Complete Features
These features were completed when this image was assembled
This outcome tracks the overall CoreOS Layering story as well as the technical items needed to converge CoreOS with RHEL image mode. This will provide operational consistency across the platforms.
ROADMAP for this Outcome: https://docs.google.com/document/d/1K5uwO1NWX_iS_la_fLAFJs_UtyERG32tdt-hLQM8Ow8/edit?usp=sharing
Note: phase 2 target is tech preview.
Feature Overview
In the initial delivery of CoreOS Layering, it is required that administrators provide their own build environment to customize RHCOS images. That could be a traditional RHEL environment or potentially an enterprising administrator with some knowledge of OCP Builds could set theirs up on-cluster.
The primary virtue of an on-cluster build path is to continue using the cluster to manage the cluster. No external dependency, batteries-included.
On-cluster, automated RHCOS Layering builds are important for multiple reasons:
- One-click/one-command upgrades of OCP are very popular. Many customers may want to make one or just a few customizations but also want to keep that simplified upgrade experience.
- Customers who only need to customize RHCOS temporarily (hotfix, driver test package, etc) will find off-cluster builds to be too much friction for one driver.
- One of OCP's virtues is that the platform and OS are developed, tested, and versioned together. Off-cluster building breaks that connection and leaves it up to the user to keep the OS up-to-date with the platform containers. We must make it easy for customers to add what they need and keep the OS image matched to the platform containers.
Goals & Requirements
- The goal of this feature is primarily to bring the 4.14 progress (
OCPSTRAT-35) to a Tech Preview or GA level of support. - Customers should be able to specify a Containerfile with their customizations and "forget it" as long as the automated builds succeed. If they fail, the admin should be alerted and pointed to the logs from the failed build.
- The admin should then be able to correct the build and resume the upgrade.
- Intersect with the Custom Boot Images such that a required custom software component can be present on every boot of every node throughout the installation process including the bootstrap node sequence (example: out-of-box storage driver needed for root disk).
- Users can return a pool to an unmodified image easily.
- RHEL entitlements should be wired in or at least simple to set up (once).
- Parity with current features – including the current drain/reboot suppression list, CoreOS Extensions, and config drift monitoring.
This work describes the tech preview state of On Cluster Builds. Major interfaces should be agreed upon at the end of this state.
Description of problem:
In clusters with OCB functionality enabled, sometimes the machine-os-builder pod is not restarted when we update the imageBuilderType. What we have observed is that the pod is restarted if a build is running, but it is not restarted if we are not building anything.
Version-Release number of selected component (if applicable):
$ oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.14.0-0.nightly-2023-09-12-195514 True False 88m Cluster version is 4.14.0-0.nightly-2023-09-12-195514
How reproducible:
Always
Steps to Reproduce:
1. Create the configuration resources needed by the OCB functionality.
To reproduce this issue we use an on-cluster-build-config configmap with an empty imageBuilderType
oc patch cm/on-cluster-build-config -n openshift-machine-config-operator -p '{"data":{"imageBuilderType": ""}}'
2. Create a infra pool and label it so that it can use OCB functionality
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfigPool
metadata:
name: infra
spec:
machineConfigSelector:
matchExpressions:
- {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]}
nodeSelector:
matchLabels:
node-role.kubernetes.io/infra: ""
oc label mcp/infra machineconfiguration.openshift.io/layering-enabled=
3. Wait for the build pod to finish.
4. Once the build has finished and it has been cleaned, update the imageBuilderType so that we use "custom-pod-builder" type now.
oc patch cm/on-cluster-build-config -n openshift-machine-config-operator -p '{"data":{"imageBuilderType": "custom-pod-builder"}}'
Actual results:
We waited for one hour, but the pod is never restarted. $ oc get pods |grep build machine-os-builder-6cfbd8d5d-xk6c5 1/1 Running 0 56m $ oc logs machine-os-builder-6cfbd8d5d-xk6c5 |grep Type I0914 08:40:23.910337 1 helpers.go:330] imageBuilderType empty, defaulting to "openshift-image-builder" $ oc get cm on-cluster-build-config -o yaml |grep Type imageBuilderType: custom-pod-builder
Expected results:
When we update the imageBuilderType value, the machine-os-builder pod should be restarted.
Additional info:
Test and verify: MCO-1042: ocb-api implementation in MCO
Areas of concern:
- nodeController
- daemon
- testing suite
Done when:
MCO-1042 PR can be verified and merged.
Description of problem:
MachineConfigs that use 3.4.0 ignition with a kernelArguments are not currently allowed by MCO. In on-cluster build pools, when we create a 3.4.0 MC with kernelArguments, the pool is not degraded. No new rendered MC is created either.
Version-Release number of selected component (if applicable):
4.14.0-0.nightly-2023-09-06-065940
How reproducible:
Always
Steps to Reproduce:
1. Enable on-cluster build in the "worker" pool
2. Create a MC using 3.4.0 ignition version with kernelArguments
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
creationTimestamp: "2023-09-07T12:52:11Z"
generation: 1
labels:
machineconfiguration.openshift.io/role: worker
name: mco-tc-66376-reject-ignition-kernel-arguments-worker
resourceVersion: "175290"
uid: 10b81a5f-04ee-4d7b-a995-89f319968110
spec:
config:
ignition:
version: 3.4.0
kernelArguments:
shouldExist:
- enforcing=0
Actual results:
The build process is triggered and new image is built and deployed. The pool is never degraded.
Expected results:
MCs with igition 3.4.0 kernelArguments are not currently allowed. The MCP should be degraded reporting a message similar to this one (this is the error reported if we deploy the MC in the master pool, which is a normal pool):
oc get mcp -o yaml
....
- lastTransitionTime: "2023-09-07T12:16:55Z"
message: 'Node sregidor-s10-7pdvl-master-1.c.openshift-qe.internal is reporting:
"can''t reconcile config rendered-master-57e85ed95604e3de944b0532c58c385e with
rendered-master-24b982c8b08ab32edc2e84e3148412a3: ignition kargs section contains
changes"'
reason: 1 nodes are reporting degraded status on sync
status: "True"
type: NodeDegraded
Additional info:
When the image is deployed (it shouldn't be deployed) the kernel argument enforcing=0 is not present: sh-5.1# cat /proc/cmdline BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-05f51fadbc7fe74fa1e2ba3c0dbd0268c6996f0582c05dc064f137e93aa68184/vmlinuz-5.14.0-284.30.1.el9_2.x86_64 ostree=/ostree/boot.0/rhcos/05f51fadbc7fe74fa1e2ba3c0dbd0268c6996f0582c05dc064f137e93aa68184/0 ignition.platform.id=gcp console=tty0 console=ttyS0,115200n8 root=UUID=95083f10-c02f-4d94-a5c9-204481ce3a91 rw rootflags=prjquota boot=UUID=0440a909-3e61-4f7c-9f8e-37fe59150665 systemd.unified_cgroup_hierarchy=1 cgroup_no_v1=all psi=1
Description of problem:
When opting into on-cluster builds on both the worker and control plane MachineConfigPools, the maxUnavailable value on the MachineConfigPools is not respected when the newly built image is rolled out to all of the nodes in a given pool.
Version-Release number of selected component (if applicable):
How reproducible:
Sometimes reproducible. I'm still working on figuring out what conditions need to be present for this to occur.
Steps to Reproduce:
1. Opt an OpenShift cluster in on-cluster builds by following these instructions: https://github.com/openshift/machine-config-operator/blob/master/docs/OnClusterBuildInstructions.md
2. Ensure that both the worker and control plane MachineConfigPools are opted in.
Actual results:
Multiple nodes in both the control plane and worker MachineConfigPools are drained and cordoned simultaneously, irrespective of the maxUnavailable value. This is particularly problematic for control plane nodes since draining more than one control plane node at a time can cause etcd issues, in addition to PDBs (Pod Disruption Budgets) which can make the config change take substantially longer or block completely. I've mostly seen this issue affect control plane nodes, but I've also seen it impact both control plane and worker nodes.
Expected results:
I would have expected the new OS image to be rolled out in a similar fashion as new MachineConfigs are rolled out. In other words, a single node (or nodes up to maxUnavailable for non-control-plane nodes) is cordoned, drained, updated, and uncordoned at a time.
Additional info:
I suspect the bug may be someplace within the NodeController since that's the part of the MCO that controls which nodes update at a given time. That said, I've had difficulty reliably reproducing this issue, so finding a root cause could be more involved. This also seems to be mostly confined to the initial opt-in process. Subsequent updates seem to follow the original "rules" more closely.
The current OCB approach is a private MCO only API. making a public API would introduce the following benefits:
1. Transparent update information linked with the proposed MachineOSUpdater API
2. Follow the MCO migration to openshift/api. We should not have private APIs anymore in the MCO. Especially if the feature is publicly used.
3. Consolidate build information into one place that both the MCO and other users can pull from
the general proposal of changes here are as follows:
1. Move global build settings to ControllerConfig object or to this object. These include `finalImagePushSecret` and `finalImagePullspec`
2. create MachineOSBuild CRD which will included Dockerfile field, MachineConfig to build from etc.
3. Add these fields to MCP as well. Rather than thinking of this as two sources of truth, you can view the MCP fields as triggers to create or modify an existing MachineOSBuild object. This is similar to the mechanism that OpenShift BuildV1 uses with its BuildConfigs and Builds CRDs; the BuildConfig houses all of the necessary configs and a new Build is created with those configs. One does not need a BuildConfig to do a build, but one can use a BuildConfig to launch multiple builds.
Making these changes will enforce a system for builds rather than the appendage that the build API is currently to the MCO. The aim here is visibility rather than hidden operations.
Description of problem:
In a cluster with a pool using OCB functionality, if we update the imageBuilderType value while an openshift-image-builder pod is building an image, the build fails. It can fail in 2 ways: 1. Removing the running pod that is building the image, and what we get is a failed build reporting "Error (BuildPodDeleted)" 2. The machine-os-builder pod is restarted but the build pod is not removed. Then the build is never removed.
Version-Release number of selected component (if applicable):
$ oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.14.0-0.nightly-2023-09-12-195514 True False 154m Cluster version is 4.14.0-0.nightly-2023-09-12-195514
How reproducible:
Steps to Reproduce:
1. Create the needed resources to make OCB functionality work (on-cluster-build-config configmap, the secrets and the imageSpec)
We reproduced it using imageBuilderType=""
oc patch cm/on-cluster-build-config -n openshift-machine-config-operator -p '{"data":{"imageBuilderType": ""}}'
2. Create an infra pool and label it so that it can use OCB functionality
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfigPool
metadata:
name: infra
spec:
machineConfigSelector:
matchExpressions:
- {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]}
nodeSelector:
matchLabels:
node-role.kubernetes.io/infra: ""
