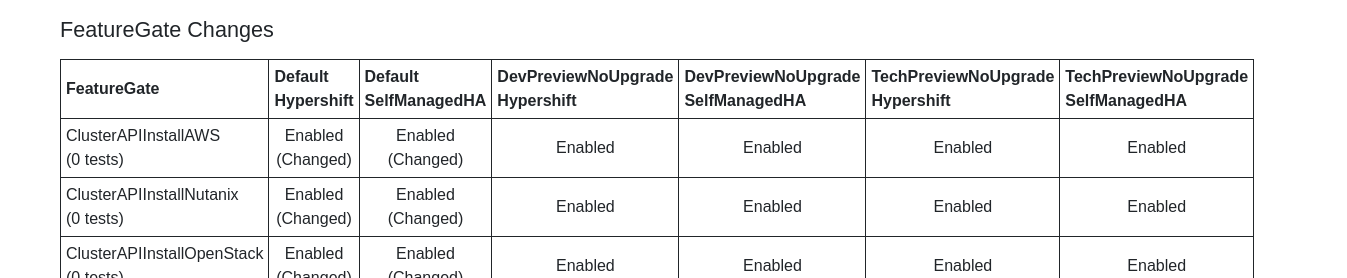
Complete Features
These features were completed when this image was assembled
This outcome tracks the overall CoreOS Layering story as well as the technical items needed to converge CoreOS with RHEL image mode. This will provide operational consistency across the platforms.
ROADMAP for this Outcome: https://docs.google.com/document/d/1K5uwO1NWX_iS_la_fLAFJs_UtyERG32tdt-hLQM8Ow8/edit?usp=sharing
This work describes the tech preview state of On Cluster Builds. Major interfaces should be agreed upon at the end of this state.
Description of problem:
When we activate the on-cluster-build functionality in a pool with yum based RHEL nodes, the pool is degraded reporting this error:
- lastTransitionTime: "2023-09-20T15:14:44Z"
message: 'Node ip-10-0-57-169.us-east-2.compute.internal is reporting: "error
running rpm-ostree --version: exec: \"rpm-ostree\": executable file not found
in $PATH"'
reason: 1 nodes are reporting degraded status on sync
status: "True"
type: NodeDegraded
Version-Release number of selected component (if applicable):
4.14.0-0.nightly-2023-09-15-233408
How reproducible:
Always
Steps to Reproduce:
1. Create a cluster and add a yum based RHEL node to the worker pool
(we used RHEL8)
2. Create the necessary resources to enable the OCB functionality. Pull and push secrets and the on-cluster-build-config configmap.
For example we can use this if we want to use the internal registry:
cat << EOF | oc create -f -
apiVersion: v1
data:
baseImagePullSecretName: $(oc get secret -n openshift-config pull-secret -o json | jq "del(.metadata.namespace, .metadata.creationTimestamp, .metadata.resourceVersion, .metadata.uid, .metadata.name)" | jq '.metadata.name="pull-copy"' | oc -n openshift-machine-config-operator create -f - &> /dev/null; echo -n "pull-copy")
finalImagePushSecretName: $(oc get -n openshift-machine-config-operator sa builder -ojsonpath='{.secrets[0].name}')
finalImagePullspec: "image-registry.openshift-image-registry.svc:5000/openshift-machine-config-operator/ocb-image"
imageBuilderType: ""
kind: ConfigMap
metadata:
name: on-cluster-build-config
namespace: openshift-machine-config-operator
EOF
The configuration doesn't matter as long as the OCB functionality can work.
3. Label the worker pool so that the OCB functionality is enabled
$ oc label mcp/worker machineconfiguration.openshift.io/layering-enabled=
Actual results:
The RHEL node shows this log:
I0920 15:14:42.852742 1979 daemon.go:760] Preflight config drift check successful (took 17.527225ms)
I0920 15:14:42.852763 1979 daemon.go:2150] Performing layered OS update
I0920 15:14:42.868723 1979 update.go:1970] Starting transition to "image-registry.openshift-image-registry.svc:5000/openshift-machine-config-operator/tc-67566@sha256:24ea4b12acf93095732ba457fc3e8c7f1287b669f2aceec65a33a41f7e8ceb01"
I0920 15:14:42.871625 1979 update.go:1970] drain is already completed on this node
I0920 15:14:42.874305 1979 rpm-ostree.go:307] Running captured: rpm-ostree --version
E0920 15:14:42.874388 1979 writer.go:226] Marking Degraded due to: error running rpm-ostree --version: exec: "rpm-ostree": executable file not found in $PATH
I0920 15:15:37.570503 1979 daemon.go:670] Transitioned from state: Working -> Degraded
I0920 15:15:37.570529 1979 daemon.go:673] Transitioned from degraded/unreconcilable reason -> error running rpm-ostree --version: exec: "rpm-ostree": executable file not found in $PATH
I0920 15:15:37.574942 1979 daemon.go:2300] Not booted into a CoreOS variant, ignoring target OSImageURL quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:e3128a8e42fb70ab6fc276f7005e3c0839795e4455823c8ff3eca9b1050798b9
I0920 15:15:37.591529 1979 daemon.go:760] Preflight config drift check successful (took 16.588912ms)
I0920 15:15:37.591549 1979 daemon.go:2150] Performing layered OS update
I0920 15:15:37.591562 1979 update.go:1970] Starting transition to "image-registry.openshift-image-registry.svc:5000/openshift-machine-config-operator/tc-67566@sha256:24ea4b12acf93095732ba457fc3e8c7f1287b669f2aceec65a33a41f7e8ceb01"
I0920 15:15:37.594534 1979 update.go:1970] drain is already completed on this node
I0920 15:15:37.597261 1979 rpm-ostree.go:307] Running captured: rpm-ostree --version
E0920 15:15:37.597315 1979 writer.go:226] Marking Degraded due to: error running rpm-ostree --version: exec: "rpm-ostree": executable file not found in $PATH
qI0920 15:16:37.613270 1979 daemon.go:2300] Not booted into a CoreOS variant, ignoring target OSImageURL quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:e3128a8e42fb70ab6fc276f7005e3c0839795e4455823c8ff3eca9b1050798b9
And the worker pool is degraded with this error:
- lastTransitionTime: "2023-09-20T15:14:44Z"
message: 'Node ip-10-0-57-169.us-east-2.compute.internal is reporting: "error
running rpm-ostree --version: exec: \"rpm-ostree\": executable file not found
in $PATH"'
reason: 1 nodes are reporting degraded status on sync
status: "True"
type: NodeDegraded
Expected results:
The pool should not be degraded.
Additional info:
Note: phase 2 target is tech preview.
Feature Overview
In the initial delivery of CoreOS Layering, it is required that administrators provide their own build environment to customize RHCOS images. That could be a traditional RHEL environment or potentially an enterprising administrator with some knowledge of OCP Builds could set theirs up on-cluster.
The primary virtue of an on-cluster build path is to continue using the cluster to manage the cluster. No external dependency, batteries-included.
On-cluster, automated RHCOS Layering builds are important for multiple reasons:
- One-click/one-command upgrades of OCP are very popular. Many customers may want to make one or just a few customizations but also want to keep that simplified upgrade experience.
- Customers who only need to customize RHCOS temporarily (hotfix, driver test package, etc) will find off-cluster builds to be too much friction for one driver.
- One of OCP's virtues is that the platform and OS are developed, tested, and versioned together. Off-cluster building breaks that connection and leaves it up to the user to keep the OS up-to-date with the platform containers. We must make it easy for customers to add what they need and keep the OS image matched to the platform containers.
Goals & Requirements
- The goal of this feature is primarily to bring the 4.14 progress (
OCPSTRAT-35) to a Tech Preview or GA level of support. - Customers should be able to specify a Containerfile with their customizations and "forget it" as long as the automated builds succeed. If they fail, the admin should be alerted and pointed to the logs from the failed build.
- The admin should then be able to correct the build and resume the upgrade.
- Intersect with the Custom Boot Images such that a required custom software component can be present on every boot of every node throughout the installation process including the bootstrap node sequence (example: out-of-box storage driver needed for root disk).
- Users can return a pool to an unmodified image easily.
- RHEL entitlements should be wired in or at least simple to set up (once).
- Parity with current features – including the current drain/reboot suppression list, CoreOS Extensions, and config drift monitoring.
The goal of this effort is to leverage OVN Kubernetes SDN to satisfy networking requirements of both traditional and modern virtualization. This Feature describes the envisioned outcome and tracks its implementation.
Current state
In its current state, OpenShift Virtualization provides a flexible toolset allowing customers to connect VMs to the physical network. It also has limited secondary overlay network capabilities and Pod network support.
It suffers from several gaps: Topology of the default pod network is not suitable for typical VM workload - due to that we are missing out on many of the advanced capabilities of OpenShift networking, and we also don't have a good solution for public cloud. Another problem is that while we provide plenty of tools to build a network solution, we are not very good in guiding cluster administrators configuring their network, making them rely on their account team.
Desired outcome
Provide:
- Networking solution for public cloud
- Advanced SDN networking functionality such as IPAM, routed ingress, DNS and cloud-native integration
- Ability to host traditional VM workload imported from other virtualization platforms
... while maintaining networking expectations of a typical VM workload:
- Sticky IPs allowing seamless live migration
- External IP reflected inside the guest, i.e. no NAT for east-west traffic
Additionally, make our networking configuration more accessible to newcomers by providing a finite list of user stories mapped to recommended solutions.
User stories
You can find more info about this effort in https://docs.google.com/document/d/1jNr0E0YMIHsHu-aJ4uB2YjNY00L9TpzZJNWf3LxRsKY/edit
Goal
Provide IPAM to customers connecting VMs to OVN Kubernetes secondary networks.
User Stories
- As a developer running VMs,
I want to offload IPAM to somebody else,
so I don't need to manage my own IP pools, DHCP server, or static IP configuration.
Non-Requirements
- IPv6 support is not required.
Notes
- KubeVirt cannot support CNI IPAM. For that reason we cannot utilize the current implementation of IP management in OVN Kubernetes
- OVN supports IPAM, where an IP range is defined per port, and the port then offers assigned IP to the client using DHCP. We can use this
Done Checklist
| Who | What | Reference |
|---|---|---|
| DEV | Upstream roadmap issue | <link to GitHub Issue> |
| DEV | Upstream code and tests merged | <link to meaningful PR> |
| DEV | Upstream documentation merged | <link to meaningful PR> |
| DEV | gap doc updated | <name sheet and cell> |
| DEV | Upgrade consideration | <link to upgrade-related test or design doc> |
| DEV | CEE/PX summary presentation | label epic with cee-training and add a <link to your support-facing preso> |
| QE | Test plans in Polarion | https://polarion.engineering.redhat.com/polarion/#/project/CNV/workitem?id=CNV-10864 |
| QE | Automated tests merged | <link or reference to automated tests> |
| DOC | Downstream documentation merged | <link to meaningful PR> |
Add a knob to CNO to control the installation of the IPAMClaim CRD.
Requires a new OpenShift feature gate only allowing the feature to be installed in Dev / Tech preview.
Placeholder feature for ccx-ocp-core maintenance tasks.
This is epic tracks "business as usual" requirements / enhancements / bug fixing of Insights Operator.
Description of problem:
InsightsRecommendationActive firing, description link results in "Invalid parameter: redirect_uri" on sso.redhat.com. Insights recommendation "OpenShift cluster with more or less than 3 control plane node replicas is not supported by Red Hat" with total risk "Moderate" was detected on the cluster. More information is available at https://console.redhat.com/openshift/insights/advisor/clusters/<UID>?first=ccx_rules_ocp.external.rules.control_plane_replicas|CONTROL_PLANE_NODE_REPLICAS.
Version-Release number of selected component (if applicable):
4.15.14
How reproducible:
unknown
Steps to Reproduce:
1. Install 4.15.14 on a cluster that triggers this alert 2. Log out of Red Hat SSO 3. Clink link in alert description
Actual results:
"Invalid parameter: redirect_uri" on sso.redhat.com
Expected results:
Link successfully navigates through SSO
Additional info:
Description of problem:
We have a test test_cluster_base_domain_obfuscation that checks that when we set the insights-config configmap with the obfuscation parameter set to "networking", we expect the archive to not have instance of the api_url or the base_hostname of the cluster. This is currently not happening in hypershift hosted clusters.
Version-Release number of selected component (if applicable):
How reproducible:
Always
Steps to Reproduce:
1. Run test_cluster_base_domain_obfuscation
Or
1. Create insights_config configmap in the openshift-insights namespace, with
dataReporting:
obfuscation: Networking
2. wait until the obfuscation creation table exists
3. Download the archive
4. Check every path in the archive and search for instances of the api_url or the base_hostname (easier to do with automation than manually)
Actual results:
Instances are found.
Expected results:
No instances are found since they've all been obfuscated.
Additional info:
This is epic tracks "business as usual" requirements / enhancements / bug fixing of Insights Operator.
Description of problem:
Insights operator should replaces %s in https://console.redhat.com/api/gathering/v2/%s/gathering_rules error messages like the failed-to-bootstrap:
$ jq -r .content osd-ccs-gcp-ad-install.log | sed 's/\\n/\n/g' | grep 'Cluster operator insights'
time="2024-09-05T08:12:51Z" level=info msg="Cluster operator insights ClusterTransferAvailable is False with Unauthorized: failed to pull cluster transfer: OCM API https://api.openshift.com/api/accounts_mgmt/v1/cluster_transfers/?search=cluster_uuid+is+%REDACTED%27+and+status+is+%27accepted%27 returned HTTP 401: REDACTED"
time="2024-09-05T08:12:51Z" level=info msg="Cluster operator insights Disabled is False with AsExpected: "
time="2024-09-05T08:12:51Z" level=info msg="Cluster operator insights RemoteConfigurationAvailable is False with HttpStatus401: received HTTP 401 Unauthorized from https://console.redhat.com/api/gathering/v2/%s/gathering_rules"
time="2024-09-05T08:12:51Z" level=info msg="Cluster operator insights RemoteConfigurationValid is Unknown with NoValidationYet: "
time="2024-09-05T08:12:51Z" level=info msg="Cluster operator insights SCAAvailable is False with Unauthorized: Failed to pull SCA certs from https://api.openshift.com/api/accounts_mgmt/v1/certificates: OCM API https://api.openshift.com/api/accounts_mgmt/v1/certificates returned HTTP 401: REDACTED
level=info msg=Cluster operator insights ClusterTransferAvailable is False with Unauthorized: failed to pull cluster transfer: OCM API https://api.openshift.com/api/accounts_mgmt/v1/cluster_transfers/?search=cluster_uuid+is+%27REDACTED%27+and+status+is+%27accepted%27 returned HTTP 401: REDACTED
level=info msg=Cluster operator insights Disabled is False with AsExpected:
level=info msg=Cluster operator insights RemoteConfigurationAvailable is False with HttpStatus401: received HTTP 401 Unauthorized from https://console.redhat.com/api/gathering/v2/%s/gathering_rules
level=info msg=Cluster operator insights RemoteConfigurationValid is Unknown with NoValidationYet:
level=info msg=Cluster operator insights SCAAvailable is False with Unauthorized: Failed to pull SCA certs from https://api.openshift.com/api/accounts_mgmt/v1/certificates: OCM API https://api.openshift.com/api/accounts_mgmt/v1/certificates returned HTTP 401: REDACTED
level=info msg=Cluster operator insights UploadDegraded is True with NotAuthorized: Reporting was not allowed: your Red Hat account is not enabled for remote support or your token has expired: {\"errors\":[{\"meta\":{\"response_by\":\"gateway\"},\"detail\":\"UHC services authentication failed\",\"status\":401}]}
Version-Release number of selected component
Seen in 4.17 RCs. Also in this comment.
How reproducible
Unknown
Steps to Reproduce:
Unknown.
Actual results:
ClusterOperator conditions talking about https://console.redhat.com/api/gathering/v2/%s/gathering_rules
Expected results
URIs we expose in customer-oriented messaging to not have %s placeholders.
Additional detail
Seems like the template is coming in as conditionalGathererEndpoint here. Seems like insights-operator#964 introduced the %s, but I'm not finding the logic that's supposed to populate that placeholder.
Rapid recommendations enhancement defines this built-in configuration when the operator cannot reach the remote endpoint.
The issue is that the built-in configuration (though currently empty) is no taken into account - i.e the data requested in the built-configuration is not gathered.
Goal:
Track Insights Operator Data Enhancements epic in 2024
INSIGHTOCP-1557 is a rule to check for any custom Prometheus instances that may impact the management of corresponding resources.
Resource to gather: Prometheus and Alertmanager in all namespaces
apiVersion: monitoring.coreos.com/v1 kind: Prometheus
apiVersion: monitoring.coreos.com/v1 kind: Alertmanager
Backport: OCP 4.12.z; 4.13.z; 4.14.z; 4.15.z
Additional info:
1) Get the Prometheus and Alertmanager in all namespaces
$ oc get prometheus -A NAMESPACE NAME VERSION DESIRED READY RECONCILED AVAILABLE AGE openshift-monitoring k8s 2.39.1 2 1 True Degraded 712d test custom-prometheus 1 0 True False 25d
$ oc get alertmanager -A NAMESPACE NAME VERSION DESIRED READY RECONCILED AVAILABLE AGE openshift-monitoring main 2.39.1 2 1 True Degraded 712d test custom-alertmanager 1 0 True False 25d
Business required:
We had a recommendation to check the certificate of the default ingress controller expiration after it has expired. From the referenced KCS, it seems that many customers(hundreds) hit this issue. So, Oscar Arribas Arribas suggests that if we can have a recommendation to alert customers before certificate expiration.
Gathering method:
1. Gather all the ingresscontroller objects(we already gathered the default ingresscontroller) with commands:
oc get ingresscontrollers -n openshift-ingress-operator
2. Gather operator auto-generated certificate's validate dates with commands:
$ oc get ingresscontrollers -n openshift-ingress-operator -o yaml | grep -A1 defaultCertificate #### empty output here when certificate created by the operator
$ oc get secret router-ca -n openshift-ingress-operator -o yaml | grep crt | awk '{print $2}' | base64 -d | openssl x509 -noout -dates
notBefore=Dec 28 00:00:00 2022 GMT
notAfter=Jan 22 23:59:59 2024 GMT
$ oc get secret router-certs-default -n openshift-ingress -o yaml | grep crt | awk '{print $2}' | base64 -d | openssl x509 -noout -dates
notBefore=Dec 28 00:00:00 2022 GMT
notAfter=Jan 22 23:59:59 2024 GMT
3. Gather custom certificates' validate dates with commands:
$ oc get ingresscontrollers -n openshift-ingress-operator -o yaml | grep -A1 defaultCertificate
defaultCertificate:
name: [custom-cert-secret-1]
#### for each [custom-cert-secret] above
$ oc get secret [custom-cert-secret-1] -n openshift-ingress -o yaml | grep crt | awk '{print $2}' | base64 -d | openssl x509 -noout -dates
notBefore=Dec 28 00:00:00 2022 GMT
notAfter=Jan 22 23:59:59 2024 GMT
Other Information:
An RFE to create a cluster alert is under reveiwing: https://issues.redhat.com/browse/RFE-4269
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision PowerVS infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The PowerVS IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing PowerVS Terraform provider. Specifically, we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- ...
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Customer has escalated the following issues where ports don't have TLS support. This Feature request lists all the components port raised by the customer.
Details here https://docs.google.com/document/d/1zB9vUGB83xlQnoM-ToLUEBtEGszQrC7u-hmhCnrhuXM/edit
Currently, we are serving the metrics as http on 9537 we need to upgrade to use TLS
Related to https://docs.google.com/document/d/1zB9vUGB83xlQnoM-ToLUEBtEGszQrC7u-hmhCnrhuXM/edit
Phase 2 Deliverable:
GA support for a generic interface for administrators to define custom reboot/drain suppression rules.
Epic Goal
- Allow administrators to define which machineconfigs won't cause a drain and/or reboot.
- Allow administrators to define which ImageContentSourcePolicy/ImageTagMirrorSet/ImageDigestMirrorSet won't cause a drain and/or reboot
- Allow administrators to define alternate actions (typically restarting a system daemon) to take instead.
- Possibly (pending discussion) add switch that allows the administrator to choose to kexec "restart" instead of a full hw reset via reboot.
Why is this important?
- There is a demonstrated need from customer cluster administrators to push configuration settings and restart system services without restarting each node in the cluster.
- Customers are modifying ICSP/ITMS/IDMS outside post day 1/adding them+
- (kexec - we are not committed on this point yet) Server class hardware with various add-in cards can take 10 minutes or longer in BIOS/POST. Skipping this step would dramatically speed-up bare metal rollouts to the point that upgrades would proceed about as fast as cloud deployments. The downside is potential problems with hardware and driver support, in-flight DMA operations, and other unexpected behavior. OEMs and ODMs may or may not support their customers with this path.
Scenarios
- As a cluster admin, I want to reconfigure sudo without disrupting workloads.
- As a cluster admin, I want to update or reconfigure sshd and reload the service without disrupting workloads.
- As a cluster admin, I want to remove mirroring rules from an ICSP, ITMS, IDMS object without disrupting workloads because the scenario in which this might lead to non-pullable images at a undefined later point in time doesn't apply to me.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Follow up epic to https://issues.redhat.com/browse/MCO-507, aiming to graduate the feature from tech preview and GA'ing the functionality.
For tech preview we only allow files/units/etc. There are two potential use cases for directories:
- namespaced image policy objects
- hostname based networking policies
Which would allow the MCO to generally allow anything under a path to apply the policy. We should adapt the API and MCO logic to also allow paths.
Add e2e tests that fit the guidelines mentioned in the openshift/api docs https://github.com/openshift/api/blob/master/README.md#defining-featuregate-e2e-tests
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision OpenShift on the existing supported providers' infrastructure without the use of Terraform.
This feature will be used to track all the CAPI preparation work that is common for all the supported providers
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
- Day 0 Cluster Provisioning
- Compatibility with existing workflows that do not require a container runtime on the host
Why is this important?
- This epic would maintain compatibility with existing customer workflows that do not have access to a management cluster and do not have the dependency of a container runtime
Scenarios
- openshift-install running in customer automation
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
This feature is about providing workloads within an HCP KubeVirt cluster access to gpu devices. This is an important use case that expands usage of HCP KubeVirt to AL and ML workloads.
Goals (aka. expected user outcomes)
- Users can assign GPUs to HCP KubeVirt worker nodes using NodePool API
Requirements (aka. Acceptance Criteria):
- Expose the ability to assign GPUS to kubevirt NodePools
- Ensure nvidia supports the nvidia gpu operator on hcp kubevirt
- document usage and support of nvidia gpus with hcp kubevirt
- CI environment and tests to verify gpu assignment to kubevirt nodepools functions
GOAL:
Support running workloads within HCP KubeVirt clusters which need access to GPUs.
Accomplishing this involves multiple efforts
- The NodePool API must be expanded to allow assignment of GPUs to the KubeVirt worker node VMs.
- ensure nvidia operator works within the HCP cluster for gpus passed through to KubeVirt VMs
- Develop a CI environment which allows us to exercise gpu passthrough.
Diagram of multiple nvidia operator layers
https://docs.google.com/document/d/1HwXVL_r9tUUwqDct8pl7Zz4bhSRBidwvWX54xqXaBwk/edit
1. Design and implement an API at the NodePool (platform.kubevirt) that will allow exposing GPU passthrough or vGPU slicing from the infra cluster to the guest cluster.
2. Implement logic that sets up the GPU resources to be available to the guest cluster's workloads (by using nvidia-gpu-operator?)
Feature Overview (aka. Goal Summary)
Currently the maximum number of snapshots per volume in vSphere CSI is set to 3 and cannot be configured. Customers find this default limit too low and are asking us to make this setting configurable.
Maximum number of snapshot is 32 per volume
Goals (aka. expected user outcomes)
Customers can override the default (three) value and set it to a custom value.
Make sure we document (or link) the VMWare recommendations in terms of performances.
https://kb.vmware.com/s/article/1025279
Requirements (aka. Acceptance Criteria):
The setting can be easily configurable by the OCP admin and the configuration is automatically updated. Test that the setting is indeed applied and the maximum number of snapshots per volume is indeed changed.
No change in the default
Use Cases (Optional):
As an OCP admin I would like to change the maximum number of snapshots per volumes.
Out of Scope
Anything outside of
Background
The default value can't be overwritten, reconciliation prevents it.
Customer Considerations
Make sure the customers understand the impact of increasing the number of snapshots per volume.
https://kb.vmware.com/s/article/1025279
Documentation Considerations
Document how to change the value as well as a link to the best practice. Mention that there is a 32 hard limit. Document other limitations if any.
Interoperability Considerations
N/A
Epic Goal*
The goal of this epic is to allow admins to configure the maximum number of snapshots per volume in vSphere CSI and find an way how to add such extension to OCP API.
Possible future candidates:
- configure EFS volume size monitioring (via driver cmdline arg.) -
STOR-1422 - configure OpenStack topology -
RFE-11
Why is this important? (mandatory)
Currently the maximum number of snapshots per volume in vSphere CSI is set to 3 and cannot be configured. Customers find this default limit too low and are asking us to make this setting configurable.
Maximum number of snapshot is 32 per volume
https://kb.vmware.com/s/article/1025279
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- As an admin I would like to configure the maximum number of snapshots per volume.
- As a user I would like to create more than 3 snapshots per volume
Dependencies (internal and external) (mandatory)
1) Write OpenShift enhancement (STOR-1759)
2) Extend ClusterCSIDriver API (TechPreview) (STOR-1803)
3) Update vSphere operator to use the new snapshot options (STOR-1804)
4) Promote feature from Tech Preview to Accessible-by-default (STOR-1839)
- prerequisite: add e2e test and demonstrate stability in CI (
STOR-1838)
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - STOR
- Documentation - STOR
- QE - STOR
- PX - Enablement
- Others -
Acceptance Criteria (optional)
Configure the maximum number of snapshot to a higher value. Check the config has been updated and verify that the maximum number of snapshots per volume maps to the new setting value.
Drawbacks or Risk (optional)
Setting this config setting with a high value can introduce performances issues. This needs to be documented.
https://kb.vmware.com/s/article/1025279
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Feature Overview (aka. Goal Summary)
The etc-ca must be rotatable both on-demand and automatically when expiry approaches.
Goals (aka. expected user outcomes)
- Have a tested path for customers to rotate certs manually
- We must have a tested path for auto rotation of certificates when certs need rotation due to age
Requirements (aka. Acceptance Criteria):
Deliver rotation and recovery requirements from OCPSTRAT-714
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Feature Overview (aka. Goal Summary)
As cluster admin I would like to configure machinesets to allocate instances from pre-existing Capacity Reservation in Azure.
I want to create a pool of reserved resources that can be shared between clusters of different teams based on their priorities. I want this pool of resources to remain available for my company and not get allocated to another Azure customer.
Additional background on the feature for considering additional use cases
- Proposed title of this feature request
Machine API support for Azure Capacity Reservation Groups
- What is the nature and description of the request?
The customer would like to configure machinesets to allocate instances from pre-existing Capacity Reservation Groups, see Azure docs below
- Why does the customer need this? (List the business requirements here)
This would allow the customer to create a pool of reserved resources which can be shared between clusters of different priorities. Imagine a test and prod cluster where the demands of the prod cluster suddenly grow. The test cluster is scaled down freeing resources and the prod cluster is scaled up with assurances that those resources remain available, not allocated to another Azure customer.
- List any affected packages or components.
MAPI/CAPI Azure
In this use case, there's no immediate need for install time support to designate reserved capacity group for control plane resources, however we should consider whether that's desirable from a completeness standpoint. We should also consider whether or not this should be added as an attribute for the installconfig compute machinepool or whether altering generated MachineSet manifests is sufficient, this appears to be a relatively new Azure feature which may or may not see wider customer demand. This customer's primary use case is centered around scaling up and down existing clusters, however others may have different uses for this feature.
Additional background on the feature for considering additional use cases
User Story
As a developer I want to add the field "CapacityReservationGroupID" to "AzureMachineProviderSpec" in openshift/api so that Azure capacity reservation can be supported.
Background
CFE-1036 adds the support of Capacity Reservation in upstream CAPZ (PR). The same support is needed to be added downstream also. Please refer the upstream PR for adding support downstream.
Slack discussion regarding the same: https://redhat-internal.slack.com/archives/CBZHF4DHC/p1713249202780119?thread_ts=1712582367.529309&cid=CBZHF4DHC_
Steps
- Add the field "CapacityReservationGroupID" to "AzureMachineProviderSpec"
- The new field should be immutable. Add validations for the same.
- Add tests to validate the immutability.
Stakeholders
- Cluster Infra
- CFE
Definition of Done
- The PR should be reviewed and approved.
- Docs
- Add appropriate godoc for the field explaining its purpose
- Testing
- Add tests to validate the immutability.
Update the vendor to update in cluster-control-plane-machine-set-operator repository for capacity reservation Changes.
User Story
As a developer I want to add support of capacity reservation group in openshift/machine-api-provider-azure so that azure VMs can be associated to a capacity reservation group during the VM creation.
Background
CFE-1036 adds the support of Capacity Reservation in upstream CAPZ (PR). The same support is needed to be added downstream also. Please refer the upstream PR for adding support downstream.
Steps
- Import the latest API changes from openshift/api to get the new field "CapacityReservationGroupID" into openshift/machine-api-provider-azure.
- If a value is assigned to the field then use for associated a VM to the capacity reservation group during VM creation.
Stakeholders
- Cluster Infra
- CFE
Definition of Done
- The PR should be reviewed and approved.
- Testing
- Add unit tests to validate the implementation.
As a developer I want to add the webhook validation for the "CapacityReservationGroupID" field of "AzureMachineProviderSpec" in openshift/machine-api-operator so that Azure capacity reservation can be supported.
Background
CFE-1036 adds the support of Capacity Reservation in upstream CAPZ (PR). The same support is needed to be added downstream also. Please refer the upstream PR for adding support downstream.
Slack discussion regarding the same: https://redhat-internal.slack.com/archives/CBZHF4DHC/p1713249202780119?thread_ts=1712582367.529309&cid=CBZHF4DHC_
Steps
- Add the validation for "CapacityReservationGroupID" to "AzureMachineProviderSpec"
- Add tests to validate.
