShift Update Service would put the information in front of all cluster administrators, regardless of which update interface they use.
However, trialing update risks client-side in tech-preview oc and then possibly promoting them to risks served by the OpenShift Update Service in the future might help us identify cluster state that's only weakly coupled to update success but still interesting enough to display. Or help us find more accessible ways of displaying that context before putting the message in front of large chunks of the fleet.
Done - Checklist
- CI Testing - Tests are merged and completing successfully
- Documentation - No docs.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Other
oc adm upgrade recommend should retrieve alerts from the cluster (similar to how oc adm upgrade status already does), and inject them as conditional update risks (similar to how OTA-902 / cvo#1907 injected Upgradeable issues). The set of alerts to include is:
- All critical alerts, because that's explicitly selected in OCPSTRAT-1834. This includes ClusterOperatorDown, which overlaps with the existing ClusterVersion Failing condition, but 🤷. It also includes the PodDisruptionBudgetLimit alert which is part of PDB coverage.
- PDB coverage:
- warning PodDisruptionBudgetAtLimit.
- Image registry access:
- warning KubeContainerWaiting.
- Nodes:
- warning KubeNodeNotReady, KubeNodeReadinessFlapping, and KubeNodeUnreachable.
Definition of done / test-plan:
- Find a cluster with both update recommendations and some of the mentioned alerts firing.
- Run OC_ENABLE_CMD_UPGRADE_RECOMMEND=true OC_ENABLE_CMD_UPGRADE_RECOMMEND_PRECHECK=true oc adm upgrade recommend.
- Confirm that the command calls out the expected alerts for all update targets.
Description of problem
The precheck functionality introduced by OTA-1426 flubbed the Route lookup implementation, and crashes with a seg-fault. Thanks to Billy Pearson for reporting.
Version-Release number of selected component
4.19 code behind both the OC_ENABLE_CMD_UPGRADE_RECOMMEND=true and OC_ENABLE_CMD_UPGRADE_RECOMMEND_PRECHECK=true feature gates.
How reproducible
Every time.
Steps to Reproduce
$ export OC_ENABLE_CMD_UPGRADE_RECOMMEND=true # overall 'recommend' command still tech-preview $ export OC_ENABLE_CMD_UPGRADE_RECOMMEND_PRECHECK=true # pre-check functionality even more tech-preview $ ./oc adm upgrade recommend
Actual results
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x3bd3cdd]
goroutine 1 [running]:
github.com/openshift/client-go/route/clientset/versioned/typed/route/v1.NewForConfig(0x24ec35c?)
/go/src/github.com/openshift/oc/vendor/github.com/openshift/client-go/route/clientset/versioned/typed/route/v1/route_client.go:31 +0x1d
github.com/openshift/oc/pkg/cli/admin/upgrade/recommend.(*options).alerts(0xc000663130, {0x5ed4828, 0x8350a80})
/go/src/github.com/openshift/oc/pkg/cli/admin/upgrade/recommend/alerts.go:34 +0x170
github.com/openshift/oc/pkg/cli/admin/upgrade/recommend.(*options).precheck(0x0?, {0x5ed4828, 0x8350a80})
...
Expected results
Successful precheck execution and reporting.
Feature Overview
Console enhancements based on customer RFEs that improve customer user experience.
Goals
- This Section:* Provide high-level goal statement, providing user context and expected user outcome(s) for this feature
- …
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Introduce a "Created Time" column to the Job listing in the OpenShift Container Platform (OCP) console to enhance the ability to sort jobs by their creation date. This feature will help users efficiently manage and navigate through numerous jobs, particularly in environments with frequent CronJob executions and a high volume of job runs.
Acceptance Criteria:
- Add a "Created Time" column to the Job listing in the OCP console.
- Display the creation timestamp in a format consistent with the console's date and time standards.
- Enable sorting of jobs by the "Created Time" column.
Feature Overview (aka. Goal Summary)
We need to maintain our dependencies across all the libraries we use in order to stay in compliance.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
<your text here>
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
<enter general Feature acceptance here>
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
An epic we can duplicate for each release to ensure we have a place to catch things we ought to be doing regularly but can tend to fall by the wayside.
Inconsistency in the loader/spinner/dots component used throughout the unified console. The dots animation is used widely through the spoke clusters, but it is not a Patternfly component(This component was originally inhereted from CoreOS console). Spoke clusters also uses skeleton states on certain pages, which is a Patternfly component. Hub uses a mix of dots animation first for half a second, and then spinners and skeletons.
Currently there is a discussion with PF to update with clearer guidelines. According to the current PF guidelines, we should be using the large spinner if we cannot anticipate the data being loaded, and the skeleton state if we do know. Link to doc
Currently console is using TypeScript 4, which is preventing us from upgrading to NodeJS-22. Due to that we need to update TypeScript 5 (not necessarily latest version).
AC:
- Update TypeScript to version 5
- Update ES build target to ES-2021
Note: In case of higher complexity we should be splitting the story into multiple stories, per console package.
Part of lifting feature gate for the CSP API we need to enable e2e CSP tests for console-operator.
In Console 4.18 we introduced an initial Content Security Policy (CSP) implementation (CONSOLE-4263).
This affects both Console web application as well as any dynamic plugins loaded by Console. In production, CSP violations are sent to telemetry service for analysis (CONSOLE-4272).
We need a reliable way to detect new CSP violations as part of our automated CI checks. We can start with testing the main dashboard page of Console and expand to more pages as necessary.
Acceptance criteria:
- Console project provides a script to test for CSP violations.
- CSP violation test script does not report any errors for Console.
As a developer I want to make sure we are running the latest version of webpack in order to take advantage of the latest benefits and also keep current so that future updating is a painless as possible.
We are currently on v4.47.0.
Changelog: https://webpack.js.org/blog/2020-10-10-webpack-5-release/
By updating to version 5 we will need to update following pkgs as well:
- html-webpack-plugin
- webpack-bundle-analyzer
- copy-webpack-plugin
- fork-ts-checker-webpack-plugin
AC: Update webpack to version 5 and determine what should be the ideal minor version.
Epic Goal
- Migrate all components to functional components
- Remove all HOC patterns
- Break the file down into smaller files
- Improve type definitions
- Improve naming for better self-documentation
- Address any React anti-patterns like nested components, or mirroring props in state.
- Address issues with handling binary data
- Add unit tests to these components
Acceptance Criteria
- Refactor secret forms
- Adding unit tests to these components.
- Fix https://issues.redhat.com/browse/OCPBUGS-32401
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
The GenericSecretForm component needs to be refactored to address several tech debt issues: * Rename to OpaqueSecretForm
- Refactor into a function component
- Remove i18n withTranslation HOC pattern
- Improve type definitions
The KeyValueEntryForm component needs to be refactored to address several tech debt issues: * Rename to OpaqueSecretFormEntry
- Refactor into a function component
- Remove i18n withTranslation HOC pattern
- Improve type definitions
The BasicAuthSubform component needs to be refactored to address several tech debt issues: * Rename to BasicAuthSecretForm
- Refactor into a function component
- Remove i18n withTranslation HOC pattern
- Improve type definitions
The SourceSecretForm component needs to be refactored to address several tech debt issues: * Rename to AuthSecretForm
- Refactor into a function component
- Remove i18n withTranslation HOC pattern
- Improve type definitions
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
Provide quality user experience for customers connecting their Pods and VMs to the underlying physical network through OVN Kubernetes localnet.
Why is this important?
This is a continuation to https://issues.redhat.com/browse/SDN-5313.
It covers the UDN API for localnet and other improvements
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
- Priority+ is set by engineering
- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- This must be done downstream too
- Release Technical Enablement - Provide necessary release enablement
details and documents. - OVN Kubernetes secondary networks with the localnet topology can be created through ClusterUserDefinedNetworks
- When possible, user input is validated and any configuration issue is shown on the UDN. Alternatively some issues can be shown on CNI ADD events on Pod
- Definition of these networks can be changed even if there are Pods connected to them. When that happens, the UDN is marked as degraded until all the "old" pods are gone. The mutable fields should be: MTU, VLAN, physnet name
- A single "bridge-mappings" "localnet" can be referenced from multiple different UDNs
- The default MTU set for localnet is 1500
- Pod requesting UDN without a VLAN is able to connect to services running on the host's network
- (
stretch) The "physnet" mapping is a "supported API" and available to users - so they can connect to the machine network without a need to configure a custom bridge-mappingwe should just always request user to configure the mapping themselves, until we understand all the implications of non-NORMAL mode on br-ex and how it works with local access / bondings / ... - (stretch) Scheduling is managed by the platform - if a UDN requests a localnet (as in bridge-mappins.localnet), the Pod requesting this UDN will be only scheduled on a node with this resource available. This can use the same mechanism as the SR-IOV operator - combination of device plugins and "k8s.v1.cni.cncf.io/resourceName" annotation
...
IPAM is not in the scope of this epic. See RFE-6947.
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
In order for Managed OpenShift Hosted Control Planes to run as part of the Azure Redhat OpenShift, it is necessary to support the new AKS design for secrets/identities.
Goals (aka. expected user outcomes)
Hosted Cluster components use the secrets/identities provided/referenced in the Hosted Cluster resources creation.
Requirements (aka. Acceptance Criteria):
All OpenShift Hosted Cluster components running with the appropriate managed or workload identity.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Managed |
| Classic (standalone cluster) | No |
| Hosted control planes | Yes |
| Multi node, Compact (three node), or Single node (SNO), or all | All supported ARO/HCP topologies |
| Connected / Restricted Network | All supported ARO/HCP topologies |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | All supported ARO/HCP topologies |
| Operator compatibility | All core operators |
| Backport needed (list applicable versions) | OCP 4.18.z |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | No |
| Other (please specify) |
Background
This is a follow-up to OCPSTRAT-979 required by an AKS sweeping change to how identities need to be handled.
Documentation Considerations
Should only affect ARO/HCP documentation rather than Hosted Control Planes documentation.
Interoperability Considerations
Does not affect ROSA or any of the supported self-managed Hosted Control Planes platforms
Goal
- The goal for this epic is for every upstream project ARO HCP uses, that needs to authenticate with Azure Cloud, supports adding authenticating with NewUserAssignedIdentityCredential.
- i.e., https://github.com/Azure/azure-sdk-for-go/blob/b1480a29448972f6cc81221af685ff9011e9e0b9/sdk/azcore/cloud/cloud.go#L41
- // opts.Cloud.ActiveDirectoryAuthorityHost
- This includes the following upstream projects:
- CAPZ
- ASO
- Cloud Provider
- Azure Disk CSI Driver
- Azure File CSI Driver
Scenarios
- CAPZ supports authenticating with NewUserAssignedIdentityCredential.
- ASO supports authenticating with NewUserAssignedIdentityCredential.
- Cloud Provider supports authenticating with NewUserAssignedIdentityCredential.
- Azure Disk CSI Driver supports authenticating with NewUserAssignedIdentityCredential.
- Azure File CSI Driver supports authenticating with NewUserAssignedIdentityCredential.
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- External - dependent on upstream communities accepting the changes needed to support authenticating with NewUserAssignedIdentityCredential.
- External - dependent on Microsoft having the SDK ready prior to HyperShift's work on this epic.
Previous Work (Optional):
- …
Open questions:
- This information is retrieved from a 1P Microsoft application; to my knowledge, there is no way for HyperShift to test this in our current environments?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As an ARO HCP user, I want to be able to:
- authenticate with NewUserAssignedIdentityCredential for Cloud Provider
so that I can
- be compliant with Microsoft security standards when using managed identities to authenticate with.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Updated upstream code in Cloud Provider to support authenticating with NewUserAssignedIdentityCredential
- Pull the upstream Cloud Provider PR into OpenShift's Cloud Provider once the Cloud Provider PR is merged
Out of Scope:
N/A
Engineering Details:
- N/A
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
User Story:
As an ARO HCP user, I want to be able to:
- authenticate with NestedCredentialsObject for CAPZ
so that I can
- be compliant with Microsoft security standards when using managed identities to authenticate with.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Updated upstream code in CAPZ to support authenticating with NestedCredentialsObject
- Pull the upstream CAPZ PR into OpenShift's CAPZ once the CAPZ PR is merged
Out of Scope:
N/A
Engineering Details:
- Previous client certificate work on CAPZ from the HyperShift team - https://github.com/kubernetes-sigs/cluster-api-provider-azure/pull/5200
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
Goal
- Today the current, the current HyperShift Azure API for Control Plane Managed Identities (MI) stores the client ID and its certificate name for each MI. The goal for this epic is to modify this API to instead allow a NestedCredentialsObject to be stored for each Control Plane MI.
- In ARO HCP, CS will store the NestedCredentialsObject for each Control Plane MI, in its JSON format, in Azure Key Vault under a secret name for each MI. The secret name for a Control Plane MI will be provided to the HyperShift Azure API (i.e. HostedCluster). The control plane operator will read and parse the ClientID ClientSecret, AuthenticationEndpoint, and TenantID for each Control Plane MI and either pass or use this data to use ClientCertificate authentication for each Control Plane component that needs to authenticate with Azure Cloud.