oc label mcp/infra machineconfiguration.openshift.io/layering-enabled=
3. Wait until the triggered build has finished.
4. Create a new MC to trigger a new build. This one, for example:
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: test-machine-config
spec:
config:
ignition:
version: 3.1.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,dGVzdA==
filesystem: root
mode: 420
path: /etc/test-file.test
5. Just after a new build pod is created, configure the on-cluster-build-config configmap to use the "custom-pod-builder" imageBuilderType
oc patch cm/on-cluster-build-config -n openshift-machine-config-operator -p '{"data":{"imageBuilderType": "custom-pod-builder"}}'
Actual results:
We have observed 2 behaviors after step 5: 1. The machine-os-builder pod is restarted and the build is never removed. build.build.openshift.io/build-rendered-infra-b2473d404d9ddfa1536d2fb32b54d855 Docker Dockerfile Running 10 seconds ago NAME READY STATUS RESTARTS AGE pod/build-rendered-infra-b2473d404d9ddfa1536d2fb32b54d855-build 1/1 Running 0 12s pod/machine-config-controller-5bdd7b66c5-dl4hh 2/2 Running 0 90m pod/machine-config-daemon-5wbw4 2/2 Running 0 90m pod/machine-config-daemon-fqr8x 2/2 Running 0 90m pod/machine-config-daemon-g77zd 2/2 Running 0 83m pod/machine-config-daemon-qzmvv 2/2 Running 0 83m pod/machine-config-daemon-w8mnz 2/2 Running 0 90m pod/machine-config-operator-7dd564556d-mqc5w 2/2 Running 0 92m pod/machine-config-server-28lnp 1/1 Running 0 89m pod/machine-config-server-5csjz 1/1 Running 0 89m pod/machine-config-server-fv4vk 1/1 Running 0 89m pod/machine-os-builder-6cfbd8d5d-2f7kd 0/1 Terminating 0 3m26s pod/machine-os-builder-6cfbd8d5d-h2ltd 0/1 ContainerCreating 0 1s NAME TYPE FROM STATUS STARTED DURATION build.build.openshift.io/build-rendered-infra-b2473d404d9ddfa1536d2fb32b54d855 Docker Dockerfile Running 12 seconds ago 2. The build pod is removed and the build fails with Error (BuildPodDeleted): NAME TYPE FROM STATUS STARTED DURATION build.build.openshift.io/build-rendered-infra-b2473d404d9ddfa1536d2fb32b54d855 Docker Dockerfile Running 10 seconds ago NAME READY STATUS RESTARTS AGE pod/build-rendered-infra-b2473d404d9ddfa1536d2fb32b54d855-build 1/1 Terminating 0 12s pod/machine-config-controller-5bdd7b66c5-dl4hh 2/2 Running 0 159m pod/machine-config-daemon-5wbw4 2/2 Running 0 159m pod/machine-config-daemon-fqr8x 2/2 Running 0 159m pod/machine-config-daemon-g77zd 2/2 Running 8 152m pod/machine-config-daemon-qzmvv 2/2 Running 16 152m pod/machine-config-daemon-w8mnz 2/2 Running 0 159m pod/machine-config-operator-7dd564556d-mqc5w 2/2 Running 0 161m pod/machine-config-server-28lnp 1/1 Running 0 159m pod/machine-config-server-5csjz 1/1 Running 0 159m pod/machine-config-server-fv4vk 1/1 Running 0 159m pod/machine-os-builder-6cfbd8d5d-g62b6 1/1 Running 0 2m11s NAME TYPE FROM STATUS STARTED DURATION build.build.openshift.io/build-rendered-infra-b2473d404d9ddfa1536d2fb32b54d855 Docker Dockerfile Running 12 seconds ago ..... NAME TYPE FROM STATUS STARTED DURATION build.build.openshift.io/build-rendered-infra-b2473d404d9ddfa1536d2fb32b54d855 Docker Dockerfile Error (BuildPodDeleted) 17 seconds ago 13s
Expected results:
Updating the imageBuilderType while a build is running should not result in the OCB functionlity in a broken status.
Additional info:
Must-gather files are provided in the first commen in this ticket.
There are a few situations in which a cluster admin might want to trigger a rebuild of their OS image in addition to situations where cluster state may dictate that we should perform a rebuild. For example, if the custom Dockerfile changes or the machine-config-osimageurl changes, it would be desirable to perform a rebuild in that case. To that end, this particular story covers adding the foundation for a rebuild mechanism in the form of an annotation that can be applied to the target MachineConfigPool. What is out of scope for this story is applying this annotation in response to a change in cluster state (e.g., custom Dockerfile change).
Done When:
- BuildController is aware of and recognizes a special annotation on layered MachineConfigPools (e.g., machineconfiguration.openshift.io/rebuildImage).
- Upon recognizing that a MachineConfigPool has this annotation, BuildController will clear any failed build attempts, delete any failed builds and their related ephemeral objects (e.g., rendered Dockerfile / MachineConfig ConfigMaps), and schedule a new build to be performed.
- This annotation should be removed when the build process completes, regardless of outcome. In other words, should the build success or fail, the annotation should be removed.
- [optional] BuildController keeps track of the number of retries for a given MachineConfigPool. This can occur via another annotation, e.g., machineconfiguration.openshift.io/buildRetries=1 . For now, this can be a hard-coded value (e.g., 5), but in the future, this could be wired up to an end-user facing knob. This annotation should be cleared upon a successful rebuild. If the rebuild is reached, then we should degrade.
Description of problem:
When a MCP has the on-cluster-build functionality enabled, when we configure a valid imageBuilderType in the on-cluster-build configmap, and later on we update this configmap with an invalid imageBuilderType the machine-config ClusterOperator is not degraded.
Version-Release number of selected component (if applicable):
$ oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.14.0-0.nightly-2023-09-12-195514 True False 3h56m Cluster version is 4.14.0-0.nightly-2023-09-12-195514
How reproducible:
Always
Steps to Reproduce:
1. Create a valid OCB configmap, and 2 valid secrets. Like this:
apiVersion: v1
data:
baseImagePullSecretName: mco-global-pull-secret
finalImagePullspec: quay.io/mcoqe/layering
finalImagePushSecretName: mco-test-push-secret
imageBuilderType: ""
kind: ConfigMap
metadata:
creationTimestamp: "2023-09-13T15:10:37Z"
name: on-cluster-build-config
namespace: openshift-machine-config-operator
resourceVersion: "131053"
uid: 1e0c66de-7a9a-4787-ab98-ce987a846f66
3. Label the "worker" MCP in order to enable the OCB functionality in it.
$ oc label mcp/worker machineconfiguration.openshift.io/layering-enabled=
4. Wait for the machine-os-builder pod to be created, and for the build to be finished. Just the wait for the pods, do not wait for the MCPs to be updated. As soon as the build pod has finished the build, go to step 5.
5. Patch the on-cluster-build configmap to use a valid imageBuilderType
oc patch cm/on-cluster-build-config -n openshift-machine-config-operator -p '{"data":{"imageBuilderType": "fake"}}'
Actual results:
The machine-os-builder pod crashes $ oc get pods NAME READY STATUS RESTARTS AGE machine-config-controller-5bdd7b66c5-6l7sz 2/2 Running 2 (45m ago) 63m machine-config-daemon-5ttqh 2/2 Running 0 63m machine-config-daemon-l95rj 2/2 Running 0 63m machine-config-daemon-swtc6 2/2 Running 2 57m machine-config-daemon-vq594 2/2 Running 2 57m machine-config-daemon-zrf4f 2/2 Running 0 63m machine-config-operator-7dd564556d-9smk4 2/2 Running 2 (45m ago) 65m machine-config-server-9sxjv 1/1 Running 0 62m machine-config-server-m5sdl 1/1 Running 0 62m machine-config-server-zb2hr 1/1 Running 0 62m machine-os-builder-6cfbd8d5d-t6g8w 0/1 CrashLoopBackOff 6 (3m11s ago) 9m16s But the machine-config ClusterOperator is not degraded $ oc get co machine-config NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE machine-config 4.14.0-0.nightly-2023-09-12-195514 True False False 63m
Expected results:
The machine-config ClusterOperator should become degraded when an invalid imageBuilderType is configured.
Additional info:
If we configure an invalid imageBuilderType directly (not by patching/editing the configmap), then the machine-config CO is degraded, but when we edit the configmap it is not. A link to the must-gather file is provided in the first comment in this issue PS: If we wait for the MCPs to be updated in step 4, the machine-os-builder pod is not restarted with the new "fake" imageBuilderType, but the machine-config CO is not degraded either, and it should. Does it make sense?
Only start the buildcontroller if the tech preview feature gate is enabled.
Proposed title of this feature request
Add support to OpenShift Telemetry to report the provider that has been added via "platform: external"
What is the nature and description of the request?
There is a new platform we have added support in OpenShift 4.14 called "external" which has been added for partners to enable and support their own integrations with OpenShift rather than making RH to develop and support this.
When deploying OpenShift using "platform: external: we don't have the ability right now to identify the provider where the platform has been deployed which is key for the product team to analyze demand and other metrics.
Why does the customer need this? (List the business requirements)
OpenShift Product Management needs this information to analyze adoption of these new platforms as well as other metrics specifically for these platforms to help us to make decisions for the product development.
List any affected packages or components.
Telemetry for OpenShift
There is some additional information in the following Slack thread --> https://redhat-internal.slack.com/archives/CEG5ZJQ1G/p1698758270895639
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision PowerVS infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The PowerVS IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing PowerVS Terraform provider. Specifically, we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for OpenStack deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision OpenStack infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The OpenStack Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing OpenStack Terraform provider. Specifically, we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Goal
- Create cluster and OpenStackCluster resource for the install-config.yaml
- Create OpenStackMachine
- Remove terraform dependency for OpenStack
Why is this important?
- To have a CAPO cluster functionally equivalent to the installer
Scenarios
\
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Rebase Installer onto the development branch of cluster-api-provider-openstack to provide CI signal to the CAPO maintainers.
Right now when trying one installation with this work https://github.com/openshift/installer/pull/7939 the bootstrap machine is not getting deleted. We need to ensure it's gone once bootstrap is finalized.
Essentially: bring the upstream-master branch of shiftstack/cluster-api-provider-openstack under the github.com/openshift organisation.
We need to get CI on this PR in good shape https://github.com/openshift/installer/pull/7939 so we can look for reviews
This is needed to identify if masters are schedulable and to upload the rhos image to glance.
- Update CAPO manifests in Installer to v1beta1
- Update the vendored operator to v0.10
Feature Overview (aka. Goal Summary)
Today we expose two main APIs for HyperShift, namely `HostedCluster` and `NodePool`. We also have metrics to gauge adoption by reporting the # of hosted clusters and nodepools.
But we are still missing other metrics to be able to make correct inference about what we see in the data.
Goals (aka. expected user outcomes)
- Provide Metrics to highlight # of Nodes per NodePool or # of Nodes per cluster
- Make sure the error between what appears in CMO via `install_type` and what we report as # Hosted Clusters is minimal.
Use Cases (Optional):
- Understand product adoption
- Gauge Health of deployments
- ...
Overview
Today we have hypershift_hostedcluster_nodepools as a metric exposed to provide information on the # of nodepools used per cluster.
Additional NodePools metrics such as hypershift_nodepools_size and hypershift_nodepools_available_replicas are available but not ingested in Telemetry.
In addition to knowing how many nodepools per hosted cluster, we would like to expose the knowledge of the nodepool size.
This will help inform our decision making and provide some insights on how the product is being adopted/used.
Goals
The main goal of this epic is to show the following NodePools metrics on Telemeter, ideally as recording rules:
- Hypershift_nodepools_size
- hypershift_nodepools_available_replicas
Requirements
The implementation involves creating updates to the following GitHub repositories:
similar PRs:
https://github.com/openshift/hypershift/pull/1544
https://github.com/openshift/cluster-monitoring-operator/pull/1710
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer - specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision GCP infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The GCP IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing GCP Terraform provider. Specifically, we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Provision GCP infrastructure without the use of Terraform
Why is this important?
- Removing Terraform from Installer
Scenarios
- The new provider should aim to provide the same results as the existing GCP
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
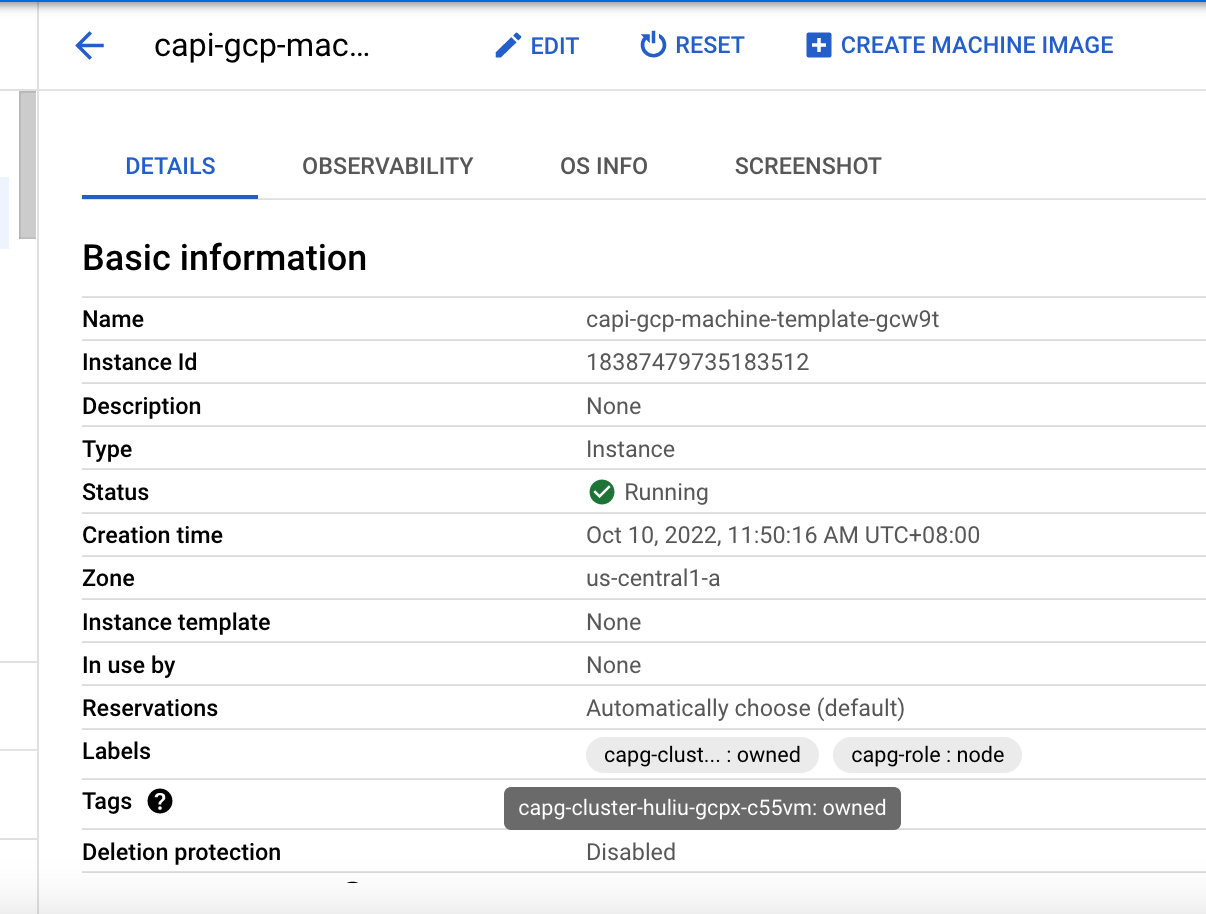
When testing GCP using the CAPG provider (not Terraform) in 4.16, it was found that the master VM instances were not distributed across instance groups but were all assigned to the same instance group.