Stakeholders
- Cluster Infra
- CFE
Feature Overview (aka. Goal Summary)
Add support for standalone secondary networks for HCP kubevirt.
Advanced multus integration involves the following scenarios
1. Secondary network as single interface for VM
2. Multiple Secondary Networks as multiple interfaces for VM
Goals (aka. expected user outcomes)
Users of HCP KubeVirt should be able to create a guest cluster that is completely isolated on a secondary network outside of the default pod network.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
<enter general Feature acceptance here>
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | self-managed |
| Classic (standalone cluster) | na |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | na |
| Connected / Restricted Network | yes |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86 |
| Operator compatibility | na |
| Backport needed (list applicable versions) | na |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | na |
| Other (please specify) | na |
Documentation Considerations
ACM documentation should include how to configure secondary standalone networks.
This is a continuation of CNV-33392.
Multus Integration for HCP KubeVirt has three scenarios.
1. Secondary network as single interface for VM
2. Multiple Secondary Networks as multiple interfaces for VM
3. Secondary network + pod network (default for kubelet) as multiple interfaces for VM
Item 3 is the simplest use case because it does not require any addition considerations for ingress and load balancing. This scenario [item 3] is covered by CNV-33392.
Items [1,2] are what this epic is tracking, which we are considering advanced use cases.
Develop hypershift e2e test that exercises attaching a secondary network to a HCP KubeVirt nodepool
Feature Overview (aka. Goal Summary)
The default OpenShift installation on AWS uses multiple IPv4 public IPs which Amazon will start charging for starting in February 2024. As a result, there is a requirement to find an alternative path for OpenShift to reduce the overall cost of a public cluster while this is deployed on AWS public cloud.
Goals (aka. expected user outcomes)
Provide an alternative path to reduce the new costs associated with public IPv4 addresses when deploying OpenShift on AWS public cloud.
Requirements (aka. Acceptance Criteria):
There is a new path for "external" OpenShift deployments on AWS public cloud where the new costs associated with public IPv4 addresses have a minimum impact on the total cost of the required infrastructure on AWS.
Background
Ongoing discussions on this topic are happening in Slack in the #wg-aws-ipv4-cost-mitigation private channel
Documentation Considerations
Usual documentation will be required in case there are any new user-facing options available as a result of this feature.
Epic Goal
- Implement support in openshift-install to install OpenShift clusters using CAPI with user-provided Public IPv4 Pool ID and create resources* which consumes Public IP when publish strategy is "External".
*Resources which consumes public IPv4: bootstrap, API Public NLB, Nat Gateways
Why is this important?
- The default OpenShift installation on AWS uses multiple IPv4 public IPs which Amazon will start charging for starting in February 2024.
Scenarios
- As a customer with BYO Public IPv4 pools in AWS, I would like to install OpenShift cluster on AWS consuming public IPs for my own CIDR blocks, so I can have control of IPs used by my the services provided by me and will not be impacted by AWS Public IPv4 charges
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- Is there a method to use the pool by default for all Public IPv4 claims from a given VPC/workload? So the implementation doesn't need to create EIP and associations for each resource and subnet/zone.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
OCP 4 clusters still maintain pinned boot images. We have numerous clusters installed that have boot media pinned to first boot images as early as 4.1. In the future these boot images may not be certified by the OEM and may fail to boot on updated datacenter or cloud hardware platforms. These "pinned" boot images should be updateable so that customers can avoid this problem and better still scale out nodes with boot media that matches the running cluster version.
In phase 1 provided tech preview for GCP.
In phase 2, GCP support goes to GA. Support for other IPI footprints is new and tech preview.
Requirements
This would involve updating the AMIs stored within the AWSProviderConfig(encapsulated within a MachineSet. The "updated" AMI values should be available in the golden configmap.
This involves create a new feature gate for AWS boot image updates in openshift/api
This will pick up stories left off from the initial Tech Preview(Phase 1): https://issues.redhat.com/browse/MCO-589
Done when:
PR to API to remove featuregate
Alert docs team
Currently errors are propagated via a prometheus alert. Before GA, we will need to make sure that we are placing a condition on the configuration object in addition to the current Prometheus mechanism. This will be done by the MSBIC, but it should be mindful as to not stomp on the operator, which updates the MachineConfiguration Status as well.
Epic Goal
- The goal of this epic is to upgrade all OpenShift and Kubernetes components that MCO uses to v1.29 which will keep it on par with rest of the OpenShift components and the underlying cluster version.
Why is this important?
- Uncover any possible issues with the openshift/kubernetes rebase before it merges.
- MCO continues using the latest kubernetes/OpenShift libraries and the kubelet, kube-proxy components.
- MCO e2e CI jobs pass on each of the supported platform with the updated components.
Acceptance Criteria
- All stories in this epic must be completed.
- Go version is upgraded for MCO components.
- CI is running successfully with the upgraded components against the 4.16/master branch.
Dependencies (internal and external)
- ART team creating the go 1.29 image for upgrade to go 1.29.
- OpenShift/kubernetes repository downstream rebase PR merge.
Open questions::
- Do we need a checklist for future upgrades as an outcome of this epic?-> yes, updated below.
Done Checklist
- Step 1 - Upgrade go version to match rest of the OpenShift and Kubernetes upgraded components.
- Step 2 - Upgrade Kubernetes client and controller-runtime dependencies (can be done in parallel with step 3)
- Step 3 - Upgrade OpenShift client and API dependencies
- Step 4 - Update kubelet and kube-proxy submodules in MCO repository
- Step 5 - CI is running successfully with the upgraded components and libraries against the master branch.
We currently have a kube version string used in the call to setup envtest. We should either git rid of this reference and grab it from elsewhere or update it with every kube bump we do.
In addition, the setup call now requires an additional argument to factor for openshift/api's kubebuilder divergence. So the value being used here may not be valid for every kube bump as the archive is not generated for every kube version. (Doing a bootstrap test run should be able to sus this out, if it doesn't error with the new version you should be ok)
This was a temporary change and should be reverted. This was done because setup-envtest did a go bump that the MCO will probably not do in time for 4.16.
PR that pinned the tag: https://github.com/openshift/machine-config-operator/pull/4280
Slack thread: https://redhat-internal.slack.com/archives/GH7G2MANS/p1711372261617039?thread_ts=1711372068.123039&cid=GH7G2MANS
Please review the following PR: https://github.com/openshift/machine-config-operator/pull/4380
The PR has been automatically opened by ART (#forum-ocp-art) team automation and indicates
that the image(s) being used downstream for production builds are not consistent
with the images referenced in this component's github repository.
Differences in upstream and downstream builds impact the fidelity of your CI signal.
If you disagree with the content of this PR, please contact @release-artists
in #forum-ocp-art to discuss the discrepancy.
Closing this issue without addressing the difference will cause the issue to
be reopened automatically.
Epic Goal*
Drive the technical part of the Kubernetes 1.29 upgrade, including rebasing openshift/kubernetes repositiry and coordination across OpenShift organization to get e2e tests green for the OCP release.
Why is this important? (mandatory)
OpenShift 4.17 cannot be released without Kubernetes 1.30
Scenarios (mandatory)
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
PRs:
- https://github.com/openshift/api/pull/1813
- https://github.com/openshift/client-go/pull/277
- https://github.com/openshift/library-go/pull/1695
- https://github.com/openshift/apiserver-library-go/pull/129
- https://github.com/openshift/cluster-kube-apiserver-operator/pull/1666
- https://github.com/openshift/cluster-kube-scheduler-operator/pull/540
- https://github.com/openshift/cluster-kube-controller-manager-operator/pull/803
- https://github.com/openshift/kubernetes/pull/1953
- https://github.com/openshift/api/pull/1906
- https://github.com/openshift/api/pull/1813
- https://github.com/openshift/api/pull/1888
- https://github.com/openshift/cluster-kube-apiserver-operator/pull/1666
- https://github.com/openshift/cluster-kube-controller-manager-operator/pull/803
- https://github.com/openshift/cluster-kube-scheduler-operator/pull/540
- https://github.com/openshift/kubernetes/pull/1996
- https://github.com/openshift/kubernetes/pull/1982
- https://github.com/openshift/kubernetes/pull/1981
- https://github.com/openshift/kubernetes/pull/1979
- https://github.com/openshift/kubernetes/pull/1953
- https://github.com/openshift/origin/pull/28869
- https://github.com/openshift/origin/pull/28829
- https://github.com/openshift/origin/pull/28850
- https://github.com/openshift/origin/pull/28832
- https://github.com/openshift/origin/pull/28814
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
Why is this important?
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
 Priority+ is set by engineering
Priority+ is set by engineering- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
make sure we deliver a 1.30 kube-proxy standalone image
Why is this important?
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
- Priority+ is set by engineering
- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
Bump kube to 1.30 in CNCC
Why is this important?
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
- Priority+ is set by engineering
- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned components should be running on Kubernetes 1.29
- This includes
- The cluster autoscaler (+operator)
- Machine API operator
- Machine API controllers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Machine API controllers for:
- Cloud Controller Manager Operator
- Cloud controller managers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Cloud controller managers for:
- Cluster Machine Approver
- Cluster API Actuator Package
- Control Plane Machine Set Operator
Why is this important?
- ...
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.30. This should be done by rebasing/updating as appropriate for the repository
upgrade all OpenShift and Kubernetes components that cloud-credential-operator uses to v1.30 which keeps it on par with rest of the OpenShift components and the underlying cluster version.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned CAPI components should be running on Kubernetes 1.29
- target is 4.17 since CAPI is always a release behind upstream
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.17 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.17 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
 [Vu Dinh] cluster-kube-controller-manager operator: https://github.com/openshift/cluster-kube-controller-manager-operator/pull/803
[Vu Dinh] cluster-kube-controller-manager operator: https://github.com/openshift/cluster-kube-controller-manager-operator/pull/803- [Jan] cluster-policy-controller: https://github.com/openshift/cluster-policy-controller/pull/151
- [Vu Dinh] cluster-kube-scheduler operator: https://github.com/openshift/cluster-kube-scheduler-operator/pull/540
- [Jan] secondary-scheduler-operator: https://github.com/openshift/secondary-scheduler-operator/pull/142
- [Jan] cluster-capacity: https://github.com/openshift/cluster-capacity/pull/93
- [Jan] run-once-duration-override-operator: https://github.com/openshift/run-once-duration-override-operator/pull/57
- [Jan] run-once-duration-override: https://github.com/openshift/run-once-duration-override/pull/35
Other teams:
- [Jan] route-controller-manager: https://github.com/openshift/route-controller-manager/pull/44
If needed this card can be broken down into more cards with sublists, each card assigned to a different assignee.
- https://github.com/openshift/oc/pull/1789
- https://github.com/openshift/cluster-openshift-controller-manager-operator/pull/352
- https://github.com/openshift/cluster-policy-controller/pull/151
- https://github.com/openshift/openshift-controller-manager/pull/313
- https://github.com/openshift/route-controller-manager/pull/44
Feature Overview (aka. Goal Summary)
While installing OpenShift on AWS add support to use of existing IAM instance profiles
Goals (aka. expected user outcomes)
Allow a user to use existing an IAM instance profile while deploying OpenShift on AWS.
Requirements (aka. Acceptance Criteria):
When using existing IAM role, the Installer tries to create a new IAM instance profile. As of today, the installation will fail if the user does not have permission to create instance profiles.
The Installer will provide an option to the user to use an existing IAM instance profile instead trying to create a new one if this is provided.
Background
This work is important not only for self-manage customers who want to reduce the required permissions needed for the IAM accounts but also for the IC regions and ROSA customers.
Previous work
https://github.com/dmc5179/installer/commit/8699caa952d4a9ce5012cca3f86aeca70c499db4
Epic Goal
- Allow a user to use existing an IAM instance profile while deploying OpenShift on AWS.
Why is this important?
- This work is important not only for self-managed customers who want to reduce the required permissions needed for the IAM accounts but also for the IC regions and ROSA customers.
Scenarios
- When using an existing IAM role, the Installer tries to create a new IAM instance profile. As of today, the installation will fail if the user does not have permission to create instance profiles.
The Installer will provide an option to the user to use an existing IAM instance profile instead of trying to create a new one if this is provided.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Previous Work (Optional):
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Use a pre-existing IAM profile in the install-config.yaml
- Use a user/role which doesn't have the permissions needed for instance profile creation.
so that I can achieve
- A cluster created with an existing IAM profile.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
Graduate the etcd tuning profiles feature delivered in https://issues.redhat.com/browse/ETCD-456 to GA
Goals (aka. expected user outcomes)
Remove the feature gate flag and ,ake the feature accessible to all customers
Requirements (aka. Acceptance Criteria):
Requires fixes to apiserver to handle etcd client retries correctly
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | yes |
| Classic (standalone cluster) | yes |
| Hosted control planes | no |
| Multi node, Compact (three node), or Single node (SNO), or all | Multi node and compact clusters |
| Connected / Restricted Network | Yes |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | Yes |
| Operator compatibility | N/A |
| Backport needed (list applicable versions) | N/A |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | N/A |
| Other (please specify) | N/A |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Epic Goal*
Graduate the etcd tuning profiles feature delivered in https://issues.redhat.com/browse/ETCD-456 to GA
https://github.com/openshift/api/pull/1538
https://github.com/openshift/enhancements/pull/1447
Why is this important? (mandatory)
Graduating the feature to GA makes it accessible to all customers and not hidden behind a feature gate.
As further outlined in the linked stories the major roadblock for this feature to GA is to ensure that the API server has the necessary capability to configure its etcd client for longer retries on platforms with slower latency profiles. See: https://issues.redhat.com/browse/OCPBUGS-18149
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- As an openshift admin I can change the latency profile of the etcd cluster without causing any downtime to the control-plane availability
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - etcd
- Documentation - etcd docs team
- QE - etcd qe
- PX -
- Others -
Acceptance Criteria (optional)
Once the cluster is installed, we should be able to change the default latency profile on the API to a slower one and verify that etcd is rolled out with the updated leader election and heartbeat timeouts. During this rollout there should be no disruption or unavailability to the control-plane.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Once https://issues.redhat.com/browse/ETCD-473 is done this story will track the work required to move the "operator/v1 etcd spec.hardwareSpeed" field from behind the feature gate to GA.
Feature Overview (aka. Goal Summary)
Graduate the etcd tuning profiles feature delivered in https://issues.redhat.com/browse/ETCD-456 to GA
Goals (aka. expected user outcomes)
Remove the feature gate flag and ,ake the feature accessible to all customers
Requirements (aka. Acceptance Criteria):
Requires fixes to apiserver to handle etcd client retries correctly
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | yes |
| Classic (standalone cluster) | yes |
| Hosted control planes | no |
| Multi node, Compact (three node), or Single node (SNO), or all | Multi node and compact clusters |
| Connected / Restricted Network | Yes |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | Yes |
| Operator compatibility | N/A |
| Backport needed (list applicable versions) | N/A |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | N/A |
| Other (please specify) | N/A |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Note: There is no work pending from OTA team. The Jira tracks the work pending from other teams.
We started the feature with the assumption that CVO has to implement sigstore key verification like we do with gpg keys.
After investigation we found that sigstore key verification is done at node level and there is no CVO work. From that point this feature became a tracking feature for us to help other teams to do "sigstore key verification" tasks . Specifically Node team. The "sigstore key verification" roadmap is here https://docs.google.com/presentation/d/16dDwALKxT4IJm7kbEU4ALlQ4GBJi14OXDNP6_O2F-No/edit#slide=id.g547716335e_0_2075
Feature Overview (aka. Goal Summary)
Add sigstore signatures to core OCP payload and enable verification. Verification is now done via CRIO.
There is no CVO work in this feature and this is a Tech Preview change.
OpenShift Release Engineering can leverage a mature signing and signature verification stack instead of relying on simple signing
Goals (aka. expected user outcomes)
Customers can leverage OpenShift to create trust relationships for running OCP core container images
Specifically, customers can trust signed images from a Red Hat registry and OCP can verify those signatures
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
<enter general Feature acceptance here>
– Kubelet/CRIO to verify RH images & release payload sigstore signatures
– ART will add sigstore signatures to core OCP images
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
These acceptance criteria are for all deployment flavors of OpenShift.
| Deployment considerations | List applicable specific needs (N/A = not applicable) | |
| Self-managed, managed, or both | both | |
| Classic (standalone cluster) | yes | |
| Hosted control planes | yes | |
| Multi node, Compact (three node), or Single node (SNO), or all | ||
| Connected / Restricted Network | ||
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | ||
| Operator compatibility | ||
| Backport needed (list applicable versions) | Not Applicable | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | none, | |
| Other (please specify) |
Documentation Considerations
Add documentation for sigstore verification and gpg verification
Interoperability Considerations
For folks mirroring release images (e.g. disconnected/restricted-network):
- oc-mirror need to support sigstore mirroring (OCPSTRAT-1417).
- Customers using BYO image registries need to support hosting sigstore signatures.
OCP clusters need to add the ability to validate Sigstore signatures for OpenShift release images.
This is part of Red Hat's overall Sigstore strategy.
Today, Red Hat uses "simple signing" which uses an OpenPGP/GPG key and a separate file server to host signatures for container images.
Cosign is on track to be an industry standard container signing technique. The main difference is that, instead of signatures being stored in a separate file server, the signature is stored in the same registry that hosts the image.
Design document / discussion from software production: https://docs.google.com/document/d/1EPCHL0cLFunBYBzjBPcaYd-zuox1ftXM04aO6dZJvIE/edit
Demo video: https://drive.google.com/file/d/1bpccVLcVg5YgoWnolQxPu8gXSxoNpUuQ/view
Software production will be migrating to the cosign over the course of 2024.
ART will continue to sign using simple signing in combination with sigstore signatures until SP stops using it and product documentation exists to help customers migrate from the simple signing signature verification.
Acceptance criteria
- Help kubelet/CRI-O verify the new Sigstore signatures for OCP release images (TechPreview)
Currently this epic is primarily supporting the Node implementation work in OCPNODE-2231. There's a minor CVO UX tweak planned in OTA-1307 that's definitely OTA work. There's also the enhancement proposal in OTA-1294 and the cluster-update-keys in OTA-1304, which Trevor happens to be doing for intertial reasons, but which he's happy to hand off to OCPNODE and/or shift under OCPNODE-2231.
seeing various MCO issue across different platforms and repos on techpreview
- https://prow.ci.openshift.org/view/gs/test-platform-results/pr-logs/pull/openshift_clus[…]der-aws-master-e2e-aws-ovn-techpreview/1818614625273384960
- https://prow.ci.openshift.org/view/gs/test-platform-results/pr-logs/pull/openshift_clus[…]der-aws-master-e2e-aws-ovn-techpreview/1818592543001022464
- https://prow.ci.openshift.org/view/gs/test-platform-results/pr-logs/pull/openshift_clus[…]perator-main-e2e-azure-ovn-techpreview/1818562032329297920
- https://prow.ci.openshift.org/view/gs/test-platform-results/pr-logs/pull/openshift_clus[…]perator-main-e2e-azure-ovn-techpreview/1818592686244892672
@David Joshy found that it might be https://github.com/openshift/cluster-update-keys/pull/58
@jerzhang found diffs in sigstore-registries and policy.json. Which may be coming from this manifest. Is this available during bootstrap?
As described in the OTA-1294 enhancement. The cluster-update-keys repository isn't actually managed by the OTA team, but I expect it will be me opening the pull, and there isn't a dedicated Jira project covering cluster-update-keys, so I'm creating this ticket under the OTA Epic just because I can't think of a better place to put it.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
The goal of this EPIC is to either ship a cluster wide policy (not enabled by default) to verify OpenShift release/payload images or document how end users can create their own policy to verify them.
Why is this important?
We shipped cluster wide policy support in OCPNODE-1628 which should be used for internal components as well.
Scenarios
- Validate the sigstore signatures of OpenShift internal images to security harden the cluster deployment.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
- The payload components as well as the release images for OpenShift 4.16 have to be sigstore signed
- There is a limitation in the MCO that ClusterImagePolicy can not set policy.json for the OCP product repo when using wildcards: https://github.com/openshift/machine-config-operator/blob/4b809a4214f/pkg/controller/container-runtime-config/container_runtime_config_controller.go#L1053-L1057
Per: https://github.com/openshift/enhancements/pull/1402#discussion_r1223543692
Workaround: the image scopes have to be fully referenced by digest or tag
Open Questions
- How can we ensure no race condition between the CVO policy and CRI-O doing the verification?
- Do we need to ensure to have old and new policies in place during an upgrade?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Description of problem
As Miloslav Trmač reported upstream, when a ClusterImagePolicy is set on a scope to accept sigstore signatures, the underlying registry needs to be configured with use-sigstore-attachments: true. The current code:
func generateSigstoreRegistriesdConfig(clusterScopePolicies map[string]signature.PolicyRequirements) ([]byte, error) {
does do that for the configured scope; but the use-sigstore-attachments option applies not to the "logical name", but to each underlying mirror individually.
I.e. the option needs to be on every mirror of the scope. Without that, if the image is found on one of such mirrors, the c/image code will not be looking for signatures on the mirror, and policy enforcement is likely to fail.
Version-Release number of selected component
Seen in 4.17.0-0.nightly-2024-06-25-162526, but likely all releases which implement ClusterImagePolicy so far, because this is unlikely to be a regression.
How reproducible
Every time.
Steps to Reproduce
Apply the ClusterImagePolicy suggested in OTA-1294's enhancements#1633:
$ cat <<EOF >policy.yaml
apiVersion: config.openshift.io/v1alpha1
kind: ClusterImagePolicy
metadata:
name: openshift
annotations:
kubernetes.io/description: Require Red Hat signatures for quay.io/openshift-release-dev/ocp-release container images.
exclude.release.openshift.io/internal-openshift-hosted: "true"
include.release.openshift.io/self-managed-high-availability: "true"
release.openshift.io/feature-set: TechPreviewNoUpgrade
spec:
scopes:
- quay.io/openshift-release-dev/ocp-release
policy:
rootOfTrust:
policyType: PublicKey
publicKey:
keyData: LS0tLS1CRUdJTiBQVUJMSUMgS0VZLS0tLS0KTUlJQ0lqQU5CZ2txaGtpRzl3MEJBUUVGQUFPQ0FnOEFNSUlDQ2dLQ0FnRUEzQzJlVGdJQUo3aGxveDdDSCtIcE1qdDEvbW5lYXcyejlHdE9NUmlSaEgya09ZalRadGVLSEtnWUJHcGViajRBcUpWYnVRaWJYZTZKYVFHQUFER0VOZXozTldsVXpCby9FUUEwaXJDRnN6dlhVbTE2cWFZMG8zOUZpbWpsVVovaG1VNVljSHhxMzR2OTh4bGtRbUVxekowR0VJMzNtWTFMbWFEM3ZhYmd3WWcwb3lzSTk1Z1V1Tk81TmdZUHA4WDREaFNoSmtyVEl5dDJLTEhYWW5BMExzOEJlbG9PWVJlTnJhZmxKRHNzaE5VRFh4MDJhQVZSd2RjMXhJUDArRTlZaTY1ZE4zKzlReVhEOUZ6K3MrTDNjZzh3bDdZd3ZZb1Z2NDhndklmTHlJbjJUaHY2Uzk2R0V6bXBoazRjWDBIeitnUkdocWpyajU4U2hSZzlteitrcnVhR0VuVGcyS3BWR0gzd3I4Z09UdUFZMmtqMnY1YWhnZWt4V1pFN05vazNiNTBKNEpnYXlpSnVSL2R0cmFQMWVMMjlFMG52akdsMXptUXlGNlZnNGdIVXYwaktrcnJ2QUQ4c1dNY2NBS00zbXNXU01uRVpOTnljTTRITlNobGNReG5xU1lFSXR6MGZjajdYamtKbnAxME51Z2lVWlNLeVNXOHc0R3hTaFNraGRGbzByRDlkVElRZkJoeS91ZHRQWUkrK2VoK243QTV2UVV4Wk5BTmZqOUhRbC81Z3lFbFV6TTJOekJ2RHpHellSNVdVZEVEaDlJQ1I4ZlFpMVIxNUtZU0h2Tlc3RW5ucDdZT2d5dmtoSkdwRU5PQkF3c1pLMUhhMkJZYXZMMk05NDJzSkhxOUQ1eEsrZyszQU81eXp6V2NqaUFDMWU4RURPcUVpY01Ud05LOENBd0VBQVE9PQotLS0tLUVORCBQVUJMSUMgS0VZLS0tLS0K
EOF
$ oc apply -f policy.yaml
Set up an ImageContentSourcePolicy such as the ones Cluster Bot jobs have by default:
cat <<EOF >mirror.yaml
apiVersion: operator.openshift.io/v1alpha1
kind: ImageContentSourcePolicy
metadata:
name: pull-through-mirror
spec:
repositoryDigestMirrors:
- mirrors:
- quayio-pull-through-cache-us-west-2-ci.apps.ci.l2s4.p1.openshiftapps.com
source: quay.io
EOF
$ oc apply -f mirror.yaml
Set CRI-O debug logs, following these docs:
$ cat <<EOF >custom-loglevel.yaml
apiVersion: machineconfiguration.openshift.io/v1
kind: ContainerRuntimeConfig
metadata:
name: custom-loglevel
spec:
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/master: ''
containerRuntimeConfig:
logLevel: debug
EOF
$ oc create -f custom-loglevel.yaml
Wait for that to roll out, as described in docs:
$ oc get machineconfigpool master
Launch a Sigstore-signed quay.io/openshift-release-dev/ocp-release image, by asking the cluster to update to 4.16.1:
$ oc adm upgrade --allow-explicit-upgrade --to-image quay.io/openshift-release-dev/ocp-release@sha256:c17d4489c1b283ee71c76dda559e66a546e16b208a57eb156ef38fb30098903a
Check the debug CRI-O logs:
$ oc adm node-logs --role=master -u crio | grep -i1 sigstore | tail -n5
Actual results
Not looking for sigstore attachments: disabled by configuration entries like:
$ oc adm node-logs --role=master -u crio' | grep -i1 sigstore | tail -n5 -- Jun 28 19:06:34.317335 ip-10-0-43-59 crio[2154]: time="2024-06-28 19:06:34.317169116Z" level=debug msg=" Using transport \"docker\" specific policy section quay.io/openshift-release-dev/ocp-release" file="signature/policy_eval.go:150" Jun 28 19:06:34.317335 ip-10-0-43-59 crio[2154]: time="2024-06-28 19:06:34.317207897Z" level=debug msg="Reading /var/lib/containers/sigstore/openshift-release-dev/ocp-release@sha256=c17d4489c1b283ee71c76dda559e66a546e16b208a57eb156ef38fb30098903a/signature-1" file="docker/docker_image_src.go:479" Jun 28 19:06:34.317335 ip-10-0-43-59 crio[2154]: time="2024-06-28 19:06:34.317240227Z" level=debug msg="Not looking for sigstore attachments: disabled by configuration" file="docker/docker_image_src.go:556" Jun 28 19:06:34.317335 ip-10-0-43-59 crio[2154]: time="2024-06-28 19:06:34.317277208Z" level=debug msg="Requirement 0: denied, done" file="signature/policy_eval.go:285"
Expected results
Something about "we're going to look for Sigstore signatures on quayio-pull-through-cache-us-west-2-ci.apps.ci.l2s4.p1.openshiftapps.com, since that's where we found the quay.io/openshift-release-dev/ocp-release@sha256:c17d4489c1b283ee71c76dda559e66a546e16b208a57eb156ef38fb30098903a image". At this point, it doesn't matter whether the retrieved signature is accepted or not, just that a signature lookup is attempted.
Remove the openshift/api ClusterImagePolicy document about the restriction of scope field on OpenShift release image repository and install the updated manifest in MCO.
enhancements#1633 is still in flight, but there seams to be some consensus around its API Extensions proposal to drop the following Godocs from ClusterImagePolicy and ImagePolicy:
// Please be aware that the scopes should not be nested under the repositories of OpenShift Container Platform images. // If configured, the policies for OpenShift Container Platform repositories will not be in effect.
The backing implementation will also be removed. This guard was initially intended to protect cluster adminstrators from breaking their clusters by configuring policies that blocked critical images. And before Red Hat was publishing signatures for quay.io/openshift-release-dev/ocp-release releases, that made sense. But now that Red Hat is almost (OTA-1267) publishing Sigstore signatures for those release images, it makes sense to allow policies covering those images. And even if a cluster administrator creates a policy that blocks critical image pulls, PodDisriptionBudgets should keep the Kubernetes API server and related core workloads running for long enough for the cluster administrator to use the Kube API to remove or adjust the problematic policy.
There's a possibility that we replace the guard with some kind of pre-rollout validation, but that doesn't have to be part of the initial work.
We want this guard in place to unblock testing of enhancements#1633's proposed ClusterImagePolicy, so we can decide if it works as expected, or if it needs tweaks before being committed as a cluster-update-keys manifest. And we want that testing to establish confidence in the approach before we start in on the installer's internalTestingImagePolicy and installer-caller work.
Update the manifest through MCO script:https://github.com/openshift/machine-config-operator/blob/master/hack/crds-sync.sh
Make sure the document of ClusterImagePolicy and featuregate in the MCO manifest is up to date with API generated CRD.
These seem like dup's, and we should remove ImagePolicy and consolidate around SigstoreImageVerification for clarity.
Feature Overview (aka. Goal Summary)
Enable Hosted Control Planes guest clusters to support up to 500 worker nodes. This enable customers to have clusters with large amount of worker nodes.
Goals (aka. expected user outcomes)
Max cluster size 250+ worker nodes (mainly about control plane). See XCMSTRAT-371 for additional information.
Service components should not be overwhelmed by additional customer workloads and should use larger cloud instances and when worker nodes are lesser than the threshold it should use smaller cloud instances.
Requirements (aka. Acceptance Criteria):
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Managed |
| Classic (standalone cluster) | N/A |
| Hosted control planes | Yes |
| Multi node, Compact (three node), or Single node (SNO), or all | N/A |
| Connected / Restricted Network | Connected |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86_64 ARM |
| Operator compatibility | N/A |
| Backport needed (list applicable versions) | N/A |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | N/A |
| Other (please specify) |
Questions to Answer (Optional):
Check with OCM and CAPI requirements to expose larger worker node count.