Why is this important?
- As part of the msi-dataplane repository walk-through, a gap in the way ARO HCP is approaching authentication as managed identities for control plane components was found. The gap was that we're not overriding the ActiveDirectoryAuthorityHost as requested by the MSI team when authenticating as a managed identity. This prompted a wider discussion with HyperShift which led to the proposal here and allowing HyperShift to use the full nested credentials objects and leverage the fields they need within the struct.
Scenarios
- The HyperShift Azure API supports only a secret name for each Control Plane MI (instead of a client ID and certificate name today).
- The Control Plane Operator, using the SecretsStore CSI Driver, will retrieve the NestedCredentialsObject from Azure Key Vault and mount it to a volume in any pod needing to authenticate with Azure Cloud.
- The Control Plane Operator, through possibly a parsing function from the library-go or msi-dataplane repo, will parse the ClientID ClientSecret, AuthenticationEndpoint, and TenantID from the NestedCredentialsObject and either use or pass this data along to authenticate with ClientCertificate. This will be done for each control plane component needing to authenticate to Azure Cloud.
- Remove the filewatcher functionality from HyperShift and in OpenShift repos (CIO, CIRO, CNO/CNCC)
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- External - dependent on upstream communities accepting the changes needed to support ActiveDirectoryAuthorityHost in ClientCertificateCredentialOptions.
- External - dependent on Microsoft having the SDK ready prior to HyperShift's work on this epic.
Previous Work (Optional):
- Previous Microsoft work:
Open questions:
- This information is retrieved from a 1P Microsoft application; to my knowledge, there is no way for HyperShift to test this in our current environments?
- Can HyperShift get a mock/real example of the JSON structure that would be stored in the Key Vault? (to be used in development, unit testing since we cannot retrieve a real version of this in our current test environments).
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
As an ARO HCP user, I want to be able to:
- have the Secret Store CSI driver retrieve the NestedCredentialsObject from an Azure Key Vault based on the control plane component's secret name in the HyperShift Azure API for these control plane components: CAPZ, Cloud Provider, KMS, and CPO.
- the corresponding HCP pod needing to authenticate with Azure cloud reads the ClientID ,ClientSecret, AuthenticationEndpoint, and TenantID from the NestedCredentialsObject and uses the data to authenticate with Azure Cloud
so that
- the NestedCredentialsObject is mounted in a volume in the pod needing to authenticate with Azure Cloud
- the ClientCertificate authentication is using the right fields needed for managed identities in ARO HCP.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Update all the SecretProviderClasses to pull from the new HyperShift Azure API field holding the secret name
- Update each HyperShift HCP component to use UserAssignedIdentityCredentials
- Remove the filewatcher functionality from HyperShift
Out of Scope:
Updating any external OpenShift components that run in the HCP
Engineering Details:
- This should be CAPZ, CPO, and Cloud Provider.
- Additional details on why we are doing this are located here - https://docs.google.com/document/d/1tX2avo8ORyjqL4GJNwxq-wQTM3-LC7zBTP5V9EgwU74/edit?tab=t.0.
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
As an ARO HCP user, I want to be able to:
- have the Secret Store CSI driver retrieve the UserAssignedIdentityCredentials from an Azure Key Vault based on the control plane component's secret name in the HyperShift Azure API for these control plane components: CNO, CIRO, CSO, and CIO.
- the corresponding HCP pod needing to authenticate with Azure cloud can read the file path to the UserAssignedIdentityCredentials object and uses the data to authenticate with Azure Cloud
so that
- the UserAssignedIdentityCredentials is mounted in a volume in the pod needing to authenticate with Azure Cloud
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Update all the SecretProviderClasses to pull from the new HyperShift Azure API field holding the secret name
- Update each HyperShift HCP component to use UserAssignedIdentityCredentials
- Remove the filewatcher functionality from OpenShift repos (CIO, CIRO, CNO/CNCC)
Out of Scope:
Updating any HyperShift-only components that run in the HCP
Engineering Details:
- This should be CNO, CIRO, CSO, and CIO.
- Additional details on why we are doing this are located here - https://docs.google.com/document/d/1tX2avo8ORyjqL4GJNwxq-wQTM3-LC7zBTP5V9EgwU74/edit?tab=t.0.
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
- https://github.com/openshift/cloud-network-config-controller/pull/161
- https://github.com/openshift/cluster-image-registry-operator/pull/1187
- https://github.com/openshift/cluster-image-registry-operator/pull/1186
- https://github.com/openshift/cluster-image-registry-operator/pull/1174
- https://github.com/openshift/cluster-network-operator/pull/2647
- https://github.com/openshift/hypershift/pull/5703
- https://github.com/openshift/hypershift/pull/5655
- https://github.com/openshift/hypershift/pull/5621
User Story:
As an ARO HCP user, I want to be able to:
- add the secret name for each control plane managed identity in the HyperShift Azure API
so that I can
- provide the secret name to the Secrets CSI driver.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Deprecate storing client ID and certificate name for each control plane managed identity in the HyperShift Azure API
- Make the client ID and certificate name for each control plane managed identity in the HyperShift Azure API optionally instead of required
- Add the capability to store the secret name for each control plane managed identity in the HyperShift Azure API; this functionality should be behind the tech preview flag
Out of Scope:
Removing the deprecated client ID and certificate name fields. This should be done at a later date when CS only supports the new API
Engineering Details:
- Additional details on why we are doing this are located here - https://docs.google.com/document/d/1tX2avo8ORyjqL4GJNwxq-wQTM3-LC7zBTP5V9EgwU74/edit?tab=t.0.
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This requires a feature gate.
This requires a feature gate.
Summary
The installation process for the OpenShift Virtualization Engine (OVE) has been identified as a critical area for improvement to address customer concerns regarding its complexity compared to competitors like VMware, Nutanix, and Proxmox. Customers often struggle with disconnected environments, operator configuration, and managing external dependencies, making the initial deployment challenging and time-consuming.
To resolve these issues, the goal is to deliver a streamlined, opinionated installation workflow that leverages existing tools like the Agent-Based Installer, the Assisted Installer, and the OpenShift Appliance (all sharing the same underlying technology) while pre-configuring essential operators and minimizing dependencies, especially the need for an image registry before installation.
By focusing on enterprise customers, particularly VMware administrators working in isolated networks, this effort aims to provide a user-friendly, UI-based installation experience that simplifies cluster setup and ensures quick time-to-value.
Objectives and Goals
Primary Objectives
- Simplify the OpenShift Virtualization installation process to reduce complexity for enterprise customers coming from VMware vSphere.
- Enable installation in disconnected environments with minimal prerequisites.
- Eliminate the dependency on a pre-existing image registry in disconnected installations.
- Provide a user-friendly, UI-driven installation experience for users used to VMware vSphere.
Goals
- Deliver an installation experience leveraging existing tools like the Agent-Based Installer, Assisted Installer, and OpenShift Appliance, i.e. the Assisted Service.
- Pre-configure essential operators for OVE and minimize external day 1 dependencies (see OCPSTRAT-1811 "Agent Installer interface to install Operators")
- Ensure successful installation in disconnected environments with standalone OpenShift, with minimal requirements and no pre-existing registry
Personas
Primary Audience
VMware administrators transitioning to OpenShift Virtualization in isolated/disconnected environments.
Pain Points
- Lack of UI-driven workflows; writing YAML files is a barrier for the target user (virtualization platforms admins)
- Complex setup requirements (e.g., image registries in disconnected environments).
- Difficulty in configuring network settings interactively.
- Lack of understanding when to use a specific installation method
- Hard time finding the relevant installation method (docs or at console.redhat.com)
Technical Requirements
Image Registry Simplification
- Eliminate the dependency on an existing external image registry for disconnected environments.
- Support a workflow similar to the OpenShift Appliance model, where users can deploy a cluster without external dependencies.
Agent-Based Installer Enhancements
- Extend the existing UI to capture all essential data points (e.g., cluster details, network settings, storage configuration) without requiring YAML files.
- Install without a pre-existing registry in disconnected environment
- Install required operators for virtualization
- OpenShift Virtualization Reference Implementation Guide v1.0.2
- List of Operators:
- OpenShift Virtualization Operator
- Machine and Node Configuration
- Machine Config Operator
-
- Node Health Check Operator
- Fence Agents Remediation Operator
- Additional Operators
- Node Maintenance Operator
- OpenShift Logging
- MetalLB
- Migration Toolkit for Virtualization
- Migration Toolkit for Containers
- Compliance Operator
- Kube Descheduler Operator
- NUMA Resources Operator
- Ansible Automation Platform Operator
- Network
- NMState Operator
- Node Failure
- Self Node Remediation Operator
- Disaster Discovery
- OADP
- ODF
- Note: we need each operator owner to enable the operator to allow its installation via the installer. We won't block the release due to not having the full list of operators included and they'll be added as required and prioritized with each team.
User experience requirements
The first area of focus is a disconnected environment. We target these environments with the Agent-Based Installer.
The current docs for installing on disconnected environment are very long and hard to follow.
Installation without pre-existing Image Registry
The image registry is required in disconnected installations before the installation process can start. We must simplify this point so that users can start the installation with one image, without having to explicitly install one.
This isn't a new requirement and in the past we've analyzed options for this and even did a POC, we could revisit this point, see Deploy OpenShift without external registry in disconnected environments.
The OpenShift Appliance can in fact be installed without a registry.
Additionally, we started work in this direction AGENT-262 (Strategy to complete installations where there isn't a pre-existing registry).
We also had the field (Brandon Jozsa![]() ) doing a POC which was promising:
) doing a POC which was promising:
https://gist.github.com/v1k0d3n/cbadfb78d45498b79428f5632853112a
User Interface (no configuration files)
The type of users coming from VMware vSphere expect a UI. They aren't used to writing YAML files and this has been identified as a blocker for some of them. We must provide a simple UI to stand up a cluster.
Proposed Workflow
Simplified Disconnected Installation:
This document written by Zane Bitter![]() as the Staff Engineer of this area contains an interactive workflow proposal.
as the Staff Engineer of this area contains an interactive workflow proposal.
This is the workflow proposed in the above document.
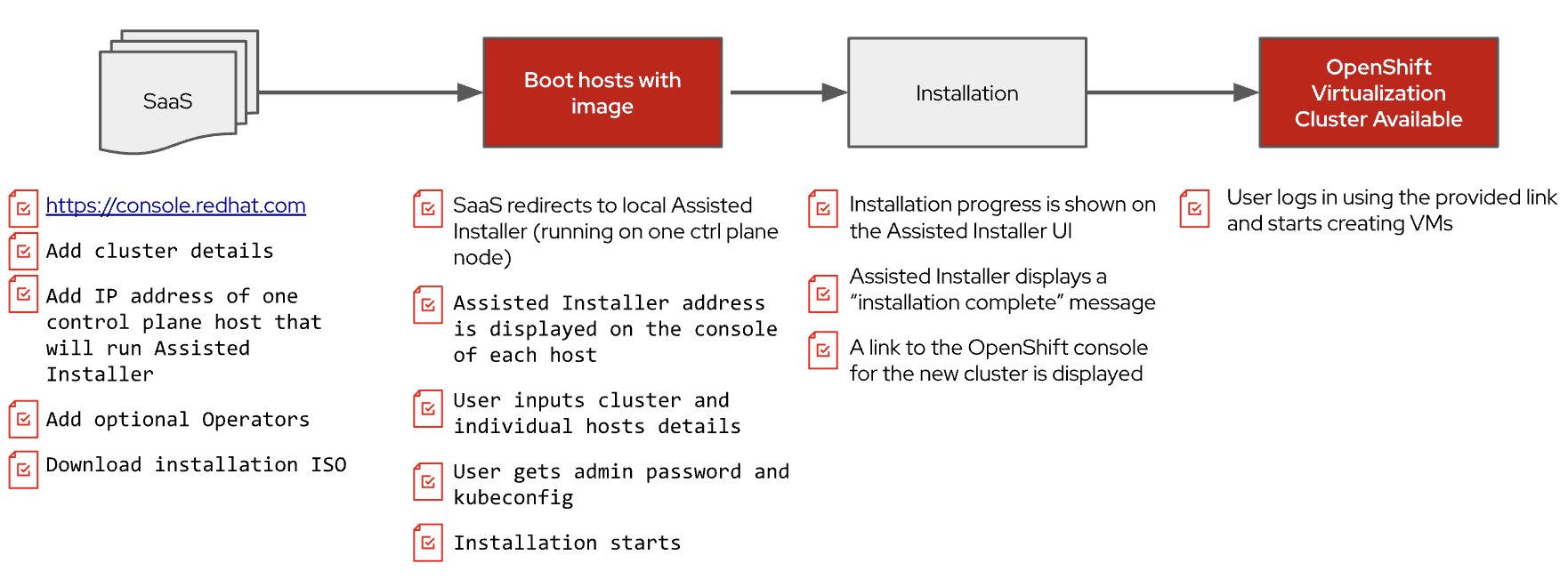
PRD and notes from regular meetings
Epic Goal
- Setup a workflow to generate an ISO that will contain all the relevant pieces to install an OVE cluster
Why is this important?