Here is a (partial) CAPG install vs a installation completed using Terraform. The capg installation (bfournie-capg-test-5ql8j) has VMs all using us-east1-b
$ gcloud compute instances list | grep bfournie bfournie-capg-test-5ql8j-bootstrap us-east1-b n2-standard-4 10.0.0.4 34.75.212.239 RUNNING bfournie-capg-test-5ql8j-master-0 us-east1-b n2-standard-4 10.0.0.5 RUNNING bfournie-capg-test-5ql8j-master-1 us-east1-b n2-standard-4 10.0.0.6 RUNNING bfournie-capg-test-5ql8j-master-2 us-east1-b n2-standard-4 10.0.0.7 RUNNING bfournie-test-tf-pdrsw-master-0 us-east4-a n2-standard-4 10.0.0.4 RUNNING bfournie-test-tf-pdrsw-worker-a-vxjbk us-east4-a n2-standard-4 10.0.128.2 RUNNING bfournie-test-tf-pdrsw-master-1 us-east4-b n2-standard-4 10.0.0.3 RUNNING bfournie-test-tf-pdrsw-worker-b-ksxfg us-east4-b n2-standard-4 10.0.128.3 RUNNING bfournie-test-tf-pdrsw-master-2 us-east4-c n2-standard-4 10.0.0.5 RUNNING bfournie-test-tf-pdrsw-worker-c-jpzd5 us-east4-c n2-standard-4 10.0.128.4 RUNNING
User Story:
As a (user persona), I want to be able to:
- Ensure that when the cluster should use CAPI installs that the correct path is chosen. AKA: no longer use terraform for installations in GCP when the user has selected the featureSet for CAPI.
so that I can achieve
- CAPI gcp installation
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
When using the CAPG provider the ServiceAccounts created by the installer for the master and worker nodes do not have the role bindings added correctly.
For example this query shows that the SA for the master nodes has no role bindings.
$ gcloud projects get-iam-policy openshift-dev-installer --flatten="bindings[].members" --format='table(bindings.role)' --filter='bindings.members:bfournie-capg-test-lk5t5-m@openshift-dev-installer.iam.gserviceaccount.com' $
User Story:
I want to destroy the load balancers created by capg
Acceptance Criteria:
Description of criteria:
- destroy deletes all capg related resources
- backwards compatible: continues to destroy terraform clusters
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- CAPG creates: global proxy load balancers
- our destroy code only looks for regional passthrough load balancers
- need to:
- update destroy code to not look at regional load balancers (only)
- destroy tcp proxy resource, which is not created in passthrough load balancers, so is not currently deleted
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
CAPG has been updated to 1.6, see https://github.com/kubernetes-sigs/cluster-api-provider-gcp/releases/tag/v1.6.0
We need to pick this up to get the latest features including disk encryption.
Machines for GCP need to be generated for use in CAPI. This will be similar to the AWS machine implementation
(https://github.com/openshift/installer/blob/master/pkg/asset/machines/aws/awsmachines.go) added in
https://github.com/openshift/installer/pull/7771
User Story:
I want to create the public and private DNS records using one of the CAPI interface SDK hooks.
Acceptance Criteria:
Description of criteria:
- Vanilla install: create public DNS record, private zone, private record
- Shared VPC: check for existing private DNS zone
- Publish Internal: create private zone, private record
- Custom DNS scenario: create no records, or zone
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- Value for DNS record for capi-provisioned LB, can be grabbed from cluster manifest
- The value for the SDK provisioned LB will need to be handled within our hook
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
As an installer user, I want my gcp creds used for install to be used by the CAPG controller when provisioning resources.
Acceptance Criteria:
- Users can authenticate using the service account from ~/.gcp/osServiceAccount.json
- users can authenticate with default application credentials
- Docs team is updated to whether existing credential methods will continue to work (specifically environment variables): see official docs
Engineering Details:
- We can pass in a secret containing the service account creds, so we can do t hat during the manifest stage, which is probably a more appropriate place
- The controller supports auth'ing with default application credentials when there is no secret supplied, so that's good. That should work for use cases where they don't want service account
- GCP controller authentication is handled here: https://github.com/kubernetes-sigs/cluster-api-provider-gcp/blob/main/cloud/scope/managedcontrolplane.go#L67
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
When installing on GCP, I want control-plane (including bootstrap) machines to bootstrap using ignition.
I want bootstrap ignition to be secured so that sensitive data is not publicly available.
Acceptance Criteria:
Description of criteria:
- Control-plane machines pull ignition (boot successfully)
- Bootstrap ignition is not public (typically signed url)
- Service account is not required for signed url (stretch goal)
- Should be labeled (with owned and user tags)
(optional) Out of Scope:
Destroying bootstrap ignition can be handled separately.
Engineering Details:
- CAPG does not support ignition, so we will need to determine what to pass in Bootstrap to allow passing ignition stub in the user data.
- terraform: https://github.com/openshift/installer/blob/master/data/data/gcp/cluster/master/main.tf#L85
- create storage bucket
- upload bootstrap ignition to object in storage bucket
- create signed url for object
- pass signed url in ignition stub
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
https://issues.redhat.com/browse/CORS-3217 covers the upstream chagnes to CAPG needed to add disk encrytion. In addition changes will be needed in the installer to set the GCPMachine disk encryption based on the machinepool settings.
Notes on the required changes are at https://docs.google.com/document/d/1kVgqeCcPOrq4wI5YgcTZKuGJo628dchjqCrIrVDS83w/edit?usp=sharing
Once the upstream changes from CORS-3217 have been accepted:
- plumb through existing encryption key fields
- vendor updated CAPG
- update infrastructure-components.yaml (CRD definitions) if necessary
User Story:
I want to create a load balancer to provide split-horizon DNS for the cluster.
Acceptance Criteria:
Description of criteria:
- In a vanilla install, we have both ext and int load balancers
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Description of problem:
The bootstrap machine never contains a public IP address. When the publish strategy is set to External, the bootstrap machine should contain a public ip address.
Version-Release number of selected component (if applicable):
How reproducible:
always
Steps to Reproduce:
1.
2.
3.
Actual results:
Expected results:
Additional info:
Create the GCP Infrastructure controller in /pkg/clusterapi/system.go.
It will be based on the AWS controller in that file, which was added in https://github.com/openshift/installer/pull/7630.
User Story:
I want the installer to create the service accounts that would be assigned to control plane and compute machines, similar to what is done in terraform now.
Acceptance Criteria:
Description of criteria:
- Control plane and compute service accounts are created with appropriate permissions (see details)
- Service accounts are attached to machines
- Skip creation of control-plane service accounts when they are specified in the install config
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- Service accounts are needed by the machines, so they could be created in either PreProvision or InfraReady
- compute node service account permissions are captured here: https://github.com/openshift/installer/blob/master/data/data/gcp/cluster/iam/main.tf
- control plane iam is here:
https://github.com/openshift/installer/blob/master/data/data/gcp/cluster/master/main.tf#L5-L38 - The service accounts should be specified in the machine spec.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
When a GCP cluster is created using CAPI, upon destroy the addresses associated with the apiserver LoadBalancer are not removed. For example here are addresses left over after previous installations
$ gcloud compute addresses list --uri | grep bfournie https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-27kzq-apiserver https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-6jrwz-apiserver https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-gn6g7-apiserver https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-h96j2-apiserver https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-k7fdj-apiserver https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-nh4z5-apiserver https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-nls2h-apiserver https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-qrhmr-apiserver
Here is one of the addresses:
$ gcloud compute addresses describe https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-27kzq-apiserver address: 34.107.255.76 addressType: EXTERNAL creationTimestamp: '2024-04-15T15:17:56.626-07:00' description: '' id: '2697572183218067835' ipVersion: IPV4 kind: compute#address labelFingerprint: 42WmSpB8rSM= name: bfournie-capg-test-27kzq-apiserver networkTier: PREMIUM selfLink: https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-27kzq-apiserver status: RESERVED [bfournie@bfournie installer-patrick-new]$ gcloud compute addresses describe https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-6jrwz-apiserver address: 34.149.208.133 addressType: EXTERNAL creationTimestamp: '2024-03-27T09:35:00.607-07:00' description: '' id: '1650865645042660443' ipVersion: IPV4 kind: compute#address labelFingerprint: 42WmSpB8rSM= name: bfournie-capg-test-6jrwz-apiserver networkTier: PREMIUM selfLink: https://www.googleapis.com/compute/v1/projects/openshift-dev-installer/global/addresses/bfournie-capg-test-6jrwz-apiserver status: RESERVED
Now that https://issues.redhat.com/browse/CORS-3447 providing the ability to override the APIServer instance group to be compatible with MAPI, we need to set the override in the installer when the Internal LoadBalancer is created.
User Story:
As a (user persona), I want to be able to:
- Create the GCP cluster manifest for CAPI installs
so that I can achieve
- The manifests in <assets-dir>/cluster-api will be applied to bootstrap ignition and the files will find their way to the machines.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
once e2e tests are passing, include gcp capi installer in tech preview feature set.
similar to https://github.com/openshift/api/pull/1880
When GCP workers are created they are not able to pull ignition over the internal subnet as its not allowed by the firewall rules created by CAPG. The allow-<infraID>-cluster allows all TCP traffic with tags for <infraID>-node and <infraID>-control-plane but the workers that are created have tags <infraID>-worker.
We need to either add the worker tags to this firewall rule or add node tags to the worker. We should decide on a general use of CAPG firewall rules.
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision AWS infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The AWS IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing AWS Terraform provider. Specifically, we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
- Provision AWS infrastructure without the use of Terraform
Why is this important?
- This is a key piece in producing a terraform-free binary for ROSA. See parent epic for more details.
Scenarios
- The new provider should aim to provide the same results as the existing AWS terraform provider.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Use cases to ensure:
- When installconfig.controlPlane.platform.aws.zones is specified, control plane nodes are correctly placed in the zones.
- When installconfig.controlPlane.platform.aws.zones isn't specified, the control plane nodes are correctly balanced in the zones available in the region, preventing single-zone when possible.
User Story:
As a (user persona), I want to be able to:
- Deploy AWS cluster with IPI with minimum customizations without terraform
Acceptance Criteria:
Description of criteria:
- Install complete, e2e pass
- Production-ready
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- PoC implementation here: https://github.com/openshift/installer/pull/7879
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
iam role is correctly attached to control plane node when installconfig.controlPlane.platform.aws.iamRole is specified
User Story:
As a (user persona), I want to be able to:
- make sure ignition respects proxy configuration
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
when installconfig.controlPlane.platform.aws.metadataService is set, the metadataservice is correctly configured for control plane machines
security group ids are added to control plane nodes when installconfig.controlPlane.platform.aws.additionalSecurityGroupIDs is specified
User Story:
As a (user persona), I want to be able to:
- implement custom endpoint support if it's still needed.