Documentation:
- Design document detailing the autoscaling mechanism and configuration options
- User documentation explaining how to configure and use the autoscaling feature.
Acceptance Criteria
- Configure max-node size from CAPI
- Management cluster nodes automatically scale up and down based on the hosted cluster's size.
- Scaling occurs without manual intervention.
- A set of "warm" nodes are maintained for immediate hosted cluster creation.
- Resizing nodes should not cause significant downtime for the control plane.
- Scaling operations should be efficient and have minimal impact on cluster performance.
Goal
- Dynamically scale the serving components of control planes
Why is this important?
- To be able to have clusters with large amount of worker nodes
Scenarios
- A hosted cluster amount of worker nodes increases past X amount, the serving components are moved to larger cloud instances
- A hosted cluster amount of workers falls below a threshold, the serving components are moved to smaller cloud instances.
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a service provider, I want to be able to:
- Configure priority and fairness settings per HostedCluster size and force these settings to be applied on the resulting hosted cluster.
so that I can achieve
- Prevent user of hosted cluster from bringing down the HostedCluster kube apiserver with their workload.
Acceptance Criteria:
Description of criteria:
- HostedCluster priority and fairness settings should be configurable per cluster size in the ClusterSizingConfiguration CR
- Any changes in priority and fairness inside the HostedCluster should be prevented and overridden by whatever is configured on the provider side.
- With the proper settings, heavy use of the API from user workloads should not result in the KAS pod getting OOMKilled due to lack of resources.
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
Description of problem:
In some instances the request serving node autoscaler helper fails to kick off a reconcile when there are pending pods.
Version-Release number of selected component (if applicable):
4.17
How reproducible:
sometimes
Steps to Reproduce:
1. Setup a mgmt cluster with size tagging
2. Create a hosted cluster and get it scheduled
3. Scale down the machinesets of the request serving nodes for the hosted cluster.
4. Wait for the hosted cluster to recover
Actual results:
A placeholder pod is created for the missing node of the hosted cluster, but does not cause a scale up of the corresponding machineset.
Expected results:
The hosted cluster recovers by scaling up the corresponding machinesets.
Additional info:
Description of problem:
On Running PerfScale test on staging sectors, the script creates 1 HC per minute to load up a Management Cluster to its maximum capacity(64 HC). There were 2 clusters trying to use same serving node pair and got in to a deadlock
# oc get nodes -l osd-fleet-manager.openshift.io/paired-nodes=serving-12 NAME STATUS ROLES AGE VERSION ip-10-0-4-127.us-east-2.compute.internal Ready worker 34m v1.27.11+d8e449a ip-10-0-84-196.us-east-2.compute.internal Ready worker 34m v1.27.11+d8e449a Each node got assigned to 2 different cluster # oc get nodes -l hypershift.openshift.io/cluster=ocm-staging-2bcimf68iudmq2pctkj11os571ahutr1-mukri-dysn-0017 NAME STATUS ROLES AGE VERSION ip-10-0-4-127.us-east-2.compute.internal Ready worker 33m v1.27.11+d8e449a # oc get nodes -l hypershift.openshift.io/cluster=ocm-staging-2bcind28698qgrugl87laqerhhb0u2c2-mukri-dysn-0019 NAME STATUS ROLES AGE VERSION ip-10-0-84-196.us-east-2.compute.internal Ready worker 36m v1.27.11+d8e449a Taints were missing on those nodes, so metric-forwarder pod from other hostedclusters got scheduled on serving nodes. # oc get pods -A -o wide | grep ip-10-0-84-196.us-east-2.compute.internal ocm-staging-2bcind28698qgrugl87laqerhhb0u2c2-mukri-dysn-0019 kube-apiserver-86d4866654-brfkb 5/5 Running 0 40m 10.128.48.6 ip-10-0-84-196.us-east-2.compute.internal <none> <none> ocm-staging-2bcins06s2acm59sp85g4qd43g9hq42g-mukri-dysn-0020 metrics-forwarder-6d787d5874-69bv7 1/1 Running 0 40m 10.128.48.7 ip-10-0-84-196.us-east-2.compute.internal <none> <none> and few more
Version-Release number of selected component (if applicable):
MC Version 4.14.17 HC version 4.15.10 HO Version quay.io/acm-d/rhtap-hypershift-operator:c698d1da049c86c2cfb4c0f61ca052a0654e2fb9
How reproducible:
Not Always
Steps to Reproduce:
1. Create an MC with prod config (non-dynamic serving node)
2. Create HCs on them at 1 HCP per minutes
3. Cluster stuck at installing for more than 30 minutes
Actual results:
Only one replica of Kube-apiserver pods were up and the second stuck at pending state, upon checking the machine API has scaled both nodes in that machineset(serving-12) but only one got assigned(labelled). Further checking that node from one zone(serving-12a) was assigned to a specific hosted cluster(0017), and the other one(serving-12b) was assigned to a different hosted cluster(0019)
Expected results:
Kube-apiserver replica should be on the same machinesets and those node should be tainted.
Additional info: Slack
Description of problem:
When creating a cluster with OCP < 4.16 and nodepools with a number of workers larger than smallest size, the placeholder pods for the hosted cluster get continually recycled and the hosted cluster is never scheduled.
Version-Release number of selected component (if applicable):
4.17.0
How reproducible:
Always
Steps to Reproduce:
0. Install hypershift with size tagging enabled
1. Create a hosted cluster with nodepools large enough to not be able to use the default placeholder pods (or simply configure no placeholder pods)
Actual results:
The cluster never schedules
Expected results:
The cluster is scheduled and the control plane can come up
Additional info:
Feature Overview (aka. Goal Summary)
CRIO wipe is existing feature in Openshift . When node reboots CRIO wipe goes and clear the node of all images so that node boots clean . When node come back up it need access to image registry to get all images and it takes time to get all images . For telco and edge situation node might not have access to image registry and takes time to come up .
Goal of this feature is to adjust CRIO wipe to wipe only images that has been corrupted because of sudden reboot not all images
Feature Overview
Phase 2 of the enclave support for oc-mirror with the following goals
- Incorporate feedback from the field from 4.16 TP
- Performance improvements
Goals
- Update the batch processing using `containers/image` to do the copying for setting the number of blobs (layers) to download
- Introduce a worker for concurrency that can also update the number of images to download to improve overall performance (these values can be tweaked via CLI flags).
- Collaborate with the UX team to improve the console output while pulling or pushing images.
For 4.17 timeframe
- Incorporate feedback from the field from 4.16 TP
- Performance improvements
Currently the operator catalog image is always being deleted in the delete feature. It can leads to catalogs broken in the clusters.
It is necessary to change the implementation to skip the deletion of the operator catalog image according with the following conditions:
- If in the DeleteImageSetConfiguration were specified packages (operators) under the operator catalog, so it means the customer wants to delete only the specified operators and the operator catalog image should not be deleted.
- If only the operator catalog was specified, it means all the operators under the specified operator catalog should be deleted AND also the operator catalog image.
It is necessary to create a data structure that contains in which operator each related image is encountered, it is possible to get this information from the current loop already present in the collection phase.
Having this data structure will allow to tell customers which operators failed based on a image that failed during the mirroring.
For example: related image X failed during the mirroring, this related image is present in the operators a, b and c, so in the mirroring errors file already being generated is going to include the name of the operators instead of the name of the related image only.
- for a fail safe on a related image, stop mirroring the whole group of related images for that bundle
- AND especially, defer mirroring bundle images till all related images are mirrored. Otherwise, we'll be in the situation you described yesterday: the operator starts upgrading when its related images are missing
Feature Overview
oc-mirror to notify users when when minVersion and maxVersion have a difference of more than one major version (e.g 4.14 to 4.16), to advice users to include the interim version in the channels to be mirrored.
This is required when planning to allow upgrades between Extended Upgrade Support (EUS) releases, which require the interim version between the two (e.g. 4.15 is required in the mirrored content to upgrade 4.14 to 4.16).
Goals
oc-mirror will inform clearly users via the command line about this requirement so that users can select the appropriate versions for their upgrade plans.
When doing OCP upgrade on EUS versions, sometimes it is required to add a middle version between the current and target version.
For example:
current OCP version 4.14
target OCP version 4.16
Sometimes in order to upgrade from 4.14 to 4.16 it is required a version in the middle like 4.15.8 and this version needs to be included in the ImageSetConfiguration when using oc-mirror.
The current algorithm in oc-mirror is not accurate enough to give this information, so the proposal is to add a warning in the command line and in the docs about using the cincinnati graph web page to check if there are versions in the middle when upgrading OCP EUS versions and adding it to the ImageSetConfiguration.
oc-mirror needs to identify when an OCP on EUS version is trying to upgrade and it is skiping one version (For example going from 4.12.14 to 4.14.18)
When this condition is identified, oc-mirror needs to show a warning in the log saying to customer to use the cincinnati web tool (upgrade tool) to identify versions required in the middle.
Feature Overview
Adding nodes to on-prem clusters in OpenShift in general is a complex task. We have numerous methods and the field keeps adding automation around these methods with a variety of solutions, sometimes unsupported (see "why is this important below"). Making cluster expansions easier will let users add nodes often and fast, leading to an much improved UX.
This feature adds nodes to any on-prem clusters, regardless of their installation method (UPI, IPI, Assisted, Agent), by booting an ISO image that will add the node to the cluster specified by the user, regardless of how the cluster was installed.
Goals and requirements
- Users can install a host on day 2 using a bootable image to an OpenShift cluster.
- At least platforms baremetal, vSphere, none and Nutanix are supported
- Clusters installed with any installation method can be expanded with the image
- Clusters don't need to run any special agent to allow the new nodes to join.
How this workflow could look like
1. Create image:
$ export KUBECONFIG=kubeconfig-of-target-cluster $ oc adm node-image -o agent.iso --network-data=worker-n.nmstate --role=worker
2. Boot image
3. Check progress
$ oc adm add-node
Consolidate options
An important goal of this feature is to unify and eliminate some of the existing options to add nodes, aiming to provide much simpler experience (See "Why is this important below"). We have official and field-documented ways to do this, that could be removed once this feature is in place, simplifying the experience, our docs and the maintenance of said official paths:
- UPI: Adding RHCOS worker nodes to a user-provisioned infrastructure cluster
- This feature will replace the need to use this method for the majority of UPI clusters. The current UPI method consists on many many manual steps. The new method would replace it by a couple of commands and apply to probably more than 90% of UPI clusters.
- Field-documented methods and asks
- Often we are asked about ways to do this or given different ways in which the field is automating this process in their own way. We can't control all aspects of these automations or how many there are, they are usually based on UPI, e.g.
- [gellner/expand-agent1.md|https://gist.github.com/gellner/f1f2928f847355ae80d0867884569109]
WKLD-433
- IPI:
- There are instances were adding a node to an bare metal IPI-deployed cluster can't be done via its BMC. This new feature, while not replacing the day-2 IPI workflow, solves the problem for this use case.
- MCE: Scaling hosts to an infrastructure environment
- This method is the most time-consuming and in many cases overkilling, but currently, along with the UPI method, is one of the two options we can give to users.
- We shouldn't need to ask users to install and configure the MCE operator and its infrastructure for single clusters as it becomes a project even larger than UPI's method and save this for when there's more than one cluster to manage.
With this proposed workflow we eliminate the need of using the UPI method in the vast majority of the cases. We also eliminate the field-documented methods that keep popping up trying to solve this in multiple formats, and the need to recommend using MCE to all on-prem users, and finally we add a simpler option for IPI-deployed clusters.
In addition, all the built-in validations in the assisted service would be run, improving the installation the success rate and overall UX.
This work would have an initial impact on bare metal, vSphere, Nutanix and platform-agnostic clusters, regardless of how they were installed.
Why is this important
This feature is essential for several reasons. Firstly, it enables easy day2 installation without burdening the user with additional technical knowledge. This simplifies the process of scaling the cluster resources with new nodes, which today is overly complex and presents multiple options (https://docs.openshift.com/container-platform/4.13/post_installation_configuration/cluster-tasks.html#adding-worker-nodes_post-install-cluster-tasks).
Secondly, it establishes a unified experience for expanding clusters, regardless of their installation method. This streamlines the deployment process and enhances user convenience.
Another advantage is the elimination of the requirement to install the Multicluster Engine and Infrastructure Operator , which besides demanding additional system resources, are an overkill for use cases where the user simply wants to add nodes to their existing cluster but aren't managing multiple clusters yet. This results in a more efficient and lightweight cluster scaling experience.
Additionally, in the case of IPI-deployed bare metal clusters, this feature eradicates the need for nodes to have a Baseboard Management Controller (BMC) available, simplifying the expansion of bare metal clusters.
Lastly, this problem is often brought up in the field, where examples of different custom solutions have been put in place by redhatters working with customers trying to solve the problem with custom automations, adding to inconsistent processes to scale clusters.
Oracle Cloud Infrastructure
This feature will solve the problem cluster expansion for OCI. OCI doesn't have MAPI and CAPI isn't in the mid term plans. Mitsubishi shared their feedback making solving the problem of lack of cluster expansion a requirement to Red Hat and Oracle.
Existing work
We already have the basic technologies to do this with the assisted-service and the agent-based installer, which already do this work for new clusters, and from which we expect to leverage the foundations for this feature.
Day 2 node addition with agent image.
Yet Another Day 2 Node Addition Commands Proposal
Enable day2 add node using agent-install: AGENT-682
Epic Goal
- Cleanup/carryover work from
AGENT-682for the GA release
Why is this important?
- Address all the required elements for the GA, such as the FIPS compliancy. This will allow a smoother integration of the node-joiner into the oc tool, as planned in
OCPSTRAT-784
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
- None
Previous Work (Optional):
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This warning message is displayed by client-go library when running in cluster. Code: https://github.com/kubernetes/client-go/blob/e4e31fd32c91e1584fd774f58b2d39f135d23571/tools/clientcmd/client_config.go#L659
This message should be disabled by either passing in the kubconfig file correctly or building the config in a different way.
By default (and if available) the same pub ssh key used for the installation is reused to add a new node.
It could be useful to allow the user to (optionally) specify a different key in the nodes-config.yaml configuration file
Allow monitoring simultaneously more than one node.
It may be necessary to coalesce the different assisted-service pre-flight validations output accordingly
Currently Assisted Service, when adding a new node, configure the bootstrap ignition to fetch the node ignition from the insecure port (22624), even though it would be possible to use the secure one (22623). This could be an issue for the existing users that didn't want to use the insecure port for the add node operation.
Implementation notes
Extend the ClusterInfo asset to retrieve the initial ignition details (url and ca certificate) from the openshift-machine-api/worker-user-data-managed secret, if available in the target cluster. These information will then be used by the agent-installer-client when importing a new cluster, to configure the cluster ignition_endpoint
(see more context in comment https://github.com/openshift/installer/pull/8242#discussion_r1571664023)
To allow running the node-joiner in a pod into a cluster where FIPS was enabled:
- set CGO_ENABLED=1 in hack/build-node-joiner.sh
- set the fips=1 karg in the ISO (if not already set, to be verified)
Performs all the required preliminary validations for adding new nodes:
- Ensure that the (static) IPs/hostnames, if specified, do not conflict with the existing ones
-If nmstate config is provided, it should be validated as usual- (already done) - Validate that the target platform is a supported one
Epic Goal*
Provide a simple commands for almost all users to add a node to a cluster where scaling up a MachineSet isn't an option - whether they have installed using UPI, Assisted or the agent-based installer, or can't use MachineSets for some other reason.
Why is this important? (mandatory)
- Enable easy day2 installation without requiring additional knowledge from the user
- Unified experience for day1 and day2 installation for the agent based installer
- Unified experience for day1 and day2 installation for appliance workflow
- Eliminate the requirement of installing MCE that have high requirements (requires 4 cores and 16GB RAM for a multi-node cluster, and if the infrastructure operator is included then it will require storage as well)
- Eliminate the requirement of nodes having a BMC available to expand bare metal clusters (see docs).
- Simplify adding compute nodes based on the the UPI method or other method implemented in the field such as
WKLD-433or other automations that try to solve this problem
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- User installed day1 cluster with agent based install and want to add workers or replace failed nodes, currently alternative is to install MCE or, if connected, use SAAS.
Dependencies (internal and external) (mandatory)
Contributing Teams(and contacts) (mandatory)
The installer team is developing the main body of the feature, which will run in the cluster to be expanded, as well as a prototype client-side script in AGENT-682. They will then be able to translate the client-side into native oc-adm subcommands.
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Allow running the node-image commands only for 4.17+ clusters.
Full support for 4.16 clusters will be implemented via https://issues.redhat.com/browse/OCPSTRAT-1528
This is the command responsible for monitoring the activity when adding new node(s) to the target cluster.
Similarly to the add-nodes-image command, also this one will be a simpler wrapper around the node-joiner's monitor command.
A list of the expected operations can be found in https://github.com/openshift/installer/blob/master/docs/user/agent/add-node/node-joiner-monitor.sh
Feature Overview
Move to using the upstream Cluster API (CAPI) in place of the current implementation of the Machine API for standalone Openshift
prerequisite work Goals completed in OCPSTRAT-1122
{}Complete the design of the Cluster API (CAPI) architecture and build the core operator logic needed for Phase-1, incorporating the assets from different repositories to simplify asset management.
Phase 1 & 2 covers implementing base functionality for CAPI.
Background, and strategic fit
- Initially CAPI did not meet the requirements for cluster/machine management that OCP had the project has moved on, and CAPI is a better fit now and also has better community involvement.
- CAPI has much better community interaction than MAPI.
- Other projects are considering using CAPI and it would be cleaner to have one solution
- Long term it will allow us to add new features more easily in one place vs. doing this in multiple places.
Acceptance Criteria
There must be no negative effect to customers/users of the MAPI, this API must continue to be accessible to them though how it is implemented "under the covers" and if that implementation leverages CAPI is open
Epic Goal
- As we prepare to move over to using Cluster API (CAPI) we need to make sure that we have the providers in place to work with this. This Epic is to track the tech preview of the provider for Azure
Why is this important?
- What are the benefits to the customer, or to us, that make this worth
doing? Fulfills a critical need for a customer? Improves
supportability/debuggability? Improves efficiency/performance? This
section is used to help justify the priority of this item vs other things
we can do.
Drawbacks
- Reasons we should consider NOT doing this such as: limited audience for
the feature, feature will be superceded by other work that is planned,
resulting feature will introduce substantial administrative complexity or
user confusion, etc.
Scenarios
- Detailed user scenarios that describe who will interact with this
feature, what they will do with it, and why they want/need to do that thing.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents. - ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub
Issue> - DEV - Upstream documentation merged: <link to meaningful PR or GitHub
Issue> - DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
On clusters where we use Cluster API instead of Machine API we need to create an empty file to report that the bootstrapping was successful. The file should be place in "/run/cluster-api/bootstrap-success.complete"
Normally there is a special controller for it, but in OpenShift we use MCO to bootstrap machines, so we have to create this file directly.
ToDo:
- Ensure that "/run/cluster-api" folder exists on the machine
- Create CAPI bootstrapping sentinel file "bootstrap-success.complete" in this folder
Links:
https://cluster-api.sigs.k8s.io/developer/providers/bootstrap.html
https://github.com/kubernetes-sigs/cluster-api-provider-azure/blob/main/azure/defaults.go#L81-L83
User Story
As an OpenShift engineer I want the CAPI Providers repositories to use the new generator tool so that they can independently generate CAPI Provider transport ConfigMaps
Background
Once the new CAPI manifests generator tool is ready, we want to make use of that directly from the CAPI Providers repositories so we can avoid storing the generated configuration centrally and independently apply that based on the running platform.
Steps
- Install new CAPI manifest generator as a go `tool` to all the CAPI provider repositories
- Setup a make target under the `/openshift/Makefile` to invoke the generator. Make it output the manifests under `/openshift/manifests`
- Make sure `/openshift/manifests` is mapped to `/manifests` in the openshift/Dockerfile, so that the files are later picked up by CVO
- Make sure the manifest generation works by triggering a manual generation
- Check in the newly generated transport ConfigMap + Credential Requests (to let them be applied by CVO)
Stakeholders
- <Who is interested in this/where did they request this>
Definition of Done
- CAPI manifest generator tool is installed
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
Feature Overview
Console enhancements based on customer RFEs that improve customer user experience.
Goals
- This Section:* Provide high-level goal statement, providing user context and expected user outcome(s) for this feature
- …
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Acceptance criteria:
- For
RFE-2461: Automatically prefill the exposed port from a Dockerfile into the Import from Git flow (if defined and possible) - For
RFE-2473: Automatically select new Deployments or Knative Services in Topology after creating them with the Import from Git or Import image container flow, similar to the "Create Helm Release" flow.
Dependencies (External/Internal):
Design Artifacts:
Exploration:
Note:
Description of problem:
Port exposed in Dockerfile not observed in the Ports Dropdown in Git Import Form
Version-Release number of selected component (if applicable):
4.15
How reproducible:
Always
Steps to Reproduce:
Use the https://github.com/Lucifergene/knative-do-demo/ to create application with the Dockerfile strateg
Actual results:
Ports not displayed
Expected results:
Should display
Additional info:
Description
As a user, I don't want to see jumping UI when the Import from Git flow (or other forms) waits that network call is handled correctly.
The PatternFly Button components have a progress indicator for that: https://www.patternfly.org/components/button/#progress-indicators
This should be preferred over the manually displayed indicator that is shown sometimes (esp on the Import from Git page) in the next line.
Acceptance Criteria
- Use the button loading indicator instead of a loading indicator next to the button ("on all forms")
- Import from Git
- Import Container image
- Pipelines Builder (Pipelines create page)
Additional Details:
Description
As a user, I want to quickly select a Git Type if Openshift cannot identify it. Currently, the UI involves opening a Dropdown and selecting the desired Git type.
But it would be great if I could select the Git Type directly without opening any dropdown. This will reduce the number of clicks required to complete the action.
Acceptance Criteria
- Remove the Git Type dropdown
- Use the Tile PF component to design the new Git Types
- Make sure it's smaller than the Build Strategy Tiles
- Update the E2E tests
Additional Details:
Goal:
The OpenShift Developer Console supports an easy way to import source code from a Git repository and automatically creates a BuildConfig or a Pipeline for the user.
Why is it important?
GitEA is an open-source alternative to GitHub, similar to GitLab. Customers who use or try GitEA will see warnings while importing their Git repository. We got already the first bug around missing GitEA support OCPBUGS-31093
Use cases:
- Import from Git should support GitEA
- Should also work with Serverless function > Import from Git
- And when import a Devfile
Acceptance criteria:
- Import from Git should support GitEA
- If might switch to GitEA provider if the domainname contains gitea or git-ea? (not a hard requirement)
- The user should have the option to switch to GitEA if the git provider auto-detection doesn't work
- It should work with public and private repositories
Dependencies (External/Internal):
None
Design Artifacts:
Not required
Exploration:
- We should explore if GitEA provides an API so that our frontend can fetch file lists and file content via REST.
- We should check if there might be CORS issues or if we can use our internet proxy if needed.
Note:
None
Description
As a developer, I want to create a new Gitea service to be able to perform all kinds of import operations on repositories hosted in Gitea.
Acceptance Criteria
- Analyse the APIs and filter the ones that are required for performing the import functions
- Create the new gitea-service file.
- Update the UI
Additional Details:
Feature Overview (aka. Goal Summary)
OLM users can easily see in the console if an installed operator package is deprecated and learn how to stay within the support boundary by viewing the alerts/notifications that OLM emits, or by reviewing the operator status rendered by the console with visual representation.
Goals (aka. expected user outcomes)
- Pre-installation: OLM users can see the deprecation visual representation in the console UI and be warned/discouraged from installing a deprecated package, from deprecated channels, or in a deprecated version, and learn the recommended alternatives to stay within the supported path (with a short description).
- Post-installation: OLM users can see the deprecation visual representation in the console UI to tell if an installed operator is deprecated entirely, currently subscribed to a deprecated channel, or in a deprecated version, and know the alternatives as in package(s), update channel(s), or version(s) to stay within the support boundary.
Related Information
- Figma mocks: https://www.figma.com/proto/ZY4kXCx9AlcFWe7nOBI8JK/Untitled?page-id=140%3A1661&node-id=257-2465&viewport=1916%2C-2026%2C0.25&t=oUHBglFpyre6LgF4-1&scaling=min-zoom&starting-point-node-id=257%3A2465&show-proto-sidebar=1
- Design Brief (google doc): https://docs.google.com/document/d/1etcAcf2BCYYAVxjpYHnNsORsxzs3VKuTYBfTsLW6Dcg/edit?usp=sharing
- CatalogSource YAML for a catalog image with Operators carrying deprecation info: test-community-operator-deprecation.yaml (see in the attachment)
- 3scale-community-operator:
- deprecated channel: threescale-2.11
- deprecated version: 3scale-community-operator.v0.8.2, 3scale-community-operator.v0.9.0
- 3scale-community-operator:
-
- kiali-operator:
- deprecated package: kiali-operator
- deprecated channel: alpha
- deprecated version: kiali-operator.v1.68.0
- kiali-operator:
Acceptance Criteria
- Pre-installation
- Operator Hub page - display the deprecation warning if the PackageManifest is deprecated
- Install Operator details page
- display the deprecation badge if the PackageManifest is deprecated
- display the deprecation warning with deprecation message if PackageManifest, Channel or Version is deprecated
- In both Channel and Version dropdown, show an warning icon next to the deprecated entry.
- Operator install page
- display the deprecation badge if the PackageManifest is deprecated
- display the deprecation warning with deprecation message if PackageManifest, Channel or Version is deprecated
- In both Channel and Version dropdown, show an warning icon next to the deprecated entry.
- Add integration and unit tests
As a user, I would like to customize the modal displayed when a 'Create Project' button is clicked in the UI.
Acceptance criteria
- add an extension point so plugin creators can provide their own "Create Project" modal
- the console should implement this extension point using the "useModal" hook from the dynamic plugin SDK
- update docs with this extension point.
add a a custom modal to the demo plugin for testing. The modal will create a project and quota for that project.
Provide a simplified view of config files belonging to MachineConfig objects, to provide more convenient user experience. simpler management.
Current state:
- When a user/partner needs to retrieve contents from a MachineConfig they need to manually decode the file into a readable format from the URL-encoded one. For example: $ oc get mc $machineConfigName -o jsonpath='
{.spec.config.storage.files[1].contents.source}
' | sed "s@+@ @g;s@%@\\\\x@g" | xargs -0 printf "%b\n
Desired state:
- Instead of the command below the partner would like to get the content of the config files by default in a human-readable format via the OpenShift web dashboard. Please see the attached image. On this screen, a new tab can be introduced to be able to check the content of the configuration files.

AC:
- Add the Configuration Files section into the MachineConfig details page, which renders all the configuration that the resource contains.
- Add integration tests
Feature Overview (aka. Goal Summary)
OLM users can easily see in the console if an installed operator package is deprecated and learn how to stay within the support boundary by viewing the alerts/notifications that OLM emits, or by reviewing the operator status rendered by the console with visual representation.
Goals (aka. expected user outcomes)
- Pre-installation: OLM users can see the deprecation visual representation in the console UI and be warned/discouraged from installing a deprecated package, from deprecated channels, or in a deprecated version, and learn the recommended alternatives to stay within the supported path (with a short description).
- Post-installation: OLM users can see the deprecation visual representation in the console UI to tell if an installed operator is deprecated entirely, currently subscribed to a deprecated channel, or in a deprecated version, and know the alternatives as in package(s), update channel(s), or version(s) to stay within the support boundary.
Related Information
- Figma mocks: https://www.figma.com/proto/ZY4kXCx9AlcFWe7nOBI8JK/Untitled?page-id=140%3A1661&node-id=257-2465&viewport=1916%2C-2026%2C0.25&t=oUHBglFpyre6LgF4-1&scaling=min-zoom&starting-point-node-id=257%3A2465&show-proto-sidebar=1
- Design Brief (google doc): https://docs.google.com/document/d/1etcAcf2BCYYAVxjpYHnNsORsxzs3VKuTYBfTsLW6Dcg/edit?usp=sharing
- CatalogSource YAML for a catalog image with Operators carrying deprecation info: test-community-operator-deprecation.yaml (see in the attachment)
- 3scale-community-operator:
- deprecated channel: threescale-2.11
- deprecated version: 3scale-community-operator.v0.8.2, 3scale-community-operator.v0.9.0
- 3scale-community-operator:
-
- kiali-operator:
- deprecated package: kiali-operator
- deprecated channel: alpha
- deprecated version: kiali-operator.v1.68.0
- kiali-operator:
Acceptance Criteria
-
- Installed operators page
- Add the deprecation badge to the operator's Status field, if PackageManifest, Channel or Version is deprecated
- Operator Details page
- Add deprecation badge next to the operator's name if PackageManifest, Channel or Version is deprecated
- Add deprecation warning to the details page, if PackageManifest, Channel or Version is deprecated
- Link the the operator's Subscription tab if Channel or Version is deprecated
- In Subscription tab, the warning will contain "Update channel" link. In case of deprecated Channel, the "Change Subscription update channel" modal will need to get updated to contain warning icons next to deprecated channels.
- Installed operators page
- Add integration and unit tests
Description
If there is any PDB with SufficientPods have allowed disruptions equal to 0, then when cluster admin tries to drain a node it will through error as Pod disruption budget is violated. So in order to avoid this, add a warning message in Topology page similar to Resource quota warning message to let the user know about this violation.
Acceptance Criteria
- Create a util where it will fetch PDB for namespace and return how many PDB with disruptionsAllowed is 0 and with SufficientPods, if the count is 1, return the name also so that we can redirect to it's details page
- Use the util in Topology page and add Warning message similar to resource quota warning message.
- On click of warning message, if there is one PDB which is violated then redirect to it's details page or else to PDB list page
- Add YellowExclamationTriangleIcon to PDB list page to Allowed disruption column where rows having allowed disruption equal to 0. Add beside the count.
- Create unit test for the util
- Add e2e test (Automate this or manual????)