- As per OCPSTRAT-1874, the user must be able to install into a disconnected environment an OVE cluster, with the help of a UI, and without requiring explicitly to setup an external registry
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Previous work:
Dependencies (internal and external)
- ...
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This sub-command will be used to generate the ignition file based on the interactive disconnected workflow.
This command will be invoked by the builder script (currently within the appliance tool) for supporting generating the ISO.
It will also consume, in future, the eventual (portion of) install configuration that the user will provide via the connected UI (above the sea level)
Description (2/20/25):
Create a script in agent-installer-utils/tools/ove-builder to build a live ISO using the appliance. The script will:
1. Checkout the appliance code.
2. Generate appliance-config.yaml.
3. Build the live ISO with the command:
sudo podman run --rm -it --pull newer --privileged --net=host -v $APPLIANCE_ASSETS:/assets:Z $APPLIANCE_IMAGE build live-iso
4. Take the pull secret as input
5. Unpack the ISO, embed TUI and Web UI components
6. Repack the ISO.
Refer to Appliance PR #335 for how release images are added in
Acceptance Criteria:
- The script takes version, arch, pull secret as mandatory inputs, generates appliance-config.yaml
- The script also successfully generates appliance ISO.
Agent TUI is a part of this ISOAssisted web UI is a part of this ISO. Stretch goal
----------------------------------------
Original description:
Deploy a script (in dev-scripts) that will take as input a release image version.
The script should perform the following tasks (possibly within a container):
- Extract the release installer (via oc extract)
- Generate the unconfigured ignition (via the openshift-install agent create unconfigured-ignition)
- Download the release ISO
- Embed the generated ignition in the ISO
This will be used as a starting point for generating the image that the user will download to install the OVE cluster, and subsequently could be expanded with the additional images required (for example, the UI)
Notes:
- we should also find a way to embed the agent TUI
- not required to address disconnected registry right now
The ove builder script should include all the necessary agent TUI artifacts within the generated ISO
Epic Goal
- Allow the user to select a host to be Node 0 interactively after the booting the ISO. On each host the user would be presented with a choice between two options:
- Select this host as the rendezvous host (it will become part of the control plane)
- The IP address of the rendezvous host is: [Enter IP]
(If the former option is selected, the IP address should be displayed so that it can be entered in the other hosts.)
Why is this important?
- Currently, when using DHCP the user must determine which IP address is assigned to at least one of the hosts prior to generating the ISO. (OpenShift requires infinite DHCP leases anyway, so no extra configuration is required but it does mean trying to manually match data with an external system.)
AGENT-385would extend a similar problem to static IPs that the user is planning to configure interactively, since in that case we won't have the network config to infer them from. We should permit the user to delay collecting this information until after the hosts are booted and we can discover it for them.
Scenarios
- In a DHCP network, the user creates the agent ISO without knowing which IP addresses are assigned to the hosts, then selects one to act as the rendezvous host after booting.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As an admin, I want to be able to:
- Have an interactive generic installation image that I can use for all nodes. Since it is a single image for all the nodes, I need to be able to select on boot whether the node is node0 (and future master) or a regular node.
- Have the TUI checks take into account whether the node is node0 or not to perform additional checks (like connectivity check to the rendenzvous IP)
so that I can achieve
- Interactive installation with a single image
Acceptance Criteria:
Description of criteria:
- A dialog is presented on boot asking whether this node should be the one that controls the installation (node0)
- On regular nodes additional connectivity checks are performed towards rendezvous IP
- TUI writes Node0 configuration so the blocked node0 services can proceed (after network configuration and registry checks)
Engineering Details:
- There is a PoC of this dialog in https://github.com/openshift-agent-team/tui
- Final dialog in use with ABI: https://github.com/openshift/agent-installer-utils/
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
Goal
Remove all persistent volumes and claims. Also check if there are any CNS volumes that could be removed but the pv/pvc deletion should check for that.
Why is this important?
When an OpenShift cluster on vSphere with CSI volumes is destroyed the volumes are not deleted, leaving behind multiple objects within vSphere. This leads to storage usage by orphan volumes that must be manually deleted.
Multiple customers have requested this feature and we need this feature for CI. PV(s) are not cleaned up and leave behind CNS orphaned volumes that cannot be removed.
Epic Goal
The goal of this epic is upon destroy to remove all persistent volumes and claims. Also check if there are any CNS volumes that could be removed but the pv/pvc deletion should check for that.
Why is this important?
- Multiple customers have requested this feature and we need this feature for CI. PV(s) are not cleaned up and leave behind CNS orphaned volumes that cannot be removed.
As a openshift engineer I want the installer to make sure there are no CNS volumes so we are not leaking volumes that could be taking disk space or alerting in vCenter.
acceptance criteria
- check if there are cns volumes, check if there are still pv from previous delete. If there are still CNS volumes and no PV(s) try to delete, if unsuccessful just return list
- are you sure warning
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Some Kubernetes clusters do not have direct Internet access and rely solely on proxies for communication, so OLM v1 needs to support proxies to enable this communication.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
Some Kubernetes clusters do not have direct Internet access and rely solely on proxies for communication. This may be done for isolation, testing or to enhance security and minimise vulnerabilities. This is a fully supported configuration in OpenShift, with origin tests designed to validate functionality in proxy-based environments. Supporting proxies is essential to ensure your solution operates reliably within these secure and compliant setups.
To address this need, we have two key challenges to solve:
- Enable catalogd and the operator-controller to work with OpenShift proxy configurations.
- Implement a solution to pass the proxy configuration for the solutions managed by OLM so that they work well with the proxy.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
- Enable catalogd and the operator-controller to work with OpenShift proxy configurations.
- Implement a solution to pass the proxy configuration for the solutions managed by OLM so that they work well with the proxy.
- Trusted CA support
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | Restricted Network |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | 4.18 |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
- Proxy support for operator-controller when communicating with catalogd.
- Adding code to support proxies upstream (the environment variable mechanism can be used).
- Support for CSV-defined proxies.
- oc-mirror support (which should already be there)
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
OpenShift’s centralized proxy control via the proxies.config.openshift.io (a.k.a. proxy.config.openshift.io) resource makes managing proxies across a cluster easier. At the same time, vanilla Kubernetes requires a manual and decentralized proxy configuration, making it more complex to manage, especially in large clusters. There is no native Kubernetes solution that can adequately address the need for centralized proxy management.
Kubernetes lacks a built-in unified API like OpenShift’s proxies.config.openshift.io, which can streamline proxy configuration and management across any Kubernetes vendor. Consequently, Kubernetes requires more manual work to ensure the proxy configuration is consistent across the cluster, and this complexity increases with the scale of the environment. As such, vanilla Kubernetes does not provide a solution that can natively address proxy configuration across all clusters and vendors without relying on external tools or complex manual processes (such as that devised by OpenShift).
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Support OpenShift Cluster Proxy
See RFC for more details
Why is this important?
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
It looks like OLMv1 doesn't handle proxies correctly, aws-ovn-proxy job is permafailing https://prow.ci.openshift.org/view/gs/test-platform-results/logs/periodic-ci-openshift-release-master-nightly-4.19-e2e-aws-ovn-proxy/1861444783696777216
I suspect it's on the OLM operator side, are you looking at the cluster-wide proxy object and wiring it into your containers if set?
Feature Overview (aka. Goal Summary)
Once CCM was moved out-of-tree for Azure the 'azurerm_user_assigned_identity' resource the Installer creates is not required anymore. To make sure the Installer only creates the minimum permissions required to deploy OpenShift on Azure this resource created at install time needs to be removed
Goals (aka. expected user outcomes)
The installer doesn't create the 'azurerm_user_assigned_identity' resource anymore that is no longer required for the Nodes
**
Requirements (aka. Acceptance Criteria)
The Installer only creates the minimum permissions required to deploy OpenShift on Azure
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Background
Once CCM was moved out-of-tree this permission is not required anymore. We are implementing this change into 4.19 and backported to 4.18.z
At the same time, for customers running previous OpenShift releases, we will test upgrades between EUS releases (4.14.z - 4.16.z - 4.18.z) when `azurerm_user_assigned_identity` resource is removed previously to ensure the upgrade process is working with no issues and OpenShift is not reporting any issues because of this change
Customer Considerations
A KCS will be created for customers running previous OpenShift releases who want to remove this resource
Documentation Considerations
The new permissions requirements will be documented
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Remove automatic (opinionated) creation (and attachment) of identities to Azure nodes
- Allow API to configure identities for nodes
Why is this important?
- Creating and attaching identities to nodes requires elevated permissions
- The identities are no longer required (or used) so we can reduce the required permissions
Scenarios
- Users want to do a default ipi install that just works without the User Access Admin role
- Users want to BYO user-assigned identity (requires some permissions)
- Users want to use a system assigned identity
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
Volume Group Snapshots is a key new Kubernetes storage feature that allows multiple PVs to be grouped together and snapshotted at the same time. This enables customers to takes consistent snapshots of applications that span across multiple PVs.
This is also a key requirement for backup and DR solutions.
https://kubernetes.io/blog/2023/05/08/kubernetes-1-27-volume-group-snapshot-alpha/
https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/3476-volume-group-snapshot
Goals (aka. expected user outcomes)
Productise the volume group snapshots feature as GA, have docs updated, testing as well as removing feature gate to enable it by default.
Requirements (aka. Acceptance Criteria):
Tests and CI must pass. We should identify all OCP shipped CSI drivers that support this feature and configure them accordingly.
Use Cases (Optional):
- As a storage vendor I want my customers to benefit from the VolumeGroupSnapshot feature included in my CSI driver.
- As a backup/DR software vendor I want to use the VolumeGroupSnapshot feature.
- As a customer I want access to use VolumeGroupSnapshot feature in order to take consistent snapshots of my workloads that are relying on multiple PVs or use a backup/DR solution that leverages VolumeGroupSnapshot
Out of Scope
CSI drivers development/support for this feature.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
This allows backup vendors to implemented advanced feature by taking snapshots of multiple volumes at the same time a common use case in virtualisation.
Customer Considerations
Drivers must support this feature and enable it. Partners may need to change their operator and/or doc to support it.
Documentation Considerations
We already have TP doc content. Update the OCP driver's table to include this capability. Check if any new driver supports it beyond ODF
Interoperability Considerations
Can be leveraged by ODF and OCP virt, especially around backup and DR scenarios.
Epic Goal
Support upstream feature "VolumeGroupSnapshot"" in OCP as Beta GA, i.e. test it and have docs for it.
Why is this important?
- We get this upstream feature through Kubernetes rebase. We should ensure it works well in OCP and we have docs for it.
Upstream links
- Enhancement issue: https://github.com/kubernetes/enhancements/issues/3476
- KEP: https://github.com/kubernetes/enhancements/pull/1551
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- External: the feature is currently scheduled for GA in Kubernetes 1.32, i.e. OCP 4.19.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
We need to make sure that we have e2e tests in Openshift that exercise this feature.
Feature Overview (aka. Goal Summary)
Enable OpenShift to be deployed on Confidential VMs on GCP using AMD SEV-SNP technology
Goals (aka. expected user outcomes)
Users deploying OpenShift on GCP can choose to deploy Confidential VMs using AMD SEV-SNP technology to rely on confidential computing to secure the data in use
Requirements (aka. Acceptance Criteria):
As a user, I can choose OpenShift Nodes to be deployed with the Confidential VM capability on GCP using AMD SEV-SNP technology at install time
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Background
This is a piece of a higher-level effort to secure data in use with OpenShift on every platform
Documentation Considerations
Documentation on how to use this new option must be added as usual
Epic Goal
- Add support to deploy Confidential VMs on GCP using AMD SEV-SNP technology
Why is this important?
- As part of the Zero Trust initiative we want to enable OpenShift to support data in use protection using confidential computing technologies
Scenarios
- As a user I want all my OpenShift Nodes to be deployed as Confidential VMs on Google Cloud using SEV-SNP technology
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Previous Work (Optional):
- We enabled Confidential VMs for GCP using SEV technology already -
OCPSTRAT-690
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
OCP 4 clusters still maintain pinned boot images. We have numerous clusters installed that have boot media pinned to first boot images as early as 4.1. In the future these boot images may not be certified by the OEM and may fail to boot on updated datacenter or cloud hardware platforms. These "pinned" boot images should be updateable so that customers can avoid this problem and better still scale out nodes with boot media that matches the running cluster version.
In phase 1 provided tech preview for GCP.
In phase 2, GCP support goes to GA and AWS goes to TP.
In phase 3, AWS support goes to GA .