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
CAPA shows
I0312 18:00:13.602972 109 s3.go:220] "Deleting S3 object" controller="awsmachine" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="AWSMachine" AWSMachine="openshift-cluster-api-guests/rdossant-installer-03-jjf6b-master-2" namespace="openshift-cluster-api-guests" name="rdossant-installer-03-jjf6b-master-2" reconcileID="9cda22be-5acd-4670-840f-8a6708437385" machine="openshift-cluster-api-guests/rdossant-installer-03-jjf6b-master-2" cluster="openshift-cluster-api-guests/rdossant-installer-03-jjf6b" bucket="openshift-bootstrap-data-rdossant-installer-03-jjf6b" key="control-plane/rdossant-installer-03-jjf6b-master-2" I0312 18:00:13.608919 109 s3.go:220] "Deleting S3 object" controller="awsmachine" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="AWSMachine" AWSMachine="openshift-cluster-api-guests/rdossant-installer-03-jjf6b-master-0" namespace="openshift-cluster-api-guests" name="rdossant-installer-03-jjf6b-master-0" reconcileID="1ed0ad52-ffc1-4b62-97e4-876f8e8c3242" machine="openshift-cluster-api-guests/rdossant-installer-03-jjf6b-master-0" cluster="openshift-cluster-api-guests/rdossant-installer-03-jjf6b" bucket="openshift-bootstrap-data-rdossant-installer-03-jjf6b" key="control-plane/rdossant-installer-03-jjf6b-master-0" [...] E0312 18:04:25.282967 109 awsmachine_controller.go:576] "controllers/AWSMachine: unable to delete secrets" err=< deleting bootstrap data object: deleting S3 object: NotFound: Not Found status code: 404, request id: 9QYY3QSWKBBDZ7R8, host id: 2f3HawFbPheaptP9E+WRbu3fhEXTMwyZQ1DBPGBG7qlg74ssQR0XISM4OSlxvrn59GeFREtN4hp9C+S5LgQD2g== > E0312 18:04:25.284197 109 controller.go:329] "Reconciler error" err=< deleting bootstrap data object: deleting S3 object: NotFound: Not Found status code: 404, request id: 9QYY3QSWKBBDZ7R8, host id: 2f3HawFbPheaptP9E+WRbu3fhEXTMwyZQ1DBPGBG7qlg74ssQR0XISM4OSlxvrn59GeFREtN4hp9C+S5LgQD2g== > controller="awsmachine" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="AWSMachine" AWSMachine="openshift-cluster-api-guests/rdossant-installer-03-jjf6b-master-0" namespace="openshift-cluster-api-guests" name="rdossant-installer-03-jjf6b-master-0" reconcileID="7fac94a1-772a-4c7b-a631-5ef7fc015d5b" E0312 18:04:25.286152 109 awsmachine_controller.go:576] "controllers/AWSMachine: unable to delete secrets" err=< deleting bootstrap data object: deleting S3 object: NotFound: Not Found status code: 404, request id: 9QYPFY0EQBM42VYH, host id: nJZakAhLrbZ1xrSNX3tyk0IKmMgFjsjMSs/D9nzci90GfRNNfUnvwZTbcaUBQYiuSlY5+aysCuwejWpvi8FmGusbQCK1Qtjr9pjqDQfxzY4= > E0312 18:04:25.287353 109 controller.go:329] "Reconciler error" err=< deleting bootstrap data object: deleting S3 object: NotFound: Not Found status code: 404, request id: 9QYPFY0EQBM42VYH, host id: nJZakAhLrbZ1xrSNX3tyk0IKmMgFjsjMSs/D9nzci90GfRNNfUnvwZTbcaUBQYiuSlY5+aysCuwejWpvi8FmGusbQCK1Qtjr9pjqDQfxzY4= > controller="awsmachine" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="AWSMachine" AWSMachine="openshift-cluster-api-guests/rdossant-installer-03-jjf6b-master-2" namespace="openshift-cluster-api-guests" name="rdossant-installer-03-jjf6b-master-2" reconcileID="b6c792ad-5519-48d5-a994-18dda76d8a93" E0312 18:04:25.291383 109 awsmachine_controller.go:576] "controllers/AWSMachine: unable to delete secrets" err=< deleting bootstrap data object: deleting S3 object: NotFound: Not Found status code: 404, request id: 9QYGWSJDR35Q4GWX, host id: Qnltg++ia3VapXjtENZOQIwfAxbxfwVLPlC0DwcRBx+L60h52ENiNqMOkvuNwJyYnPxbo/CaawzMT11oIKGO9g== > E0312 18:04:25.292132 109 controller.go:329] "Reconciler error" err=< deleting bootstrap data object: deleting S3 object: NotFound: Not Found status code: 404, request id: 9QYGWSJDR35Q4GWX, host id: Qnltg++ia3VapXjtENZOQIwfAxbxfwVLPlC0DwcRBx+L60h52ENiNqMOkvuNwJyYnPxbo/CaawzMT11oIKGO9g== > controller="awsmachine" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="AWSMachine" AWSMachine="openshift-cluster-api-guests/rdossant-installer-03-jjf6b-master-1" namespace="openshift-cluster-api-guests" name="rdossant-installer-03-jjf6b-master-1" reconcileID="92e1f8ed-b31f-4f75-9083-59aad15efe79" E0312 18:04:25.679859 109 awsmachine_controller.go:576] "controllers/AWSMachine: unable to delete secrets" err=< deleting bootstrap data object: deleting S3 object: NotFound: Not Found status code: 404, request id: 9QYSBZGYPC7SNJEX, host id: EplmtNQ+RxmbU88z+4App6YEVvniJpyCeMiMZuUegJIMqZgbkA1lmCjHntSLDm4eA857OdhtHsn+zD6AX7uelGIsogzN2ZziiAZXZrbIIEg= > E0312 18:04:25.680663 109 controller.go:329] "Reconciler error" err=< deleting bootstrap data object: deleting S3 object: NotFound: Not Found status code: 404, request id: 9QYSBZGYPC7SNJEX, host id: EplmtNQ+RxmbU88z+4App6YEVvniJpyCeMiMZuUegJIMqZgbkA1lmCjHntSLDm4eA857OdhtHsn+zD6AX7uelGIsogzN2ZziiAZXZrbIIEg= > controller="awsmachine" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="AWSMachine" AWSMachine="openshift-cluster-api-guests/rdossant-installer-03-jjf6b-master-0" namespace="openshift-cluster-api-guests" name="rdossant-installer-03-jjf6b-master-0" reconcileID="9e436c67-aca0-409c-9179-0ce4cccce9ad"
Even though we are not creating s3 buckets for the master nodes. That's preventing the bootstrap process from finishing.
Because of the assumption that subnets have auto-assign public IPs turned on, which is how CAPA configures the subnets it creates, supplying your own VPC where that is not the case causes the bootstrap node to not get a public IP and therefore not be able to download the release image (no internet connection).
The bootstrap node needs a public IP because the public subnets are connected only to the internet gateway, which does not provide NAT.
User Story:
Destroy all bootstrap resources created through the new non-terraform provider.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Issue:
- Kubernetes API on OpenShift requires advanced health check configuration ensure graceful termiantion[1] works correctly. The health check protocol must be HTTPS testing the path /readyz.
- Currently CAPA support standard configuration (health check probe timers) and for path, when using HTTP or HTTPS is selected.
- MCS listener/target must use HTTPS health check with custom probe periods too.
Steps to reproduce:
- Create CAPA cluster
- Check the Target Groups created to route traffic to API (6443), for both Load Balancers (int and ext)
Actual results:
- TCP health check w/ default probe config
Expected results:
- HTTPS health check evaluating /readyz path
- Check parameters: 2 checks in the interval of 10s, using 10s of timeout
References:
- [1] API graceful termination: https://github.com/openshift/installer/blob/master/docs/dev/kube-apiserver-health-check.md
- documentation: https://docs.openshift.com/container-platform/4.15/installing/installing_platform_agnostic/installing-platform-agnostic.html#installation-load-balancing-user-infra_installing-platform-agnostic
- Current terraform setup: https://github.com/openshift/installer/blob/master/data/data/aws/cluster/vpc/master-elb.tf#L86-L94
Goal:
- As OCP developer I would like to deploy OpenShift using the installer/CAPA to provision the infrastructure setting the health check parameters to satisfy the existing terraform implementation
Issue:
- The API listeners is created exposing different health check attributes than the terraform implementation. There is a bug to fix to the correct path when using health check protocol HTTP or HTTPS (
CORS-3289) - The MCS listener, created using the AdditionalListeners option from the *LoadBalancer, requires advanced health check configuration to satisfy terraform implementation. Currently CAPA sets the health check with standard TCP or default path ("/") when using HTTP or HTTPS protocol.
Steps to reproduce:
- Create CAPA cluster
- Check the Target Groups created to route traffic to MCS (22623), for internal Load Balancers
Actual results:
- TCP or HTTP/S health check w/ default probe config
Expected results:
- API listeners with target health check using HTTPS evaluating /healthz path
- MCS listener with target health check using HTTPS evaluating /healthz path
- Check parameters: 2 checks in the interval of 10s, using 10s of timeout
References:
- [1] API graceful termination: https://github.com/openshift/installer/blob/master/docs/dev/kube-apiserver-health-check.md
- documentation: https://docs.openshift.com/container-platform/4.15/installing/installing_platform_agnostic/installing-platform-agnostic.html#installation-load-balancing-user-infra_installing-platform-agnostic
- Current terraform setup: https://github.com/openshift/installer/blob/master/data/data/aws/cluster/vpc/master-elb.tf#L86-L94
CAPA creates 4 security groups:
$ aws ec2 describe-security-groups --region us-east-2 --filters "Name = group-name, Values = *rdossant*" --query "SecurityGroups[*].[GroupName]" --output text rdossant-installer-03-tvcbd-lb rdossant-installer-03-tvcbd-controlplane rdossant-installer-03-tvcbd-apiserver-lb rdossant-installer-03-tvcbd-node
Given that the maximum number of SGs in a network interface is 16, we should update the max number validation in the installer:
https://github.com/openshift/installer/blob/master/pkg/types/aws/validation/machinepool.go#L66
Patrick says:
I think we want to update this to cap the user limit to 10 additional security groups:
More context: https://redhat-internal.slack.com/archives/C68TNFWA2/p1697764210634529?thread_ts=1697471429.293929&cid=C68TNFWA2
when installconfig.platform.aws.userTags is specified, all taggable resources should have the specified user tags.
- Manifests:
- cluster
- machines
- Non-capi provisioned resources:
- IAM roles
- Load balancer resources
- DNS resources (private zone is tagged)
- Check compatibility of how CAPA provider is tagging bootstrap S3 bucket
When using Wavelength zones, networks are cidr'd differently than in vanilla installs. Ensure wavelength support
Private hosted zone and cross-account shared vpc works when installconfig.platform.aws.hostedZone is specified
AWS Local zone support works as expected when local zones are specified
The schema check[1] in the LB reconciliation is hardcoded to check the primary Load Balancer only, it will result to always filter the subnets from the schema for the primary, ignoring additional Load Balancers ("SecondaryControlPlaneLoadBalancer")
How to reproduce:
- Create a cluster w/ secondaryLoadBalancer w/ internet-facing
- Check the subnets for the secondary load balancers: "ext" (public) API Load Balancer's subnets
Actual results:
- Private subnets attached to the SecondaryControlPlaneLoadBalancer
Expected results:
- Public subnets attached to the SecondaryControlPlaneLoadBalancer
References:
bootstrap ignition is not deleted when installconfig.platform.aws.preserveBootstrapIgnition is specified
As an Openshift admin i want to leverage /dev/fuse in unprivileged containers so that to successfully integrate cloud storage into OpenShift application in a secure, efficient, and scalable manner. This approach simplifies application architecture and allows developers to interact with cloud storage as if it were a local filesystem, all while maintaining strong security practices.
Epic Goal
- Give users the ability to mount /dev/fuse into a pod by default with the `io.kubernetes.cri-o.Devices` annotation
Why is this important?
- It's the first step in a series of steps that allows users to run unprivileged containers within containers
- It also gives access to faster builds within containers
Scenarios
- as a developer on openshift, I would like to run builds within containers in a performant way
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- Through this epic, we will update our CI to use a UPI workflow instead of the libvirt openshift-installer, allowing us to eliminate the use of terraform in our deployments.
Why is this important?
- There is an active initiative in openshift to remove terraform from the openshift installer.
Acceptance Criteria
- All tasks within the epic are completed.
Done Checklist
- CI - For new features (non-enablement), existing Multi-Arch CI jobs are not broken by the Epic
- All the stories, tasks, sub-tasks and bugs that belong to this epic need to have been completed and indicated by a status of 'Done'.