Additional Details:
Internal doc for reference - https://docs.google.com/document/d/1pa1jaYXPPMc-XhHt_syKecbrBaozhFg2_gKOz7E2JWw/edit
Feature Overview (aka. Goal Summary)
This about GAing the work we started with OCPSTRAT-1040
Goal is to remove experiment tag in command and document this
This is about GA-ing the work we started in OCPSTRAT-1040.
Goal is to remove the experimental keyword from the new command flag and document this.
Acceptance Criteria
- oc adm must-gather -
helpno longer shows thesinceand -since-time flags as experimental
As a customer of self managed OpenShift or an SRE managing a fleet of OpenShift clusters I should be able to determine the progress and state of an OCP upgrade and only be alerted if the cluster is unable to progress. Support a cli-status command and status-API which can be used by cluster-admin to monitor the progress. status command/API should also contain data to alert users about potential issues which can make the updates problematic.
Feature Overview (aka. Goal Summary)
Here are common update improvements from customer interactions on Update experience
- Show nodes where pod draining is taking more time.
Customers have to dig deeper often to find the nodes for further debugging.
The ask has been to bubble up this on the update progress window. - oc update status ?
From the UI we can see the progress of the update. From oc cli we can see this from "oc get cvo"
But the ask is to show more details in a human-readable format.
Know where the update has stopped. Consider adding at what run level it has stopped.
oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.12.0 True True 16s Working towards 4.12.4: 9 of 829 done (1% complete)

Documentation Considerations
Update docs for UX and CLI changes
Reference : https://docs.google.com/presentation/d/1cwxN30uno_9O8RayvcIAe8Owlds-5Wjr970sDxn7hPg/edit#slide=id.g2a2b8de8edb_0_22
Epic Goal*
Add a new command `oc adm upgrade status` command which is backed by an API. Please find the mock output of the command output attached in this card.
Why is this important? (mandatory)
- From the UI we can see the progress of the update. Using OC CLI we can see some of the information using "oc get clusterversion" but the output is not readable and it is a lot of extra information to process.
- Customer as asking us to show more details in a human-readable format as well provide an API which they can use for automation.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Tests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Other
Current state:
An update is in progress for 28m42s: Working towards 4.14.1: 700 of 859 done (81% complete), waiting on network = Control Plane = ... Completion: 91%
Improvement opportunities
1. Inconsistent info: CVO message says "700 of 859 done (81% complete)" but control plane section says "Completion: 91%"
2. Unclear measure of completion: CVO message counts manifest applied and control plane section says "Completion: 91%" which counts upgraded COs. Both messages do not state what they count. Manifest count is an internal implementation detail which users likely do not understand. COs are less so, but we should be more clear in what the completion means.
3. We could take advantage of this line and communicate progress with more details
Definition of Done
We'll only remove CVO message once the rest of the output functionally covers it, so the inconsistency stays until OTA-1154. Otherwise:
= Control Plane = ... Completion: 91% (30 operators upgraded, 1 upgrading, 2 waiting)
Upgraded operators are COs that updated its version, no matter its conditions
Upgrading operators are COs that havent updated its version and are Progressing=True
Waiting operators are COs that havent updated its version and are Progressing=False
=Control Plane Upgrade=
...
Completion: 45% (Est Time Remaining: 35m)
^^^^^^^^^^^^^^^^^^^^^^^^^
Do not worry too much about the precision, we can make this more precise in the future. I am thinking of
1. Assigning a fixed amount of time per CO remaining for COs that do not have daemonsets
2. Assign an amount of time proportional to # of workers to each remaining CO that has daemonsets (network, dns)
3. Assign a special amount of time proportional to # of workers to MCO
We can probably take into account the "how long are we upgrading this operator right now" exposed by CVO in OTA-1160
Discovered by Evgeni Vakhonin during OTA-1245, the 4.16 code did not take nodes that are members of multiple pools into account. This surfaced in several ways:
Duplicate insights (=we iterate over nodes over pools, so we see problematic edges in each pool it is a member of):
= Update Health = SINCE LEVEL IMPACT MESSAGE - Error Update Stalled Node ip-10-0-26-198.us-east-2.compute.internal is degraded - Error Update Stalled Node ip-10-0-26-198.us-east-2.compute.internal is degraded
Such node is present in all pool listings, and in some cases such as paused pools the output is confusing (paused-ness is a property of a pool, so we list a node as paused in one pool but outdated pending in another):
= Worker Pool = Worker Pool: mcpfoo Assessment: Excluded ... Worker Pool Node NAME ASSESSMENT PHASE VERSION EST MESSAGE ip-10-0-26-198.us-east-2.compute.internal Excluded Paused 4.15.12 - = Worker Pool = Worker Pool: worker ... Worker Pool Nodes NAME ASSESSMENT PHASE VERSION EST MESSAGE ip-10-0-26-198.us-east-2.compute.internal Outdated Pending 4.15.12 ?
It is not clear to me what would be the correct presentation of this case. Because this is an update status (and not node or cluster status) command, and only a single pool drives an update of a node, I'm thinking that maybe the best course of action would be to show only nodes whose version is driven by a given pool, or maybe come up with a "externally driven"-like assessment or whatever.
As an OTA engineer,
I would like to make sure the node in a single-node cluster is handled correctly in the upgrade-status command.
Context:
According to the discussion with the MCO team,
the node is in MCP/master but not worker.
This card is to make sure that the node are displayed that way too. My feeling is that the current code probably does the job already. In that case, we should add test coverage for the case to avoid regression in the future.
AC:
- The node is displayed in the master section in the output of the upgrade-status command.
- The node is NOT displayed in the worker section in the output of the upgrade-status command.
- A test case exists in https://github.com/openshift/oc/tree/master/pkg/cli/admin/upgrade/status/examples
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Enable GCP Workload Identity Webhook
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
Provide GCP workload identity webhook so a customer can more easily configure their applications to use the service account tokens minted by clusters that use GCP Workload Identity.{}
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
<enter general Feature acceptance here>
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Both, the scope of this is for self-managed |
| Classic (standalone cluster) | Classic |
| Hosted control planes | N/A |
| Multi node, Compact (three node), or Single node (SNO), or all | All |
| Connected / Restricted Network | All |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86_x64 |
| Operator compatibility | TBD |
| Backport needed (list applicable versions) | N/A |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | TBD |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Just like AWS STS and ARO Entra Workload ID, we want to provide the GCP workload identity webhook so a customer can more easily configure their applications to use the service account tokens minted by clusters that use GCP Workload Identity.
- For AWS, we deploy the AWS STS pod identity webhook as a customer convenience for configuring their applications to utilize service account tokens minted by a cluster that supports STS. When you create a pod that references a service account, the webhook looks for annotations on that service account and if found, the webhook mutates the deployment in order to set environment variables + mounts the service account token on that deployment so that the pod has everything it needs to make an API client.
- Our temporary access token (using TAT in place of STS because STS is AWS specific) enablement for (select) third party operators does not rely on the webhook and is instead using CCO to create a secret containing the variables based on the credentials requests. The service account token is also explicitly mounted for those operators. Pod identity webhooks were considered as an alternative to this approach but weren't chosen.
- Basically, if we deploy this webhook it will be for customer convenience and will enable us to potentially use the Azure pod identity webhook in the future if we so chose. Note that AKS provides this webhook and other clouds like Google offer a webhook solution for configuring customer applications.
- This is about providing parity with other solutions but not required for anything directly related to the product.
If we don't provide this Azure pod identity webhook method, customer would need to get the details via some other way like a secret or set explicitly as environment variables. With the webhook, you just annotate your service account. - For Azure pod identity webhook, see
CCO-363and https://azure.github.io/azure-workload-identity/docs/installation/mutating-admission-webhook.html.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Will require following
- fork webhook
- make part of build process + OCP build dockerfile receival
- write CCO controller which deploys the webhook
- see https://github.com/pfnet-research/gcp-workload-identity-federation-webhook
Background
- For AWS, we deploy the AWS STS pod identity webhook as a customer convenience for configuring their applications to utilize service account tokens minted by a cluster that supports STS. When you create a pod that references a service account, the webhook looks for annotations on that service account and if found, the webhook mutates the deployment in order to set environment variables + mounts the service account token on that deployment so that the pod has everything it needs to make an API client.
- Our temporary access token (using TAT in place of STS because STS is AWS specific) enablement for (select) third party operators does not rely on the webhook and is instead using CCO to create a secret containing the variables based on the credentials requests. The service account token is also explicitly mounted for those operators. Pod identity webhooks were considered as an alternative to this approach but weren't chosen.
- Basically, if we deploy this webhook it will be for customer convenience and will enable us to potentially use the Azure pod identity webhook in the future if we so chose. Note that AKS provides this webhook and other clouds like Google offer a webhook solution for configuring customer applications.
- This is about providing parity with other solutions but not required for anything directly related to the product.
If we don't provide this Azure pod identity webhook method, customer would need to get the details via some other way like a secret or set explicitly as environment variables. With the webhook, you just annotate your service account. - For Azure pod identity webhook, see
CCO-363and https://azure.github.io/azure-workload-identity/docs/installation/mutating-admission-webhook.html.
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer - specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision GCP infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The GCP IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing GCP Terraform provider. Specifically, we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Provision GCP infrastructure without the use of Terraform
Why is this important?
- Removing Terraform from Installer
Scenarios
- The new provider should aim to provide the same results as the existing GCP
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Description of problem:
failed to create control-plane machines using GCP marketplace image
Version-Release number of selected component (if applicable):
4.16.0-0.nightly-multi-2024-06-11-205940 / 4.16.0-0.nightly-2024-06-10-211334
How reproducible:
Always
Steps to Reproduce:
1. "create install-config", and then edit it to insert osImage settings (see [1]) 2. "create cluster" (see [2])
Actual results:
1. The bootstrap machine and the control-plane machines are not created. 2. Although it says "Waiting up to 15m0s (until 10:07AM CST)" for control-plane machines being provisioned, it did not time out until around 10:35AM CST.
Expected results:
The installation should succeed.
Additional info:
FYI a PROW CI test also has the issue: https://qe-private-deck-ci.apps.ci.l2s4.p1.openshiftapps.com/view/gs/qe-private-deck/pr-logs/pull/openshift_release/52816/rehearse-52816-periodic-ci-openshift-verification-tests-master-installer-rehearse-4.16-installer-rehearse-debug/1800431930391400448
Once support for private/internal clusters is added to CAPG in CORS-3252, we will need to integrate those changes into the installer:
- vendor updated capg
- update cluster manifest so internal cluster is default
- update load balancer creation (so external LB is created by installer and MCS configuration is added to CAPI-created LB)
- update DNS record creation (if needed) to ensure we are associating records with proper LB
Description of problem:
installing into Shared VPC stuck in waiting for network infrastructure ready
Version-Release number of selected component (if applicable):
4.17.0-0.nightly-2024-06-10-225505
How reproducible:
Always
Steps to Reproduce:
1. "create install-config" and then insert Shared VPC settings (see [1]) 2. activate the service account which has the minimum permissions in the host project (see [2]) 3. "create cluster" FYI The GCP project "openshift-qe" is the service project, and the GCP project "openshift-qe-shared-vpc" is the host project.
Actual results:
1. Getting stuck in waiting for network infrastructure to become ready, until Ctrl+C is pressed. 2. 2 firewall-rules are created in the service project unexpectedly (see [3]).
Expected results:
The installation should succeed, and there should be no any firewall-rule getting created either in the service project or in the host project.
Additional info:
When installconfig.platform.gcp.userTags is specified, all taggable resources should have the specified user tags.
This requires setting TechPreviewNoUpgrade featureSet to configure tags.
Use CAPG by default and remove it from TechPreview in 4.17.
Once https://github.com/openshift/installer/pull/8359 merges, which adds a call to CAPI DestroyBootstrap, the GCP bootstrap firewall rule should be removed. This rule was added in https://github.com/openshift/installer/pull/8374.
When creating a Private Cluster with CAPG the cloud-controller-manager generates an error when the instance-group is created:
I0611 00:04:34.998546 1 event.go:376] "Event occurred" object="openshift-ingress/router-default" fieldPath="" kind="Service" apiVersion="v1" type="Warning" reason="SyncLoadBalancerFailed" message="Error syncing load balancer: failed to ensure load balancer: googleapi: Error 400: Resource 'projects/openshift-dev-installer/zones/us-east1-b/instances/bfournie-capg-test-6vn69-worker-b-rghf7' is expected to be in the subnetwork 'projects/openshift-dev-installer/regions/us-east1/subnetworks/bfournie-capg-test-6vn69-master-subnet' but is in the subnetwork 'projects/openshift-dev-installer/regions/us-east1/subnetworks/bfournie-capg-test-6vn69-worker-subnet'., wrongSubnetwork"
Three "k8s-ig" instance-groups were created for the Internal LoadBlancer. Of the 3, the first one is using the master subnet
subnetwork: https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/regions/us-east1/subnetworks/bfournie-capg-test-6vn69-master-subnet
while the other two are using the worker-subnet. Since this IG uses the master-subnet and the instance is using the worker-subnet it results in this mismatch.
This looks similar to issue tracked (and closed) with cloud-provider-gcp
https://github.com/kubernetes/cloud-provider-gcp/pull/605
Once a new version of CAPG is released we'll need to pick it up.
Related to https://issues.redhat.com/browse/CORS-3445, we need to ensure that pre-created ServiceAccounts can be passed in and used by a CAPG installation.
We are occasionally seeing this error when using GCP with TechPreview, i.e. using CAPG.
waiting for api to be available
level=warning msg=FeatureSet "TechPreviewNoUpgrade" is enabled. This FeatureSet does not allow upgrades and may affect the supportability of the cluster.
level=info msg=Creating infrastructure resources...
level=error msg=failed to fetch Cluster: failed to generate asset "Cluster": failed to create cluster: failed during pre-provisioning: failed to add worker roles: failed to set project IAM policy: googleapi: Error 409: There were concurrent policy changes. Please retry the whole read-modify-write with exponential backoff. The request's ETag '\007\006\033\255\347+\335\210' did not match the current policy's ETag '\007\006\033\255\347>%\332'., aborted
Installer exit with code 4
Install attempt 3 of 3
This is a clone of issue OCPBUGS-38152. The following is the description of the original issue:
—
Description of problem:
Shared VPC installation using service account having all required permissions failed due to cluster operator ingress degraded, by telling error "error getting load balancer's firewall: googleapi: Error 403: Required 'compute.firewalls.get' permission for 'projects/openshift-qe-shared-vpc/global/firewalls/k8s-fw-a5b1f420669b3474d959cff80e8452dc'"
Version-Release number of selected component (if applicable):
4.17.0-0.nightly-multi-2024-08-07-221959
How reproducible:
Always
Steps to Reproduce:
1. "create install-config", then insert the interested settings (see [1]) 2. "create cluster" (see [2])
Actual results:
Installation failed, because cluster operator ingress degraded (see [2] and [3]). $ oc get co ingress NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE ingress False True True 113m The "default" ingress controller reports Available=False: IngressControllerUnavailable: One or more status conditions indicate unavailable: LoadBalancerReady=False (SyncLoadBalancerFailed: The service-controller component is reporting SyncLoadBalancerFailed events like: Error syncing load balancer: failed to ensure load balancer: error getting load balancer's firewall: googleapi: Error 403: Required 'compute.firewalls.get' permission for 'projects/openshift-qe-shared-vpc/global/firewalls/k8s-fw-a5b1f420669b3474d959cff80e8452dc', forbidden... $ In fact the mentioned k8s firewall-rule doesn't exist in the host project (see [4]), and, the given service account does have enough permissions (see [6]).
Expected results:
Installation succeeds, and all cluster operators are healthy.
Additional info:
Feature Overview (aka. Goal Summary)
Customers have requested the ability to have the ability to apply tolerations to the HCP control plane pods. This provides the flexibility to have the HCP pods scheduled to nodes with taints applied to them that are not currently tolerated by default.
API
Add new field to HostedCluster. hc.Spec.Tolerations
Tolerations []corev1.Toleration `json:"tolerations,omitempty"`
Implementation
In support/config/deployment.go, add hc.spec.tolerations from hc when generating the default config. This will cause the toleration to naturally get spread to the deployments and statefulsets.
CLI
Add new cli argument called –tolerations to the hcp cli tool during cluster creation. This argument should be able to be set multiple times. The syntax of the field should follow the convention set by the kubectl client tool when setting a taint on a node.
For example, the kubectl client tool can be used to set the following taint on a node.
kubectl taint nodes node1 key1=value1:NoSchedule
And then the hcp cli tool should be able to add a toleration for this taint during creation with the following cli arg.
hcp cluster create kubevirt –toleration “key1=value1:noSchedule” …
Goals (aka. expected user outcomes)
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
<enter general Feature acceptance here>
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Customers have requested the ability to have the ability to apply tolerations to the HCP control plane pods. This provides the flexibility to have the HCP pods scheduled to nodes with taints applied to them that are not currently tolerated by default.
API
Add new field to HostedCluster. hc.Spec.Tolerations
Tolerations []corev1.Toleration `json:"tolerations,omitempty"`
Implementation
In support/config/deployment.go, add hc.spec.tolerations from hc when generating the default config. This will cause the toleration to naturally get spread to the deployments and statefulsets.
CLI
Add new cli argument called –tolerations to the hcp cli tool during cluster creation. This argument should be able to be set multiple times. The syntax of the field should follow the convention set by the kubectl client tool when setting a taint on a node.
For example, the kubectl client tool can be used to set the following taint on a node.
kubectl taint nodes node1 key1=value1:NoSchedule
And then the hcp cli tool should be able to add a toleration for this taint during creation with the following cli arg.
hcp cluster create kubevirt –toleration “key1=value1:noSchedule” …
The OCP snapshot controller needs to be updated in the pkg/operator/starter.go file to account for HCP tolerations
The cluster-network-operator needs to be HCP tolerations aware, otherwise controllers (like multus and ovn) won't be deployed by the CNO with the correct tolerations.
The code that looks at the HostedControlPlane within the CNO can be found in pkg/hypershift/hypershift.go. https://github.com/openshift/cluster-network-operator/blob/33070b57aac78118eea34060adef7f2fb7b7b4bf/pkg/hypershift/hypershift.go#L134
API
Add new field to HostedCluster. hc.Spec.Tolerations
Tolerations []corev1.Toleration `json:"tolerations,omitempty"`
Implementation
In support/config/deployment.go, add hc.spec.tolerations from hc when generating the default config. This will cause the toleration to naturally get spread to the deployments and statefulsets.
Feature Overview (aka. Goal Summary)
The objective is to create a comprehensive backup and restore mechanism for HCP OpenShift Virtualization Provider. This feature ensures both the HCP state and the worker node state are backed up and can be restored efficiently, addressing the unique requirements of KubeVirt environments.
Goals (aka. Expected User Outcomes)
- Users will be able to backup and restore the KubeVirt HCP cluster, including both HCP state and worker node state.
- Ensures continuity and reliability of operations after a restore, minimizing downtime and data loss.
- Supports seamless re-connection of HCP to worker nodes post-restore.
Requirements (aka. Acceptance Criteria)
- Backup of KubeVirt CSI infra PVCs
- Backup of KubeVirt VMs + VM state + (possibly even network attachment definitions)
- Backup of Cloud Provider KubeVirt Infra Load Balancer services (having IP addresses change here on the service could be problematic)
- Backup of Any custom network policies associated with VM pods
- Backup of VMs and state placed on External Infra
Use Cases (Optional)
- Disaster Recovery: In case of a disaster, the system can restore the HCP and worker nodes to the previous state, ensuring minimal disruption.
- Cluster Migration: Allows migration of hosted clusters across different management clusters/
- System Upgrades: Facilitates safe upgrades by providing a reliable restore point.
Out of Scope
- Real-time synchronization of backup data.
- Non-disruptive Backup and restore (ideal but not required)
Documentation Considerations
- Detailed guides on how to perform backup and restore operations for OpenShift Virtualizations, ideally aligning with the DR section: https://docs.openshift.com/container-platform/4.15/hosted_control_planes/hcp_high_availability/hcp-recovering-etcd-cluster.html
- Troubleshooting section for common issues during restoration.
Interoperability Considerations
- Impact on other projects like ACM/MCE vol-sync.
- Test scenarios to validate interoperability with existing backup solutions.
The HCP team has delivered OADP backup and restore steps for the Agent and AWS provider here. We need to add the steps necessary to make these steps work for HCP KubeVirt clusters.
Requirements
- Deliver backup/restore steps that reach feature parity with the documented agent and aws platforms
- Ensure that kubevirt-csi and cloud-provider-kubevirt LBs can be backup and restored successfully
- Ensure this works with external infra
Non Requirements
- VMs do not need to be backed up to reach feature parity because the current aws/agent steps require the cluster to scale down to zero before backing up.
Feature Overview (aka. Goal Summary)
The etcd-operator should automatically rotate the etcd-signer and etcd-metrics-signer certs as they approach expiry.
Goals (aka. expected user outcomes)
- We must have a tested path for auto rotation of certificates when certs need rotation due to age
Requirements (aka. Acceptance Criteria):
Deliver rotation and recovery requirements from OCPSTRAT-714
Epic Goal*
The etcd cert rotation controller should automatically rotate the etcd-signer and etcd-metrics-signer certs (and re-sign leaf certs) as they approach expiry.
Why is this important? (mandatory)
Automatic rotation of the signer certs will reduce the operational burden of having to manually rotate the signer certs.
Scenarios (mandatory)
etcd-signer and etcd-metrics-signer certs are rotated as they approach the end of their validity period. For the signer certs this is 4.5 years.
https://github.com/openshift/cluster-etcd-operator/blob/d8f87ecf9b3af3cde87206762a8ca88d12bc37f5/pkg/tlshelpers/tlshelpers.go#L32
Dependencies (internal and external) (mandatory)
None
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - etcd team
- Documentation - etcd docs team
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
We shall never allow new leaf certificates to be generated when a revision rollout is in progress AND when the bundle was just changed.
From ETCD-606 we know when a bundle has changed, so we can save the current revision in the operator status and only allow leaf updates on the next higher revision.
NOTE: this assumes etcd rolls out slower than apiserver in practice. We should also think about how we can in-cooperate the revision rollout on the apiserver static pods.
in ETCD-565 we have added tests to manually rotate certificate.
In the recovery test suite, depending on the order of execution we have the following failures:
1. : [sig-etcd][Feature:CertRotation][Suite:openshift/etcd/recovery] etcd can recreate trust bundle [Timeout:15m]
Here the tests usually time out waiting for a revision rollout - couldn't find a deeper cause, maybe the timeout is not large enough.
2. : [sig-etcd][Feature:CertRotation][Suite:openshift/etcd/recovery] etcd can recreate dynamic certificates [Timeout:15m]
The recovery test suite creates several new nodes. When choosing a peer secret, we sometimes choose one that has no member/node anymore and thus it will never be recreated.
3. after https://github.com/openshift/cluster-etcd-operator/pull/1269
After the leaf gating has merged, some certificates are not in their original place anymore, which invalidates the manual rotation procedure
For backward compatibility we tried to keep the previous named certificates the way they were:
https://github.com/openshift/cluster-etcd-operator/blob/master/pkg/operator/starter.go#L614-L639
Many of those are currently merely copied with the ResourceSyncController and could be replaced with their source configmap/secret.
This should help with easier understanding and mental load of the codebase.
Some replacement suggestions:
- etcd-serving-ca -> etcd-ca-bundle
- etcd-peer-client-ca -> etcd-ca-bundle
- etcd-metrics-proxy-serving-ca -> etcd-metrics-ca-bundle
- etcd-metrics-proxy-client-ca -> etcd-metrics-ca-bundle
AC:
- replaced the above suggestions
- updated static pod manifests and references in backups
- updated docs/etcd-tls-assets.md
All openshift TLS artifacts (secrets and configmaps) now have a requirement to have an annotation for user facing descriptions per the metadata registry for TLS artifacts.
https://github.com/openshift/origin/tree/master/tls
There is a guideline for how these descriptions must be written:
https://github.com/openshift/origin/blob/master/tls/descriptions/descriptions.md#how-to-meet-the-requirement
The descriptions for the etcd's TLS artifacts don't meet that requirement and should be updated to point out the required details e.g hostnames, subjects and what kind of certificates the signer is signing.
https://github.com/openshift/origin/blob/8ffdb0e38af1319da4a67e391ee9c973d865f727/tls/descriptions/descriptions.md#certificates-22-1
https://github.com/openshift/cluster-etcd-operator/blob/master/pkg/tlshelpers/tlshelpers.go#L74
See also:
https://github.com/openshift/origin/blob/master/tls/descriptions/descriptions.md#Certificates-85
Currently a new revision is created when the ca bundle configmaps (etcd-signer / metrics-signer) have changed.
As of today, this change is not transactional across invocations of EnsureConfigMapCABundle, meaning that four revisions (at most, one for each function call) could be created.
For gating the leaf cert generation on a fixed revision number, it's important to ensure that any bundle change will only ever result in exactly one revision change.
We currently ensure this for leaf certificates by a single update to "etcd-all-certs", we can use the exact same trick again.
AC:
- create a single revisioned configmap that contains all relevant CA bundles
- update all static pod manifests to read from that configmap instead of the two existing ones
additional salvage/refactoring from previously reverted ETCD-579
This feature request proposes adding the Partition Number within a Placement Group for OpenShift MachineSets & in CAPI. Currently, OCP 4.14 supports pre-created Placement Groups (RFE-2194). But the feature to define the Partition Number within those groups is missing.
Partition placement groups offer a more granular approach to instance allocation within an Availability Zone on AWS, particularly beneficial for deployments on AWS Outpost (https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups-outpost.html). It also allows users to further enhance high availability by distributing instances across isolated hardware units within the chosen Placement Group. This improves fault tolerance by minimizing the impact of hardware failures to only instances within the same partition.
Some Benefits are listed below.
- By leveraging Partition Numbers, users can achieve a higher level of availability for their OpenShift clusters on AWS Outpost, as failures within a partition won't affect instances in other partitions.
- Distributing instances across isolated hardware units minimizes the impact of hardware failures, ensuring service continuity.
- It provides optimized resource utilization.
Update MAPI to Support AWS Placement Group Partition Number
Based on RFE-2194, support for pre-created Placement Groups was added in OCP. Following that, it is requested in RFE-4965 to have the ability to specify the Partition Number of the Placement Group as this allows more precise allocation.
NOTE: Placement Group (and Partition) will be pre-created by the user. User should be able to specify Partition Number along with PlacementGroupName on EC2 level to improve availability.
References
- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
- https://docs.aws.amazon.com/AWSEC2/latest/APIReference/API_Placement.html
- https://github.com/kubernetes-sigs/cluster-api-provider-aws/pull/4273
Upstream changes: CFE-1041
Add a new field (PlacementGroupPartition) in AWSMachineProviderConfig to allow users specify the Partition Number for AWSMachine
Description of problem:
Create machineset with invalid placementGroupPartition 0, it will be cleared in machineset, machine created successfully and placed inside an auto-chosen partition number, but should create failed
Version-Release number of selected component (if applicable):
4.17.0-0.nightly-2024-07-01-124741
How reproducible:
Always
Steps to Reproduce:
1.Create a machineset with a pre-created partition placement group and placementGroupPartition = 0
placementGroupName: pgpartition
placementGroupPartition: 0
2.The placementGroupPartition was cleared in the machineset, and the machine created successfully in pgpartition placement group and placed inside an auto-chosen partition number
Actual results:
The machine created and placed inside an auto-chosen partition number.
Expected results:
The machine should fail and give error message like other invalid values. errorMessage: 'error launching instance: Value ''8'' is not a valid value for PartitionNumber. Use a value between 1 and 7.'
Additional info:
It's a new feature test for https://issues.redhat.com/browse/CFE-1066
Implement changes in machine-api-provider-aws to support partition number while creating instance.
Acceptance criteria:
- Add implementation to support PlacementGroupPartition during AWS instance creation
- Add unit tests
- Vendor
CFE-1063into machine-api-operator to support PlacementGroupPartition in AWSMachineProviderConfig to allow users specify the Partition Number of placement group. - Add webhook validation to check non-empty PlacementGroupName while using PlacementGroupPartition
- Add necessary unit tests
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
We have multiple customers that are asking us to disable the vsphere CSI driver/operator as a day 2 operation. The goal of this epic is to provide a safe API that will remove the vSphere CSI/Operator. This will also silent the VPD alerts as we received several complaints about VPD raising to many.
IMPORTANT: As disabling a storage driver from a running environment can be risky, the use of this API will only be allowed through a RH customer support case. Support will ensure that it is safe to proceed and guide the customer through the process.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
Customers want to disable vSphere CSI because this requires several vsphere permissions that they don't want to allow at the OCP level, not setting these permissions ends up with constant and recurring alerting. These customers don't want to use vsphere CSI usually because they use another storage solution.
The goal is to provide an API that disables vSphere storage intergration as well as the VPD alerts which will still be present in the logs but not raise (no alerts, lower frequency of checks, lower severity).
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
vsphere CSI/Operator is disabled and no VDP alerts are raised. Logs are still present.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | self managed |
| Classic (standalone cluster) | yes vsphere only |
| Hosted control planes | N/A |
| Multi node, Compact (three node), or Single node (SNO), or all | vsphere only usually not SNO |
| Connected / Restricted Network | both |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all applicable to vsphere |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | none |
| Other (please specify) | Available only through RH support case |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
As an admin I want to disable the vsphere CSI driver because I am using another storage solution.
As an admin I want to disable the vsphere CSI driver because it requires too many vsphere permissions and keep raising OCP alerts.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
What to do if there is existing PVs?
How do we manage general alerts if VPD alert are silenced?
What do we do if customer tries to install the upstream vsphere CSI?
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Replace the Red Hat vSphere CSI with the vmware upstream driver. We can consider this use case in a second phase if there is an actual demand.
Public availability. To begin with this will be only possible through RH support.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Several customers requests asking to disable vsphere CSI drivers.
see https://issues.redhat.com/browse/RFE-3821
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Understand why the customer wants to disable it in the first. Be extra careful with pre-flight checks in order to make sure that it is safe to proceed with.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
No public doc, we need a detailed documentation for our support organisation that includes, pre-flight checks, the differents steps, confirmation that everything works as expected and basic troubleshooting guide. Likely an internal KB or whatever works best for support.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Applies to vsphere only
Epic Goal*
Provide a nice and user-friendly API to disable integration between OCP storage and vSphere.