In phase 4, vsphere opt-in goes to TP and GCP goes to opt-out.
Requirements
This epic will encompass work required to switch boot image updates on GCP to be opt-out.
The origin tests should be:
- updated to use the new API from https://github.com/openshift/api/pull/2223
- disable the ownerref test as we no longer plan to degrade in that manner in the default-on behavior
This should land before MCO-1584 lands.
Based on discussion on the enhancement, we have decided that we'd like to add an explicit opt-out option and a status field for the ManagedBootImages knob in the MachineConfiguration object.
More context here:
https://github.com/openshift/enhancements/pull/1761#discussion_r1987873170
The boot image controller should should ensure `-user-data` stub secrets are at least spec 3. This requires the cert management work to land first.
To ensure maximum coverage and minimum risk, we will only attempt to upgrade stub secrets that are currently spec 2. While we could potentially upgrade all stubs to the newest(which at the moment is 3.4.0) supported by the MCO, this may cause issues like https://issues.redhat.com/browse/MCO-1589 for some boot images that only support early spec 3 ignition(certain older boot images can't do can only do 3.0.0 and 3.1.0 ignition). Newer boot images can support all spec 3 stubs, so to preserve scaling ability as much as we can, we'll leave spec 3 stubs as is for the moment.
Feature Overview (aka. Goal Summary)
As a cluster administrator, I want to use Karpenter on an OpenShift cluster running in AWS to scale nodes instead of Cluster Autoscalar(CAS). I want to automatically manage heterogeneous compute resources in my OpenShift cluster without the additional manual task of managing node pools. Additional features I want are:
- Reducing cloud costs through instance selection and scaling/descaling
- Support GPUs, spot instances, mixed compute types and other compute types.
- Automatic node lifecycle management and upgrades
This feature covers the work done to integrate upstream Karpenter 1.x with ROSA HCP. This eliminates the need for manual node pool management while ensuring cost-effective compute selection for workloads. Red Hat manages the node lifecycle and upgrades.
The goal is roll this out with ROSA-HCP (AWS) since it has more mature Karpenter ecosystem, followed by ARO-HCP (Azure) implementation (refer to OCPSTRAT-1498).
This feature will be delivered in 3 Phases:
- Dev Preview: Autonode with HCP (OCPSTRAT-943) – targeting OCP 4.19
- Preview (Tech Preview): Autonode for ROSA-HCP (OCPSTRAT-1946) - TBD (2025)
- GA: Autonode for ROSA-HCP – TBD (2025)
The Dev Preview release will expose AutoNode capabilities on Hosted Control Planes for AWS (note this is not meant to be productized on self-managed OpenShift). It includes the following capabilities:
- Service Consumer opts-in to AutoNode on Day 1 and Day 2
- Service Provider lifecycles Karpenter management side
- Cluster Admin gains access to Karpenter CRDs and default nodeClass
- Cluster Admin creates a NodePool and scale out workloads
- Service Consumer signals cluster control plane upgrade
- Expose Karpenter metrics to Cluster Admin
Goals (aka. expected user outcomes)
- Run Karpenter in management cluster and disable CAS
- Automate node provisioning in workload cluster
- automate lifecycle management in workload cluster
- Reduce cost in heterogenous compute workloads
- Additional features karpenter
OpenShift AutoNode (a.k.a. Karpenter) Proposal
Requirements (aka. Acceptance Criteria):
As a cluster-admin or SRE I should be able to configure Karpenter with OCP on AWS. Both cli and UI should enable users to configure Karpenter and disable CAS.
- Run Karpenter in management cluster and disable CAS
- OCM API
- Enable/Disable Cluster autoscaler
- Enable/disable AutoNode feature
- New ARN role configuration for Karpenter
- Optional: New managed policy or integration with existing nodepool role permissions
- Expose NodeClass/Nodepool resources to users.
- secure node provisioning and management, machine approval system for Karpenter instances
- HCP Karpenter cleanup/deletion support
- ROSA CAPI fields to enable/disable/configure Karpenter
- Write end-to-end tests for karpenter running on ROSA HCP
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Managed, i.e. ROSA-HCP |
| Classic (standalone cluster) | N/A |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | MNO |
| Connected / Restricted Network | Connected |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86_x64, ARM (aarch64) |
| Operator compatibility | |
| Backport needed (list applicable versions) | No |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | yes - console |
| Other (please specify) | OCM, rosa-cli, ACM, cost management |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
- Self-managed standalone OCP, self-hosted HCP, ROSA classic are out-of-scope.
- Creating a multi-provider cost/pricing operator compatible with CAPI is beyond the scope of this Feature. That may take more time.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
- Karpenter.sh is an open-source node provisioning project built for Kubernetes. It is designed to simplify Kubernetes infrastructure by automatically launching and terminating nodes based on the needs of your workloads. Karpenter can help you to reduce costs, improve performance, and simplify operations.
- Karpenter works by observing the unscheduled pods in your cluster and launching new nodes to accommodate them. Karpenter can also terminate nodes that are no longer needed, which can help you save money on infrastructure costs.
- Karpenter architecture has a Karpenter-core and Karpenter-provider as components.
The core has AWS code which does the resource calculation to reduce the cost by re-provisioning new nodes.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
- Ability to enable AutoNode/Karpenter during installation and post-cluster installation
- Ability to run AutoNode/Karpenter and Cluster Autoscaler at the same time
- Use with an OpenShift cluster with Hosted Control Planes
- CAPI to enable/disable/configure AutoNode/Karpenter
- Have AutoNode/Karpenter perform data plane upgrades
- Designed for FIPS / FIPS compatible
- Enable cost effective mixed compute with auto-provisioning from/to zero
- Provide Karpenter metrics for monitoring and reporting purposes
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
- Migration guides from using CAS to Karpenter
- Performance testing to compare CAS vs Karpenter on ROSA HCP
- API documentation for NodePool and EC2NodeClass configuration
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Goal
- Validate the implementation details are prod ready before removing the feature gate
Why is this important?
- …
Scenarios
- Revisit Default ec2Class
- Revisit karpenter IAM policy
- Consider vendoring karpenter instead of using unstructured types
- Consider manage the userdata programatically instead of using NodePool API
- Revisit rbac and watchers
- Last time I checked, karpenter was failing to allocate OCP workloads because of a conflicting label.
https://github.com/kubernetes-sigs/karpenter/issues/1046#issuecomment-2578291462
https://github.com/kubernetes-sigs/karpenter/pull/1908
- Remove feature gate
- ...
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Move from karpenter nodepool to programatic generate userdata
User Story:
As a (user persona), I want to be able to:
- create/update Karpenter resources directly without dealing with unstructured types
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Karpenter CRDs are vendored in Hypershift code
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
This is currently hardcoded to this value and clobbered by the controller in the default ec2nodeclass. https://github.com/openshift/hypershift/blob/f21f250592ea74b38e8d79555ab720982869ef5e/karpenter-operator/controllers/karpenter/karpenter_controller.go#L362
We need to default to a more neutral name and possibly stop clobbering it so it can be changed.
I see creating the role as an admin task. For hypershift "the project" this can be automated by the cli, so it will be created when cli create cluster with known name e.g karpenter-role-infra-id
While VAP is ok for implementing shared ownership it has some drawbacks. e.g. it forces us to change the builtin CEL rules of the API for required fields which is a maintenance burden and error prone. Besides it doesn't gives control to future api pivots we might need to execute to satisfy business needs. E.g. expose a field for dual stream support which requires picking a different ami, e.g expose a field for kubeletconfig that let us include that in the payload generation...
we should be ready to pivot to have our own class which exposes only a subset of the upstream and have a controller which just renders the upstream one
Feature Overview (aka. Goal Summary)
The ability in OpenShift to create trust and directly consume access tokens issued by external OIDC Authentication Providers using an authentication approach similar to upstream Kubernetes.
BYO Identity will help facilitate CLI only workflows and capabilities of the Authentication Provider (such as Keycloak, Dex, Azure AD) similar to upstream Kubernetes.
Goals (aka. expected user outcomes)
Ability in OpenShift to provide a direct, pluggable Authentication workflow such that the OpenShift/K8s API server can consume access tokens issued by external OIDC identity providers. Kubernetes provides this integration as described here. Customer/Users can then configure their IDPs to support the OIDC protocols and workflows they desire such as Client credential flow.
OpenShift OAuth server is still available as default option, with the ability to tune in the external OIDC provider as a Day-2 configuration.
Requirements (aka. Acceptance Criteria):
- The customer should be able to tie into RBAC functionality, similar to how it is closely aligned with OpenShift OAuth
Use Cases (Optional):
- As a customer, I would like to integrate my OIDC Identity Provider directly with the OpenShift API server.
- As a customer in multi-cluster cloud environment, I have both K8s and non-K8s clusters using my IDP and hence I need seamless authentication directly to the OpenShift/K8sAPI using my Identity Provider
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
_Items listed for GA https://issues.redhat.com/browse/OCPSTRAT-1804_
- Multiple IDPs
- Removing resources related to Oauth server when it is disabled.
- Metrics equivalence. We provided access attempts for OAuth. With KAS we cannot provide exactly same functionality but we are looking to provide ways to review audit log and get this information.
- Exec plugins other than oc
- OIDC workflows other than Auth Code flow (Such as device code grant workflow, implicit flow etc). __
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
The ability to provide a direct authentication workflow such that OpenShift can consume bearer tokens issued by external OIDC identity providers, replacing the built-in OAuth stack by deactivating/removing its components as necessary.
Why is this important? (mandatory)
OpenShift has its own built-in OAuth server which can be used to obtain OAuth access tokens for authentication to the API. The server can be configured with an external identity provider (including support for OIDC), however it is still the built-in server that issues tokens, and thus authentication is limited to the capabilities of the oauth-server.
Scenarios (mandatory)
- As a customer, I want to integrate my OIDC Identity Provider directly with OpenShift so that I can fully use its capabilities in machine-to-machine workflows.
*As a customer in a hybrid cloud environment, I want to seamlessly use my OIDC Identity Provider across all of my fleet.
Dependencies (internal and external) (mandatory)
- Support in the console/console-operator (already completed)
- Support in the OpenShift CLI `oc` (already completed)
Contributing Teams(and contacts) (mandatory)
- Development - OCP Auth
- Documentation - OCP Auth
- QE - OCP Auth
- PX -
- Others -
Acceptance Criteria (optional)
- external OIDC provider can be configured to be used directly via the kube-apiserver to issue tokens
- built-in oauth stack no longer operational in the cluster; respective APIs, resources and components deactivated
- changing back to the built-in oauth stack possible
Drawbacks or Risk (optional)
- Enabling an external OIDC provider to an OCP cluster will result in the oauth-apiserver being removed from the system; this inherently means that the two API Services it is serving (v1.oauth.openshift.io, v1.user.openshift.io) will be gone from the cluster, and therefore any related data will be lost. It is the user's responsibility to create backups of any required data.
- Configuring an external OIDC identity provider for authentication by definition means that any security updates or patches must be managed independently from the cluster itself, i.e. cluster updates will not resolve security issues relevant to the provider itself; the provider will have to be updated separately. Additionally, new functionality or features on the provider's side might need integration work in OpenShift (depending on their nature).
Done - Checklist (mandatory)
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
In order to remove the RoleBindingRestriction CRD from the cluster, as outlined in the updates to the original OIDC enhancement proposal in CNTRLPLANE-69, we will have to make it such that CVO no longer manages it. This means updating the cluster-authentication-operator such that it is responsible for ensuring the CRD is present on the cluster.
The CAO and KAS-o both need to work and enable structured authentication configuration for the KAS static pods.
CAO:
- a controller tracks the auth CR for auth type OIDC
- generates structured auth config object and serializes it into a configmap
- syncs the configmap into openshift-config
KAS-o:
- a config observer tracks the auth CR for type OIDC
- syncs the auth configmap from openshift-config into openshift-kube-apiserver and enables the `--authentication-config` CLI arg for the KAS pods
- the auth-metadata and webhook-authenticator config observers remove their resources and CLI args accordingly
- a revision controller syncs that configmap into a static file
Description of problem:
This is a bug found during pre-merge test of 4.18 epic AUTH-528 PRs and filed for better tracking per existing "OpenShift - Testing Before PR Merges - Left-Shift Testing" google doc workflow.
co/console degraded with AuthStatusHandlerDegraded after OCP BYO external oidc is configured and then removed (i.e. reverted back to OAuth IDP).
Version-Release number of selected component (if applicable):
Cluster-bot build which is built at 2024-11-25 09:39 CST (UTC+800) build 4.18,openshift/cluster-authentication-operator#713,openshift/cluster-authentication-operator#740,openshift/cluster-kube-apiserver-operator#1760,openshift/console-operator#940
How reproducible:
Always (tried twice, both hit it)
Steps to Reproduce:
1. Launch a TechPreviewNoUpgrade standalone OCP cluster with above build. Configure htpasswd IDP. Test users can login successfully.