As a multiarch CI-focused engineer, I want to create a workflow in `openshift/release` that will enable creating the backend nodes for a cluster installation.
Customer has escalated the following issues where ports don't have TLS support. This Feature request lists all the components port raised by the customer.
Details here https://docs.google.com/document/d/1zB9vUGB83xlQnoM-ToLUEBtEGszQrC7u-hmhCnrhuXM/edit
Currently, we are serving the metrics as http on 9537 we need to upgrade to use TLS
Related to https://docs.google.com/document/d/1zB9vUGB83xlQnoM-ToLUEBtEGszQrC7u-hmhCnrhuXM/edit
Feature Overview (aka. Goal Summary)
Reduce the resource footprint of LVMS in regards to CPU, Memory, Image count and size by collapsing current various containers and deployments into a small number of highly integrated ones.
Goals (aka. expected user outcomes)
- Reduce the resource footprint while keeping the same functionallity
- Provide seemless migration for existing customers{}
Requirements (aka. Acceptance Criteria):
- Ressource Reduction:
- Reduce memory consumption
- Reduce CPU consumption (stressed, idle, requested)
- Reduce container count (to reduce APi/scheduler/crio load)
- Reduce container image sizes (to speed up deployments)
- new version must be functionally equivalent no current feature/function is dropped,
- day1 operations (installation, configuration) must be the same
- day2 operations (updates, config changes, monitoring) must be the same
- seamless migration for existing customers
- special care must be taken with MicroShift, as it uses LVMS in a special way.
Questions to Answer (Optional):
- Do we need some sort of DP/TP release, make it an opt in feature for customers to try?
Out of Scope
tbd
Background
The idea was creating during a ShiftWeek project. Potential saving / reductions are documented here: https://docs.google.com/presentation/d/1j646hJDVNefFfy1Z7glYx5sNBnSZymDjCbUQVOZJ8CE/edit#slide=id.gdbe984d017_0_0
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Resource Requirements should be added/updated to the documentation in the requirements section.
Interoperability Considerations
Interoperability with MicroShift is a challenge, as it allows way more detailed configuration of topolvm with direct access to lvmd.conf
Feature Overview (aka. Goal Summary)
Enable developers to perform actions in a faster and better way than before.
Goals (aka. expected user outcomes)
Developers will be able to reduce the time or clicks spent on the UI to perform specific set of actions.
Requirements (aka. Acceptance Criteria):
Search->Resources option should show 5 of the recently searched resources across all sessions by the user.
The recently searched resources should should be clearly visible and separated from rest.
Pinning resources capability should be removed.
Getting Started menu on Add page can be collapsed and expanded
Use Cases (Optional):
Questions to Answer (Optional):
Out of Scope
Background
Customer Considerations
Documentation Considerations
Interoperability Considerations
__
Problem:
Developers have to repeatedly search for resources and pin them separately in order to view details of a resource that have seen in the past.
Goal:
Provide developers with the ability to see the last 5 resources that they have seen in the past so they can quickly view their details without any further actions.
Why is it important?
Provides a better user experience for developers when using the console.
Use cases:
- <case>
Acceptance criteria:
- Same as listed in
OCPSTRAT-1024
Dependencies (External/Internal):
Design Artifacts:
Exploration:
Note:
Description
As a user, I want the console to remember the resources I have recently searched so that I don't have to type the names of the same resources I use frequently in the Search Page.
Acceptance Criteria
- Modify the Search dropdown to add a new section to display the recently searched items in the order they were searched.
Additional Details:
Problem:
The Getting Started menu on Add page can cannot be restored after users click on the "X" symbol when its hidden.
Goal:
Users should be able to collapse and expand the Getting Started menu on Add Page.
Why is it important?
The current behavior causes confusion.
Use cases:
- <case>
Acceptance criteria:
- The Getting Started menu on Add page can be collapsed by clicking on the screen.
- The collapsed Getting Started page can be expanded by clicking on the screen.
- When collapsed, it is visibly available for someone to expand again.
Dependencies (External/Internal):
Design Artifacts:
Exploration:
Note:
Description
As of now, getting started section can be hidden and enable back using the button but user can close that button and it will not show back. It is confusing for the users. So add the expandable section instead of hide and show button similar to Functions List page
Acceptance Criteria
- Update getting Started section to use expandable section in Add page
- Update getting Started section to use expandable section in Cluster tab in overview page in Admin perspective
- Updated the test cases
Additional Details:
Check Functions list page in Dev perspective for the design
Phase 2 Deliverable:
GA support for a generic interface for administrators to define custom reboot/drain suppression rules.
Epic Goal
- Allow administrators to define which machineconfigs won't cause a drain and/or reboot.
- Allow administrators to define which ImageContentSourcePolicy/ImageTagMirrorSet/ImageDigestMirrorSet won't cause a drain and/or reboot
- Allow administrators to define alternate actions (typically restarting a system daemon) to take instead.
- Possibly (pending discussion) add switch that allows the administrator to choose to kexec "restart" instead of a full hw reset via reboot.
Why is this important?
- There is a demonstrated need from customer cluster administrators to push configuration settings and restart system services without restarting each node in the cluster.
- Customers are modifying ICSP/ITMS/IDMS outside post day 1/adding them+
- (kexec - we are not committed on this point yet) Server class hardware with various add-in cards can take 10 minutes or longer in BIOS/POST. Skipping this step would dramatically speed-up bare metal rollouts to the point that upgrades would proceed about as fast as cloud deployments. The downside is potential problems with hardware and driver support, in-flight DMA operations, and other unexpected behavior. OEMs and ODMs may or may not support their customers with this path.
Scenarios
- As a cluster admin, I want to reconfigure sudo without disrupting workloads.
- As a cluster admin, I want to update or reconfigure sshd and reload the service without disrupting workloads.
- As a cluster admin, I want to remove mirroring rules from an ICSP, ITMS, IDMS object without disrupting workloads because the scenario in which this might lead to non-pullable images at a undefined later point in time doesn't apply to me.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Follow up epic to https://issues.redhat.com/browse/MCO-507, aiming to graduate the feature from tech preview and GA'ing the functionality.
This status was added as a legacy field and isn't currently used for anything, nor should it be there. We'd like to remove this, so:
- we get rid of unused fields
- we can use the proper api conditions types for status's
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision OpenShift on the existing supported providers' infrastructure without the use of Terraform.
This feature will be used to track all the CAPI preparation work that is common for all the supported providers
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
- Day 0 Cluster Provisioning
- Compatibility with existing workflows that do not require a container runtime on the host
Why is this important?
- This epic would maintain compatibility with existing customer workflows that do not have access to a management cluster and do not have the dependency of a container runtime
Scenarios
- openshift-install running in customer automation
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
PoC & design for running CAPI control plane using binaries.
User Story:
As a CAPI install user, I want to be able to:
- gather bootstrap logs
-
- automatically after bootstrap failure during install
- when running `gather bootstrap` command
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Define CAPI provider interface for grabbing IP addresses
- Handle loading manifests from disk
- Confirm that IP addresses are specified in manifests
- Point 3
(optional) Out of Scope:
This is intended to be platform agnostic. If there is a common way for obtaining ip addresses from capi manifests, this should be sufficient. Otherwise, this should enable other platforms to implement their specific logic.
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
I want hack/build.sh to embed the kube-apiserver and etcd dependencies in openshift-install without making external network calls so that ART/OSBS can build the installer with CAPI dependencies.
Acceptance Criteria:
Description of criteria:
- dependencies are not obtained over the internet
- gated by OPENSHIFT_INSTALL_CLUSTER_API env var
- should work when building for various architectures
(optional) Out of Scope:
Engineering Details:
- Currently the dependencies are obtained through the sync_envtest function in build-cluster-api.sh
- Cluster API provider dependencies are vendored and built here
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Extract the needed binaries during the Installer container image build and copy them to an appropriate location so they can be used by CAPI.
We need build configs for the binaries so they are built as dependencies of the Installer images in the release pipeline.
Write CAPI manifests to disk during create manifests so that they can be user edited and users can also provide their own set of manifests. In general, we think of manifests as an escape hatch that should be used when a feature is missing from the install config, and users accept the degraded user experience of editing manifests in order to achieve non-install-config-supported functionality.
Acceptance criteria:
Manifests should be generated correctly (and applied correctly to the control plane):
- when create manifests is run before create cluster
- only when create cluster is run
There is some WIP for this, but there are issues with the serialization/deserialization flow when writing the GVK in the manifests.
all capi artifacts should be collected in a hidden dir
they should always be written (regardless of success or fail)
they should be collected in the installer log bundle
Right now the CAPI providers will run indefinitely. We need to stop the installer if installs fail, based on either a timeout or more sophisticated analysis.
We cannot execute cross-compiled binaries, otherwise we get an error saying:
hack/build-cluster-api.sh: line 26: /go/src/github.com/openshift/installer/cluster-api/bin/darwin_amd64/kube-apiserver: cannot execute binary file: Exec format error
The check should be skipped in those cases.
Fit provisioning via the CAPI system into the infrastructure.Provider interface
so that:
- code path to selecting an infrastructure provider is simplified
- enabling/disabling infrastructure providers via feature gates is centralized in platform package
We want CAPI providers to be built and embedded in the installer binary when ART builds the installer with OSBS.
Currently CAPI providers are only built when the OPENSHIFT_INSTALL_CLUSTER_API env var is set for hack/build.sh. One way of resolving this would be to always build the providers, but gate the kas/etcd dependencies on the environment variable. Some prior art for that here: https://github.com/openshift/installer/pull/8273
The main issue with enabling CAPI provider builds will be the effect on build time, which is already long-running and somewhat unstable.
The 100.88.0.0/14 IPv4 subnet is currently reserved for the transit switch in OVN-Kubernetes for east west traffic in the OVN Interconnect architecture. We need to make this value configurable so that users can avoid conflicts with their local infrastructure. We need to support this config both prior to installation and post installation (day 2).
This epic will include stories for the upstream ovn-org work, getting that work downstream, an api change, and a cno change to consume the new api
Scope of this card is to track the work around getting the required pieces in for transit switch subnet in CNO that will let users do custom configurations to transit switch subnet on both day0 (install) and day2 (post-install).
This card will complement https://issues.redhat.com/browse/SDN-4156
You can create the cluster-bot cluster with Ben's PR and do CNO changes locally and test them out.
After the upstream pr merges it needs to get into openshift ovn-k via a downstream merge
Feature Overview
Allow setting custom tags to machines created during the installation of an OpenShift cluster on vSphere.
Why is this important
Just as labeling is important in Kubernetes for organizing API objects and compute workloads (pods/containers), the same is true for the Kube/OCP node VMs running on the underlying infrastructure in any hosted or cloud platform.
Reporting, auditing, troubleshooting and internal organization processes all require ways of easily filtering on and referencing servers by naming, labels or tags. Ensuring appropriate tagging is added to all OCP nodes in VMware ensures those troubleshooting, reporting or auditing can easily identify and filter Openshift node VMs.
For example we can use tags for prod vs. non-prod, VMs that should have backup snapshots vs. those that shouldn't, VMs that fall under certain regulatory constraints, etc.
Epic Goal
- Customers need to assign additional tags to machines that are reconciled via the machine API.
Why is this important?
- Just as labeling is important in Kubernetes for organizing API objects and compute workloads (pods/containers), the same is true for the Kube/OCP node VMs running on the underlying infrastructure in any hosted or cloud platform.
Reporting, auditing, troubleshooting and internal organization processes all require ways of easily filtering on and referencing servers by naming, labels or tags. Ensuring appropriate tagging is added to all OCP nodes in VMware ensures those troubleshooting, reporting or auditing can easily identify and filter Openshift node VMs.
For example we can use tags for prod vs. non-prod, VMs that should have backup snapshots vs. those that shouldn't, VMs that fall under certain regulatory constraints, etc.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Promote vSphere control plane machinesets from tech preview to GA
Why is this important?
- …
Scenarios
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Promotion PRs collectively pass payload testing
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
As a openshift administrator when i run must-gather in large cluster it tends to be in GB's which fill up my master node . I want an ability to define the time stamp of duration where problem happened and in that way we can have targeted log gathered that can take less space
Goals (aka. expected user outcomes)
have "--since and --until " option in mustgather
Epic Goal*
As a openshift administrator when i run must-gather in large cluster it tends to be in GB's which fill up my master node . I want an ability to define the time stamp of duration where problem happened and in that way we can have targeted log gathered that can take less space
Why is this important? (mandatory)
Reduce must-gather size
Scenarios (mandatory)
Must-gather running over a cluster with many logs can produces tens of GBs of data in cases where only few MBs is needed. Such a huge must-gather archive takes too long to collect and too long to upload. Which makes the process impractical.