Why is this important? (mandatory)
This is continuation of STOR-1766. In the old releases we want to provide a dirty way to disable vSphere CSI driver in 4.12 - 4.16.
This epic provides a nice and explicit API to disable the CSI driver in 4.17 (or where is this epic implemented), and ensures the cluster can be upgraded to any future OCP version.
Scenarios (mandatory)
- As OCP cluster admin, I want to disable the CSI driver as day 2 operation (i.e. I can't disable Storage capability), so the vSphere CSI driver + its operator does not mess up with my vSphere.
- As OCP cluster admin, I want to update my 4.12 cluster with the vSphere CSI driver removed in a dirty way (
STOR-1766) all the way to 4.17 and then use a nice API to disable the CSI driver forever.
Dependencies (internal and external) (mandatory)
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be "Release Pending"
- https://github.com/openshift/cluster-storage-operator/pull/487
- https://github.com/openshift/cluster-storage-operator/pull/485
- https://github.com/openshift/vmware-vsphere-csi-driver-operator/pull/233
- https://github.com/openshift/vsphere-problem-detector/pull/169
- https://github.com/openshift/vsphere-problem-detector/pull/166
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Allow customer to enabled EFS CSI usage metrics.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
OCP already supports exposing CSI usage metrics however the EFS metrics are not enabled by default. The goal of this feature is to allows customers to optionally turn on EFS CSI usage metrics in order to see them in the OCP console.
The EFS metrics are not enabled by default for a good reason as it can potentially impact performances. It's disabled in OCP, because the CSI driver would walk through the whole volume, and that can be very slow on large volumes. For this reason, the default will remain the same (no metrics), customers would need explicitly opt-in.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Clear procedure on how to enable it as a day 2 operation. Default remains no metrics. Once enabled the metrics should be available for visualisation.
We should also have a way to disable metrics.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | both |
| Classic (standalone cluster) | yes |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | AWS only |
| Connected / Restricted Network | both |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all AWS/EFS supported |
| Operator compatibility | EFS CSI operator |
| Backport needed (list applicable versions) | No |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | Should appear in OCP UI automatically |
| Other (please specify) | OCP on AWS only |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
As an OCP user i want to be able to visualise the EFS CSI metrics
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Additional metrics
Enabling metrics by default.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer request as per
https://issues.redhat.com/browse/RFE-3290
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
We need to be extra clear on the potential performance impact
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Document how to enable CSI metrics + warning about the potential performance impact.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
It can benefit any cluster on AWS using EFS CSI including ROSA
Epic Goal*
This goal of this epic is to provide a way to admin to turn on EFS CSI usage metrics. Since this could lead to performance because the CSI driver would walk through the whole volume this option will not be enabled by default; admin will need to explicitly opt-in.
Why is this important? (mandatory)
Turning on EFS metrics allows users to monitor how much EFS space is being used by OCP.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- As an admin I would like to turn on EFS CSI metrics
- As an admin I would like to visualise how much EFS space is used by OCP.
Dependencies (internal and external) (mandatory)
None
Contributing Teams(and contacts) (mandatory)
- Development - STOR
- Documentation - STOR
- QE - STOR
- PX - Yes, knowledge transfer
- Others -
Acceptance Criteria (optional)
Enable CSI metrics via the operator - ensure the driver is started with the proper cmdline options. Verify that the metrics are sent and exposed to the users.
Drawbacks or Risk (optional)
Metrics are calculated by walking through the whole volume which can impact performances. For this reason enabling CSI metrics will need an explicit opt-in from the admin. This risk needs to be explicitly documented.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Description of problem:
The original PR had all the labels, but it didn't merge on time for code freeze duo to CI flakes.
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1.
2.
3.
Actual results:
Expected results:
Additional info:
Feature Overview (aka. Goal Summary)
Some customers have expressed the need to have a control plane with nodes of a different architecture from the compute nodes in a cluster. This may be to realise cost or power savings or maybe just to benefit from cloud providers in-house hardware.
While this config can be achieved with Hosted Control Planes the customers also want to use Multi-architecture compute to achieve these configs, ideally at install time.
This feature is to track the implementation of this offering with Arm nodes running in the AWS cloud.
Goals (aka. expected user outcomes)
Customers will be able to install OpenShift clusters that contain control plane and compute nodes of different architectures
Requirements (aka. Acceptance Criteria):
- Install a cluster with an x86 control plane arm workers
- Install a cluster with an arm control plane x86 workers
- Validate that the installer can support the above configurations (ie fails gracefully with single arch payload)
- Provide a way for the user to know that their installer can support multi-arch installs.(ie openshift-install version)
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Yes |
| Classic (standalone cluster) | Yes |
| Hosted control planes | Yes |
| Multi node, Compact (three node), or Single node (SNO), or all | Yes |
| Connected / Restricted Network | Yes |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86 and Arm |
| Operator compatibility | n/a |
| Backport needed (list applicable versions) | n/a |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | n/a |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Epic Goal
- Install a cluster in AWS with different cpu architectures for the control plane and workers.
Acceptance Criteria
- Install a cluster with an x86 control plane arm workers
- Install a cluster with an arm control plane x86 workers
- Validate that the installer can support the above configurations (ie fails gracefully with single arch payload)
- Provide a way for the user to know that their installer can support multi-arch installs.(ie openshift-install version)
Allow mixing Control Plane and Compute CPU archs, bypass with warnings if the user overrides the release image. Put behind a feature gate.
Add validation in the Installer to not allow install with multi-arch nodes using a single-arch release payload.
The validation needs to be skipped (or just a warning) when the release payload architecture cannot be determined (e.g. when using OPENSHIFT_INSTALL_RELEASE_IMAGE_OVERRIDE).
Currently the installer doesn't expose if the release payload is multi or single arch:
./openshift-install version ./openshift-install 4.y.z built from commit xx release image quay.io/openshift-release-dev/ocp-release@sha256:xxx release architecture amd64
Or delete the feature gate altogether if we are allowed to do so.
Feature Overview (aka. Goal Summary)
Some customers have expressed the need to have a control plane with nodes of a different architecture from the compute nodes in a cluster. This may be to realise cost or power savings or maybe just to benefit from cloud providers in-house hardware.
While this config can be achieved with Hosted Control Planes the customers also want to use Multi-architecture compute to achieve these configs, ideally at install time.
This feature is to track the implementation of this offering with Arm nodes running in the AWS cloud.
Goals (aka. expected user outcomes)
Customers will be able to install OpenShift clusters that contain control plane and compute nodes of different architectures
Requirements (aka. Acceptance Criteria):
- Install a cluster with an x86 control plane arm workers
- Install a cluster with an arm control plane x86 workers
- Validate that the installer can support the above configurations (ie fails gracefully with single arch payload)
- Provide a way for the user to know that their installer can support multi-arch installs.(ie openshift-install version)
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Yes |
| Classic (standalone cluster) | Yes |
| Hosted control planes | Yes |
| Multi node, Compact (three node), or Single node (SNO), or all | Yes |
| Connected / Restricted Network | Yes |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86 and Arm |
| Operator compatibility | n/a |
| Backport needed (list applicable versions) | n/a |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | n/a |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Epic Goal
- Install a cluster in GCP with different cpu architectures for the control plane and workers.
Why is this important?
Scenarios
1. …
Acceptance Criteria
- Install a cluster with an x86 control plane arm workers
- Install a cluster with an arm control plane x86 workers
- Validate that the installer can support the above configurations (ie fails gracefully with single arch payload)
Dependencies (internal and external)
1. …
Previous Work (Optional):
1. …
Open questions::
1.
Done Checklist
- CI - For new features (non-enablement), existing Multi-Arch CI jobs are not broken by the Epic
- Release Enablement: <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR orf GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - If the Epic is adding a new stream, downstream build attached to advisory: <link to errata>
- QE - Test plans in Test Plan tracking software (e.g. Polarion, RQM, etc.): <link or reference to the Test Plan>
- QE - Automated tests merged: <link or reference to automated tests>
- QE - QE to verify documentation when testing
- DOC - Downstream documentation merged: <link to meaningful PR>
- All the stories, tasks, sub-tasks and bugs that belong to this epic need to have been completed and indicated by a status of 'Done'.
Or delete the feature gate altogether if we are allowed to do so.
Feature Overview (aka. Goal Summary)
Enable CPU manager on s390x.
Why is this important?
CPU manager is an important component to manage performance of OpenShift and utilize the respective platforms.
Goals (aka. expected user outcomes)
Enable CPU manager on s390x.
Requirements (aka. Acceptance Criteria):
CPU manager works on s390x.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Y |
| Classic (standalone cluster) | Y |
| Hosted control planes | Y |
| Multi node, Compact (three node), or Single node (SNO), or all | Y |
| Connected / Restricted Network | Y |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | IBM Z |
| Operator compatibility | n/a |
| Backport needed (list applicable versions) | n/a |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | n/a |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Feature Overview
oc-mirror to include the RHCOS image for HyperShift KubeVirt provider when mirroring the OCP release payload
Goals
When using the KubeVirt (OpenShift Virtualization) provider for HyperShift, the KubeVirt VMs that are going to serve as nodes for the hosted clusters will consume an RHOCS image shipped as a container-disk image for KubeVirt.
In order to have it working on disconnected/air-gapped environments, its image must be part of the mirroring process.
Overview
Refer to RFE-5468
The coreos image is needed to ensure seamless deployment of HyperShift KubeVirt functionality in disconnected/air-gapped environments.
Solution
This story will address this issue, in that oc-mirror will include the cores kubevirt container image in the release payload
The image is found in the file release-manifests/0000_50_installer_coreos-bootimages.yaml
A field kubeVirtContainer (default false) will be added to the current v2 imagesetconfig and if set to true, the release collector will have logic to read and parse the yaml file correctly to extract and add the "DigestRef" (digest) to the release payload
Feature Overview (aka. Goal Summary)
As a product manager or business owner of OpenShift Lightspeed. I want to track who is using what feature of OLS and WHY. I also want to track the product adoption rate so that I can make decision about the product ( add/remove feature , add new investment )
Requirements (aka. Acceptance Criteria):
- Gaurav and Jan are working to come up with a list of KPIs to track https://miro.com/app/board/uXjVKIhVw5U=/
Notes:
- Once finalized all this KPI will converted to what metrics and based on that build a dashboard that can help in visualize the those KPI progress
- Here is an example of how ALS has build their dashboard : https://app.amplitude.com/analytics/redhat/space/574rvc9/all
Enable moniotring of OLS by defult when a user install OLS operator ---> check the box by defualt
Users will have the ability to disable the monitoring by . ----> in check the box
Refer to this slack conversation :https://redhat-internal.slack.com/archives/C068JAU4Y0P/p1723564267962489

Description of problem:
When installing the OpenShift Lightspeed operator, cluster monitoring should be enabled by default.
Version-Release number of selected component (if applicable):
How reproducible:
Always
Steps to Reproduce:
1. Click OpenShift Lightspeed in operator catalog
2. Click Install
Actual results:
"Enable Operator recommended cluster monitoring on this Namespace" checkbox is not selected by default.
Expected results:
"Enable Operator recommended cluster monitoring on this Namespace" checkbox should be selected by default.
Additional info:
Feature Overview (aka. Goal Summary)
This ticket focuses on a reduced scope compared to the initial Tech Preview outlined in OCPSTRAT-1327.
Specifically, the console in the 4.17 Tech Preview release allows customers to:
- discover collections of Kubernetes extension/operator content released in FBC format within a new ecosystem catalog UI in the 'Administrator Perspective' of the console, powered by the OLM v1 catalog API.
- view a list of installed Kubernetes extension/operator objects (previously installed via CLI) and easily edit them using the built-in YAML editor in the console.
Goals (aka. expected user outcomes)
1) Pre-installation:
- Both cluster-admins and non-privileged end-users can explore and discover the layered capabilities or workloads provided by Kubernetes extensions/operators in a new unified ecosystem catalog UI within the console's Administrator Perspective.
- (This catalog will be expanded to include content packaged as Helm charts in the future.)
- Users can filter available offerings by the provider (Red Hat, ISV, community, etc), valid subscription, infrastructure features, and other criteria in the new unified ecosystem catalog UI.
- In this Tech Preview release, users can view detailed descriptions and other metadata for the latest version within the default channel.
- (Future releases will expand this to allow users to discover all versions across all channels defined by an offering or package within a catalog and select a specific version from a desired channel.)
2) Post-installation:
- In this Tech Preview release, users with access to OLM v1's ClusterExtension API can view a list of installed Kubernetes extension/operator objects (previously installed via CLI) and easily create, read, update, and delete them using the console's built-in YAML editor.
Requirements (aka. Acceptance Criteria):
All the expected user outcomes and the acceptance criteria in the engineering epics are covered.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Our customers will experience a streamlined approach to managing layered capabilities and workloads delivered through operators, operators packaged in Helm charts, or even plain Helm charts. The next generation OLM will power this central distribution mechanism within the OpenShift in the future.
Customers will be able to explore and discover the layered capabilities or workloads, and then install those offerings and make them available on their OpenShift clusters. Similar to the experience with the current OperatorHub, customers will be able to sort and filter the available offerings based on the delivery mechanism (i.e., operator-backed or plain helm charts), source type (i.e., from Red Hat or ISVs), valid subscriptions, infrastructure features, etc. Once click on a specific offering, they see the details which include the description, usage, and requirements of the offering, the provided services in APIs, and the rest of the relevant metadata for making the decisions.
The next-gen OLM aims to unify workload management. This includes operators packaged for current OLM, operators packaged in Helm charts, and even plain Helm charts for workloads. We want to leverage the current support for managing plain Helm charts within OpenShift and the console for leveraging our investment over the years.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Refer to the “Documentation Considerations” section of the OLM v1 GA feature.
Relevant documents
- Next-gen OLM UX: Unifying workload management
- Next-gen OLM UX: Unifying workload management
- Operator Framework F2F - PM Session
- PRD OLM 1.0
- OLM F2F Discussion - Roadmap
- Post F2F Roadmap
This epic contains all the OLM related stories for OCP release-4.17. This was cloned from the original epic which contained a spike to create stories and a plan to support the OLM v1 api
Some docs that detail the OLM v1 Upgrade: https://docs.google.com/document/d/1D--lL8gnoDvs0vl72WZl675T23XcsYIfgW4yhuneCug/edit#heading=h.3l98owr87ve
Epic Goal
- Results from planning spike in 4.16
AC: Implement a catalog view, which lists available OLM v1 packages
- MVP - Both cluster-admins or non-privileged end-users can explore and discover the layered capabilities or workloads delivered by k8s extensions/operators or plain helm charts from a unified ecosystem catalog UI in the ‘Administrator Perspective’ in the console.
- Stretch - Users can filter the available offerings based on the delivery mechanism/source type (i.e., operator-backed or plain helm charts), providers (i.e., from Red Hat or ISVs), valid subscriptions, infrastructure features, etc.
- Enable the Catalog view only when the OLMv1 is installed on the cluster.
Feature Overview (aka. Goal Summary)
This ticket outlines the scope of the Tech Preview release for OCP 4.17
This Tech Preview release grants early access to upcoming features in the next-generation Operator Lifecycle Manager (OLM v1). Customers can now test these functionalities and provide valuable feedback during development.
Goals (aka. expected user outcomes)
Highlights of OLM v1 Phase 4 Preview:
- Safe CRD upgrades: Prevent data loss due to CRD schema changes
- Clear compatibility reporting: Improved status reporting for supported and unsupported operator bundles
- Clear ownership: Prevent conflicts between multiple ClusterExtensions managing the same resources
- Least privilege principle: Adhere to security best practices by using dedicated ServiceAccounts for installing/upgrading content
- Secure communication: Protect catalog data with HTTPS encryption for catalogd webserver responses
- Laying the groundwork for native Helm chart support: OLM v1 embeds Helm, doing the heavy lifting to enable future native support for Helm chart-packaged content
Requirements (aka. Acceptance Criteria):
All the expected user outcomes and the acceptance criteria in the engineering epics are covered.
Background
Leveraging learnings and customer feedback since OCP 4's inception, OLM v1 is designed to be a major overhaul.
With OpenShift 4.17, we are one step closer to the highly anticipated general availability (GA) of the next-generation OLM.
See the OCPSTRAT feature for OLM v1 GA:
- OCPSTRAT-1347 [GA release] Next-gen OLM (OLM v1)
Documentation Considerations
- Safe CRD Upgrades: [TP release] Docs explain OLM v1's current approach to prevent data loss due to CRD schema changes during the ClusterExtension upgrade.
- Clear compatibility reporting: [TP release] Docs introduce OLM v1's current approach to communicating the supported and unsupported operator bundles during installation.
- Clear Ownership: [TP release] Docs explain OLM v1's effort to prevent conflicts between multiple ClusterExtensions managing the same resources.
- Least Privilege Principle: [TP release] Docs explain OLM v1's design rationale behind adhering to security best practices by using dedicated ServiceAccounts for installing/upgrading content, showcasing the installation/upgrade flow with ServiceAccounts w/o and w/ enough permissions associated with it.
- Secure Communication: [TP release] Docs explain OLM v1's security stance in protecting catalog data with HTTPS encryption for catalogd webserver responses.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Operator controller no longer depends on the rukpak APIs and controllers, and we do not intend to support them in OLMv1 going forward. We need to remove the rukpak APIs and controllers from the payload to ensure they are not present/do not run.
Remove Rukpak from cluster-olm-operator
Stop building rukpak for OCP 4.17
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Use HTTPS for catalogd webserver before we GA the Catalog API
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- Upstream parent issue: https://github.com/operator-framework/catalogd/issues/242
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
operator-controller manifests will need to be updated to create a configmap for service-ca-operator to inject the CA bundle into. In order to not break the payload, cluster-olm-operator will need to be updated to have create, update, patch permissions for the configmap we are creating. Following the principle of least privilege, the permissions should be scoped to the resource name "operator-controller-openshift-ca" (this will be the name of the created configmap)
Feature Overview (aka. Goal Summary)
OVN Kubernetes Developer's Preview for BGP as a routing protocol for User Defined Network (Segmentation) pod and VM addressability via common data center networking removing the need to negotiate NAT at the cluster's edge.
Goals (aka. expected user outcomes)
OVN-Kubernetes currently has no native routing protocol integration, and relies on a Geneve overlay for east/west traffic, as well as third party operators to handle external network integration into the cluster. The purpose of this Developer's Preview enhancement is to introduce BGP as a supported routing protocol with OVN-Kubernetes. The extent of this support will allow OVN-Kubernetes to integrate into different BGP user environments, enabling it to dynamically expose cluster scoped network entities into a provider’s network, as well as program BGP learned routes from the provider’s network into OVN. In a follow-on release, this enhancement will provide support for EVPN, which is a common data center networking fabric that relies on BGP.
Requirements (aka. Acceptance Criteria):
- Provide a user-facing API to allow configuration of iBGP or eBGP peers, along with typical BGP configurations to include communities, route targets, vpnv4/v6, etc
- Support for advertising Egress IP addresses
- Enable BFD to BGP peers
- Support EVPN configuration and integration with a user’s DC fabric, along with MAC-VRFs and IP-VRFs
- ECMP routing support within OVN for BGP learned routes
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.Deployment considerations List applicable specific needs (N/A = not applicable) Self-managed, managed, or both Classic (standalone cluster) Hosted control planes Multi node, Compact (three node), or Single node (SNO), or all Connected / Restricted Network Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) Operator compatibility Backport needed (list applicable versions) UI need (e.g. OpenShift Console, dynamic plugin, OCM) Other (please specify)
Use Cases (Optional):
- Integration with 3rdparty load balancers that send packets directly to OpenShift nodes with the destination IP address of a targeted pod, without needing custom operators to detect which node a pod is scheduled to and then add routes into the load balancer to send the packet to the right node.
Questions to Answer (Optional):
Out of Scope
- EVPN integration
- Support of any other routing protocol
- Running separate BGP instances per VRF network
- Support for any other type of L3VPN with BGP, including MPLS
- Providing any type of API or operator to automatically connect two Kubernetes clusters via L3VPN
- Replacing the support that MetalLB provides today for advertising service IPs
- Asymmetric Integrated Routing and Bridging (IRB) with EVPN
Background
BGP
Importing Routes from the Provider Network
Today in OpenShift there is no API for a user to be able to configure routes into OVN. In order for a user to change how cluster traffic is routed egress into the cluster, the user leverages local gateway mode, which forces egress traffic to hop through the Linux host's networking stack, where a user can configure routes inside of the host via NM State. This manual configuration would need to be performed and maintained across nodes and VRFs within each node.
Additionally, if a user chooses to not manage routes within the host and use local gateway mode, then by default traffic is always sent to the default gateway. The only other way to affect egress routing is by using the Multiple External Gateways (MEG) feature. With this feature the user may choose to have multiple different egress gateways per namespace to send traffic to.
As an alternative, configuring BGP peers and which route-targets to import would eliminate the need to manually configure routes in the host, and would allow dynamic routing updates based on changes in the provider’s network.
Exporting Routes into the Provider Network
There exists a need for provider networks to learn routes directly to services and pods today in Kubernetes. Metal LB is already one solution whereby load balancer IPs are advertised by BGP to provider networks, and this feature development does not intend to duplicate or replace the function of Metal LB. Metal LB should be able to interoperate with OVN-Kubernetes, and be responsible for advertising services to a provider’s network.
However, there is an alternative need to advertise pod IPs on the provider network. One use case is integration with 3rd party load balancers, where they terminate a load balancer and then send packets directly to OCP nodes with the destination IP address being the pod IP itself. Today these load balancers rely on custom operators to detect which node a pod is scheduled to and then add routes into its load balancer to send the packet to the right node.
By integrating BGP and advertising the pod subnets/addresses directly on the provider network, load balancers and other entities on the network would be able to reach the pod IPs directly.
EVPN (to be integrated with BGP in a follow-on release targeting 4.18)
Extending OVN-Kubernetes VRFs into the Provider Network
This is the most powerful motivation for bringing support of EVPN into OVN-Kubernetes. A previous development effort enabled the ability to create a network per namespace (VRF) in OVN-Kubernetes, allowing users to create multiple isolated networks for namespaces of pods. However, the VRFs terminate at node egress, and routes are leaked from the default VRF so that traffic is able to route out of the OCP node. With EVPN, we can now extend the VRFs into the provider network using a VPN. This unlocks the ability to have L3VPNs that extend across the provider networks.
Utilizing the EVPN Fabric as the Overlay for OVN-Kubernetes
In addition to extending VRFs to the outside world for ingress and egress, we can also leverage EVPN to handle extending VRFs into the fabric for east/west traffic. This is useful in EVPN DC deployments where EVPN is already being used in the TOR network, and there is no need to use a Geneve overlay. In this use case, both layer 2 (MAC-VRFs) and layer 3 (IP-VRFs) can be advertised directly to the EVPN fabric. One advantage of doing this is that with Layer 2 networks, broadcast, unknown-unicast and multicast (BUM) traffic is suppressed across the EVPN fabric. Therefore the flooding domain in L2 networks for this type of traffic is limited to the node.
Multi-homing, Link Redundancy, Fast Convergence
Extending the EVPN fabric to OCP nodes brings other added benefits that are not present in OCP natively today. In this design there are at least 2 physical NICs and links leaving the OCP node to the EVPN leaves. This provides link redundancy, and when coupled with BFD and mass withdrawal, it can also provide fast failover. Additionally, the links can be used by the EVPN fabric to utilize ECMP routing.
Customer Considerations
- For customers using MetalLB, it will continue to function correctly regardless of this development.
Documentation Considerations
Interoperability Considerations
- Multiple External Gateways (MEG)
- Egress IP
- Services
- Egress Service
- Egress Firewall
- Egress QoS
Epic Goal
OVN Kubernetes support for BGP as a routing protocol.
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
- Priority+ is set by engineering
- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
MetalLB or a cluster admin will set this flag so that CNO deploys FFR-K8S and activates BGP support in OVN-K
When the OCP API flag to enable BGP support in the cluster is set, CNO should deploy FRR-K8S. Depends on SDN-5086.
enhancement ref: https://github.com/openshift/enhancements/pull/1636
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Introduce snapshots support for Azure File as Tech Preview
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
After introducing cloning support in 4.17, the goal of this epic is to add the last remaining piece to support snapshots support as tech preview
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Should pass all the regular CSI snapshot tests. All failing or known issues should be documented in the RN. Since this feature is TP we can still introduce it with knows issues.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | both |
| Classic (standalone cluster) | yes |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | all with Azure |
| Connected / Restricted Network | all |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all |
| Operator compatibility | Azure File CSI |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | Already covered |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
As an OCP on Azure user I want to perform snapshots of my PVC and be able to restore them as a new PVC.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Is there any known issues, if so they should be documented.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
N/A
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
We have support for other cloud providers CSI snapshots, we need to align capabilities in Azure with their File CSI. Upstream support has lagged.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
User experience should be the same as other CSI drivers.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Add snapshot support in the CSI driver table, if there is any specific information to add, include it in the Azure File CSI driver doc. Any known issue should be documented in the RN.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Can be leveraged by ARO or OSD on Azure.
Epic Goal*
Add support for snapshots in Azure File.
Why is this important? (mandatory)
We should track upstream issues and ensure enablement in OpenShift. Snapshots are a standard feature of CSI and the reason we did not support it until now was lacking upstream support for snapshot restoration.
Snapshot restore feature was added recently in upstream driver 1.30.3 which we rebased to in 4.17 - https://github.com/kubernetes-sigs/azurefile-csi-driver/pull/1904
Furthermore we already included azcopy cli which is a depencency of cloning (and snapshots). Enabling snapshots in 4.17 is therefore just a matter of adding a sidecar, volumesnapshotclass and RBAC in csi-operator which is cheap compared to the gain.
However, we've observed a few issues with cloning that might need further fixes to be able to graduate to GA and intend releasing the cloning feature as Tech Preview in 4.17 - since snapshots are implemented with azcopy too we expect similar issues and suggest releasing snapshot feature also as Tech Preview first in 4.17.
Scenarios (mandatory)
Users should be able to create a snapshot and restore PVC from snapshots.
Dependencies (internal and external) (mandatory)
azcopy - already added in scope of cloning epic
upstream driver support for snapshot restore - already added via 4.17 rebase
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Introduce snapshots support for Azure File as Tech Preview
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
After introducing cloning support in 4.17, the goal of this epic is to add the last remaining piece to support snapshots support as tech preview
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Should pass all the regular CSI snapshot tests. All failing or known issues should be documented in the RN. Since this feature is TP we can still introduce it with knows issues.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | both |
| Classic (standalone cluster) | yes |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | all with Azure |
| Connected / Restricted Network | all |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all |
| Operator compatibility | Azure File CSI |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | Already covered |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
As an OCP on Azure user I want to perform snapshots of my PVC and be able to restore them as a new PVC.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Is there any known issues, if so they should be documented.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
N/A
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
We have support for other cloud providers CSI snapshots, we need to align capabilities in Azure with their File CSI. Upstream support has lagged.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
User experience should be the same as other CSI drivers.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Add snapshot support in the CSI driver table, if there is any specific information to add, include it in the Azure File CSI driver doc. Any known issue should be documented in the RN.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Can be leveraged by ARO or OSD on Azure.
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Develop tooling to support migrating CNS volumes between datastores in a safe way for Openshift users.
This tool relies on a new VMware CNS API and requires 8.0.2 or 7.0 Update 3o minimum versions
https://docs.vmware.com/en/VMware-vSphere/8.0/rn/vsphere-vcenter-server-802-release-notes/index.html
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
Often our customers are looking to migrate volumes between datastores because they are running out of space in current datastore or want to move to more performant datastore. Previously this was almost impossible or required modifying PV specs by hand to accomplish this. It was also very error prone.
As a first version, we develop a CLI tool that is shipped as part of the vsphere CSI operator. We keep this tooling internal for now, support can guide customers on a per request basis. This is to manage current urgent customer's requests, a CLI tool is easier and faster to develop it can also easily be used in previous OCP releases.
Ultimately we want to develop an operator that would take care of migrating CNS between datastores.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Tool is able to take a list of volumes and migrate from one datastore to another. It also performs the necessary pre-flight tests to ensure that the volume is safe to migrate.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | both |
| Classic (standalone cluster) | Yes |
| Hosted control planes | |
| Multi node, Compact (three node), or Single node (SNO), or all | Yes |
| Connected / Restricted Network | both |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | vsphere CSI operator |
| Backport needed (list applicable versions) | no |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | no |
| Other (please specify) | OCP on vsphere only |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
As a admin - want to migrate all my PVs or optional PVCs belonging to certain namespace to a different datastore within cluster without potentially requiring extended downtime.
- I want to move volumes to another datastore that has better performances
- I want to move volumes to another datastore current the current one is getting full
- I want to move all volumes to another datastore because the current one is being decommissioned.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
How to ship the binary?
Which versions of OCP can this tool support?
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
This feature tracks the implementation with a CLI binary. The operator implementation will be tracked by another Jira feature.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
We had a lot of requests to migrate volumes between datastore for multiple reason. Up until now it was not natively supported by VMware. In 8.0.2 they added a CNS API and a vsphere UI feature to perform volume migration.
We want to avoid customers to directly use the feature from the vsphere UI so we have to develop a wrapper for customers. It's easier to ship a CLI tool first to cover current request and then take some time to develop an official operator-led way.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Given this tool is shipped as part of the vsphere CSI operator and requires extraction and careful manipulation we are not going to document it publicly.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Will be documented as an internal KCS
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
OCP on vSphere only
Epic Goal*
Develop tooling to support migrating CNS volumes between datastores in a safe way for Openshift users.
As a first version, we develop a CLI tool that is shipped as part of the vsphere CSI operator. We keep this tooling internal for now, support can guide customers on a per request basis. This is to manage current urgent customer request, a CLI tool is easier and faster to develop it can also easily be used in previous OCP releases.
Ultimately we want to develop an operator that would take care of migrating CNS between datastores.