2. Configure BYO external OIDC in this OCP cluster using Microsoft Entra ID. KAS and console pods can roll out successfully. oc login and console login to Microsoft Entra ID can succeed.
3. Remove BYO external OIDC configuration, i.e. go back to original htpasswd OAuth IDP:
[xxia@2024-11-25 21:10:17 CST my]$ oc patch authentication.config/cluster --type=merge -p='
spec:
type: ""
oidcProviders: null
'
authentication.config.openshift.io/cluster patched
[xxia@2024-11-25 21:15:24 CST my]$ oc get authentication.config cluster -o yaml
apiVersion: config.openshift.io/v1
kind: Authentication
metadata:
annotations:
include.release.openshift.io/ibm-cloud-managed: "true"
include.release.openshift.io/self-managed-high-availability: "true"
release.openshift.io/create-only: "true"
creationTimestamp: "2024-11-25T04:11:59Z"
generation: 5
name: cluster
ownerReferences:
- apiVersion: config.openshift.io/v1
kind: ClusterVersion
name: version
uid: e814f1dc-0b51-4b87-8f04-6bd99594bf47
resourceVersion: "284724"
uid: 2de77b67-7de4-4883-8ceb-f1020b277210
spec:
oauthMetadata:
name: ""
serviceAccountIssuer: ""
type: ""
webhookTokenAuthenticator:
kubeConfig:
name: webhook-authentication-integrated-oauth
status:
integratedOAuthMetadata:
name: oauth-openshift
oidcClients:
- componentName: cli
componentNamespace: openshift-console
- componentName: console
componentNamespace: openshift-console
conditions:
- lastTransitionTime: "2024-11-25T13:10:23Z"
message: ""
reason: OIDCConfigAvailable
status: "False"
type: Degraded
- lastTransitionTime: "2024-11-25T13:10:23Z"
message: ""
reason: OIDCConfigAvailable
status: "False"
type: Progressing
- lastTransitionTime: "2024-11-25T13:10:23Z"
message: ""
reason: OIDCConfigAvailable
status: "True"
type: Available
currentOIDCClients:
- clientID: 95fbae1d-69a7-4206-86bd-00ea9e0bb778
issuerURL: https://login.microsoftonline.com/6047c7e9-b2ad-488d-a54e-dc3f6be6a7ee/v2.0
oidcProviderName: microsoft-entra-id
KAS and console pods indeed can roll out successfully; and now oc login and console login indeed can succeed using the htpasswd user and password:
[xxia@2024-11-25 21:49:32 CST my]$ oc login -u testuser-1 -p xxxxxx
Login successful.
...
But co/console degraded, which is weird:
[xxia@2024-11-25 21:56:07 CST my]$ oc get co | grep -v 'True *False *False'
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
console 4.18.0-0.test-2024-11-25-020414-ci-ln-71cvsj2-latest True False True 9h AuthStatusHandlerDegraded: Authentication.config.openshift.io "cluster" is invalid: [status.oidcClients[1].currentOIDCClients[0].issuerURL: Invalid value: "": oidcClients[1].currentOIDCClients[0].issuerURL in body should match '^https:\/\/[^\s]', status.oidcClients[1].currentOIDCClients[0].oidcProviderName: Invalid value: "": oidcClients[1].currentOIDCClients[0].oidcProviderName in body should be at least 1 chars long]
Actual results:
co/console degraded, as above.
Expected results:
co/console is normal.
Additional info:
In order to fully transition the management of the RoleBindingRestriction CRD to the cluster-authentication-operator, we also need to update the openshift/installer to use the cluster-authentication-operator render subcommand to add the RoleBindingRestriction CRD to the set of manifests applied during cluster bootstrapping.
Without the RoleBindingRestriction CRD included in the set of bootstrap manifests, the authorization.openshift.io/RestrictSubjectBindings admission plugin will prevent the creation of system:* RoleBindings during the installation process.
Feature Overview
This is a TechDebt and doesn't impact OpenShift Users.
As the autoscaler has become a key feature of OpenShift, there is the requirement to continue to expand it's use bringing all the features to all the cloud platforms and contributing to the community upstream. This feature is to track the initiatives associated with the Autoscaler in OpenShift.
Goals
- Scale from zero available on all cloud providers (where available)
- Required upstream work
- Work needed as a result of rebase to new kubernetes version
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| vSphere autoscaling from zero | No | |
| Upstream E2E testing | No | |
| Upstream adapt scale from zero replicas | No | |
Out of Scope
n/a
Background, and strategic fit
Autoscaling is a key benefit of the Machine API and should be made available on all providers
Assumptions
Customer Considerations
Documentation Considerations
- Target audience: cluster admins
- Updated content: update docs to mention any change to where the features are available.
Epic Goal
- Update the scale from zero autoscaling annotations on MachineSets to conform with the upstream keys, while also continuing to accept the openshift specific keys that we have been using.
Why is this important?
- This change makes our implementation of the cluster autoscaler conform to the API that is described in the upstream community. This reduces the mental overhead for someone that knows kubernetes but is new to openshift.
- This change also reduces the maintenance burden that we carry in the form of addition patches to the cluster autoscaler. By changing our controllers to understand the upstream annotations we are able to remove extra patches on our fork of the cluster autoscaler, making future maintenance easier and closer to the upstream source.
Scenarios
- A user is debugging a cluster autoscaler issue by examining the related MachineSet objects, they see the scale from zero annotations and recognize them from the project documentation and from upstream discussions. The result is that the user is more easily able to find common issues and advice from the upstream community.
- An openshift maintainer is updating the cluster autoscaler for a new version of kubernetes, because the openshift controllers understand the upstream annotations, the maintainer does not need to carry or modify a patch to support multiple varieties of annotation. This in turn makes the task of updating the autoscaler simpler and reduces burden on the maintainer.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Scale from zero autoscaling must continue to work with both the old openshift annotations and the newer upstream annotations.
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - OpenShift code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - OpenShift documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - OpenShift build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - OpenShift documentation merged: <link to meaningful PR>
please note, the changes described by this epic will happen in OpenShift controllers and as such there is no "upstream" relationship in the same sense as the Kubernetes-based controllers.
User Story
As a developer, in order to deprecate the old annotations, we will need to carry both for at least one release cycle. Updating the CAO to apply the upstream annotations, and the CAS to accept both (preferring upstream), will allow me to properly deprecate the old annotations.
Background
to help the transition to the upstream scale from zero annotations, we need to have the CAS recognize both sets of annotations, preferring the upstream, for at least one release cycle. this will allow us to have a window of deprecation on the old annotations.
Steps
- update CAS to recognize both annotations
- add a unit test to ensure prioritization works properly
Stakeholders
- openshift eng
Definition of Done
- CAS can recognize both sets of annotations
- Docs
- n/a
- Testing
- unit testing for priority behavior
Upstream K8s deprecated PodSecurityPolicy and replaced it with a new built-in admission controller that enforces the Pod Security Standards (See here for the motivations for deprecation).] There is an OpenShift-specific dedicated pod admission system called Security Context Constraints. Our aim is to keep the Security Context Constraints pod admission system while also allowing users to have access to the Kubernetes Pod Security Admission.
With OpenShift 4.11, we are turned on the Pod Security Admission with global "privileged" enforcement. Additionally we set the "restricted" profile for warnings and audit. This configuration made it possible for users to opt-in their namespaces to Pod Security Admission with the per-namespace labels. We also introduced a new mechanism that automatically synchronizes the Pod Security Admission "warn" and "audit" labels.
With OpenShift 4.19, we intend to move the global configuration to enforce the "restricted" pod security profile globally. With this change, the label synchronization mechanism will also switch into a mode where it synchronizes the "enforce" Pod Security Admission label rather than the "audit" and "warn".
Epic Goal
Get Pod Security admission to be run in "restricted" mode globally by default alongside with SCC admission.
When creating a custom SCC, it is possible to assign a priority that is higher than existing SCCs. This means that any SA with access to all SCCs might use the higher priority custom SCC, and this might mutate a workload in an unexpected/unintended way.
To protect platform workloads from such an effect (which, combined with PSa, might result in rejecting the workload once we start enforcing the "restricted" profile) we must pin the required SCC to all workloads in platform namespaces (openshift-, kube-, default).
Each workload should pin the SCC with the least-privilege, except workloads in runlevel 0 namespaces that should pin the "privileged" SCC (SCC admission is not enabled on these namespaces, but we should pin an SCC for tracking purposes).
The following tables track progress.
Progress summary
| # namespaces | 4.19 | 4.18 | 4.17 | 4.16 | 4.15 | 4.14 |
|---|---|---|---|---|---|---|
| monitored | 82 | 82 | 82 | 82 | 82 | 82 |
| fix needed | 68 | 68 | 68 | 68 | 68 | 68 |
| fixed | 39 | 39 | 35 | 32 | 39 | 1 |
| remaining | 29 | 29 | 33 | 36 | 29 | 67 |
| ~ remaining non-runlevel | 8 | 8 | 12 | 15 | 8 | 46 |
| ~ remaining runlevel (low-prio) | 21 | 21 | 21 | 21 | 21 | 21 |
| ~ untested | 3 | 2 | 2 | 2 | 82 | 82 |
Progress breakdown
| # | namespace | 4.19 | 4.18 | 4.17 | 4.16 | 4.15 | 4.14 |
|---|---|---|---|---|---|---|---|
| 1 | oc debug node pods | |
|
|
|
|
|
| 2 | openshift-apiserver-operator | |
|
|
|
|
|
| 3 | openshift-authentication | |
|
|
|
|
|
| 4 | openshift-authentication-operator | |
|
|
|
|
|
| 5 | openshift-catalogd | |
|
|
|
|
|
| 6 | openshift-cloud-credential-operator | |
|
|
|
|
|
| 7 | openshift-cloud-network-config-controller | |
|
|
#2496 | ||
| 8 | openshift-cluster-csi-drivers | #118 #5310 #135 | #524 #131 #306 #265 #75 | #170 #459 | |
||
| 9 | openshift-cluster-node-tuning-operator | |
|
|
|
|
|
| 10 | openshift-cluster-olm-operator | |
|
|
|
n/a | n/a |
| 11 | openshift-cluster-samples-operator | |
|
|
|
|
|
| 12 | openshift-cluster-storage-operator | |
|
#459 #196 | |
||
| 13 | openshift-cluster-version | #1038 | |
||||
| 14 | openshift-config-operator | |
|
|
|
|
|
| 15 | openshift-console | |
|
|
|
|
|
| 16 | openshift-console-operator | |
|
|
|
|
|
| 17 | openshift-controller-manager | |
|
|
|
|
|
| 18 | openshift-controller-manager-operator | |
|
|
|
|
|
| 19 | openshift-e2e-loki | |
|
|
|
|
|
| 20 | openshift-image-registry | #1008 | |
||||
| 21 | openshift-ingress | #1032 | |||||
| 22 | openshift-ingress-canary | #1031 | |||||
| 23 | openshift-ingress-operator | #1031 | |||||
| 24 | openshift-insights | |
|
|
|
|
|
| 25 | openshift-kni-infra | |
|
|
|
|
|
| 26 | openshift-kube-storage-version-migrator | |
|
|
|
|
|
| 27 | openshift-kube-storage-version-migrator-operator | |
|
|
|
|
|
| 28 | openshift-machine-api | #1308 #1317 | #1311 | #407 | #315 #282 #1220 #73 #50 #433 | |
|
| 29 | openshift-machine-config-operator | |
|
#4219 | #4384 | |
|
| 30 | openshift-manila-csi-driver | |
|
|
|
|
|
| 31 | openshift-marketplace | |
|
|
|
|
|
| 32 | openshift-metallb-system | |
|
|
#241 | ||
| 33 | openshift-monitoring | #2298 #366 | #2498 | #2335 | |
||
| 34 | openshift-network-console | |
|
||||
| 35 | openshift-network-diagnostics | |
|
|
#2496 | ||
| 36 | openshift-network-node-identity | |
|
|
#2496 | ||
| 37 | openshift-nutanix-infra | |
|
|
|
|
|
| 38 | openshift-oauth-apiserver | |
|
|
|
|
|
| 39 | openshift-openstack-infra | |
|
|
|
||
| 40 | openshift-operator-controller | |
|
|
|
|
|
| 41 | openshift-operator-lifecycle-manager | |
|
|
|
|
|
| 42 | openshift-route-controller-manager | |
|
|
|
|
|
| 43 | openshift-service-ca | |
|
|
|
|
|
| 44 | openshift-service-ca-operator | |
|
|
|
|
|
| 45 | openshift-sriov-network-operator | |
|
|
|
|
|
| 46 | openshift-user-workload-monitoring | |
|
|
|
|
|
| 47 | openshift-vsphere-infra | |
|
|
|
|
|
| 48 | (runlevel) kube-system | ||||||
| 49 | (runlevel) openshift-cloud-controller-manager | ||||||
| 50 | (runlevel) openshift-cloud-controller-manager-operator | ||||||
| 51 | (runlevel) openshift-cluster-api | ||||||
| 52 | (runlevel) openshift-cluster-machine-approver | ||||||
| 53 | (runlevel) openshift-dns | ||||||
| 54 | (runlevel) openshift-dns-operator | ||||||
| 55 | (runlevel) openshift-etcd | ||||||
| 56 | (runlevel) openshift-etcd-operator | ||||||
| 57 | (runlevel) openshift-kube-apiserver | ||||||
| 58 | (runlevel) openshift-kube-apiserver-operator | ||||||
| 59 | (runlevel) openshift-kube-controller-manager | ||||||
| 60 | (runlevel) openshift-kube-controller-manager-operator | ||||||
| 61 | (runlevel) openshift-kube-proxy | ||||||
| 62 | (runlevel) openshift-kube-scheduler | ||||||
| 63 | (runlevel) openshift-kube-scheduler-operator | ||||||
| 64 | (runlevel) openshift-multus | ||||||
| 65 | (runlevel) openshift-network-operator | ||||||
| 66 | (runlevel) openshift-ovn-kubernetes | ||||||
| 67 | (runlevel) openshift-sdn | ||||||
| 68 | (runlevel) openshift-storage |
What
The PodSecurityAdmissionLabelSynchronizationController in cluster-policy-controller should set an annotation, that tells us what it decided wrt given namespace.