Dependencies (internal and external) (mandatory)
The default must-gather images need to implement this functionality. Custom images will be asked to implement the same.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - workloads team
- Documentation - docs team
- QE - workloads QE team
- PX -
- Others -
Acceptance Criteria (optional)
Must-gather contain only logs from requested time interval
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Must-gather currently does not allow to limit the amount of data collected by a customer. Which can lead into collection of tens of GBs even when only a limited set of data (e.g. for the last 2 days) is required. In some cases ending with a master node down.
Suggested solution:
- pass envs such as MUST_GATHER_SINCE_TIME (Only return logs after a specific date (RFC3339)) or MUST_GATHER_SINCE (Only return logs newer than a relative duration like 5s, 2m, or 3h).
Acceptance criteria:
- Extend https://github.com/openshift/enhancements/blob/d3fe6aa13c5c4f8588e6885f3e5a00f0432b1a66/enhancements/oc/must-gather.md#proposal with support for collection controlling envs. oc adm must-gather will get extended with new options (e.g. --since and --since-time) that gets rendered as must-gather container envs. Each must-gather image (including custom images) will be recommended to adopt the envs.
- Extend https://github.com/openshift/oc/blob/master/pkg/cli/admin/mustgather/mustgather.go and https://github.com/openshift/must-gather with the controlling mechanism
rotated-pod-logs does not interact with since/since-time. This causes inspect (and must-gather) outputs to considerably increase in size, even when users attempt to filter it by using time constraints.
Suggested solution:
- parse the date from the log filename and only gather the logs when they are within the provided since or since-time flags
Acceptance criteria:
- `oc adm inspect` respects --since or --since-time flags work as expected even when used in conjunction with --rotated-pod-logs
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
We have decided to remove IPI and UPI support for Alibaba Cloud, which until recently has been in Tech Preview due to the following reasons:
(1) Low customer interest of using Openshift on Alibaba Cloud
(2) Removal of Terraform usage
(3) MAPI to CAPI migration
(4) CAPI adoption for installation (Day 1) in OpenShift 4.16 and Day 2 (post-OpenShift 4.16)
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
- We want to remove official support for UPI and IPI support for Alibaba Cloud provider, which is in Tech Preview in OpenShift 4.15 and earlier. Going forward, we are recommending installations on Alibaba Cloud with either external platform or agnostic platform installation method.
- There will be no upgrades from OpenShift 4.14 / OpenShift 4.15 to OpenShift 4.16.
- For OpenShift 4.16, we will instead offer customers the ability to install OpenShift on Alibaba Cloud with the agnostic platform (platform=none) using the Assisted Installer as Tech Preview - see
OCPSTRAT-1149for details. Note: we cannot remove IPI (Tech Preview) install method until we provide the Assisted Installer (Tech Preview) solution.
Impacted areas based on CI:
- alibaba-cloud-csi-driver/openshift-alibaba-cloud-csi-driver-release-4.16.yaml
- alibaba-disk-csi-driver-operator/openshift-alibaba-disk-csi-driver-operator-release-4.16.yaml
- cloud-provider-alibaba-cloud/openshift-cloud-provider-alibaba-cloud-release-4.16.yaml
- cluster-api-provider-alibaba/openshift-cluster-api-provider-alibaba-release-4.16.yaml
- cluster-cloud-controller-manager-operator/openshift-cluster-cloud-controller-manager-operator-release-4.16.yaml
- machine-config-operator/openshift-machine-config-operator-release-4.16.yaml
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
- Update cloud.redhat.com (Hybrid Cloud Console) to remove Alibaba support.
- Update/removal from Alibaba IPI installer code.
- Update release notes with removal information and no updates/upgrades offered from OpenShift 4.14 or OpenShift 4.15.
- Remove Alibaba installation instructions from Openshift documentation including updating OpenShift Container Platform 4.x Tested Integrations.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Self-managed |
| Classic (standalone cluster) | Classic (standalone) |
| Hosted control planes | N/A |
| Multi node, Compact (three node), or Single node (SNO), or all | All |
| Connected / Restricted Network | All |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | All |
| Operator compatibility | N/A |
| Backport needed (list applicable versions) | N/A |
| Other (please specify) | N/A |
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- Remove any Alibaba-related operator
- Remove Alibaba-related driver
- Remove Alibaba related code from CSO, CCM, and other repos
- Remove container images
- Remove related CI jobs
- Remove documentation
- Stop building images in ART pipeline
- Archive github repositories
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Epic Goal*
Per OCPSTRAT-1042, we are removing Alicloud IPI/UPI support in 4.16 and removing code in 4.16. This epic track the necessary actions to remove the Alicloud Disk CSI driver
Why is this important? (mandatory)
Since we are removing support of Alicloud as a supported provider we need to clean up all the storage artefacts related to Alicloud.
Dependencies (internal and external) (mandatory)
Alicloud IPI/UPI support removal must be confirmed. IPI/UPI code should be remove.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- Remove operator
- Remove driver
- Remove Alibaba related code from CSO.
- Remove container images
- Remove related CI jobs
- Remove documentation
- Stop building images in ART pipeline
- Archive github repositories
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- We want to remove official support for UPI and IPI support for Alibaba Cloud provider. Going forward, we are recommending installations on Alibaba Cloud with either external platform or agnostic platform installation method.
Why is this important?
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
We have decided to remove IPI and UPI support for Alibaba Cloud, which until recently has been in Tech Preview due to the following reasons:
(1) Low customer interest of using Openshift on Alibaba Cloud
(2) Removal of Terraform usage
(3) MAPI to CAPI migration
(4) CAPI adoption for installation (Day 1) in OpenShift 4.16 and Day 2 (post-OpenShift 4.16)
Scenarios
Impacted areas based on CI:
alibaba-cloud-csi-driver/openshift-alibaba-cloud-csi-driver-release-4.16.yaml
alibaba-disk-csi-driver-operator/openshift-alibaba-disk-csi-driver-operator-release-4.16.yaml
cloud-provider-alibaba-cloud/openshift-cloud-provider-alibaba-cloud-release-4.16.yaml
cluster-api-provider-alibaba/openshift-cluster-api-provider-alibaba-release-4.16.yaml
cluster-cloud-controller-manager-operator/openshift-cluster-cloud-controller-manager-operator-release-4.16.yaml
machine-config-operator/openshift-machine-config-operator-release-4.16.yaml
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI jobs are removed
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
Add support for snapshots into kubevirt-csi when the underlying infra csi driver supports snapshots.
Goals (aka. expected user outcomes)
- Users of kubevirt-csi should be able to use csi snapshots within their HCP Kubevirt cluster if the underlying infra storageclass mapped to kubevirt-csi supports snapshots.
Requirements (aka. Acceptance Criteria):
- snapshot support
- downstream ci
- documentation
Goal
Add support for snapshots into kubevirt-csi when the underlying infra csi driver supports snapshots.
User Stories
- As a HCP KubeVirt cluster admin, i would like to be able to create snapshots if the underlying infra cluster csi driver mapped to my kubevirt-csi storageclass supports snapshots.
Non-Requirements
- Scale testing should be handled in the future after this lands as part of the ongoing HCP scale testing effort.
Notes
- Any additional details or decisions made/needed
Done Checklist
| Who | What | Reference |
|---|---|---|
| DEV | Upstream roadmap issue (or individual upstream PRs) | <link to GitHub Issue> |
| DEV | Upstream documentation merged | <link to meaningful PR> |
| DEV | gap doc updated | <name sheet and cell> |
| DEV | Upgrade consideration | <link to upgrade-related test or design doc> |
| DEV | CEE/PX summary presentation | label epic with cee-training and add a <link to your support-facing preso> |
| QE | Test plans in Polarion | <link or reference to Polarion> |
| QE | Automated tests merged | <link or reference to automated tests> |
| DOC | Downstream documentation merged | <link to meaningful PR> |
This task is to add infra snapshot support into upstream kubevirt-csi driver.
This should include unit and functional testing upstream.
This is a new section to the configuring storage for HCP OpenShift Virtualization section in the ACM docs. https://access.redhat.com/documentation/en-us/red_hat_advanced_cluster_management_for_kubernetes/2.10/html/clusters/cluster_mce_overview#configuring-storage-kubevirt
There's a new feature landing in 4.16 that gives HCP Openshift Virtualization's kubevirt-csi component the ability to perform csi snapshots. We need this feature to be documented downstream.
The downstream documentation should follow closely to upstream hypershift documentation that is being introduced in this issue, https://issues.redhat.com/browse/CNV-36075
Feature Overview (aka. Goal Summary)
Streamline and secure CLI interactions, improve backend validation processes, and refine user guidance and documentation for the hcp command and related functionalities.
Use Cases :
- Backend systems robustly handle validations especially to API-address featching and logic previously managed by CLI.
- Users can use the --render command independently of cluster connections, suitable for initial configurations.
- Clear guidance and documentation are available for configuring API server addresses and understanding platform-specific behaviors.
- Clarify which API server address is required for different platforms and configurations.
- Ensure the correct selection of nodes for API server address derivation.
- Improve the description of the --api-server-address flag, be concrete about which api server address is needed
- Add a note + the above to let folks to know they need to set it if they don’t want to be “connected” to a cluster.
Future:
- Improve APIServerAddress Selection?
- Add documentation about the restriction to have the management cluster being standalone
As a customer, I would like to deploy OpenShift On OpenStack, using the IPI workflow where my control plane would have 3 machines and each machine would have use a root volume (a Cinder volume attached to the Nova server) and also an attached ephemeral disk using local storage, that would only be used by etcd.
As this feature will be TechPreview in 4.15, this will only be implemented as a day 2 operation for now. This might or might not change in the future.
We know that etcd requires storage with strong performance capabilities and currently a root volume backed by Ceph has difficulties to provide these capabilities.
By also attaching local storage to the machine and mounting it for etcd would solve the performance issues that we saw when customers were using Ceph as the backend for the control plane disks.
Gophercloud already accepts to create a server with multiple ephemeral disks:
We need to figure out how we want to address that in CAPO, probably involving a new API; that later would be used in openshift (MAPO, and probably installer).
We'll also have to update the OpenStack Failure Domain in CPMS.
ARO (Azure) has conducted some benckmarks and is now recommending to put etcd on a separated data disk:
https://docs.google.com/document/d/1O_k6_CUyiGAB_30LuJFI6Hl93oEoKQ07q1Y7N2cBJHE/edit
Also interesting thread: https://groups.google.com/u/0/a/redhat.com/g/aos-devel/c/CztJzGWdsSM/m/jsPKZHSRAwAJ
- Day 2 install is documented here (this document was originally created for QE, as a FID).
- We need to document that when using rootVolumes for the Control Plane, etcd should be placed on a local ephemeral disk and we document how.
- We also need to update https://docs.openshift.com/container-platform/4.13/scalability_and_performance/recommended-performance-scale-practices/recommended-etcd-practices.html#move-etcd-different-disk_recommended-etcd-practices with 2 adjustments: the command that is used is mkfs.xfs -f and also we use /dev/vdb.
Epic Goal
- Log linking is a feature implemented where a container can get access to logs of other containers in the pod. To be used in supported configurations, this feature has to be enabled by default in CRI-O
Why is this important?
- Allow this feature for most configurations without a support exception
Scenarios
- as a cluster admin, I would like to easily configure a log forwarder for containers in a pod
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Add it to the OOTB runtime classes to allow access without a custom MC
Feature Overview (aka. Goal Summary)
Explore providing a consistent developer experience within OpenShift and Kubernetes via OpenShift console.
Goals (aka. expected user outcomes)
Enable running OpenShift console on Kubernetes clusters and explore the user experience that can be consistent across clusters.
Requirements (aka. Acceptance Criteria):
Install and run OpenShift console on Kubernetes
Enable selection of menu items in Dev and Admin perspective
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
Fully working OpenShift console on Kubernetes.
Background
Customer Considerations
Provide a simple way to install and access OpenShift console on Kubernetes.
Documentation Considerations
None
Interoperability Considerations
N/A
Goal:
Enable running OpenShift console on Kubernetes clusters and explore the user experience that can be consistent across clusters.
Explore providing a consistent developer experience within OpenShift and Kubernetes via OpenShift console.
Out of Scope: The OpenShift console is fully working on Kubernetes.