Why is this important? (mandatory)
Often our customers are looking to migrate volumes between datastores because they are running out of space in current datastore or want to move to more performant datastore. Previously this was almost impossible or required modifying PV specs by hand to accomplish this. It was also very error prone.
Scenarios (mandatory)
As a admin - want to migrate all my PVs or optional PVCs belonging to certain namespace to a different datastore within cluster without potentially requiring extended downtime.
- I want to move volumes to another datastore that has better performances
- I want to move volumes to another datastore current the current one is getting full
- I want to move all volumes to another datastore because the current one is being decommissioned.
Dependencies (internal and external) (mandatory)
- We depend on latest version of vCenter to accomplish this. So customer must be running latest version of vCenter - https://docs.vmware.com/en/VMware-vSphere/7.0/rn/vsphere-vcenter-server-70u3o-release-notes/index.html and https://docs.vmware.com/en/VMware-vSphere/8.0/rn/vsphere-vcenter-server-802-release-notes/index.html
- We also depend on an environment where we can reasonable test this.
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Place holder epic to capture all azure tickets.
TODO: review.
User Story:
As an end user of a hypershift cluster, I want to be able to:
- Not see internal host information when inspecting a serving certificate of the kubernetes API server
so that I can achieve
- No knowledge of internal names for the kubernetes cluster.
From slack thread: https://redhat-external.slack.com/archives/C075PHEFZKQ/p1722615219974739
We need 4 different certs:
- common sans
- internal san
- fqdn
- svc ip
Add e2e tests to openshift/origin to test the improvement in integration between CoreDNS and EgressFirewall as proposed in the enhancement https://github.com/openshift/enhancements/pull/1335.
As the feature is currently targeted for Tech-Preview, the e2e tests should enable the feature set to test the feature.
The e2e test should create EgressFirewall with DNS rules after enabling Tech-Preview. The EgressFirewall rules should work correctly. E.g. https://github.com/openshift/origin/blob/master/test/extended/networking/egress_firewall.go
Goal
As an OpenShift installer I want to update the firmware of the hosts I use for OpenShift on day 1 and day 2.
As an OpenShift installer I want to integrate the firmware update in the ZTP workflow.
Description
The firmware updates are required in BIOS, GPUs, NICs, DPUs, on hosts that will often be used as DUs in Edge locations (commonly installed with ZTP).
Acceptance criteria
- Firmware can be updated (upgrade/downgrade)
- Existing firmware version can be checked
Out of Scope
- Day 2 host firmware upgrade
Description of problem:
After running a firmware update the new version is not displayed in the status of the HostFirmwareComponents
Version-Release number of selected component (if applicable):
How reproducible:
100%
Steps to Reproduce:
1. Execute a firmware update, after it succeeds check the Status to find the information about the new version installed.
Actual results:
Status only show the initial information about the firmware components.
Expected results:
Status should show the newer information about the firmware components.
Additional info:
When executing a firmware update for BMH, there is a problem updating the Status of the HostFirmwareComponents CRD, causing the BMH to repeat the update multiple times since it stays in Preparing state.
As a customer of self managed OpenShift or an SRE managing a fleet of OpenShift clusters I should be able to determine the progress and state of an OCP upgrade and only be alerted if the cluster is unable to progress. Support a cli-status command and status-API which can be used by cluster-admin to monitor the progress. status command/API should also contain data to alert users about potential issues which can make the updates problematic.
Feature Overview (aka. Goal Summary)
Here are common update improvements from customer interactions on Update experience
- Show nodes where pod draining is taking more time.
Customers have to dig deeper often to find the nodes for further debugging.
The ask has been to bubble up this on the update progress window. - oc update status ?
From the UI we can see the progress of the update. From oc cli we can see this from "oc get cvo"
But the ask is to show more details in a human-readable format.
Know where the update has stopped. Consider adding at what run level it has stopped.
oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.12.0 True True 16s Working towards 4.12.4: 9 of 829 done (1% complete)
Documentation Considerations
Update docs for UX and CLI changes
Reference : https://docs.google.com/presentation/d/1cwxN30uno_9O8RayvcIAe8Owlds-5Wjr970sDxn7hPg/edit#slide=id.g2a2b8de8edb_0_22
Epic Goal*
Add a new command `oc adm upgrade status` command which is backed by an API. Please find the mock output of the command output attached in this card.
Why is this important? (mandatory)
- From the UI we can see the progress of the update. Using OC CLI we can see some of the information using "oc get clusterversion" but the output is not readable and it is a lot of extra information to process.
- Customer as asking us to show more details in a human-readable format as well provide an API which they can use for automation.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Tests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Other
Description of problem:
The cluster version is not updating (Progressing=False). Reason: <none> Message: Cluster version is 4.16.0-0.nightly-2024-05-08-222442
When cluster is outside of update it shows Failing=True condition content which is potentially confusing. I think we can just show "The cluster version is not updating ".
Description of problem:
the newly available TP upgrade status command have formatting issue while expanding update health using --details flag, a plural s:<resource> is displayed, which according to dev supposed to be added to group.kind, but only the plural itself is displayed instead Resources: s: version
Version-Release number of selected component (if applicable):
4.16.0-0.nightly-2024-05-08-222442
How reproducible:
100%
Steps to Reproduce:
oc adm upgrade status --details=all while there is any health issue with the cluster
Actual results:
Resources: s: ip-10-0-76-83.us-east-2.compute.internal Description: Node is unavailable
Resources: s: version Description: Cluster operator control-plane-machine-set is not available
Resources:
s: ip-10-0-58-8.us-east-2.compute.internal
Description: failed to set annotations on node: unable to update node "&Node{ObjectMeta:{ 0 0001-01-01 00:00:00 +0000 UTC <nil> <nil> map[] map[] [] [] []},Spec:NodeSpec{PodCIDR:,DoNotUseExternalID:,ProviderID:,Unschedulable:false,Taints:[]Taint{},ConfigSource:nil,PodCIDRs:[],},Status:NodeStatus{Capacity:ResourceList{},Allocatable:ResourceList{},Phase:,Conditions:[]NodeCondition{},Addresses:[]NodeAddress{},DaemonEndpoints:NodeDaemonEndpoints{KubeletEndpoint:DaemonEndpoint{Port:0,},},NodeInfo:NodeSystemInfo{MachineID:,SystemUUID:,BootID:,KernelVersion:,OSImage:,ContainerRuntimeVersion:,KubeletVersion:,KubeProxyVersion:,OperatingSystem:,Architecture:,},Images:[]ContainerImage{},VolumesInUse:[],VolumesAttached:[]AttachedVolume{},Config:nil,},}": Patch "https://api-int.evakhoni-1514.qe.devcluster.openshift.com:6443/api/v1/nodes/ip-10-0-58-8.us-east-2.compute.internal": read tcp 10.0.58.8:48328->10.0.27.41:6443: read: connection reset by peer
Expected results:
should mention the correct <group.kind>s:<resource> ?
Additional info:
OTA-1246
slackl thread
Using the alerts-in-CLI PoC OTA-1080 show relevant firing alerts in the OTA-1087 section. Probably do not show all firing alerts.
I propose showing
- Alerts that started to fire during the upgrade
- Allow list of alerts that we know are relevant during upgrades? Insight severity can match alert severity.
Impact can be probably simple alertname -> impact type classifier. Message can be "Alert name: Alert message":
=Update Health= SINCE LEVEL IMPACT MESSAGE 3h Warning API Availability KubeDaemonSetRolloutStuck: DaemonSet openshift-ingress-canary/ingress-canary has not finished or progressed for at least 30 minutes.
Definition of done
- Alerts that started firing during the upgrade are shown as a upgrade health insight in upgrade health section
- Alerts that started firing before the upgrade but are present on an allowlist (hardcoded for now) of alerts relevant for update
- Create an allow list for alerts (structure) which will show the alerts in this section.
- We do not plan to decide which alerts should be in the allow list as part of this card (as this is a future card)
Feature Overview
Support deploying an OpenShift cluster across multiple vSphere clusters, i.e. configuring multiple vCenter servers in one OpenShift cluster.
Goals
Multiple vCenter support in the Cloud Provider Interface (CPI) and the Cloud Storage Interface (CSI).
Use Cases
Customers want to deploy OpenShift across multiple vSphere clusters (vCenters) primarily for high availability.
粗文本*h3. *Feature Overview
Support deploying an OpenShift cluster across multiple vSphere clusters, i.e. configuring multiple vCenter servers in one OpenShift cluster.
Goals
Multiple vCenter support in the Cloud Provider Interface (CPI) and the Cloud Storage Interface (CSI).
Use Cases
Customers want to deploy OpenShift across multiple vSphere clusters (vCenters) primarily for high availability.
Done Done Done Criteria
This section contains all the test cases that we need to make sure work as part of the done^3 criteria.
- Clean install of new cluster with multi vCenter configuration
- Clean install of new cluster with single vCenter still working as previously
- VMs / machines can be scaled across all vCenters / Failure Domains
- PVs should be able to be created on all vCenters
Out-of-Scope
This section contains all scenarios that are considered out of scope for this enhancement that will be done via a separate epic / feature / story.
- Migration of single vCenter OCP to a multi vCenter (stretch
User Story
As an OpenShift administrator, I would like vShere CSI Driver Operator to not become degraded due to vSphere Multi vCenter feature gate being enabled so that I can begin to install my cluster across multiple vcenters and create PVs.
Description
The purpose of this story is to perform the needed changes to get vShere CSI Driver Operator allowing the configuration of the new Feature Gate for vSphere Multi vCenter support. By default, the operator will still only allow one vCenter definition and support that config; however, once the feature gate for vSphere Multi vCenter is enabled, we will allow more than one vCenter. Initially, the plan is to only allow a max of 3 vCenter definitions which will be controlled via the CRD for the vSphere infrastructure definitions.
Required:
The vShere CSI Driver Operator after install must not fail due to the number of vCenters configured. The operator will also need to allow the creation of PVs. Any other failure reported based on issues performing operator tasks is valid and should be addressed via a new story.
ACCEPTANCE CRITERIA
- multi vcenter enabled: Operator is not degraded from having more than one vCenter defined in the infrastructure custom resource
- multi vcenter disabled: Operator will become degraded if vCenter count is greater than 1
ENGINEERING DETAILS
- Migrate operator to use new YAML cloud config
- Fix csi driver controller roles to include correct permissions
- Update openshift/api to be >= version with new VSphereMultiVCenters feature gate
- Enhance operator to be able to monitor feature gates
- Enhance operator to support multiple vCenters
- apply tags
- create storage policies
- Update all check logic
- Update pod creation to not use env var and put user/pass in config. ENV vars do not allow for mulitple user/pass to allow communication w/ multiple vCenters
User Story
As an OpenShift administrator, I would like Machine API Operator (MAO) to not become degraded due to vSphere Multi vCenter feature gate being enabled so that I can begin to install my cluster across multiple vcenters.
Description
The purpose of this story is to perform the needed changes to get MAO allowing the configuration of the new Feature Gate for vSphere Multi vCenter support. By default, the operator will still only allow one vCenter definition and support that config; however, once the feature gate for vSphere Multi vCenter is enabled, we will allow more than one vCenter. Initially, the plan is to only allow a max of 3 vCenter definitions which will be controlled via the CRD for the vSphere infrastructure definitions. Also, this operator will need to be enhanced to handle the new YAML format cloud config.
Required:
The vShere CSI Driver Operator after install must not fail due to the number of vCenters configured. The operator will also need to allow the creation of PVs. Any other failure reported based on issues performing operator tasks is valid and should be addressed via a new story.
ACCEPTANCE CRITERIA
- multi vcenter enabled: Operator is not degraded from having more than one vCenter defined in the infrastructure custom resource
- multi vcenter disabled: Operator will become degraded if vCenter count is greater than 1
- Operator is now using the new YAML cloud config for vSphere
ENGINEERING DETAILS
- Migrate operator to use new YAML cloud config
- Update openshift/api to be >= version with new VSphereMultiVCenters feature gate
USER STORY
As a cluster administrator, I would like to enhance the CAPI installer to support multiple vCenters for installation of cluster so that I can spread my cluster across several vcenters.
DESCRIPTION:
The purpose of this story is to enhance the installer to support multiple vcenters. Today OCP only allows the use of once vcenter to install the cluster into. With the development of this feature, cluster admins will be able to configure via the install-config multiple vCenters and allow creation of VMs in all specified vCenter instances. Failure Domains will encapsulate the vcenter definitions.
ACCEPTANCE CRITERIA
- Installer can create a cluster with multiple vCenters defined in the install-config when using the new CAPI installer.
- Installer (Terraform) should still fail when feature gate is enabled and multiple vcenter definitions are detected.
- Installer uses new feature gate to allow use of multiple vcenters
- If feature gate enabled and vCenter count > 1, allow install
- If feature gate disabled and vCenter count > 1, error out with message that more than one is not allowed
- Installer can destroy a cluster that is spread across multiple vcenters
- Create unit tests to cover all scenarios
ENGINEERING DETAILS
This will required changed in the API to provide the new feature gate. Once the feature gate is created, the installer can be enhanced to leverage this new feature gate to allow the user to install the VMs of the cluster across multiple vCenters.
We will need to verify how we are handling unit testing CAPI in the installer. The unit tests should cover the cases of checking for the new FeatureGate.
User Story
As an OpenShift administrator, I would like MCO to not become degraded due to vSphere Multi vCenter feature gate being enabled so that I can begin to install my cluster across multiple vcenters.
Description
The purpose of this story is to perform the needed changes to get MCO allowing the configuration of the new Feature Gate for vSphere Multi vCenter support. There will be other stories created to track the functional improvements of MCO. By default, the operator will still only allow one vCenter definition; however, once the feature gate for vSphere Multi vCenter is enabled, we will allow more than one vCenter. Initially, the plan is to only allow a max of 3 vCenter definitions which will be controlled via the CRD for the vSphere infrastructure definitions.
Required:
The MCO after install must not fail due to the number of vCenters configured. Any other failure reported based on issues performing operator tasks is valid and should be addressed via a new story.
ACCEPTANCE CRITERIA
- multi vcenter enabled: MCO is not degraded from having more than one vCenter defined in the infrastructure custom resource
- multi vcenter disabled: MCO will become degraded if vCenter count is greater than 1
ENGINEERING DETAILS
We will need to enhance all logic that has hard coded vCenter size to now look to see if vSphere Multi vCenter feature gate is enabled. If it is enabled, the vCenter count may be larger than 1, else it will still need to fail with the error message of vCenter count may not be greater than 1.
User Story
As an OpenShift administrator, I would like CSO to not become degraded due to multi vcenter feature gate being enabled so that I can begin to install my cluster across multiple vcenters.
Description
The purpose of this story is to perform the needed changes to get CSO allowing the configuration of the new Feature Gate for vSphere Multi vCenter support. There will be other stories created to track the functional improvements of CSO. By default, the operator will still only allow one vcenter definition; however, once the feature gate for vSphere Multi vCenter is enabled, we will allow more than one vCenter. Initially, the plan is to only allow a max of 3 vCenter definitions which will be controlled via the CRD for the vSphere infrastructure definitions.
Required:
The CSO after install must not fail due to the number of vCenters configured. Any other failure reported based on issues performing operator tasks is valid and should be addressed via a new story.
ACCEPTANCE CRITERIA
- multi vcenter enabled: CSO is not degraded from having more than one vCenter defined in the infrastructure custom resource
- multi vcenter disabled: CSO will become degraded if vcenter count is greater than 1
ENGINEERING DETAILS
We will need to enhance all logic that has hard coded vCenter size to now look to see if multi vcenter feature gate is enabled. If it is enabled, the vcenter count may be larger than 1, else it will still need to fail with the error message of vcenter count may not be greater than 1.
User Story
As an OpenShift administrator, I would like the vSphere Problem Detector (VPD) to not log error messages related to new YAML config so that I can begin to install my cluster across multiple vcenters and create PVs and have VPD verify all vCenters and their configs.
Description
The purpose of this story is to perform the needed changes to get vSphere Problem Detector (VPD) allowing the configuration of the new Feature Gate for vSphere Multi vCenter support. This involves a new YAML config that needs to be supported. Also, we need to make sure the VPD checks all vCenters / failure domains for any and all checks that it performs.
Required:
The VPD after install must not fail due to the number of vCenters configured. The VPD may be logging error messages that are not causing the storage operator to become degraded. We should verify the logs and make sure all vCenters / FD are check as we expect.
ACCEPTANCE CRITERIA
- multi vcenter enabled (YAML): VPD logs no error message.
- multi vcenter disabled (INI): VPD logs no error messages.
- all existing unit tests pass
- new unit tests added for multi vcenter
ENGINEERING DETAILS
- Migrate operator to use new YAML cloud config
Feature Overview
Add authentication to the internal components of the Agent Installer so that the cluster install is secure.
Goals
- Day1: Only allow agents booted from the same agent ISO to register with the assisted-service and use the agent endpoints
- Day2: Only allow agents booted from the same node ISO to register with the assisted-service and use the agent endpoints
Only allow access to write endpoints to the internal servicesUse authentication to read endpoints
Epic Goal
- This epic scope was originally to encompass both authentication and authorization but we have split the expanding scope into a separate epic.
- We want to add authorization to the internal components of Agent Installer so that the cluster install is secure.
Why is this important?
- The Agent Installer API server (assisted-service) has several methods for Authorization but none of the existing methods are applicable tothe Agent Installer use case.
- During the MVP of Agent Installer we attempted to turn on the existing authorization schemes but found we didn't have access to the correct API calls.
- Without proper authorization it is possible for an unauthorized node to be added to the cluster during install. Currently we expect this to be done as a mistake rather than maliciously.
Brainstorming Notes:
Requirements
- Allow only agents booted from the same ISO to register with the assisted-service and use the agent endpoints
- Agents already know the InfraEnv ID, so if read access requires authentication then that is sufficient in some existing auth schemes.
- Prevent access to write endpoints except by the internal systemd services
- Use some kind of authentication for read endpoints
Ideally use existing credentials - admin-kubeconfig client cert and/or kubeadmin-password
(Future) Allow UI access in interactive mode only
Are there any requirements specific to the auth token?
- Ephemeral
- Limited to one cluster:
Reuse the existing admin-kubeconfig client cert
Actors:
- Agent Installer: example wait-for
- Internal systemd: configurations, create cluster infraenv, etc
UI: interactive userUser: advanced automation user (not supported yet)
Do we need more than one auth scheme?
Agent-admin - agent-read-write
Agent-user - agent-read
Options for Implementation:
- New auth scheme in assisted-service
Reverse proxy in front of assisted-service APIUse an existing auth scheme in assisted-service
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Previous Work (Optional):
AGENT-60Originally we wanted to just turn on local authorization for Agent Installer workflows. It was discovered this was not sufficient for our use case.
Open questions::
- Which API endpoints do we need for the interactive flow?
- What auth scheme does the Assisted UI use if any?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Once the new auth type is implemented, update assisted-service-env.template from AUTH_TYPE:none to AUTH_TYPE: agent-installer-local
Read the generated local JWT token and ECDSA public key from the asset store and pass it to newly implemented auth type in assisted service to perform authentication in assisted service. Use seperate the auth headers for the API requests in the places where we make curl requests w.r.t. systemd services.
User Story:
As a user using agent installer on day2 to add a new node to the cluster, I want to be able to:
- verify if the token is unexpired
so that I can achieve
- successful authentication from assisted service and be able to add a node to the cluster
- an error in the case if token is expired
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a user, I want to be able to:
- Implement a new auth type `agent-installer-local` in assisted service. This new auth type will implement agentAuth and userAuth.
- The implementation will be based on existing local auth in assisted service.
- Note that in assisted service, when using local auth only agentAuth is implemented and userAuth is not supported. Agent auth: Validating a token using ECDSA public key
- For agent installer, AuthUserAuth will be internally calling the same logic for AuthAgentAuth
- Ref from assisted service existing local auth implementation: Implementing these four functions in your authenticator will give you access to all API endpoints
- AuthURLAuth and AuthImageAuth implementation will remain same as in assisted service
so that I can achieve
- API authentication
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
When running `./openshift-install agent wait-for bootstrap-complete` and `./openshift-install agent wait-for install-complete`, read the generated local JWT token and ECDSA public key from the asset store and pass it to newly implemented auth type in assisted service to perform authentication in assisted service.
User Story:
As an ABI user responsible for day-2 operations, I want to be able to:
- Verify the Status of the Authentication Token:
- Quickly and easily check whether the authentication token used for booting up nodes with node.iso is currently valid or has expired.
- Receive Guidance on Expired Tokens:
- If the authentication token has expired, receive clear and actionable instructions on the necessary steps to renew or replace the token. This includes understanding how to generate a new token by running the add-nodes command to create a new node ISO.
-
- Display a status message on the boot-up screen where other status messages are shown. The message could be:
- The auth token is expired. Re-run the add-nodes command to generate a new node ISO and boot it up to continue.
- The auth token is valid up to AGENT_AUTH_TOKEN_EXPIRY
- Display a status message on the boot-up screen where other status messages are shown. The message could be:
so that I can
- effectively manage the authentication aspect of booting up nodes using node.iso, ensuring that all operations run smoothly and securely. This will provide a clear path for corrective actions in the event of authentication issues.
Additional Details:
A new systemd service will be introduced to check and display the status of the authentication token—whether it is valid or expired. This service will run immediately after the agent-interactive-console systemd service. If the authentication token is expired, cluster installation or adding new nodes will be halted until a new node ISO is generated.
Acceptance Criteria:
Description of criteria:
- A new systemd service
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Read the generated local JWT token and ECDSA public key from the asset store and pass it to newly implemented auth type in assisted service to perform authentication in assisted service. Use seperate the auth headers for agent API requests, similar to wait-for commands and internal systemd services.
User Story:
As a user, I want to be able to
- create an ISO to add nodes to an existing cluster
- make authenticated API requests to add a new node
so that I can achieve
- cluster expansion ( adding new nodes)
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Note: phase 2 target is tech preview.
Feature Overview
In the initial delivery of CoreOS Layering, it is required that administrators provide their own build environment to customize RHCOS images. That could be a traditional RHEL environment or potentially an enterprising administrator with some knowledge of OCP Builds could set theirs up on-cluster.
The primary virtue of an on-cluster build path is to continue using the cluster to manage the cluster. No external dependency, batteries-included.
On-cluster, automated RHCOS Layering builds are important for multiple reasons:
- One-click/one-command upgrades of OCP are very popular. Many customers may want to make one or just a few customizations but also want to keep that simplified upgrade experience.
- Customers who only need to customize RHCOS temporarily (hotfix, driver test package, etc) will find off-cluster builds to be too much friction for one driver.
- One of OCP's virtues is that the platform and OS are developed, tested, and versioned together. Off-cluster building breaks that connection and leaves it up to the user to keep the OS up-to-date with the platform containers. We must make it easy for customers to add what they need and keep the OS image matched to the platform containers.
Goals & Requirements
- The goal of this feature is primarily to bring the 4.14 progress (
OCPSTRAT-35) to a Tech Preview or GA level of support. - Customers should be able to specify a Containerfile with their customizations and "forget it" as long as the automated builds succeed. If they fail, the admin should be alerted and pointed to the logs from the failed build.
- The admin should then be able to correct the build and resume the upgrade.
- Intersect with the Custom Boot Images such that a required custom software component can be present on every boot of every node throughout the installation process including the bootstrap node sequence (example: out-of-box storage driver needed for root disk).
- Users can return a pool to an unmodified image easily.
- RHEL entitlements should be wired in or at least simple to set up (once).
- Parity with current features – including the current drain/reboot suppression list, CoreOS Extensions, and config drift monitoring.
Feature Overview
Create a GCP cloud specific spec.resourceTags entry in the infrastructure CRD. This should create and update tags (or labels in GCP) on any openshift cloud resource that we create and manage. The behaviour should also tag existing resources that do not have the tags yet and once the tags in the infrastructure CRD are changed all the resources should be updated accordingly.
Tag deletes continue to be out of scope, as the customer can still have custom tags applied to the resources that we do not want to delete.
Due to the ongoing intree/out of tree split on the cloud and CSI providers, this should not apply to clusters with intree providers (!= "external").
Once confident we have all components updated, we should introduce an end2end test that makes sure we never create resources that are untagged.
Goals
- Functionality on GCP GA
- inclusion in the cluster backups
- flexibility of changing tags during cluster lifetime, without recreating the whole cluster
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
List any affected packages or components.
- Installer
- Cluster Infrastructure
- Storage
- Node
- NetworkEdge
- Internal Registry
- CCO
Dependent on https://issues.redhat.com/browse/CFE-918. Once driver is updated to support tags, operator should be added with the functionality to pass the user-defined tags found in Infrastructure as arg to the driver.
https://issues.redhat.com/browse/CFE-918 is for enabling tag functionality in the driver and driver will have the provision to pass user-defined tags to be added to the resources managed by it as process args and operator should read the user-defined tags found in Infrastructure object and pass as CSV to the driver.
Acceptance Criteria
- Code linting, validation and best practices adhered to
- Unit tests should be added for the new changes.
- Compute Disks, Images, Snapshots created by the driver should have user-defined tags attached to it.
TechPreview featureSet check added in machine-api-provider-gcp operator for userLabels and userTags.
And the new featureGate added in openshift/api should also be removed.
Acceptance Criteria
- Should be able to define userLabel and userTags without setting featureSet.
Installer would validate the existence of tags and fail the installation if the tags defined are not present. But the tags processed by installer is removed later, operator referencing these tags through Infrastructure would fail.
Enhance checks to identify not existent tags and insufficient permissions errors as GCP doesn't differentiate it.
Epic Goal*
GCP Filestore instances are not automatically deleted when the cluster is destroyed.
Why is this important? (mandatory)
The need to delete GCP Filestore instances is documented. This is however inconsistent with other Storage resources (GCP PD), which get removed automatically and also may lead to resource leaks
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- User installs a GCP cluster
- User creates a new Filestore instance as per the documentation: https://docs.openshift.com/container-platform/4.13/storage/container_storage_interface/persistent-storage-csi-google-cloud-file.html
- User does not delete the Filestore instance but destroys the cluster
- The Filestore is not removed and may impose additional cloud costs
Dependencies (internal and external) (mandatory)
This requires changes in the GCP Filestore Operator, GCP Filestore Driver and the OpenShift Installer
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
As the GCP Filestore user I would like all the resources belonging to the cluster to be automatically deleted upon the cluster destruction. This is currently only working for GCP PD volumes but has to be done manually for GCP Filestore ones:
Exit criteria:
- All the cluster provisioned GCP Filestore volumes are labelled as belonging to a cluster
- All the labelled GCP Filestore volumes are removed from the cloud when the cluster gets destroyed.
DoD
We need to ensure we have parity with OCP and support heterogeneous clusters
https://github.com/openshift/enhancements/pull/1014
- Define UX for multi arch NodePool input. E.g always enforce multi arch image, this might not be possible because of impact for image registry on disconnected clusters https://github.com/openshift/enhancements/pull/1014#discussion_r798444099.
Goal
- Provide a way to install with varied architecture NodePools with the ability to autoscale
- Define UX for multi arch NodePool input. E.g always enforce multi arch image, this might not be possible because of impact for image registry on disconnected clusters https://github.com/openshift/enhancements/pull/1014#discussion_r798444099.
Why is this important?
- Necessary to enable workloads with different architectures in the same Hosted Clusters.
- Cost savings brought by more cost effective ARM instances
Scenarios
- I have an x86 hosted cluster and I want to have at least one NodePool running ARM workloads
- I have an ARM hosted cluster and I want to have at least one NodePool running x86 workloads
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
Dependencies (internal and external)
- The management cluster must use a multi architecture payload image.
- The target architecture is in the OCP payload
- MCE has builds for the architecture used by the worker nodes of the management cluster
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
Using a multi-arch Node requires the HC to be multi arch as well. This is an good to recipe to let users shoot on their foot. We need to automate the required input via CLI to multi-arch NodePool to work, e.g. on HC creation enabling a multi-arch flag which sets the right release image
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a HyperShift/HCP CLI user, I want:
- the multi-arch flag to be enabled by default
so that
- the multi-arch validation is triggered by default for customers
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- mult-arch flag enabled by default for HyperShift and HCP CLIs by default
Out of Scope:
N/A
Engineering Details:
- This shouldn't affect CI testing since there is a related e2e flag setting the multi-arch flag to false - Slack thread.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Goal
- Add a heterogenous NodePool e2e to the AWS test suite
Why is this important?
- Ensure we don't regress on this feature
Scenarios
- HC cluster with both an x86 NodePool and an arm NodePool
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision Azure infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The Azure IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing Azure Terraform provider. Specifically, we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Provision Azure infrastructure without the use of Terraform
Why is this important?
- Removing Terraform from Installer
Scenarios
- The new provider should aim to provide the same results as the existing Azure
- terraform provider.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As an administrator, I want to be able to:
- Create cluster without public endpoints
- Create cluster that isn't reachable publicly
Acceptance Criteria:
Description of criteria:
- No public endpoints
- No public resources
- Single private load balancer
- Only reachable internally or through VPN or some other layer 2 or 3 protocol
Engineering Details:
Storage account should be encrypted with installconfig.platform.azure.CustomerManagedKey
Description of problem:
Launched CAPI based installation on azure platform, the default HyperVGeneration on each master node is V1, the expected value should be V2 if instance type supports HyperVGeneration V2.
$ az vm get-instance-view --name jimadisk01-xphq8-master-0 -g jimadisk01-xphq8-rg --query 'instanceView.hyperVGeneration' -otsv
V1
Also, if setting instance type to Standard_DC4ds_v3 that only supports HyperVGeneration V2,
install-config:
========================
controlPlane:
architecture: amd64
hyperthreading: Enabled
name: master
platform:
azure:
type: Standard_DC4ds_v3
continued to create cluster, installer failed and was timeout when waiting for machine provision.
INFO Waiting up to 15m0s (until 6:46AM UTC) for machines [jimadisk-nmkzj-bootstrap jimadisk-nmkzj-master-0 jimadisk-nmkzj-master-1 jimadisk-nmkzj-master-2] to provision...