Why
- Once a customer changes the labels and the label syncer doesn't set them anymore, we don't know what it would have picked.
- Knowing that is important, in case that the label syncer would set the enforce label.
Note
- Annotation is already part of the API: https://github.com/openshift/api/pull/1980.
- Once this is done, the kube-apiserver-operator can be updated to use that.
- We would like to backpor this to 4.18
Feature Overview
- Add support to custom GCP API endpoints (private and restricted) while deploying OpenShift on GCP
Goals
- Enable OpenShift to support private and restricted GCP API endpoints while deploying the platform on GCP as we do for AWS already
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Use Cases
This Section:
- As a user I want to be able to use GCP Private API endpoints while deploying OpenShift so I can be complaint with my company security policies
- As a user I want to be able to use GCP Restricted API endpoints while deploying OpenShift so I can be complaint with my company security policies
Background, and strategic fit
For users with strict regulatory policies, Private Service Connect allows private consumption of services across VPC networks that belong to different groups, teams, projects, or organizations. Supporting OpenShift to consume these private endpoints is key for these customers to be able to deploy the platform on GCP and be complaint with their regulatory policies.
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Feature Overview
- Add support to custom GCP API endpoints (private and restricted) while deploying OpenShift on GCP
Goals
- Enable OpenShift to support private and restricted GCP API endpoints while deploying the platform on GCP as we do for AWS already
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Use Cases
This Section:
- As a user I want to be able to use GCP Private API endpoints while deploying OpenShift so I can be complaint with my company security policies
- As a user I want to be able to use GCP Restricted API endpoints while deploying OpenShift so I can be complaint with my company security policies
Background, and strategic fit
For users with strict regulatory policies, Private Service Connect allows private consumption of services across VPC networks that belong to different groups, teams, projects, or organizations. Supporting OpenShift to consume these private endpoints is key for these customers to be able to deploy the platform on GCP and be complaint with their regulatory policies.
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
User Story:
As a (user persona), I want to be able to:
- Add the Tech Preview Feature Gate to the installer for custom endpoints
- Validate the custom endpoints feature gate in the installer
- Capability 3
so that I can achieve
- An installer feature gate to ensure users know that this feature is not yet slated for release
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a (user persona), I want to be able to:
- Ensure that the custom endpoints are valid before use.
- Reach the endpoints provided.
- Capability 3
so that I can achieve
- Ensuring that the custom endpoint connectivity are not the reason for any installation issues.
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a (user persona), I want to be able to:
- Add the feature to API
- Add tech preview tags for the feature
- Capability 3
so that I can achieve
- Protect installs using this feature. The feature will touch many aspects of openshift
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a (user persona), I want to be able to:
- Enter the custom endpoints via the install config
- Capability 2
- Capability 3
so that I can achieve
- Initiate an install where the custom endpoints for GCP APIs can be used.
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- The user enters the data into the install-config. The data is validated.
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a (user persona), I want to be able to:
- Use the custom endpoints in MAPI that were set in the installer.
- Override the endpoints for:
- compute
- tagging
so that I can achieve
- Using the same custom endpoints for all of the services in the cluster.
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- The services with endpoints to be overwritten can be found:
- pkg/cloud/gcp/actuators/services
- Each time the service is created New, the the option for `withEndpoint` should be issued when applicable.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a (user persona), I want to be able to:
- Pass the custom endpoints to all cluster components
- Capability 2
- Capability 3
so that I can achieve
- All cluster components should use the same api endpoints.
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- Fill out the API infra config with the custom endpoints when the user has supplied them via the install-config
- Bring in the API changes as a vendor update.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
Add the ability to choose subnets for IngressControllers with LoadBalancer-type Services for AWS in the Installer. This install config should be applies to the default IngressController and all future IngressControllers (the design is similar to installconfig.platform.aws.lbtype).
Why is this important?
Cluster Admins may have dedicated subnets for their load balancers due to security reasons or infrastructure constraints. With the implementation in NE-705, Cluster Admins will be able to specify subnets for IngressControllers for Day 2 operations. Service Delivery needs a way to configure IngressController subnets for the default IngressController for ROSA.
Scenarios
If the cluster is spread across multiple subnets then we can have a way to select the subnet while creating ingresscontroller of type LoadBalancerService.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- Network Edge Epic (
NE-705)
Previous Work (Optional):
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
- As an openshift-install user I want to be able to continue to use aws.subnets during deprecation (a warning will show)
- As an openshift developer, I only want a single code path for subnets (via upconversion)
Acceptance Criteria:
Description of criteria:
- Validation that both fields are not simultaneously specified
- When aws.subnets is specified, it's upconverted into aws.vpc.subnets
- Existing pkg/types/aws/Subnets type is renamed to DeprecatedSubnets
- Remove all (or as many possible) usages of DeprecatedSubnets, replaced with the new vpc.Subnets field
- We may need to keep usage of DeprecatedSubnets for certain validations
- Warning when using deprecated field
(optional) Out of Scope:
.
Engineering Details:
- Conversion package: https://github.com/openshift/installer/tree/main/pkg/types/conversion
- Review how subnets are used in https://github.com/openshift/installer/blob/main/pkg/asset/installconfig/aws/metadata.go and whether any changes/refactoring is needed
User Story:
Static validations (no API connection required)
Acceptance Criteria:
Description of criteria:
The subnet IDs must be valid:Start with subnet-Length is exactly 24 characters
- The subnet IDs must not include duplicates
- Maximum of 10 IngressController Subnets Validation
- All or Nothing Subnet Roles Selection
- For a subnet that has defined roles
- Roles must be of supported types (i.e. from a set of defined roles)
- Roles must not be duplicate. This and * check naturally validates that a subnet can only have max 5 roles
- EdgeNode cannot be combined with any other roles
- ClusterNode, IngressControllerLB, ControlPlaneExternalLB (if cluster is external), and ControlPlaneInternalLB must be assigned to at least 1 subnet
- A subnet cannot have both role ControlPlaneExternalLB and ControlPlaneInternalLB *
- If the cluster is internal, ControlPlaneExternalLB must not be assigned to any subnets.
Some validations are extracted from API validation (i.e. the intstaller does not handle CEL at this time) and Xvalidation markers (i.e. defined in the enhancement proposal).
(optional) Out of Scope:
Validations that require access to the AWS API will go in pkg/asset (different card)
Engineering Details:
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As an openshift-instlal user I want to be able to specify AWS subnets with roles.
Acceptance Criteria:
Description of criteria:
- Installconfig has installconfig.platform.aws.vpc.subnets field
- vpc.subnets conforms to API defined in the enhancement
- godoc/oc explain text is written and generated (see explain docs)
(optional) Out of Scope:
Validations will be handled in a different card.
Engineering Details:
- API for installconfig field is defined in https://github.com/openshift/enhancements/blob/30f44ee0cd57dc4ba3b72e10c0b8f1614970d0e0/enhancements/installer/aws-lb-subnet-selection.md
-
- the type for subnets is:
- id - string
- roles - slice of SubnetRoles
- the type for subnets is:
- the list of subnet roles is defined in the enhancement. they include ClusterNode, EdgeNode, ControlPlaneExternalLBSubnetRole, etc...
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
Implement Migration core for MAPI to CAPI for AWS
- This feature covers the design and implementation of converting from using the Machine API (MAPI) to Cluster API (CAPI) for AWS
- This Design investigates possible solutions for AWS
- Once AWS shim/sync layer is implemented use the architecture for other clouds in phase-2 & phase 3
Acceptance Criteria
When customers use CAPI, There must be no negative effect to switching over to using CAPI . Seamless migration of Machine resources. the fields in MAPI/CAPI should reconcile from both CRDs.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- To bring MAPI and CAPI to feature parity and unblock conversions between MAPI and CAPI resources
Why is this important?
- Blocks migration to Cluster API
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Background
VolumeSize on the block device mapping spec in MAPA is currently optional (and if is not set we send an empty value to AWS and let it choose for us), where it is required and a minimum of 8gb in CAPA.
We need to determine an appropriate behaviour for when the value is unset.
Steps
- Check historically on the installer to see what value it typically has set (in the AMI, and if that changed overtime)
- Determine an appropriate minimum size for the root volume in OpenShift
- When not set, default the CAPA volume size to an appropriate value based on the above
- Adjust conversion logic based on the above
Stakeholders
- Cluster Infra
Definition of Done
- Machines with no volume size in MAPI can be converted to CAPI
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Create the core/common tooling needed to enable the migration designed in
OCPCLOUD-1578 - To allow providers to individually migrate from MAPI to CAPI
- Implementation plan in https://docs.google.com/document/d/1IZPmcJujKPdoBZKt66i3eGcJWb1RDIgk1ywt13h6T-w/edit
Why is this important?
- We need to build out the core so that development of the migration for individual providers can then happen in parallel
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Background
To enable CAPI MachineSets to still mirror MAPI MachineSets accurately, and to enable MAPI MachineSets to be implemented by CAPI MachineSets in the future, we need to implement a way to convert CAPI Machines back into MAPI Machines.
These steps assume that the CAPI Machine is authoritative, or, that there is no MAPI Machines.
Behaviours
- If no Machine exists in MAPI
- But the CAPI Machine is owned, and that owner exists in MAPI
- Create a MAPI Machine to mirror the CAPI Machine
- MAPI Machines should set authority to CAPI on create
- But the CAPI Machine is owned, and that owner exists in MAPI
- If a MAPI Machine exists
- Convert infrastructure template from InfraMachine to providerSpec
- Update spec and status fields of MAPI Machine to reflect CAPI Machine
- On failures
- Set Synchronized condition to False and report error on MAPI resource
- On success
- Set Synchronized condition to True on MAPI resource
- Set status.synchronizedGeneration to match the auth resource generation
Steps
- Implement conversion based on the behaviours outlined above using the CAPI to MAPI conversion library
Stakeholders
- Cluster Infra
Definition of Done
- When a CAPI MachineSet scales up and is mirrored in MAPI, the CAPI Machine gets mirrored into MAPI
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
Background
For the MachineSet controller, we need to implement a forward conversion, converting the MachineAPI MachineSet to ClusterAPI.
This will involve creating the CAPI MachineSet if it does not exist, and managing the Infrastructure templates.
This card covers the case where MAPI is currently authoritative.
Behaviours
- Create Cluster API mirror if not present
- CAPI mirror should be paused on create
- Names of mirror should be 1:1 with original
- Manage InfraTemplate creation by converting MAPI providerSpec
- InfraTemplate naming should be based on hash to be able to deduplicate
- InfraTemplate naming should be based on parent resources
- InfraTemplate should have ownerReference to CAPI MachineSet
- If template has changed, remove ownerReference from old template. If no other ownerReferences, remove template.
- Should be identifiable as created by the sync controller (annotated?)
- Ensure CAPI MachineSet spec and status overwritten with conversion from MAPI
- Ensure Labels/Annotations copied from MAPI to CAPI
- On failures
- Set Synchronized condition to False and report error on MAPI resource
- On success
- Set Synchronized condition to True on MAPI resource
- Set status.synchronizedGeneration to match the auth resource generation
Steps
- Implement MAPI to CAPI conversion by leveraging library for conversion and applying above MachineSet level rules
Stakeholders
- Cluster Infra
Definition of Done
- When a MAPI MachineSet exists, a CAPI MachineSet is created and kept up to date if there are changes
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
As QE have tried to test upstream CAPI pausing, we've hit a few issues with running the migration controller. & cluster capi operator on a real cluster vs envtest.
This card captures the work required to iron out these kinks, and get things running (i.e not crashing).
I also think we want an e2e or some sort of automated testing to ensure we don't break things again.