Acceptance criteria:
- Install and run the OpenShift console on Kubernetes (provide a helm or yaml setup)
- General console should work, and users should see the Dev and Admin perspective (fix obvious crashes and hide features that depend on OpenShift)
- Explore and extend (when possible) the setup without Authentification with one that supports a user login
- List missing (hidden) or non-working features and dependencies
- Check how good our console works with just the upstream operators like. Recommended order:
- Knative instead of OpenShift Serverless
- Tekton instead of OpenShift Pipelines
- Shipwright instead of OpenShift Builds
- Operator Lifecycle Manager (OLM)
- Web Terminal Operator
Topology export with Primer operator
Description of problem:
When running the console against a non-OpenShift/non-OKD cluster the admin perspective almost work fine. But the developer perspective has a lot of small issues.
Version-Release number of selected component (if applicable):
Almost all versions
How reproducible:
Always
Steps to Reproduce:
You need a non-OpenShift cluster. You might can test this any another kubernetes distribution. I used kubeadm to create a local cluster, but it take some time until I can start a Pod locally. (That's the precondition.)
You might want test kind or k3s instead.
To run the console on your local machine against a non-OpenShift k8s cluster on your local machine you can use this script: https://github.com/jerolimov/openshift/commit/e6fe0924807017ff1320cfc8d82bde23c162eba3
Actual results:
- Add page, Topology and Search wasn't shown in the navigation. The add page is opened anyway when switching to developer perspective.
- Topology page and Search already worked fine and are available when changing the URL manually.
- Add page quick search doesn't find anything
- The add page contains actions like Import from Git that doesn't work.
- The Namespace dropdown says "Namespaces" multiple times, but one "Projects" has left
- The masthead navigation contains a Quick Start item that shows just a "No Quick Starts found" page
Expected results:
- Add page, Topology and Search navigation items should be shown.
- Add page should not show quick search button if it doesn't find anything
- Add page should not show any broken actions (better is to fix them, but this might be more complex)
- The namespace dropdown should only show Namespace labels.
- The masthead navigation should not show a Quick Start item if the Quick Start CRD is not installed
Additional info:
Feature Overview (aka. Goal Summary)
Graduce the new PV access mode ReadWriteOncePod as GA.
Such PV/PVC can be used only in a single pod on a single node compared to the traditional ReadWriteOnce access mode, where such a PV/PVC can be used on a single node by many pods.
Goals (aka. expected user outcomes)
The customers can start using the new ReadWriteOncePod access mode.
This new mode allows customers to provision and attach PV and get the guarantee that it cannot be attached to another local pod.
Requirements (aka. Acceptance Criteria):
This new mode should support the same operations as regular ReadWriteOnce PVs therefore it should pass the regression tests. We should also ensure that this PV can't be accessed by another local-to-node pod.
Use Cases (Optional):
As a user I want to attach a PV to a pod and ensure that it can't be accessed by another local pod.
Background
We are getting this feature from upstream as GA. We need to test it and fully support it.
- Enhancement issue: https://github.com/kubernetes/enhancements/issues/2485
- KEP: https://github.com/kubernetes/enhancements/pull/2489
Customer Considerations
Check that there is no limitations / regression.
Documentation Considerations
Remove tech preview warning. No additional change.
Interoperability Considerations
N/A
Epic Goal
Support upstream feature "New RWO access mode " in OCP as GA, i.e. test it and have docs for it.
This is continuation of STOR-1171 (Beta/Tech Preview in 4.14), now we just need to mark it as GA and remove all TechPreview notes from docs.
Why is this important?
- We get this upstream feature through Kubernetes rebase. We should ensure it works well in OCP and we have docs for it.
Upstream links
- Enhancement issue: https://github.com/kubernetes/enhancements/issues/2485
- KEP: https://github.com/kubernetes/enhancements/pull/2489
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- External: the feature is currently scheduled for GA in Kubernetes 1.29, i.e. OCP 4.16, but it may change before Kubernetes 1.29 GA.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
Currently it's not possible to modify the BMC address of a BareMetalHost after it has been set.
Users need to be able to update the BMC entries in the BareMetalHost objects after they have been created .
Use Cases
There are at least two scenarios in which this causes problems:
1. When deploying baremetal clusters with the Assisted Installer, Metal3 is deployed and BareMetalHost objects are created but with empty BMC entries. We can modify these BMC entries after the cluster has come up to bring the nodes "under management", but if you make a mistake like I did with the URI then it's not possible to fix that mistake.
2. BMC addresses may change over time - whilst it may appear unlikely, network readdressing, or changes in DNS names may mean that BMC addresses will need to be updated.
Currently it's not possible to modify the BMC address of a BareMetalHost after it has been set. It's understood that this was an initial design choice, and there's a webhook that prevents any modification of the object once it has been set for the first time. There are at least two scenarios in which this causes problems:
1. When deploying baremetal clusters with the Assisted Installer, Metal3 is deployed and BareMetalHost objects are created but with empty BMC entries. We can modify these BMC entries after the cluster has come up to bring the nodes "under management", but if you make a mistake like I did with the URI then it's not possible to fix that mistake.
2. BMC addresses may change over time - whilst it may appear unlikely, network readdressing, or changes in DNS names may mean that BMC addresses will need to be updated.
Thanks!
Currently, the baremetal operator does not allow the BMC address of a node to be updated after BMH creation. This ability needs to be added in BMO.
Feature Overview (aka. Goal Summary)
Currently the maximum number of snapshots per volume in vSphere CSI is set to 3 and cannot be configured. Customers find this default limit too low and are asking us to make this setting configurable.
Maximum number of snapshot is 32 per volume
Goals (aka. expected user outcomes)
Customers can override the default (three) value and set it to a custom value.
Make sure we document (or link) the VMWare recommendations in terms of performances.
https://kb.vmware.com/s/article/1025279
Requirements (aka. Acceptance Criteria):
The setting can be easily configurable by the OCP admin and the configuration is automatically updated. Test that the setting is indeed applied and the maximum number of snapshots per volume is indeed changed.
No change in the default
Use Cases (Optional):
As an OCP admin I would like to change the maximum number of snapshots per volumes.
Out of Scope
Anything outside of
Background
The default value can't be overwritten, reconciliation prevents it.
Customer Considerations
Make sure the customers understand the impact of increasing the number of snapshots per volume.
https://kb.vmware.com/s/article/1025279
Documentation Considerations
Document how to change the value as well as a link to the best practice. Mention that there is a 32 hard limit. Document other limitations if any.
Interoperability Considerations
N/A
Epic Goal*
The goal of this epic is to allow admins to configure the maximum number of snapshots per volume in vSphere CSI and find an way how to add such extension to OCP API.
Possible future candidates:
- configure EFS volume size monitioring (via driver cmdline arg.) -
STOR-1422 - configure OpenStack topology -
RFE-11
Why is this important? (mandatory)
Currently the maximum number of snapshots per volume in vSphere CSI is set to 3 and cannot be configured. Customers find this default limit too low and are asking us to make this setting configurable.
Maximum number of snapshot is 32 per volume
https://kb.vmware.com/s/article/1025279
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- As an admin I would like to configure the maximum number of snapshots per volume.
- As a user I would like to create more than 3 snapshots per volume
Dependencies (internal and external) (mandatory)
1) Write OpenShift enhancement (STOR-1759)
2) Extend ClusterCSIDriver API (TechPreview) (STOR-1803)
3) Update vSphere operator to use the new snapshot options (STOR-1804)
4) Promote feature from Tech Preview to Accessible-by-default (STOR-1839)
- prerequisite: add e2e test and demonstrate stability in CI (
STOR-1838)
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - STOR
- Documentation - STOR
- QE - STOR
- PX - Enablement
- Others -
Acceptance Criteria (optional)
Configure the maximum number of snapshot to a higher value. Check the config has been updated and verify that the maximum number of snapshots per volume maps to the new setting value.
Drawbacks or Risk (optional)
Setting this config setting with a high value can introduce performances issues. This needs to be documented.
https://kb.vmware.com/s/article/1025279
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Feature Overview (aka. Goal Summary)
To support volume provisioning and usage in multi-zonal clusters, the deployment should match certain requirements imposed by CSI driver - https://docs.vmware.com/en/VMware-vSphere-Container-Storage-Plug-in/3.0/vmware-vsphere-csp-getting-started/GUID-4E5F8F65-8845-44EE-9485-426186A5E546.html
The requirements have slightly changed in 3.1.0 - https://docs.vmware.com/en/VMware-vSphere-Container-Storage-Plug-in/3.0/vmware-vsphere-csp-getting-started/GUID-162E7582-723B-4A0F-A937-3ACE82EAFD31.html
We need to ensure that, cluster is compliant with topology requirement and if not, vsphere-problem-detector should detect invalid configuration and create warnings and alerts.
A patch to the vSphere CSI driver was added to accept both the old and new tagging methods in order to avoid regressions. A warning is thrown if the old way is used.
Goals (aka. expected user outcomes)
Ensure that if customer's configuration is not compliant, OCP raises a warning. The goal is to validate customer's config. Improve VPD to detect these misconfigurations.
Ensure the driver keeps working with the old configuration. Raise a warning if customers are still using the old tagging way.
Requirements (aka. Acceptance Criteria):
This feature should be able to detect any anomalies when customers are configuring vSphere topology.
Driver should work with both new and old way to define zones
Out of Scope
This epic is not about testing topology which is already supported.
Background
The vSphere CSI driver changed the way tag are applied to nodes and clusters. This feature ensures that the customer's config and what is expected from the driver.
Customer Considerations
This will help customers get the guarantee that their configuration is compliant especially for those who are used to the old way of configuring topology
Documentation Considerations
Update the topology documentation to match the new driver requirements.
Interoperability Considerations
OCP on vSphere
Epic Goal*
To support volume provisioning and usage in multi-zonal clusters, the deployment should match certain requirements imposed by CSI driver - https://docs.vmware.com/en/VMware-vSphere-Container-Storage-Plug-in/3.0/vmware-vsphere-csp-getting-started/GUID-4E5F8F65-8845-44EE-9485-426186A5E546.html
The requirements have slightly changed in 3.1.0 - https://docs.vmware.com/en/VMware-vSphere-Container-Storage-Plug-in/3.0/vmware-vsphere-csp-getting-started/GUID-162E7582-723B-4A0F-A937-3ACE82EAFD31.html
We need to ensure that, cluster is compliant with topology requirement and if not, vsphere-problem-detector should detect invalid configuration and create warnings and alerts.
What is our purpose in implementing this? What new capability will be available to customers?
Why is this important? (mandatory)
This is important because clusters could be misconfigured and it will be tricky to detect if volume provisioning is not working because of misconfiguration or there are some other errors. Having a way to validate customer's topology will ensure that we have right topology.
We already have checks in VPD, but we need to enhance those checks to ensure we are compliant.
Scenarios (mandatory)
In 4.15: make cluster Upgradeable=False when:
- Customer has deployed OCP in multizonal clusters and has forgot to tag compute clusters.
- Customer has deployed OCP in multizonal clusters and has tagged compute clusters as well as hosts.
4.16: mark the cluster degraded in the conditions above.
These scenarios will result in invalid cluster configuration.
Dependencies (internal and external) (mandatory)
- No dependencies on other teams.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Feature Overview (aka. Goal Summary)
Support the SMB CSI driver through an OLM operator as tech preview. The SMB CSI driver allows OCP to consume SMB/CIFS storage with a dynamic CSI driver. This enables customers to leverage their existing storage infrastructure with either SAMBA or Microsoft environment.
https://github.com/kubernetes-csi/csi-driver-smb
Goals (aka. expected user outcomes)
Customers can start testing connecting OCP to their backend exposing CIFS. This can allow to consume net new volume or consume existing data produced outside OCP.
Requirements (aka. Acceptance Criteria):
Driver already exists and is under the storage SIG umbrella. We need to make sure the driver is meeting OCP quality requirement and if so develop an operator to deploy and maintain it.
Review and clearly define all driver limitations and corner cases.
Use Cases (Optional):
- As an OCP admin, I want OCP to consume storage exposed via SMB/CIFS to capitalise on my existing infrastructure.
- As an user, I want to consume external data stored on a SMB/CIFS backend.
Questions to Answer (Optional):
Review the different authentication method.
Out of Scope
Windows containers support.
Only storage class login/password authentication method. Other methods can be reviewed and considered for GA.
Background
Customers are expecting to consume storage and possibly existing data via SMB/CIFS. As of today vendor's drivers support is really limited in terms of CIFS support whereas this protocol is widely used on premise especially with MS/AD customers.