ERROR failed to fetch Cluster: failed to generate asset "Cluster": failed to create cluster: control-plane machines were not provisioned within 15m0s: client rate limiter Wait returned an error: context deadline exceeded
INFO Shutting down local Cluster API control plane...
INFO Stopped controller: Cluster API
WARNING process cluster-api-provider-azure exited with error: signal: killed
INFO Stopped controller: azure infrastructure provider
INFO Stopped controller: azureaso infrastructure provider
In openshift-install.log, got below error:
time="2024-06-25T06:42:57Z" level=debug msg="I0625 06:42:57.090269 1377336 recorder.go:104] \"failed to reconcile AzureMachine: failed to reconcile AzureMachine service virtualmachine: failed to create or update resource jimadisk-nmkzj-rg/jimadisk-nmkzj-master-2 (service: virtualmachine): PUT https://management.azure.com/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jimadisk-nmkzj-rg/providers/Microsoft.Compute/virtualMachines/jimadisk-nmkzj-master-2\\n--------------------------------------------------------------------------------\\nRESPONSE 400: 400 Bad Request\\nERROR CODE: BadRequest\\n--------------------------------------------------------------------------------\\n{\\n \\\"error\\\": {\\n \\\"code\\\": \\\"BadRequest\\\",\\n \\\"message\\\": \\\"The selected VM size 'Standard_DC4ds_v3' cannot boot Hypervisor Generation '1'. If this was a Create operation please check that the Hypervisor Generation of the Image matches the Hypervisor Generation of the selected VM Size. If this was an Update operation please select a Hypervisor Generation '1' VM Size. For more information, see https://aka.ms/azuregen2vm\\\"\\n }\\n}\\n--------------------------------------------------------------------------------\\n\" logger=\"events\" type=\"Warning\" object={\"kind\":\"AzureMachine\",\"namespace\":\"openshift-cluster-api-guests\",\"name\":\"jimadisk-nmkzj-master-2\",\"uid\":\"c2cdabed-e19a-4e88-96d9-3f3026910403\",\"apiVersion\":\"infrastructure.cluster.x-k8s.io/v1beta1\",\"resourceVersion\":\"1600\"} reason=\"ReconcileError\""
time="2024-06-25T06:42:57Z" level=debug msg="E0625 06:42:57.090701 1377336 controller.go:329] \"Reconciler error\" err=<"
time="2024-06-25T06:42:57Z" level=debug msg="\tfailed to reconcile AzureMachine: failed to reconcile AzureMachine service virtualmachine: failed to create or update resource jimadisk-nmkzj-rg/jimadisk-nmkzj-master-2 (service: virtualmachine): PUT https://management.azure.com/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jimadisk-nmkzj-rg/providers/Microsoft.Compute/virtualMachines/jimadisk-nmkzj-master-2"
time="2024-06-25T06:42:57Z" level=debug msg="\t--------------------------------------------------------------------------------"
time="2024-06-25T06:42:57Z" level=debug msg="\tRESPONSE 400: 400 Bad Request"
time="2024-06-25T06:42:57Z" level=debug msg="\tERROR CODE: BadRequest"
time="2024-06-25T06:42:57Z" level=debug msg="\t--------------------------------------------------------------------------------"
time="2024-06-25T06:42:57Z" level=debug msg="\t{"
time="2024-06-25T06:42:57Z" level=debug msg="\t \"error\": {"
time="2024-06-25T06:42:57Z" level=debug msg="\t \"code\": \"BadRequest\","
time="2024-06-25T06:42:57Z" level=debug msg="\t \"message\": \"The selected VM size 'Standard_DC4ds_v3' cannot boot Hypervisor Generation '1'. If this was a Create operation please check that the Hypervisor Generation of the Image matches the Hypervisor Generation of the selected VM Size. If this was an Update operation please select a Hypervisor Generation '1' VM Size. For more information, see https://aka.ms/azuregen2vm\""
time="2024-06-25T06:42:57Z" level=debug msg="\t }"
time="2024-06-25T06:42:57Z" level=debug msg="\t}"
time="2024-06-25T06:42:57Z" level=debug msg="\t--------------------------------------------------------------------------------"
Version-Release number of selected component (if applicable):
4.17.0-0.nightly-2024-06-23-145410
How reproducible:
Always
Steps to Reproduce:
1. set instance type to Standard_DC4ds_v3 which only supports HyperVGeneration V2 or without instance type setting in install-config
2. launched installation
3.
Actual results:
1. without instance type setting, default HyperVGeneraton on each master instances is V1 2. fail to create master instances with instance type to Standard_DC4ds_v3
Expected results:
1. without instance type setting, default HyperVGeneraton on each master instances is V2. 2. succeed to create cluster with instance type Standard_DC4ds_v3
Additional info:
Remove vendored terraform-provider-azure and not all the terraform code for Azure installs.
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Description of problem:
Enable diskEncryptionSet under defaultMachinePlatform in install-config:
=============
platform:
azure:
defaultMachinePlatform:
encryptionAtHost: true
osDisk:
diskEncryptionSet:
resourceGroup: jimades01-rg
name: jimades01-des
subscriptionId: 53b8f551-f0fc-4bea-8cba-6d1fefd54c8a
Created cluster, checked diskEncryptionSet on each master instance's osDisk, all of them are empty.
$ az vm list -g jimades01-8ktkn-rg --query '[].[name, storageProfile.osDisk.managedDisk.diskEncryptionSet]' -otable
Column1 Column2
------------------------------------ ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
jimades01-8ktkn-master-0
jimades01-8ktkn-master-1
jimades01-8ktkn-master-2
jimades01-8ktkn-worker-eastus1-9m8p5 {'id': '/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jimades01-rg/providers/Microsoft.Compute/diskEncryptionSets/jimades01-des', 'resourceGroup': 'jimades01-rg'}
jimades01-8ktkn-worker-eastus2-cmcn7 {'id': '/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jimades01-rg/providers/Microsoft.Compute/diskEncryptionSets/jimades01-des', 'resourceGroup': 'jimades01-rg'}
jimades01-8ktkn-worker-eastus3-nknss {'id': '/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jimades01-rg/providers/Microsoft.Compute/diskEncryptionSets/jimades01-des', 'resourceGroup': 'jimades01-rg'}
same situation when setting diskEncryptionSet under controlPlane in install-config, no des setting in cluster api manifests 10_inframachine_jima24c-2cmlf_*.yaml.
$ yq-go r 10_inframachine_jima24c-2cmlf-bootstrap.yaml 'spec.osDisk'
cachingType: ReadWrite
diskSizeGB: 1024
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
$ yq-go r 10_inframachine_jima24c-2cmlf-master-0.yaml 'spec.osDisk'
cachingType: ReadWrite
diskSizeGB: 1024
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
Version-Release number of selected component (if applicable):
4.17.0-0.nightly-2024-06-23-145410
How reproducible:
Always
Steps to Reproduce:
1. Configure disk encryption set under controlPlane or defaultMachinePlatform in install-config
2. Create cluster
3.
Actual results:
DES does not take effect on master instances
Expected results:
DES should be configured on all master instances
Additional info:
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
We see that the MachinePool feaure gate has become default=true in a recent version of CAPZ. See https://github.com/openshift/installer/pull/8627#issuecomment-2178061050 for more context.
We should probably disable this feature gate. Here's an example of disabling a feature gate using a flag for the aws controller:
https://github.com/openshift/installer/blob/master/pkg/clusterapi/system.go#L153
Existing VNets can be specified in the cluster spec. Ensure that they are still tagged appropriately, which is in the PreTerraform code.https://github.com/openshift/installer/blob/master/pkg/asset/cluster/cluster.go#L111
Description of problem:
created Azure IPI cluster by using CAPI, interrupted the installer when running at the stage of waiting for bootstrapping to complete, then ran command "openshift-installer gather bootstrap --dir <install_dir>" to gather bootstrap log. $ ./openshift-install gather bootstrap --dir ipi --log-level debug DEBUG OpenShift Installer 4.17.0-0.test-2024-07-25-014817-ci-ln-rcc2djt-latest DEBUG Built from commit 91618bc6507416492d685c11540efb9ae9a0ec2e ... DEBUG Looking for machine manifests in ipi/.clusterapi_output DEBUG bootstrap manifests found: [ipi/.clusterapi_output/Machine-openshift-cluster-api-guests-jima25-m-4sq6j-bootstrap.yaml] DEBUG found bootstrap address: 10.0.0.7 DEBUG master machine manifests found: [ipi/.clusterapi_output/Machine-openshift-cluster-api-guests-jima25-m-4sq6j-master-0.yaml ipi/.clusterapi_output/Machine-openshift-cluster-api-guests-jima25-m-4sq6j-master-1.yaml ipi/.clusterapi_output/Machine-openshift-cluster-api-guests-jima25-m-4sq6j-master-2.yaml] DEBUG found master address: 10.0.0.4 DEBUG found master address: 10.0.0.5 DEBUG found master address: 10.0.0.6 ... DEBUG Added /home/fedora/.ssh/openshift-qe.pem to installer's internal agent DEBUG Added /home/fedora/.ssh/id_rsa to installer's internal agent DEBUG Added /home/fedora/.ssh/openshift-dev.pem to installer's internal agent DEBUG Added /tmp/bootstrap-ssh2769549403 to installer's internal agent INFO Failed to gather bootstrap logs: failed to connect to the bootstrap machine: dial tcp 10.0.0.7:22: connect: connection timed out ... Checked Machine-openshift-cluster-api-guests-jima25-m-4sq6j-bootstrap.yaml under capi artifact folder, only private IP is there. $ yq-go r Machine-openshift-cluster-api-guests-jima25-m-4sq6j-bootstrap.yaml status.addresses - type: InternalDNS address: jima25-m-4sq6j-bootstrap - type: InternalIP address: 10.0.0.7 From https://github.com/openshift/installer/pull/8669/, it creates an inbound nat rule that forwards port 22 on the public load balancer to the bootstrap host instead of creating public IP directly for bootstrap, and I tried and it was succeeded to ssh login bootstrap server by using frontend IP of public load balancer. But as no public IP saved in bootstrap machine CAPI artifact, installer failed to connect bootstrap machine with private ip.
Version-Release number of selected component (if applicable):
4.17 nightly build
How reproducible:
Always
Steps to Reproduce:
1. Create Azure IPI cluster by using CAPI
2. Interrupt installer when waiting for bootstrap complete
3. gather bootstrap logs
Actual results:
Only serial console logs and local capi artifacts are collected, logs on bootstrap and control plane fails to be collected due to ssh connection to bootstrap timeout.
Expected results:
succeed to gather bootstrap logs
Additional info:
Install with marketplace images specified in the install config.
Attach identities to VMs so that service principals are not placed on the VMs. CAPZ is issuing warnings about this when creating VMs.
Add configuration to support SSH'ing to bootstrap node.
Description of problem:
When creating cluster with service principal certificate, as known issues OCPBUGS-36360, installer exited with error. # ./openshift-install create cluster --dir ipi6 INFO Credentials loaded from file "/root/.azure/osServicePrincipal.json" WARNING Using client certs to authenticate. Please be warned cluster does not support certs and only the installer does. INFO Consuming Install Config from target directory WARNING FeatureSet "CustomNoUpgrade" is enabled. This FeatureSet does not allow upgrades and may affect the supportability of the cluster. INFO Creating infrastructure resources... INFO Started local control plane with envtest INFO Stored kubeconfig for envtest in: /tmp/jima/ipi6/.clusterapi_output/envtest.kubeconfig WARNING Using client certs to authenticate. Please be warned cluster does not support certs and only the installer does. INFO Running process: Cluster API with args [-v=2 --diagnostics-address=0 --health-addr=127.0.0.1:36847 --webhook-port=38905 --webhook-cert-dir=/tmp/envtest-serving-certs-941163289 --kubeconfig=/tmp/jima/ipi6/.clusterapi_output/envtest.kubeconfig] INFO Running process: azure infrastructure provider with args [-v=2 --health-addr=127.0.0.1:44743 --webhook-port=35373 --webhook-cert-dir=/tmp/envtest-serving-certs-3807817663 --feature-gates=MachinePool=false --kubeconfig=/tmp/jima/ipi6/.clusterapi_output/envtest.kubeconfig] INFO Running process: azureaso infrastructure provider with args [-v=0 -metrics-addr=0 -health-addr=127.0.0.1:45179 -webhook-port=37401 -webhook-cert-dir=/tmp/envtest-serving-certs-1364466879 -crd-pattern= -crd-management=none] ERROR failed to fetch Cluster: failed to generate asset "Cluster": failed to create cluster: failed to run cluster api system: failed to run controller "azureaso infrastructure provider": failed to start controller "azureaso infrastructure provider": timeout waiting for process cluster-api-provider-azureaso to start successfully (it may have failed to start, or stopped unexpectedly before becoming ready) INFO Shutting down local Cluster API control plane... INFO Local Cluster API system has completed operations From output, local cluster API system is shut down. But when checking processes, only parent process installer exit, CAPI related processes are still running. When local control plane is running: # ps -ef|grep cluster | grep -v grep root 13355 6900 39 08:07 pts/1 00:00:13 ./openshift-install create cluster --dir ipi6 root 13365 13355 2 08:08 pts/1 00:00:00 ipi6/cluster-api/etcd --advertise-client-urls=http://127.0.0.1:41341 --data-dir=ipi6/.clusterapi_output/etcd --listen-client-urls=http://127.0.0.1:41341 --listen-peer-urls=http://127.0.0.1:34081 --unsafe-no-fsync=true root 13373 13355 55 08:08 pts/1 00:00:10 ipi6/cluster-api/kube-apiserver --allow-privileged=true --authorization-mode=RBAC --bind-address=127.0.0.1 --cert-dir=/tmp/k8s_test_framework_50606349 --client-ca-file=/tmp/k8s_test_framework_50606349/client-cert-auth-ca.crt --disable-admission-plugins=ServiceAccount --etcd-servers=http://127.0.0.1:41341 --secure-port=38483 --service-account-issuer=https://127.0.0.1:38483/ --service-account-key-file=/tmp/k8s_test_framework_50606349/sa-signer.crt --service-account-signing-key-file=/tmp/k8s_test_framework_50606349/sa-signer.key --service-cluster-ip-range=10.0.0.0/24 root 13385 13355 0 08:08 pts/1 00:00:00 ipi6/cluster-api/cluster-api -v=2 --diagnostics-address=0 --health-addr=127.0.0.1:36847 --webhook-port=38905 --webhook-cert-dir=/tmp/envtest-serving-certs-941163289 --kubeconfig=/tmp/jima/ipi6/.clusterapi_output/envtest.kubeconfig root 13394 13355 6 08:08 pts/1 00:00:00 ipi6/cluster-api/cluster-api-provider-azure -v=2 --health-addr=127.0.0.1:44743 --webhook-port=35373 --webhook-cert-dir=/tmp/envtest-serving-certs-3807817663 --feature-gates=MachinePool=false --kubeconfig=/tmp/jima/ipi6/.clusterapi_output/envtest.kubeconfig After installer exited: # ps -ef|grep cluster | grep -v grep root 13365 1 1 08:08 pts/1 00:00:01 ipi6/cluster-api/etcd --advertise-client-urls=http://127.0.0.1:41341 --data-dir=ipi6/.clusterapi_output/etcd --listen-client-urls=http://127.0.0.1:41341 --listen-peer-urls=http://127.0.0.1:34081 --unsafe-no-fsync=true root 13373 1 45 08:08 pts/1 00:00:35 ipi6/cluster-api/kube-apiserver --allow-privileged=true --authorization-mode=RBAC --bind-address=127.0.0.1 --cert-dir=/tmp/k8s_test_framework_50606349 --client-ca-file=/tmp/k8s_test_framework_50606349/client-cert-auth-ca.crt --disable-admission-plugins=ServiceAccount --etcd-servers=http://127.0.0.1:41341 --secure-port=38483 --service-account-issuer=https://127.0.0.1:38483/ --service-account-key-file=/tmp/k8s_test_framework_50606349/sa-signer.crt --service-account-signing-key-file=/tmp/k8s_test_framework_50606349/sa-signer.key --service-cluster-ip-range=10.0.0.0/24 root 13385 1 0 08:08 pts/1 00:00:00 ipi6/cluster-api/cluster-api -v=2 --diagnostics-address=0 --health-addr=127.0.0.1:36847 --webhook-port=38905 --webhook-cert-dir=/tmp/envtest-serving-certs-941163289 --kubeconfig=/tmp/jima/ipi6/.clusterapi_output/envtest.kubeconfig root 13394 1 0 08:08 pts/1 00:00:00 ipi6/cluster-api/cluster-api-provider-azure -v=2 --health-addr=127.0.0.1:44743 --webhook-port=35373 --webhook-cert-dir=/tmp/envtest-serving-certs-3807817663 --feature-gates=MachinePool=false --kubeconfig=/tmp/jima/ipi6/.clusterapi_output/envtest.kubeconfig Another scenario, ran capi-based installer on the small disk, and installer stuck there and didn't exit until interrupted until <Ctrl> + C. Then checked that all CAPI related processes were still running, only installer process was killed. [root@jima09id-vm-1 jima]# ./openshift-install create cluster --dir ipi4 INFO Credentials loaded from file "/root/.azure/osServicePrincipal.json" INFO Consuming Install Config from target directory WARNING FeatureSet "CustomNoUpgrade" is enabled. This FeatureSet does not allow upgrades and may affect the supportability of the cluster. INFO Creating infrastructure resources... INFO Started local control plane with envtest INFO Stored kubeconfig for envtest in: /tmp/jima/ipi4/.clusterapi_output/envtest.kubeconfig INFO Running process: Cluster API with args [-v=2 --diagnostics-address=0 --health-addr=127.0.0.1:42017 --webhook-port=41085 --webhook-cert-dir=/tmp/envtest-serving-certs-1774658110 --kubeconfig=/tmp/jima/ipi4/.clusterapi_output/envtest.kubeconfig] INFO Running process: azure infrastructure provider with args [-v=2 --health-addr=127.0.0.1:38387 --webhook-port=37783 --webhook-cert-dir=/tmp/envtest-serving-certs-1319713198 --feature-gates=MachinePool=false --kubeconfig=/tmp/jima/ipi4/.clusterapi_output/envtest.kubeconfig] FATAL failed to extract "ipi4/cluster-api/cluster-api-provider-azureaso": write ipi4/cluster-api/cluster-api-provider-azureaso: no space left on device ^CWARNING Received interrupt signal ^C[root@jima09id-vm-1 jima]# [root@jima09id-vm-1 jima]# ps -ef|grep cluster | grep -v grep root 12752 1 0 07:38 pts/1 00:00:00 ipi4/cluster-api/etcd --advertise-client-urls=http://127.0.0.1:38889 --data-dir=ipi4/.clusterapi_output/etcd --listen-client-urls=http://127.0.0.1:38889 --listen-peer-urls=http://127.0.0.1:38859 --unsafe-no-fsync=true root 12760 1 4 07:38 pts/1 00:00:09 ipi4/cluster-api/kube-apiserver --allow-privileged=true --authorization-mode=RBAC --bind-address=127.0.0.1 --cert-dir=/tmp/k8s_test_framework_3790461974 --client-ca-file=/tmp/k8s_test_framework_3790461974/client-cert-auth-ca.crt --disable-admission-plugins=ServiceAccount --etcd-servers=http://127.0.0.1:38889 --secure-port=44429 --service-account-issuer=https://127.0.0.1:44429/ --service-account-key-file=/tmp/k8s_test_framework_3790461974/sa-signer.crt --service-account-signing-key-file=/tmp/k8s_test_framework_3790461974/sa-signer.key --service-cluster-ip-range=10.0.0.0/24 root 12769 1 0 07:38 pts/1 00:00:00 ipi4/cluster-api/cluster-api -v=2 --diagnostics-address=0 --health-addr=127.0.0.1:42017 --webhook-port=41085 --webhook-cert-dir=/tmp/envtest-serving-certs-1774658110 --kubeconfig=/tmp/jima/ipi4/.clusterapi_output/envtest.kubeconfig root 12781 1 0 07:38 pts/1 00:00:00 ipi4/cluster-api/cluster-api-provider-azure -v=2 --health-addr=127.0.0.1:38387 --webhook-port=37783 --webhook-cert-dir=/tmp/envtest-serving-certs-1319713198 --feature-gates=MachinePool=false --kubeconfig=/tmp/jima/ipi4/.clusterapi_output/envtest.kubeconfig root 12851 6900 1 07:41 pts/1 00:00:00 ./openshift-install destroy cluster --dir ipi4
Version-Release number of selected component (if applicable):
4.17 nightly build
How reproducible:
Always
Steps to Reproduce:
1. Run capi-based installer
2. Installer failed to start some capi process and exited
3.
Actual results:
Installer process exited, but capi related processes are still running
Expected results:
Both installer and all capi related processes are exited.
Additional info:
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Currently, CAPZ only allows a single API load balancer to be specified. OpenShift requires both a public and private load balancer. It is desirable to allow multiple load balancers to be specified in the API load balancer field.
We need to modify the Azure CAPI NetworkSpec to add support for an array of load balancers. For each LB in the array, the existing behavior of a load balancer needs to be implemented (adding VM's into the backend pool).
Description of problem:
Created VM instances on Azure, and assign managed identity to it, then created cluster in this VM, installer got error as below:
# ./openshift-install create cluster --dir ipi --log-level debug
...
time="2024-07-01T00:52:43Z" level=info msg="Waiting up to 15m0s (until 1:07AM UTC) for network infrastructure to become ready..."
...
time="2024-07-01T00:52:58Z" level=debug msg="I0701 00:52:58.528931 7149 recorder.go:104] \"failed to create scope: failed to configure azure settings and credentials for Identity: failed to create credential: secret can't be empty string\" logger=\"events\" type=\"Warning\" object={\"kind\":\"AzureCluster\",\"namespace\":\"openshift-cluster-api-guests\",\"name\":\"jima0701-hxtzd\",\"uid\":\"63aa5b17-9063-4b33-a471-1f58c146da8a\",\"apiVersion\":\"infrastructure.cluster.x-k8s.io/v1beta1\",\"resourceVersion\":\"1083\"} reason=\"CreateClusterScopeFailed\""
Version-Release number of selected component (if applicable):
4.17 nightly build
How reproducible:
Always
Steps to Reproduce:
1. Created VM and assigned managed identity to it
2. Create cluster in this VM
3.
Actual results:
cluster is created failed
Expected results:
cluster is installed successfully
Additional info:
These are install config fields that have existing counterparts in CAPZ. All we should need to do is plumb the values through, so should be relatively low effort.
Description of problem:
Specify controlPlane.architecture as arm64 in install-config
===
controlPlane:
architecture: arm64
name: master
platform:
azure:
type: null
compute:
- architecture: arm64
name: worker
replicas: 3
platform:
azure:
type: Standard_D4ps_v5
Launch installer to create cluster, installer exit with below error:
time="2024-07-26T06:11:00Z" level=debug msg="\tfailed to reconcile AzureMachine: failed to reconcile AzureMachine service virtualmachine: failed to create or update resource ci-op-wtm3h6km-72f4b-fdwtz-rg/ci-op-wtm3h6km-72f4b-fdwtz-bootstrap (service: virtualmachine): PUT https://management.azure.com/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/ci-op-wtm3h6km-72f4b-fdwtz-rg/providers/Microsoft.Compute/virtualMachines/ci-op-wtm3h6km-72f4b-fdwtz-bootstrap"
time="2024-07-26T06:11:00Z" level=debug msg="\t--------------------------------------------------------------------------------"
time="2024-07-26T06:11:00Z" level=debug msg="\tRESPONSE 400: 400 Bad Request"
time="2024-07-26T06:11:00Z" level=debug msg="\tERROR CODE: BadRequest"
time="2024-07-26T06:11:00Z" level=debug msg="\t--------------------------------------------------------------------------------"
time="2024-07-26T06:11:00Z" level=debug msg="\t{"
time="2024-07-26T06:11:00Z" level=debug msg="\t \"error\": {"
time="2024-07-26T06:11:00Z" level=debug msg="\t \"code\": \"BadRequest\","
time="2024-07-26T06:11:00Z" level=debug msg="\t \"message\": \"Cannot create a VM of size 'Standard_D8ps_v5' because this VM size only supports a CPU Architecture of 'Arm64', but an image or disk with CPU Architecture 'x64' was given. Please check that the CPU Architecture of the image or disk is compatible with that of the VM size.\""
time="2024-07-26T06:11:00Z" level=debug msg="\t }"
time="2024-07-26T06:11:00Z" level=debug msg="\t}"
time="2024-07-26T06:11:00Z" level=debug msg="\t--------------------------------------------------------------------------------"
time="2024-07-26T06:11:00Z" level=debug msg=" > controller=\"azuremachine\" controllerGroup=\"infrastructure.cluster.x-k8s.io\" controllerKind=\"AzureMachine\" AzureMachine=\"openshift-cluster-api-guests/ci-op-wtm3h6km-72f4b-fdwtz-bootstrap\" namespace=\"openshift-cluster-api-guests\" name=\"ci-op-wtm3h6km-72f4b-fdwtz-bootstrap\" reconcileID=\"60b1d513-07e4-4b34-ac90-d2a33ce156e1\""
Checked that gallery image definitions (Gen1 & Gen2), the architecture is still x64.
$ az sig image-definition show --gallery-image-definition ci-op-wtm3h6km-72f4b-fdwtz -g ci-op-wtm3h6km-72f4b-fdwtz-rg --gallery-name gallery_ci_op_wtm3h6km_72f4b_fdwtz
{
"architecture": "x64",
"hyperVGeneration": "V1",
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/ci-op-wtm3h6km-72f4b-fdwtz-rg/providers/Microsoft.Compute/galleries/gallery_ci_op_wtm3h6km_72f4b_fdwtz/images/ci-op-wtm3h6km-72f4b-fdwtz",
"identifier": {
"offer": "rhcos",
"publisher": "RedHat",
"sku": "basic"
},
"location": "southcentralus",
"name": "ci-op-wtm3h6km-72f4b-fdwtz",
"osState": "Generalized",
"osType": "Linux",
"provisioningState": "Succeeded",
"resourceGroup": "ci-op-wtm3h6km-72f4b-fdwtz-rg",
"tags": {
"kubernetes.io_cluster.ci-op-wtm3h6km-72f4b-fdwtz": "owned"
},
"type": "Microsoft.Compute/galleries/images"
}
$ az sig image-definition show --gallery-image-definition ci-op-wtm3h6km-72f4b-fdwtz-gen2 -g ci-op-wtm3h6km-72f4b-fdwtz-rg --gallery-name gallery_ci_op_wtm3h6km_72f4b_fdwtz
{
"architecture": "x64",
"hyperVGeneration": "V2",
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/ci-op-wtm3h6km-72f4b-fdwtz-rg/providers/Microsoft.Compute/galleries/gallery_ci_op_wtm3h6km_72f4b_fdwtz/images/ci-op-wtm3h6km-72f4b-fdwtz-gen2",
"identifier": {
"offer": "rhcos-gen2",
"publisher": "RedHat-gen2",
"sku": "gen2"
},
"location": "southcentralus",
"name": "ci-op-wtm3h6km-72f4b-fdwtz-gen2",
"osState": "Generalized",
"osType": "Linux",
"provisioningState": "Succeeded",
"resourceGroup": "ci-op-wtm3h6km-72f4b-fdwtz-rg",
"tags": {
"kubernetes.io_cluster.ci-op-wtm3h6km-72f4b-fdwtz": "owned"
},
"type": "Microsoft.Compute/galleries/images"
}
Version-Release number of selected component (if applicable):
4.17 nightly build
How reproducible:
Always
Steps to Reproduce:
1. Configure controlPlane.architecture as arm64
2. Create cluster by using multi nightly build
Actual results:
Installation fails as unable to create bootstrap/master machines
Expected results:
Installation succeeds.
Additional info:
Outbound Type defines how egress is provided for the cluster. Currently 3 options: Load Balancer (default), User Defined Routing and NAT Gateway (tech preview) are supported.
As part of the move away from terraform, the `UserDefinedRouting` outboundType needs to be supported.
Description of problem:
Failed to create second cluster in shared vnet, below error is thrown out during creating network infrastructure when creating 2nd cluster, installer timed out and exited.
==============
07-23 14:09:27.315 level=info msg=Waiting up to 15m0s (until 6:24AM UTC) for network infrastructure to become ready...
...