Goal: Stop the CAPI operator crashing on startup in a real cluster.
Non goals: get the entire conversion flow running from CAPI -> MAPI and MAPI -> CAPI. We still need significant feature work before we're here.
- https://github.com/openshift/cluster-capi-operator/pull/244
- https://github.com/openshift/cluster-capi-operator/pull/243
- https://github.com/openshift/cluster-capi-operator/pull/242
- https://github.com/openshift/cluster-capi-operator/pull/238
- https://github.com/openshift/cluster-machine-approver/pull/262
Background
For the Machine controller, we need to implement a forward conversion, converting the MachineAPI Machine to ClusterAPI.
This will involve creating the CAPI Machine if it does not exist, and managing the Infrastructure Machine.
This card covers the case where MAPI is currently authoritative.
Behaviours
- Create Cluster API mirror if not present
- CAPI mirror should be paused on create
- Names of mirror should be 1:1 with original
- Manage InfraMachine creation by converting MAPI providerSpec
- InfraMachine should be named based on the name of the Machine (to mirror CAPI behaviour)
- InfraMachine should have appropriate owner references and finalizers created
- Ensure CAPI Machine spec and status overwritten with conversion from MAPI
- Ensure Labels/Annotations copied from MAPI to CAPI
- On failures
- Set Synchronized condition to False and report error on MAPI resource
- On success
- Set Synchronized condition to True on MAPI resource
- Set status.synchronizedGeneration to match the auth resource generation
Steps
- Implement behaviours described above to convert MAPI Machines to CAPI Machines using conversion library
Stakeholders
- Cluster Infra
Definition of Done
- MAPI Machines create paused CAPI mirrors
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- To bring MAPI and CAPI to feature parity and unblock conversions between MAPI and CAPI resources
Why is this important?
- Blocks migration to Cluster API
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story
As a user I want to be able to add labels/taints/annotations to my machines, and have them propagate to the nodes. This will allow me to use the labels for other tasks e.g selectors.
Background
Currently, MAPI supports propagating labels from machines to nodes, but CAPI does not. When we move to CAPI we will lose this feature.
_See https://issues.redhat.com/browse/OCPBUGS-37236_
Relevant upstream issues:
Steps
- Understand why the discrepancy exists
- Determine how much work it would be for the NodeLink controller to copy the labels
- Chat with upstream to see if the idea of unrestricted label propagation through some mechansim is palletable.
- Come back to the group and decide a course of action.
Stakeholders
- Our users, who currently have this feature.
Definition of Done
- Code is implemented upstream to sync labels from a Machine to a Node
- Our manifests include the "--additional-sync-machine-labels=.*" argument. The generated manifests are at https://github.com/openshift/cluster-api/blob/master/openshift/manifests/0000_30_cluster-api_04_cm.core-cluster-api.yaml#L481
Epic Goal
This is the epic tracking the work to collect a list of TLS artifacts (certificates, keys and CA bundles).
This list will contain a set of required an optional metadata. Required metadata examples are ownership (name of Jira component) and ability to auto-regenerate certificate after it has expired while offline. In most cases metadata can be set via annotations to secret/configmap containing the TLS artifact.
Components not meeting the required metadata will fail CI - i.e. when a pull request makes a component create a new secret, the secret is expected to have all necessary metadata present to pass CI.
This PR will enforce it WIP API-1789: make TLS registry tests required
Description of problem:
In order to make TLS registry tests required we need to make sure all OpenShift variants are using the same metadata for kube-apiserver certs. Hypershift uses several certs stored in the secret without accompanying metadata (namely component ownership).
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1.
2.
3.
Actual results:
Expected results:
Additional info:
In order to keep track of existing certs/CA bundles and ensure that they adhere to requirements we need to have a TLS artifact registry setup.
The registry would:
- have a test which automatically collects existing certs/CA bundles from secrets/configmaps/files on disk
- have a test which collects necessary metedata from them (from cert contents or annotations)
- ensure that new certs match expected metadata and have necessary annotations on when a new cert is added
Ref: API-1622
Feature Overview (aka. Goal Summary)
To improve automation, governance and security, AWS customers extensively use AWS Tags to track resources. Customers wants the ability to change user tags on day 2 without having to recreate a new cluster to have 1 or more tags added/modified.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Complete during New status.
- Cluster administrator can add one or more tags to an existing cluster.
- Cluster administrator can remove one or more tags from an existing cluster.
- Cluster administrator can add one or more tags just to machine-pool / node-pool in the ROSA with HCP cluster.
- All ROSA client interfaces (ROSA CLI, API, UI) can utilise the day2 tagging feature on ROSA with HCP clusters
- All OSD client interfaces (API, UI, CLI) can utilize the day2 tagging feature on ROSA with HCP clusters
- This feature does not affect the Red Hat owned day1 tags built into OCP/ROSA (there are 10 reserved spaces for tags, of the 50 available, leaving 40 spaces for customer provided tags)
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
- Following capabilities are available for AWS on standalone and HCP clusters.
- OCP automatically tags the cloud resources with the Cluster's External ID.
- Tags added by default on Day 1 are not affected.
- All existing active AWS resources in the OCP clusters have the tagging changes propagated.
- All new AWS resources created by OCP reflect the changes to tagging.
- Hive to support additional list of key=value strings on MachinePools
- These are AWS user-defined / custom tags, not to be confused with node labels
- ROSA CLI can accept a list of key=value strings with additional tag values
- it currently can do this during cluster-install
- The default tag(s) is/are still applied
- NOTE: AWS limit of 50 tags per object (2 used automatically by OCP; with a third to be added soon; 10 reserved for Red Hat overall, as at least 2-3 are used by Managed Services) - customer's can only specify 40 tags max!
- Must be able to modify tags after creation
- Support for OpenShift 4.15 onwards.
Out-of-scope
This feature will only apply to ROSA with Hosted Control Planes, and ROSA Classic / standalone is excluded.
Why is this important?
- Customers want to use custom tagging for
- access controls
- chargeback/showback
- cloud IAM conditional permissions
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
As a cluster administrator, I want to use Karpenter on an OpenShift cluster running in AWS to scale nodes instead of Cluster Autoscalar(CAS). I want to automatically manage heterogeneous compute resources in my OpenShift cluster without the additional manual task of managing node pools. Additional features I want are:
- Reducing cloud costs through instance selection and scaling/descaling
- Support GPUs, spot instances, mixed compute types and other compute types.
- Automatic node lifecycle management and upgrades
This feature covers the work done to integrate upstream Karpenter 1.x with ROSA HCP. This eliminates the need for manual node pool management while ensuring cost-effective compute selection for workloads. Red Hat manages the node lifecycle and upgrades.
The goal is roll this out with ROSA-HCP (AWS) since it has more mature Karpenter ecosystem, followed by ARO-HCP (Azure) implementation (refer to OCPSTRAT-1498).
This feature will be delivered in 3 Phases:
- Dev Preview: Autonode with HCP (OCPSTRAT-943) – targeting OCP 4.19
- Preview (Tech Preview): Autonode for ROSA-HCP (OCPSTRAT-1946) - TBD (2025)
- GA: Autonode for ROSA-HCP – TBD (2025)
The Dev Preview release will expose AutoNode capabilities on Hosted Control Planes for AWS (note this is not meant to be productized on self-managed OpenShift) as APIs for Managed Services (ROSA) to consume. It includes the following capabilities:
- Service Consumer opts-in to AutoNode on Day 1 and Day 2 (out of scope for Dev Preview)
- Service Provider lifecycles Karpenter management side
- Cluster Admin gains access to Karpenter CRDs and default nodeClass
- Cluster Admin creates a NodePool and scale out workloads
- Service Consumer signals cluster control plane upgrade (TBD for Dev Preview but potentially out of scope for Dev Preview, i.e. may slip to Tech Preview)
- Expose Karpenter metrics to Cluster Admin (out of scope for Dev Preview, Targeting Tech Preview)
Goals (aka. expected user outcomes)
- Run Karpenter in management cluster and disable CAS
- Automate node provisioning in workload cluster
- automate lifecycle management in workload cluster
- Reduce cost in heterogenous compute workloads
- Additional features karpenter
OpenShift AutoNode (a.k.a. Karpenter) Proposal
Requirements (aka. Acceptance Criteria):
As a cluster-admin or SRE I should be able to configure Karpenter with OCP on AWS. Both cli and UI should enable users to configure Karpenter and disable CAS.
- Run Karpenter in management cluster and disable CAS
- OCM API
- Enable/Disable Cluster autoscaler
- Enable/disable AutoNode feature
- New ARN role configuration for Karpenter
- Optional: New managed policy or integration with existing nodepool role permissions
- Expose NodeClass/Nodepool resources to users.
- secure node provisioning and management, machine approval system for Karpenter instances
- HCP Karpenter cleanup/deletion support
- ROSA CAPI fields to enable/disable/configure Karpenter
- Write end-to-end tests for karpenter running on ROSA HCP
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Managed, i.e. ROSA-HCP |
| Classic (standalone cluster) | N/A |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | MNO |
| Connected / Restricted Network | Connected |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86_x64, ARM (aarch64) |
| Operator compatibility | |
| Backport needed (list applicable versions) | No |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | yes - console |
| Other (please specify) | OCM, rosa-cli, ACM, cost management |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
- Self-managed standalone OCP, self-hosted HCP, ROSA classic are out-of-scope.
- Creating a multi-provider cost/pricing operator compatible with CAPI is beyond the scope of this Feature. That may take more time.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
- Karpenter.sh is an open-source node provisioning project built for Kubernetes. It is designed to simplify Kubernetes infrastructure by automatically launching and terminating nodes based on the needs of your workloads. Karpenter can help you to reduce costs, improve performance, and simplify operations.
- Karpenter works by observing the unscheduled pods in your cluster and launching new nodes to accommodate them. Karpenter can also terminate nodes that are no longer needed, which can help you save money on infrastructure costs.
- Karpenter architecture has a Karpenter-core and Karpenter-provider as components.
The core has AWS code which does the resource calculation to reduce the cost by re-provisioning new nodes.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
- Ability to enable AutoNode/Karpenter during installation and post-cluster installation
- Ability to run AutoNode/Karpenter and Cluster Autoscaler at the same time
- Use with an OpenShift cluster with Hosted Control Planes
- CAPI to enable/disable/configure AutoNode/Karpenter
- Have AutoNode/Karpenter perform data plane upgrades
- Designed for FIPS / FIPS compatible
- Enable cost effective mixed compute with auto-provisioning from/to zero
- Provide Karpenter metrics for monitoring and reporting purposes
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
- Migration guides from using CAS to Karpenter
- Performance testing to compare CAS vs Karpenter on ROSA HCP
- API documentation for NodePool and EC2NodeClass configuration
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Goal
- Instances created by karpenter can automatically become Nodes
Why is this important?
- Reduce operational burden.
Scenarios
For CAPI/MAPI driven machine management the cluster-machine-approver uses the machine.status.ips to match the CSRs. In karpenter there's no Machine resources
We'll need to implement something similar. Some ideas:
- Explore using the nodeClaim resource info like status.providerID to match the CSRs
- Store the requesting IP when the ec2 instances query ignition and follow similar comparison criteria than machine approver to match CSRs
- Query AWS to get info and compare info to match CSRs
- ...
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Instances created by karpenter can automatically become Nodes
so that I can achieve
- Reduce operational burden.
Acceptance Criteria:
Description of criteria:
- For CAPI/MAPI driven machine management the cluster-machine-approver uses the machine.status.ips to match the CSRs. In karpenter there's no Machine resources
We'll need to implement something similar. Some ideas:
– Explore using the nodeClaim resource info like status.providerID to match the CSRs
– Store the requesting IP when the ec2 instances query ignition and follow similar comparison criteria than machine approver to match CSRs
– Query AWS to get info and compare info to match CSRs
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a (user persona), I want to be able to:
- Instances created by karpenter can automatically become Nodes
so that I can achieve
- Reduce operational burden.
Acceptance Criteria:
Description of criteria:
https://github.com/openshift/hypershift/pull/5349 introduced a new controller to implement auto approval for kubelet client CSRs. We need to extend to also approve serving CSRs since they are not auto approved by the cluster-machine-approver
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Goal
- Codify and enable usage of a prototype for HCP working with karpetner management side.
Why is this important?
- A first usable version is critical to democratize knowledge and develop internal feedback.
Acceptance Criteria
- Deploying a cluster with --auto-node results in karpenter running management side, the CRDs and a default ec2NodeClass installed within the guest cluster
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Goal
- As a service provider I the cluster admin to only manipulate fields of the nodeclass API that won't impact the service ability to operate, e.g. userdata and ami can't be changed.
- As a service provider I want to be the solely authoritative source of truth to set input that impacts the ability to operate AutoNode.
Why is this important?
- The way we implement this will have UX implications for cluster admin which has direct impact on customer satisfaction.
Scenarios
We decided to start by using validating admission policies to implement ownership of ec2NodeClass fields. So we can restrict fields crud to a particular service account.
This has some caveats:
- If a field that the service own is required in the API, we need to let the cluster admin to set it on creation even though we'll clobber it by reconciling a controller. To mitigate this we might want to change the upstream CEL validations of the ec2NodeClass API
- The raw userdata is exposed to the cluster admin via ec2NodeClass.spec.userdata
- Since we enforce the values for userdata and ami via controller reconciliation there's potential room for race conditions
If using validating policies for this proves to be satisfactory we'll need to consider alternatives, e.g:
- Having an additional dedicated CRD for openshiftnodeclass that translates into the ec2NodeClass and completely prevent the cluster admin from interacting with the latter via vap.
- having our own class similar to eks so we can fully manage the operational input in the backend.
- # ...
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Bring https://issues.redhat.com/browse/CNF-11805 to a GA solution:
- end to end CI with sunny and rainy days scenarios: we want to make sure that the control plane cannot be affected by any workload, ideally, and worse case, clearly document workloads profiles that will put the control plane at risk.
Business justification: request from NEPs and end customers (not listed in the title, please check then tracker links) who do want to have one single type of servers in their clusters, those servers hosting more than 200 CPUs (512 is now common for AMD based servers, and e can expect more in the future). Having 3 servers dedicated just to run control plane is not OPEX neither CAPEX efficient, as 90%+ of the server capacity will never be used. This is even worse for 30 nodes clusters (very common size).
Finally, our HUB clusters (hosting ACM), infrastructure clusters (hosting HCP for instance) are tiny clusters, and the above applies: we cannot require customers to use servers with less than 32 CPUs (for instance).
Phase 1 goals:
Come up with a proposal of what level of isolation and workload limitations (only easy workload? DPDK?) are acceptable on the control plane nodes. In other words, lets take all the easy hanging fruits and see what the platform can do while maintaining control plane stability.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Currently we protect containers from their own mistakes wrt networking by redirecting all network sends to separate CPUs via RPS.
- This is causing load on the reserved / control plane level
- We should stop configuring this protection mechanism by default and only leave it opt-in for emergency purposes.
Why is this important?
- Containers that use kernel networking heavily are causing high cpu load of the reserved (system and control plane) cpus. This affects the stability of the whole node. Our opinion is that containers should pay for the resources they use by their own cpu time.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
BU Priority Overview
To date our work within the telecommunications radio access network space has focused primarily on x86-based solutions. Industry trends around sustainability, and more specific discussions with partners and customers, indicate a desire to progress towards ARM-based solutions with a view to production deployments in roughly a 2025 timeframe. This would mean being able to support one or more RAN partners DU applications on ARM-based servers.
Goals
- Introduce ARM CPUs for RAN DU scenario (SNO deployment) with a feature parity to Intel Ice Lake/SPR-EE/SPR-SP w/o QAT for DU with:
- STD-kernel (RT-Kernel is not supported by RHEL)
- SR-IOV and DPDK over SR-IOV
- PTP (OC, BC). Partner asked for LLS-C3, according to Fujitsu - ptp4l and phy2sys to work with NVIDIA Aerial SDK
- Characterize ARM-based RAN DU solution performance and power metrics (unless performance parameters are specified by partners, we should propose them, see Open questions)
- Productize ARM-based RAN DU solution by 2024 (partner’s expectation).
State of the Business
Depending on source 75-85% of service provider network power consumption is attributable to the RAN sites, with data centers making up the remainder. This means that in the face of increased downward pressure on both TCO and carbon footprint (the former for company performance reasons, the later for regulatory reasons) it is an attractive place to make substantial improvements using economies of scale.
There are currently three main obvious thrusts to how to go about this:
- Introducing tools that improve overall observability w.r.t. power utilization of the network.
- Improvement of existing RAN architectures via smarter orchestration of workloads, fine tuning hardware utilization on a per site basis in response to network usage, etc.
- Introducing alternative architectures which have been designed from the ground up with lower power utilization as a goal.
This BU priority focuses on the third of these approaches.
BoM
- Details per partner in TELCOSTRAT-99 and TELCOSTRAT-210 ARM requirements for DU
- SuperMicro ARS-111GL-NHR
- NVidia GraceHopper CPU
- 2 units of BlueField-3 DPU (in NIC mode)
- Single NUMA
- GPU - 1 NVidia GraceHopper GPU (GH200)
Out of scope
- …
Open questions:
- What are the latency KPIs? Do we need a RT-kernel to meet them?
- What page size is expected?
- What are the performance/throughout requirements?
Reference Documents:
- Softbank AI-RAN PoC Architecture
- Fujitsu vRAN RHOCP Integration
- Red Hat Ecosystem Catalog
- NVIDIA Grace Hopper - Red Hat Ecosystem Catalog (RHEL 9.2 +)
- NVIDIA BlueField-3 200GbE (2x200) - Red Hat Ecosystem Catalog (RHEL 9.4 +)
Epic Goal
The PerformanceProfile currently allows the user to select either the standard kernel (by default) or the realtime kernel, using the realTimeKernel field. However, for some use cases (e.g. Nvidia based ARM server) a kernel with 64k page size is required. This is supported through the MachineConfig kernelType, which currently supports the following options:
- default (standard kernel with 4k pages)
- realtime (realtime kernel with 4k pages)
- 64k-pages (standard kernel with 64k pages)
At some point it is likely that 64k page support will be added to the realtime kernel, which would likely mean another "realtime-64k-pages" option (or similar) would be added.
The purpose of this epic is to allow the 64k-pages (standard kernel with 64k pages) option to be selected in the PerformanceProfile and make it easy to support new kernelTypes added to the MachineConfig. There is a workaround for this today, by applying an additional MachineConfig CR, which overrides the kernelType, but this is awkward for the user.
One option to support this in the PerformanceProfile would be to deprecate the existing realTimeKernel option and replace it with a new kernelType option. The kernelType option would support the same values as the MachineConfig kernelType (i.e. default, realtime, 64k-pages). The old option could be supported for backwards compatibility - attempting to use both options at the same time would be treated as an error. Another option would be to add a new kernelPageSize option (with values like default or 64k) and then internally map that to the MachineConfig kernelType (after validation that the combination of kernel type and page size was allowed).
This will require updates to the customer documentation and to the performance-profile-creator to support the new option.
This will also might require updates to the workloadhints kernel related sections.
Why is this important?
- This makes it easier for the user to select the kernel page size.
Scenarios
- User wants to use standard kernel with default page size (4k).
- User wants to use standard kernel with 64k page size.
- User wants to use realtime kernel with default page size (4k).
- Future: user wants to use realtime kernel with 64k page size.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- N/A
Previous Work (Optional):
- N/A
Open questions::
- Need to decide the best option for specifying the kernel type and kernel page size in the PerformanceProfile.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
https://docs.kernel.org/mm/vmemmap_dedup.html
Reading this doc, we can see a mapping of kernel page size and hugepages support.
We want to enforce that the combination of hugepages and kernelPageSize entered by the users in the performance profile is valid (done by validation webhook).
Acceptance criteria:
- Introduce a new kernelPageSize field to the performance profile API:
for x86/amd64, the only valid value is 4K, while for aarch64, the valid values are 4K, 64K. - Adding this to performance-profile.md doc.
- A smart validation should be integrated into the validation webhook:
64k should be used only on aarch64 nodes and is currently supported with a no real-time kernel. Moreover, we should check for invalid inputs on both arch systems. - The default value is 4K if none is specified.
- Modifying the kernel Type selection process, adding the new kernel type 64k-pages alongside default and realtime.
- Verification on an ARM cluster.
PERSONAS:
The following personas are borrowed from Hypershift docs used in the user stories below.
- Cluster service consumer: The user empowered to request control planes, request workers, and drive upgrades or modify externalized configuration. Likely not empowered to manage or access cloud credentials or infrastructure encryption keys. In the case of managed services, this is someone employed by the customer.
- Cluster service provider: The user hosting cluster control planes, responsible for up-time. UI for fleet wide alerts, configuring AWS account to host control planes in, user provisioned infra (host awareness of available compute), where to pull VMs from. Has cluster admin management. In the case of managed services, this persona represents Red Hat SRE.
USER STORY:
- As a cluster service consumer, I want to provision hosted control planes and clusters without the Image Registry, so that my hosted clusters do not contain resources from a component I do not use, such as workloads, storage accounts, pull-secrets, etc, which allows me to save on computing resources
- As a cluster service provider, I want users to be able to disable the Image Registry so that I don't need to maintain hosted control plane components that users don't care about.
ACCEPTANCE CRITERIA:
What is "done", and how do we measure it? You might need to duplicate this a few times.
Given a
When b
Then c
CUSTOMER EXPERIENCE:
Only fill this out for Product Management / customer-driven work. Otherwise, delete it.
- Does this feature require customer facing documentation? YES/NO
- If yes, provide the link once available
- Does this feature need to be communicated with the customer? YES/NO
-
- How far in advance does the customer need to be notified?
- Ensure PM signoff that communications for enabling this feature are complete
-
- Does this feature require a feature enablement run (i.e. feature flags update) YES/NO
- If YES, what feature flags need to change?
- FLAG1=valueA
- If YES, is it safe to bundle this feature enablement with other feature enablement tasks? YES/NO
- If YES, what feature flags need to change?
BREADCRUMBS:
Where can SREs look for additional information? Mark with "N/A" if these items do not exist yet so Functional Teams know they need to create them.
- ADR: a
- Design Doc: b
- Wiki: c
- Similar Work PRs: d
- Subject Matter Experts: e
- PRD: f
NOTES:
If there's anything else to add.
User Story
To reconcile capabilities at runtime correctly, we need to constantly reconcile the CVO capabilities in the HostedClusterConfigOperator.
This was introduced in https://github.com/openshift/hypershift/pull/1687 and causes the capabilities to reset after being set initially after the installation.
This logic needs to take into account the enabled/disabled state of the image registry and the desired state of the hypershift control plane config CRD to render the capabilities correctly.
Ref from ARO-13685 where this was simply removed: https://github.com/openshift/hypershift/pull/5315/files#diff-c888020c5dc46c458d818b931db97131d6e35b90661fe1030a39ebeac8859b19L1224
Definition of Done
Mark with an X when done; strikethrough for non-applicable items. All items
must be considered before closing this issue.
[ ] Ensure all pull request (PR) checks, including ci & e2e, are passing
[ ] Document manual test steps and results
[ ] Manual test steps executed by someone other than the primary implementer or a test artifact such as a recording are attached
[ ] All PRs are merged
[ ] Ensure necessary actions to take during this change's release are communicated and documented
[ ] Troubleshooting Guides (TSGs), ADRs, or other documents are updated as necessary
User Story
When the cluster is installed and configured, the CVO container has init containers that apply the initial CRDs and remove some manifests from CVO.
Depending on the configuration state of the image registry, it needs to remove or keep the capability as enabled. The bootstrap init container needs to set the initial capabilities as AdditionalEnabledCapabilities and the BaselineCapabilities as None.
Note there is a gotcha on the ordering of the capabilities, they always need to be sorted ascending for the API to accept them - otherwise they are silently ignored.
Note, we need to implement the same change in V1 and V2 of the operator:
1.
2.
XREF implementation from ARO-13685: https://github.com/openshift/hypershift/pull/5315/files#diff-520b6ecfad21e6c9bc0cbf244ff694cf5296ffc8c0318cb2248eb7185a36cd8aR363-R366
Definition of Done
Mark with an X when done; strikethrough for non-applicable items. All items
must be considered before closing this issue.
[ ] Ensure all pull request (PR) checks, including ci & e2e, are passing
[ ] Document manual test steps and results
[ ] Manual test steps executed by someone other than the primary implementer or a test artifact such as a recording are attached
[ ] All PRs are merged
[ ] Ensure necessary actions to take during this change's release are communicated and documented
[ ] Troubleshooting Guides (TSGs), ADRs, or other documents are updated as necessary
User Story
Currently the ImagePolicyConfig has the internal image registry url hardcoded
When the image registry is disabled, we need to ensure that this is properly accounted for, as the registry won't be reachable under this address anymore.
Definition of Done
Mark with an X when done; strikethrough for non-applicable items. All items
must be considered before closing this issue.
[ ] Ensure all pull request (PR) checks, including ci & e2e, are passing
[ ] Document manual test steps and results
[ ] Manual test steps executed by someone other than the primary implementer or a test artifact such as a recording are attached
[ ] All PRs are merged
[ ] Ensure necessary actions to take during this change's release are communicated and documented
[ ] Troubleshooting Guides (TSGs), ADRs, or other documents are updated as necessary
Enhancement https://github.com/openshift/enhancements/pull/1729
We want to add the disabled capabilities to the hosted cluster CRD as described in the above enhancement.
AC:
- Updated API is merged in the Hypershift repo
- Updated API can be consumed from cluster service and follow-up tasks in this epic
{kind=link}