07-23 14:16:14.900 level=debug msg= failed to reconcile cluster services: failed to reconcile AzureCluster service loadbalancers: failed to create or update resource jima0723b-1-x6vpp-rg/jima0723b-1-x6vpp-internal (service: loadbalancers): PUT https://management.azure.com/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jima0723b-1-x6vpp-rg/providers/Microsoft.Network/loadBalancers/jima0723b-1-x6vpp-internal
07-23 14:16:14.900 level=debug msg= --------------------------------------------------------------------------------
07-23 14:16:14.901 level=debug msg= RESPONSE 400: 400 Bad Request
07-23 14:16:14.901 level=debug msg= ERROR CODE: PrivateIPAddressIsAllocated
07-23 14:16:14.901 level=debug msg= --------------------------------------------------------------------------------
07-23 14:16:14.901 level=debug msg= {
07-23 14:16:14.901 level=debug msg= "error": {
07-23 14:16:14.901 level=debug msg= "code": "PrivateIPAddressIsAllocated",
07-23 14:16:14.901 level=debug msg= "message": "IP configuration /subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jima0723b-1-x6vpp-rg/providers/Microsoft.Network/loadBalancers/jima0723b-1-x6vpp-internal/frontendIPConfigurations/jima0723b-1-x6vpp-internal-frontEnd is using the private IP address 10.0.0.100 which is already allocated to resource /subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jima0723b-49hnw-rg/providers/Microsoft.Network/loadBalancers/jima0723b-49hnw-internal/frontendIPConfigurations/jima0723b-49hnw-internal-frontEnd.",
07-23 14:16:14.902 level=debug msg= "details": []
07-23 14:16:14.902 level=debug msg= }
07-23 14:16:14.902 level=debug msg= }
07-23 14:16:14.902 level=debug msg= --------------------------------------------------------------------------------
Install-config for 1st cluster:
=========
metadata:
name: jima0723b
platform:
azure:
region: eastus
baseDomainResourceGroupName: os4-common
networkResourceGroupName: jima0723b-rg
virtualNetwork: jima0723b-vnet
controlPlaneSubnet: jima0723b-master-subnet
computeSubnet: jima0723b-worker-subnet
publish: External
Install-config for 2nd cluster:
========
metadata:
name: jima0723b-1
platform:
azure:
region: eastus
baseDomainResourceGroupName: os4-common
networkResourceGroupName: jima0723b-rg
virtualNetwork: jima0723b-vnet
controlPlaneSubnet: jima0723b-master-subnet
computeSubnet: jima0723b-worker-subnet
publish: External
shared master subnet/worker subnet:
$ az network vnet subnet list -g jima0723b-rg --vnet-name jima0723b-vnet -otable
AddressPrefix Name PrivateEndpointNetworkPolicies PrivateLinkServiceNetworkPolicies ProvisioningState ResourceGroup
--------------- ----------------------- -------------------------------- ----------------------------------- ------------------- ---------------
10.0.0.0/24 jima0723b-master-subnet Disabled Enabled Succeeded jima0723b-rg
10.0.1.0/24 jima0723b-worker-subnet Disabled Enabled Succeeded jima0723b-rg
internal lb frontedIPConfiguration on 1st cluster:
$ az network lb show -n jima0723b-49hnw-internal -g jima0723b-49hnw-rg --query 'frontendIPConfigurations'
[
{
"etag": "W/\"7a7531ca-fb02-48d0-b9a6-d3fb49e1a416\"",
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jima0723b-49hnw-rg/providers/Microsoft.Network/loadBalancers/jima0723b-49hnw-internal/frontendIPConfigurations/jima0723b-49hnw-internal-frontEnd",
"inboundNatRules": [
{
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jima0723b-49hnw-rg/providers/Microsoft.Network/loadBalancers/jima0723b-49hnw-internal/inboundNatRules/jima0723b-49hnw-master-0",
"resourceGroup": "jima0723b-49hnw-rg"
},
{
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jima0723b-49hnw-rg/providers/Microsoft.Network/loadBalancers/jima0723b-49hnw-internal/inboundNatRules/jima0723b-49hnw-master-1",
"resourceGroup": "jima0723b-49hnw-rg"
},
{
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jima0723b-49hnw-rg/providers/Microsoft.Network/loadBalancers/jima0723b-49hnw-internal/inboundNatRules/jima0723b-49hnw-master-2",
"resourceGroup": "jima0723b-49hnw-rg"
}
],
"loadBalancingRules": [
{
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jima0723b-49hnw-rg/providers/Microsoft.Network/loadBalancers/jima0723b-49hnw-internal/loadBalancingRules/LBRuleHTTPS",
"resourceGroup": "jima0723b-49hnw-rg"
},
{
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jima0723b-49hnw-rg/providers/Microsoft.Network/loadBalancers/jima0723b-49hnw-internal/loadBalancingRules/sint-v4",
"resourceGroup": "jima0723b-49hnw-rg"
}
],
"name": "jima0723b-49hnw-internal-frontEnd",
"privateIPAddress": "10.0.0.100",
"privateIPAddressVersion": "IPv4",
"privateIPAllocationMethod": "Static",
"provisioningState": "Succeeded",
"resourceGroup": "jima0723b-49hnw-rg",
"subnet": {
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/jima0723b-rg/providers/Microsoft.Network/virtualNetworks/jima0723b-vnet/subnets/jima0723b-master-subnet",
"resourceGroup": "jima0723b-rg"
},
"type": "Microsoft.Network/loadBalancers/frontendIPConfigurations"
}
]
From above output, privateIPAllocationMethod is static and always allocate privateIPAddress to 10.0.0.100, this might cause the 2nd cluster installation failure.
Checked the same on cluster created by using terraform, privateIPAllocationMethod is dynamic.
===============
$ az network lb show -n wxjaz723-pm99k-internal -g wxjaz723-pm99k-rg --query 'frontendIPConfigurations'
[
{
"etag": "W/\"e6bec037-843a-47ba-a725-3f322564be58\"",
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/wxjaz723-pm99k-rg/providers/Microsoft.Network/loadBalancers/wxjaz723-pm99k-internal/frontendIPConfigurations/internal-lb-ip-v4",
"loadBalancingRules": [
{
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/wxjaz723-pm99k-rg/providers/Microsoft.Network/loadBalancers/wxjaz723-pm99k-internal/loadBalancingRules/api-internal-v4",
"resourceGroup": "wxjaz723-pm99k-rg"
},
{
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/wxjaz723-pm99k-rg/providers/Microsoft.Network/loadBalancers/wxjaz723-pm99k-internal/loadBalancingRules/sint-v4",
"resourceGroup": "wxjaz723-pm99k-rg"
}
],
"name": "internal-lb-ip-v4",
"privateIPAddress": "10.0.0.4",
"privateIPAddressVersion": "IPv4",
"privateIPAllocationMethod": "Dynamic",
"provisioningState": "Succeeded",
"resourceGroup": "wxjaz723-pm99k-rg",
"subnet": {
"id": "/subscriptions/53b8f551-f0fc-4bea-8cba-6d1fefd54c8a/resourceGroups/wxjaz723-rg/providers/Microsoft.Network/virtualNetworks/wxjaz723-vnet/subnets/wxjaz723-master-subnet",
"resourceGroup": "wxjaz723-rg"
},
"type": "Microsoft.Network/loadBalancers/frontendIPConfigurations"
},
...
]
Version-Release number of selected component (if applicable):
4.17 nightly build
How reproducible:
Always
Steps to Reproduce:
1. Create shared vnet / master subnet / worker subnet
2. Create 1st cluster in shared vnet
3. Create 2nd cluster in shared vnet
Actual results:
2nd cluster installation failed
Expected results:
Both clusters are installed successfully.
Additional info:
Description of problem:
Whatever vmNetworkingType setting under ControlPlane in install-config, "Accelerated networking" on master instances are always disabled. In install-config.yaml, set controlPlane.platform.azure.vmNetworkingType to 'Accelerated' or without such setting on controlPlane ======================= controlPlane: architecture: amd64 hyperthreading: Enabled name: master platform: azure: vmNetworkingType: 'Accelerated' create cluster, and checked "Accelerated networking" on master instances, all are disabled. $ az network nic show --name jima24c-tp7lp-master-0-nic -g jima24c-tp7lp-rg --query 'enableAcceleratedNetworking' false After creating manifests, checked capi manifests, acceleratedNetworking is set as false. $ yq-go r 10_inframachine_jima24c-qglff-master-0.yaml 'spec.networkInterfaces' - acceleratedNetworking: false
Version-Release number of selected component (if applicable):
4.17.0-0.nightly-2024-06-23-145410
How reproducible:
Always
Steps to Reproduce:
1. Set vmNetworkingType to 'Accelerated' or without vmNetworkingType setting under controlPlane in install-config 2. Create cluster 3.
Actual results:
AcceleratedNetworking on all master instances are always disabled.
Expected results:
1. Without vmNetworkingType setting in install-config, AcceleratedNetworking on all master instances should be enabled by default, which keeps the same behavior as terraform based installation. 2. AcceleratedNetworking on all master instances should be consistent with setting in install-config.
Additional info:
CAPZ expects a VM extension to report back that capi bootstapping is successful but rhcos does not support extensions (because it, by design, does not support the azure linux agent).
We need https://github.com/kubernetes-sigs/cluster-api-provider-azure/pull/4792 to be able to disable the default extension in capz.
Feature Overview
Much like core OpenShift operators, a standardized flow exists for OLM-managed operators to interact with the cluster in a specific way to leverage GCP Workload Identity Federation-based authorization when using GCP APIs as opposed to insecure static, long-lived credentials. OLM-managed operators can implement integration with the CloudCredentialOperator in well-defined way to support this flow.
Goals:
Enable customers to easily leverage OpenShift's capabilities around GCP WIF with layered products, for increased security posture. Enable OLM-managed operators to implement support for this in well-defined pattern.
Requirements:
- CCO gets a new mode in which it can reconcile GCPP credential request for OLM-managed operators
- A standardized flow is leveraged to guide users in discovering and preparing their GCP IAM policies and roles with permissions that are required for OLM-managed operators
- A standardized flow is defined in which users can configure OLM-managed operators to leverage GCP WIF
- An example operator is used to demonstrate the end2end functionality
- Clear instructions and documentation for operator development teams to implement the required interaction with the CloudCredentialOperator to support this flow
Use Cases:
See Operators & STS slide deck.
Out of Scope:
- handling OLM-managed operator updates in which GCP IAM permission requirements might change from one version to another (which requires user awareness and intervention)
Background:
The CloudCredentialsOperator already provides a powerful API for OpenShift's cluster core operator to request credentials and acquire them via short-lived tokens for other cloud providers like AWS. This capabilitiy is now also being implemented for GCP as part of CCO-1898 and CCO-285. The support should be expanded to OLM-managed operators, specifically to Red Hat layered products that interact with GCP APIs. The process today is cumbersome to none-existent based on the operator in question and seen as an adoption blocker of OpenShift on GCP.
Customer Considerations
This is particularly important for OSD on GCP customers. Customers are expected to be asked to pre-create the required IAM roles outside of OpenShift, which is deemed acceptable.
Documentation Considerations
- Internal documentation needs to exists to guide Red Hat operator developer teams on the requirements and proposed implementation of integration with CCO and the proposed flow
- External documentation needs to exist to guide users on:
- how to become aware that the cluster is in GCP WIF mode
- how to become aware of operators that support GCP WIF and the proposed CCO flow
- how to become aware of the IAM permissions requirements of these operators
- how to configure an operator in the proposed flow to interact with CCO
Interoperability Considerations
- this needs to work with OSD on GCP
- this needs to work with self-managed OCP on AWS
CCO needs to support the CloudCredentialRequestAPI with GCP Workload Identity (just like we did for AWS STS and Azure Entra Workload ID) to enable OCPSTRAT-922 (CloudCredentialOperator-based workflows for OLM-managed operators and GCP WIF).
Similar to the AWS and Azure actuators, we need to add the STS OLM functionality to the GCP actuator.
Feature Overview (aka. Goal Summary)
When the internal oauth-server and oauth-apiserver are removed and replaced with an external OIDC issuer (like azure AD), the console must work for human users of the external OIDC issuer.
Goals (aka. expected user outcomes)
An end user can use the openshift console without a notable difference in experience. This must eventually work on both hypershift and standalone, but hypershift is the first priority if it impacts delivery
Requirements (aka. Acceptance Criteria):
- User can log in and use the console
- User can get a kubeconfig that functions on the CLI with matching oc
- Both of those work on hypershift
- both of those work on standalone.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- When installed with external OIDC, the clientID and clientSecret need to be configurable to match the external (and unmanaged) OIDC server
Why is this important?
- Without a configurable clientID and secret, I don't think the console can identify the user.
- There must be a mechanism to do this on both hypershift and openshift, though the API may be very similar.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Description of problem:
When a cluster is configured for direct OIDC configuration (authentication.config/cluster .spec.type=OIDC), console pods will be in crashloop until an OIDC client is configured for the console.
Version-Release number of selected component (if applicable):
4.15.0
How reproducible:
100% in Hypershift; 100% in TechPreviewNoUpgrade featureset on standalone OpenShift
Steps to Reproduce:
1. Update authentication.config/cluster so that Type=OIDC
Actual results:
The console operator tries to create a new console rollout, but the pods crashloop. This is because the operator sets the console pods to "disabled". This would normally actually mean a privilege escalation, fortunately the configuration prevents a successful deploy.
Expected results:
Console pods are healthy, they show a page which says that no authentication is currently configured.
Additional info:
Epic Goal
- The goal of this epic is to upgrade all OpenShift and Kubernetes components that MCO uses to v1.29 which will keep it on par with rest of the OpenShift components and the underlying cluster version.
Why is this important?
- Uncover any possible issues with the openshift/kubernetes rebase before it merges.
- MCO continues using the latest kubernetes/OpenShift libraries and the kubelet, kube-proxy components.
- MCO e2e CI jobs pass on each of the supported platform with the updated components.
Acceptance Criteria
- All stories in this epic must be completed.
- Go version is upgraded for MCO components.
- CI is running successfully with the upgraded components against the 4.16/master branch.
Dependencies (internal and external)
- ART team creating the go 1.29 image for upgrade to go 1.29.
- OpenShift/kubernetes repository downstream rebase PR merge.
Open questions::
- Do we need a checklist for future upgrades as an outcome of this epic?-> yes, updated below.
Done Checklist
- Step 1 - Upgrade go version to match rest of the OpenShift and Kubernetes upgraded components.
- Step 2 - Upgrade Kubernetes client and controller-runtime dependencies (can be done in parallel with step 3)
- Step 3 - Upgrade OpenShift client and API dependencies
- Step 4 - Update kubelet and kube-proxy submodules in MCO repository
- Step 5 - CI is running successfully with the upgraded components and libraries against the master branch.
This feature is now re-opened because we want to run z-rollback CI. This feature doesn't block the release of 4.17.This is not going to be exposed as a customer-facing feature and will not be documented within OpenShift documentation. This is strictly going to be covered as a RH Support guided solution with KCS article providing guidance. A public facing KCS will basically point to contacting Support for help on Z-stream rollback, and Y-stream rollback is not supported.
NOTE:
Previously this was closed as "won't do" because didn't have a plan to support y-stream and z-stream rollbacks is standalone openshift.
For Single node openshift please check TELCOSTRAT-160 . "won't do" decisions was after further discussion with leadership.
The e2e tests https://docs.google.com/spreadsheets/d/1mr633YgQItJ0XhbiFkeSRhdLlk6m9vzk1YSKQPHgSvw/edit?gid=0#gid=0 We have identified a few bugs that need to be resolved before the General Availability (GA) release. Ideally, these should be addressed in the final month before GA when all features are development complete. However, asking component teams to commit to fixing critical rollback bugs during this time could potentially delay the GA date.
------
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Red Hat Support assisted z-stream rollback from 4.16+
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
Red Hat Support may, at their discretion, assist customers with z-stream rollback once it’s determined to be the best option for restoring a cluster to the desired state whenever a z-stream rollback compromises cluster functionality.
Engineering will take a “no regressions, no promises” approach, ensuring there are no major regressions between z-streams, but not testing specific combinations or addressing case-specific bugs.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
- Public Documentation (or KCS?) that explains why we do not advise unassisted z-stream rollback and what to do when a cluster experiences loss of functionality associated with a z-stream upgrade.
- Internal KCS article that provides a comprehensive plan for troubleshooting and resolving issues introduced after applying a z-stream update, up to and including complete z-stream rollback.
- Should include alternatives such as limited component rollback (single operator, RHCOS, etc) and workaround options
- Should include incident response and escalation procedures for all issues incurred during application of a z-stream update so that even if rollback is performed we’re tracking resolution of defects with highest priority
- Foolproof command to initiate z-stream rollback with Support’s approval, aka a hidden command that ensures we don’t typo the pull spec or initiate A->B->C version changes, only A->B->A
- Test plan and jobs to ensure that we have high confidence in ability to rollback a z-stream along happy paths
- Need not be tested on all platforms and configurations, likely metal or vSphere and one foolproof platform like AWS
- Test should not monitor for disruption since it’s assumed disruption is tolerable during an emergency rollback provided we achieve availability at the end of the operation
- Engineering agrees to fix bugs which inhibit rollback completion before the current master branch release ships, aka they’ll be filed as blockers for the current master branch release. This means bugs found after 4.N branches may not be fixed until the next release without discussion.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed | all |
| Multi node, Compact (three node) | all |
| Connected and Restricted Network | all |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all |
| Release payload only | all |
| Starting with 4.16, including all future releases | all |
While this feature applies to all deployments we will only run a single platform canary test on a high success rate platform, such as AWS. Any specific ecosystems which require more focused testing should bring their own testing.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
As an admin who has determined that a z-stream update has compromised cluster functionality I have clear documentation that explains that unassisted rollback is not supported and that I should consult with Red Hat Support on the best path forward.
As a support engineer I have a clear plan for responding to problems which occur during or after a z-stream upgrade, including the process for rolling back specific components, applying workarounds, or rolling the entire cluster back to the previously running z-stream version.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Should we allow rollbacks whenever an upgrade doesn’t complete? No, not without fully understanding the root cause. If it’s simply a situation where workers are in process of updating but stalled, that should never yield a rollback without credible evidence that rollback will fix that.
Similar to our “foolproof command” to initiate rollback to previous z-stream should we also craft a foolproof command to override select operators to previous z-stream versions? Part of the goal of the foolproof command is to avoid potential for moving to an unintended version, the same risk may apply at single operator level though impact would be smaller it could still be catastrophic.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Non-HA clusters, Hosted Control Planes – those may be handled via separately scoped features
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Occasionally clusters either upgrade successfully and encounter issues after the upgrade or may run into problems during the upgrade. Many customers assume that a rollback will fix their concerns but without understanding the root cause we cannot assume that’s the case. Therefore, we recommend anyone who has encountered a negative outcome associated with a z-stream upgrade contact support for guidance.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
It’s expected that customers should have adequate testing and rollout procedures to protect against most regressions, i.e. roll out a z-stream update in pre-production environments where it can be adequately tested prior to updating production environments.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
This is largely a documentation effort, i.e. we should create either a KCS article or new documentation section which describes how customers should respond to loss of functionality during or after an upgrade.
KCS Solution : https://access.redhat.com/solutions/7083335
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Given we test as many upgrade configurations as possible and for whatever reason the upgrade still encounters problems, we should not strive to comprehensively test all configurations for rollback success. We will only test a limited set of platforms and configurations necessary to ensure that we believe the platform is generally able to roll back a z-stream update.
Epic Goal
- Validate z-stream rollbacks in CI starting with 4.10 by ensuring that a rollback completes unassisted and e2e testsuite passes
- Provide internal documentation (private KCS article) that explains when this is the best course of action versus working around a specific issue
- Provide internal documentation (private KCS article) that explains the expected cluster degradation until the rollback is complete
- Provide internal documentation (private KCS article) outlining the process and any post rollback validation
Why is this important?
- Even if upgrade success is 100% there's some chance that we've introduced a change which is incompatible with a customer's needs and they desire to roll back to the previous z-stream
- Previously we've relied on backup and restore here, however due to many problems with time travel, that's only appropriate for disaster recovery scenarios where the cluster is either completely shut down already or it's acceptable to do so while also accepting loss of any workload state change (PVs that were attached after the backup was taken, etc)
- We believe that we can reasonably roll back to a previous z-stream
Scenarios
- Upgrade from 4.10.z to 4.10.z+n
- oc adm upgrade rollback-z-stream – which will initially be hidden command, this will look at clusterversion history and rollback to the previous version if and only if that version is a z-stream away
- Rollback from 4.10.z+n to exactly 4.10.z, during which the cluster may experience degraded service and/or periods of service unavailability but must eventually complete with no further admin action
- Must pass 4.10.z e2e testsuite
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Fix all bugs listed here
project = "OpenShift Bugs" AND affectedVersion in( 4.12, 4.14, 4.15) AND labels = rollback AND status not in (Closed ) ORDER BY status DESC
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- At least today we indend to only surface this process internally and work through it with customers actively engaged with support, where do we put that?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- Validate z-stream rollbacks in CI starting with 4.16 by ensuring that a rollback completes unassisted and e2e testsuite passes
- Provide internal documentation (private KCS article) that explains when this is the best course of action versus working around a specific issue
- Provide internal documentation (private KCS article) that explains the expected cluster degradation until the rollback is complete
- Provide internal documentation (private KCS article) outlining the process and any post rollback validation
Why is this important?
- Even if upgrade success is 100% there's some chance that we've introduced a change which is incompatible with a customer's needs and they desire to roll back to the previous z-stream
- Previously we've relied on backup and restore here, however due to many problems with time travel, that's only appropriate for disaster recovery scenarios where the cluster is either completely shut down already or it's acceptable to do so while also accepting loss of any workload state change (PVs that were attached after the backup was taken, etc)
- We believe that we can reasonably roll back to a previous z-stream
Scenarios
- Upgrade from 4.16.z to 4.16.z+n
- oc adm upgrade rollback-z-stream – which will initially be hidden command, this will look at clusterversion history and rollback to the previous version if and only if that version is a z-stream away
- Rollback from 4.16.z+n to exactly 4.16.z, during which the cluster may experience degraded service and/or periods of service unavailability but must eventually complete with no further admin action
- Must pass 4.16.z e2e testsuite
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Fix all bugs listed here
project = "OpenShift Bugs" AND affectedVersion in( 4.16, 4.17) AND labels = rollback AND status not in (Closed ) ORDER BY status DESC
Documentation
KCS : https://access.redhat.com/solutions/7089715
Open questions::
- At least today we indend to only surface this process internally and work through it with customers actively engaged with support, where do we put that?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Description of problem
OTA-941 landed a rollback guard in 4.14 that blocked all rollbacks. OCPBUGS-24535 drilled a hole in that guard to allow limited rollbacks to the previous release the cluster had been aiming at, as long as that previous release was part of the same 4.y z stream. We decided to block that hole back up in OCPBUGS-35994. And now folks want the hole re-opened in this bug. We also want to bring back the oc adm upgrade rollback ... subcommand. Hopefully this new plan sticks ![]()
Version-Release number of selected component
Folks want the guard-hole and rollback subcommand restored for 4.16 and 4.17.
How reproducible
Every time.
Steps to Reproduce
Try to perform the rollbacks that OCPBUGS-24535 allowed.
Actual results
They stop working, with reasonable ClusterVersion conditions explaining that even those rollback requests will not be accepted.
Expected results
They work, as verified in OCPBUGS-24535.
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
openshift-sdn is no longer part of OCP in 4.17, so CNO must stop referring to its image
Why is this important?
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
- Priority+ is set by engineering
- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
This feature is to track automation in ODC, related packages, upgrades and some tech debts
Goals
- Improve automation for Pipelines dynamic plugins
- Improve automation for OpenShift Developer console
- Move cypress script into frontend to make it easier to approve changes
- Update to latest PatternFly QuickStarts
Requirements
- TBD
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | No |
Questions to answer…
- Is there overlap with what other teams at RH are already planning? No overlap
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
This won't impact documentation and this feature is to mostly enhance end to end test and job runs on CI
Assumptions
- ...
Customer Considerations
- No direct impact to customer
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Here is our overall tech debt backlog: ODC-6711
See included tickets, we want to clean up in 4.16.
Description
This is a follow-up on https://github.com/openshift/console/pull/13931.
We should move test-cypress.sh from the root of the console project into the frontend folder or a new frontend integration-tests folder to allow more people to approve changes in the test-cypress.sh script.
Acceptance Criteria
- More people can approve changes in the test-cypress.sh script.
Additional Details:
*Executive Summary *
Provide mechanisms for the builder service account to be made optional in core OpenShift.
Goals
< Who benefits from this feature, and how? What is the difference between today’s current state and a world with this feature? >
- Let cluster administrators disable the automatic creation of the "builder" service account when the Build capability is disabled on the cluster. This reduces potential attack vectors for clusters that do not run build or other CI/CD workloads. Example - fleets for mission-critical applications, edge deployments, security-sensitive environments.
- Let cluster administrators enable/disable the generation of the "builder" service account at will. Applies to new installations with the "Build" capability enabled as well as upgraded clusters. This helps customers who are not able to easily provision new OpenShift clusters and block usage of the Build system through other means (ex: RBAC, 3rd party admission controllers (ex OPA, Kyverno)).
Requirements
| Requirements | Notes | IS MVP |
| Disable service account controller related to Build/BuildConfig when Build capability is disabled | When the API is marked as removed or disabled, stop creating the "builder" service account and its associated RBAC | Yes |
| Option to disable the "builder" service account | Even if the Build capability is enabled, allow admins to disable the "builder" service account generation. Admins will need to bring their own service accounts/RBAC for builds to work | Yes |
(Optional) Use Cases
< What are we making, for who, and why/what problem are we solving?>
- Build as an installation capability - see
WRKLDS-695 - Disabling the Build system through RBAC or admission controllers. The "builder" service account is the only thing that RBAC and admission control cannot block without significant cluster impact.
Out of scope
<Defines what is not included in this story>
- Disabling the Build API separately from the capabilities feature
Dependencies
< Link or at least explain any known dependencies. >
- Build capability:
WRKLDS-695 - Separate controllers for default service accounts: API-1651
Background, and strategic fit
< What does the person writing code, testing, documenting need to know? >
- In OCP 4.14, "Build" was introduced as an optional installation capability. This means that the BuildConfig API and subsystems are not guaranteed to be present on new clusters.
- The "builder" service account is granted permission to push images to the OpenShift internal registry via a controller. There is risk that the service account can be used as an attack vector to overwrite images in the internal registry.
- OpenShift has an existing API to configure the build system. See OCP documentation on the current supported options. The current OCP build test suite includes checks for these global settings. Source code.
- Customers with larger footprints typically separate "CI/CD clusters" from "application clusters" that run production workloads. This is because CI/CD workloads (and building container images in particular) can have "noisy" consumption of resources that risk destabilizing running applications.
Assumptions
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Customer Considerations
< Are there specific customer environments that need to be considered (such as working with existing h/w and software)?>
- Must work for new installations as well as upgraded clusters.
Documentation Considerations
< What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)? >
- Update the "Build configurations" doc so admins can understand the new feature.
- Potential updates to "Understanding BuildConfig" doc doc to include references to the serviceAccount option in the spec, as well as a section describing the permissions granted to the "builder" service account.
What does success look like?
< Does this feature have doc impact? Possible values are: New Content, Updates to existing content, Release Note, or No Doc Impact?>
QE Contact
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Impact
< If the feature is ordered with other work, state the impact of this feature on the other work>
Related Architecture/Technical Documents
- Disabling OCM Controllers (slides). Note that the controller names may be a bit out of date once API-1651 is done.
- Install capabilities - OCP docs
Done Checklist
- Acceptance criteria are met
- Non-functional properties of the Feature have been validated (such as performance, resource, UX, security or privacy aspects)
- User Journey automation is delivered
- Support and SRE teams are provided with enough skills to support the feature in production environment
Description of problem:
When a cluster is deployed with no capabilities enabled, and the Build capability is later enabled, it's related cluster configuration CRD is not installed. This prevents admins from fine-tuning builds and ocm-o from fully reconciling its state.
Version-Release number of selected component (if applicable):
4.16.0
How reproducible:
Always
Steps to Reproduce:
1. Launch a cluster with no capabilities enabled (via cluster-bot: launch 4.16.0.0-ci aws,no-capabilities
2. Edit the clusterversion to enable the build capability: oc patch clusterversion/version --type merge -p '{"spec":{"capabilities":{"additionalEnabledCapabilities":["Build"]}}}'
3. Wait for the openshift-apiserver and openshift-controller-manager to roll out
Actual results:
APIs for BuildConfig (build.openshift.io) are enabled.
Cluster configuration API for build system is not:
$ oc api-resources | grep "build"
buildconfigs bc build.openshift.io/v1 true BuildConfig
builds build.openshift.io/v1 true Build
Expected results:
Cluster configuration API is enabled.
$ oc api-resources | grep "build"
buildconfigs bc build.openshift.io/v1 true BuildConfig
builds build.openshift.io/v1 true Build
builds config.openshift.io/v1 true Build
Additional info:
This causes list errors in openshift-controller-manager-operator, breaking the controller that reconciles state for builds and the image registry.
W0523 18:23:38.551022 1 reflector.go:539] k8s.io/client-go@v0.29.0/tools/cache/reflector.go:229: failed to list *v1.Build: the server could not find the requested resource (get builds.config.openshift.io)
E0523 18:23:38.551334 1 reflector.go:147] k8s.io/client-go@v0.29.0/tools/cache/reflector.go:229: Failed to watch *v1.Build: failed to list *v1.Build: the server could not find the requested resource (get builds.config.openshift.io)
Story (Required)
As a cluster admin trying to disable the Build, DeploymentConfig, and Image Registry capabilities I want the RBAC controllers for the builder and deployer service accounts and default image-registry rolebindings disabled when their respective capability is disabled.
<Describes high level purpose and goal for this story. Answers the questions: Who is impacted, what is it and why do we need it? How does it improve the customer's experience?>
Background (Required)
<Describes the context or background related to this story>
In WRKLDS-695, ocm-o was enhanced to disable the Build and DeploymentConfig controllers when the respective capability was disabled. This logic should be extended to include the controllers that set up the service accounts and role bindings for these respective features.
Out of scope
<Defines what is not included in this story>
Approach (Required)
<Description of the general technical path on how to achieve the goal of the story. Include details like json schema, class definitions>
- Ensure that all the controllers (builder, deployer, image-puller rolebinding controllers) are specified in the api/*/types.go as well as in controllerInitializers, so that the controller is initiated when capability is enabled.
- Map the controllers introduced with
BUILD-725to respective capabilities in ocm-operator.- This helps to avoid running controllers when capabilities are disabled.
- The relevant clusterVersionCapability is available here
- The OpenShift CI has no check for cluster deployment with capabilities disabled. Looked through https://github.com/openshift/release/tree/master/ci-operator/step-registry/ipi/conf/capability
-
- Needs manual testing (OpenShift cluster deployed with all/some capabilities disabled).
Dependencies
<Describes what this story depends on. Dependent Stories and EPICs should be linked to the story.>
Acceptance Criteria (Mandatory)
- Build and DeploymentConfig systems remain functional when the respective capability is enabled.
- Build, DeploymentConfig, and Image-Puller RoleBinding controllers are not started when the respective capability is disabled.
INVEST Checklist
Dependencies identified
Blockers noted and expected delivery timelines set
Design is implementable
Acceptance criteria agreed upon
Story estimated
- Engineering: 5
- QE: 2
- Doc: 2
Legend
Unknown
Verified
Unsatisfied
Done Checklist
- Code is completed, reviewed, documented and checked in
- Unit and integration test automation have been delivered and running cleanly in continuous integration/staging/canary environment
- Continuous Delivery pipeline(s) is able to proceed with new code included
- Customer facing documentation, API docs etc. are produced/updated, reviewed and published
- Acceptance criteria are met
In OCP 4.16.0, the default role bindings for image puller, image pusher, and deployer are created, even if the respective capabilities are disabled on the cluster.