Customer Considerations
Need to understand what customers expect in terms of authentication.
How to extend this feature to windows containers.
Documentation Considerations
Document the operator and driver installation, usage capabilities and limitations.
Interoperability Considerations
Future: How to manage interoperability with windows containers (not for TP)
- https://github.com/openshift/csi-operator/pull/217
- https://github.com/openshift/csi-operator/pull/215
- https://github.com/openshift/csi-operator/pull/210
- https://github.com/openshift/csi-operator/pull/212
- https://github.com/openshift/csi-operator/pull/211
- https://github.com/openshift/csi-operator/pull/209
- https://github.com/openshift/csi-operator/pull/205
- https://github.com/openshift/csi-operator/pull/169
- https://github.com/openshift/csi-operator/pull/217
- https://github.com/openshift/csi-operator/pull/215
- https://github.com/openshift/csi-operator/pull/210
- https://github.com/openshift/csi-operator/pull/212
- https://github.com/openshift/csi-operator/pull/211
- https://github.com/openshift/csi-operator/pull/209
- https://github.com/openshift/csi-operator/pull/205
- https://github.com/openshift/csi-operator/pull/169
- https://github.com/openshift/csi-operator/pull/217
- https://github.com/openshift/csi-operator/pull/215
- https://github.com/openshift/csi-operator/pull/210
- https://github.com/openshift/csi-operator/pull/212
- https://github.com/openshift/csi-operator/pull/211
- https://github.com/openshift/csi-operator/pull/209
- https://github.com/openshift/csi-operator/pull/205
- https://github.com/openshift/csi-operator/pull/169
Add a new provider here:
https://github.com/openshift/api/blob/6d48d55c0598ec78adacdd847dcf934035ec2e1b/operator/v1/types_csi_cluster_driver.go#L86
It should be "smb.csi.k8s.io", from the CSIDriver manifest:
https://github.com/kubernetes-csi/csi-driver-smb/blob/master/deploy/csi-smb-driver.yaml
Feature Overview:
Hypershift-provisioned clusters, regardless of the cloud provider support the proposed integration for OLM-managed integration outlined in OCPBU-559 and OCPBU-560.
Goals
There is no degradation in capability or coverage of OLM-managed operators support short-lived token authentication on cluster, that are lifecycled via Hypershift.
Requirements:
- the flows in
OCPBU-559andOCPBU-560need to work unchanged on Hypershift-managed clusters - most likely this means that Hypershift needs to adopt the CloudCredentialOperator
- all operators enabled as part of
OCPBU-563, OCPBU-564,OCPBU-566and OCPBU-568 need to be able to leverage short-lived authentication on Hypershift-managed clusters without being aware that they are on Hypershift-managed clusters - also OCPBU-569 and
OCPBU-570should be achievable on Hypershift-managed clusters
Background
Currently, Hypershift lacks support for CCO.
Customer Considerations
Currently, Hypershift will be limited to deploying clusters in which the cluster core operators are leveraging short-lived token authentication exclusively.
Documentation Considerations
If we are successful, no special documentation should be needed for this.
Outcome Overview
Operators on guest clusters can take advantage of the new tokenized authentication workflow that depends on CCO.
Success Criteria
CCO is included in HyperShift and its footprint is minimal while meeting the above outcome.
Expected Results (what, how, when)
Post Completion Review – Actual Results
After completing the work (as determined by the "when" in Expected Results above), list the actual results observed / measured during Post Completion review(s).
Every guest cluster should have a running CCO pod with its kubeconfig attached to it.
Enchancement doc: https://github.com/openshift/enhancements/blob/master/enhancements/cloud-integration/tokenized-auth-enablement-operators-on-cloud.md
Feature Overview (aka. Goal Summary)
Provide a way to automatically recover a cluster with expired etcd server and peer certificates.
Goals (aka. expected user outcomes)
A cluster has etcd serving, peer, and serving-metrics certificates that are expired. There should be a way to either trigger certificate rotation or have a process that automatically does the rotation.
Requirements (aka. Acceptance Criteria):
Deliver rotation and recovery requirements from OCPSTRAT-714
Epic Goal*
Provide a way to automatically recover a cluster with expired etcd server and peer certs
Why is this important? (mandatory)
Currently, the EtcdCertSigner controller, which is part of the CEO, renews the aforementioned certificates roughly every 3 years. However, if the cluster is offline for a period longer than the certificate's validity, upon restarting the cluster, the controller won't be able to renew the certificates since the operator won't be running at all.
We have scenarios where the customer, partner, or service delivery needs to recover a cluster that is offline, suspended, or shutdown, and as part of the process requires a supported way to force certificate and key rotation or replacement.
See the following doc for more use cases of when such clusters need to be recovered:
https://docs.google.com/document/d/198C4xwi5td_V-yS6w-VtwJtudHONq0tbEmjknfccyR0/edit
Required to enable emergency certificate rotation.
https://issues.redhat.com/browse/API-1613
https://issues.redhat.com/browse/API-1603
Scenarios (mandatory)
A cluster has etcd serving, peer and serving-metrics certificates that are expired. There should be a way to either trigger certificate rotation or have a process that automatically does the rotation.
This does not cover the expiration of etcd-signer certificates at this time.
That will be covered under https://issues.redhat.com/browse/ETCD-445
Dependencies (internal and external) (mandatory)
While the etcd team will implement the automatic recovery for the etcd certificates, other control-plane operators will be handling their own certificate recovery.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - etcd team
- Documentation - etcd docs team
- QE - etcd qe
- PX -
- Others -
Acceptance Criteria (optional)
When a openshift etcd cluster that has expired etcd server and peer certs is restarted and is able to regenerate those certs.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Having an e2e test that puts a cluster into the expired certs failure mode and forces it to recover.
- Documentation - Docs that explain the cert recovery procedure
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Given the scope creep of the work required to enable an offline cert rotation (or an automated restore), we are going to rely on online cert rotation to ensure that etcd certs don't expire during a cluster shutdown/hibernation.
Slack thread for background:
https://redhat-internal.slack.com/archives/C851TKLLQ/p1712533437483709?thread_ts=1712526244.614259&cid=C851TKLLQ
The estimated maximum shutdown period is 9 months. The refresh rate for the etcd certs can be increased so that there are always e.g 10 months left on the cert validity in the worst case i.e we shutdown right before the controller does its rotation.
Feature Overview (aka. Goal Summary)
The etc-ca must be rotatable both on-demand and automatically when expiry approaches.
Goals (aka. expected user outcomes)
- Have a tested path for customers to rotate certs manually
- We must have a tested path for auto rotation of certificates when certs need rotation due to age
Requirements (aka. Acceptance Criteria):
Deliver rotation and recovery requirements from OCPSTRAT-714
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Refactoring in ETCD-512 creates a rotation due to incompatible certificate creation processes. We should update the render [1] the same way the controller manages the certificates. Keep in mind that important information are always stored in annotations, which means we also need to update the manifest template itself (just exchanging file bytes isn't enough).
AC:
- CEO should render the same certificates it would otherwise when the refactored CertSignerController runs
- test that a fresh installation avoids re-creating certificates after the bootstrap phase
[1] https://github.com/openshift/cluster-etcd-operator/blob/master/pkg/cmd/render/render.go#L347-L365
This spike explores using the library-go cert rotation utils in the etcd-operator to replace or augment the existing etcdcertsigner controller.
https://github.com/openshift/library-go/blob/master/pkg/operator/certrotation/client_cert_rotation_controller.go
https://github.com/openshift/cluster-etcd-operator/pull/1177
The goal of this spike is to evaluate if the library-go cert rotation util gives us rotation capabilities for the signer cert along with the peer and server certs.
There are a couple of issues to explore with the use of the library-go cert signer controller:
- The etcd cluster is currently configured with a single CA for etcd's peer and server certs, whereas the library-go controller would require using different CAs for the peer and server certs.
- We also need to consider how upgrades would be handled, i.e if we change to using two new CAs, would our new certsignercontroller handle that transparently?
Given the manual rotation of signers for 4.16, we should add an alert that proactively tells customers to run the manual rotation procedure.
AC:
- Add a metric that denotes how many days the signer certs are still valid
- Add an alert over that metric (eg 300 days before expiry)
After merging ETCD-512, we need to ensure the certs are regenerated when the signer changes.
Current logic in library-go only changes when the bundle is updated, which is not sufficient of a criteria for the etcd rotation.
Some initial take: https://github.com/openshift/library-go/pull/1674
discussion in: https://redhat-internal.slack.com/archives/CC3CZCQHM/p1706889759638639
AC:
- leaf certs should be checked with AKI/SKI continuously for more robust change detection
- leaf certs should be checked that a given signer was actually used to sign a certificate
- use a filtered informer for node updates to avoid calling expensive logic too often (https://github.com/openshift/library-go/blob/master/pkg/controller/factory/factory.go#L109C19-L109C46)
Refactoring in ETCD-512 does not clean up certificates that are dynamically generated. Imagine you're recreating all your master nodes everyday, we would create new peer/serving/metrics certificates for each node and never clean them up.
We should try to be conservative when cleaning them up, so keep them around for a certain retention period (7-10 days?) after the node went away.
AC:
- CEO should clean up old-enough "node" certificates
Testing in ETCD-512 revealed that CEO does not react to changes in the CA bundle or the client certificates.
The current mounts are defined here:
https://github.com/openshift/cluster-etcd-operator/blob/60b7665a26610a095722d3b12b2bb08dcae6965f/manifests/0000_20_etcd-operator_06_deployment.yaml#L90-L106
A simple fix would be to watch the respective resources in a controller and exit the container on changes. This is how we did it with feature gates as well: (https://github.com/openshift/cluster-etcd-operator/blob/60b7665a26610a095722d3b12b2bb08dcae6965f/pkg/operator/starter.go#L174C1-L174C1)
If hot-reload would be feasible we should take a look at it, but it seems a larger refactoring.
AC:
- CEO needs to react (restart) when it detects changes in certificate related secrets
- add an e2e testcase for it
To make better decision on rev rollouts and when to recert leafs, we should store the revision when a given CA was rotated.
AC:
- when a new CA is generated, store the static pod revision in the operator status
Feature Overview (aka. Goal Summary)
As cluster admin I would like to configure machinesets to allocate instances from pre-existing Capacity Reservation in Azure.
I want to create a pool of reserved resources that can be shared between clusters of different teams based on their priorities. I want this pool of resources to remain available for my company and not get allocated to another Azure customer.
Additional background on the feature for considering additional use cases
- Proposed title of this feature request
Machine API support for Azure Capacity Reservation Groups
- What is the nature and description of the request?
The customer would like to configure machinesets to allocate instances from pre-existing Capacity Reservation Groups, see Azure docs below
- Why does the customer need this? (List the business requirements here)
This would allow the customer to create a pool of reserved resources which can be shared between clusters of different priorities. Imagine a test and prod cluster where the demands of the prod cluster suddenly grow. The test cluster is scaled down freeing resources and the prod cluster is scaled up with assurances that those resources remain available, not allocated to another Azure customer.
- List any affected packages or components.
MAPI/CAPI Azure
In this use case, there's no immediate need for install time support to designate reserved capacity group for control plane resources, however we should consider whether that's desirable from a completeness standpoint. We should also consider whether or not this should be added as an attribute for the installconfig compute machinepool or whether altering generated MachineSet manifests is sufficient, this appears to be a relatively new Azure feature which may or may not see wider customer demand. This customer's primary use case is centered around scaling up and down existing clusters, however others may have different uses for this feature.
Additional background on the feature for considering additional use cases
Update the vendor to update in cluster-control-plane-machine-set-operator repository for capacity reservation Changes.
User Story
As a developer I want to add support of capacity reservation group in openshift/machine-api-provider-azure so that azure VMs can be associated to a capacity reservation group during the VM creation.
Background
CFE-1036 adds the support of Capacity Reservation in upstream CAPZ (PR). The same support is needed to be added downstream also. Please refer the upstream PR for adding support downstream.
Steps
- Import the latest API changes from openshift/api to get the new field "CapacityReservationGroupID" into openshift/machine-api-provider-azure.
- If a value is assigned to the field then use for associated a VM to the capacity reservation group during VM creation.
Stakeholders
- Cluster Infra
- CFE
Definition of Done
- The PR should be reviewed and approved.
- Testing
- Add unit tests to validate the implementation.
As a developer I want to add the webhook validation for the "CapacityReservationGroupID" field of "AzureMachineProviderSpec" in openshift/machine-api-operator so that Azure capacity reservation can be supported.
Background
CFE-1036 adds the support of Capacity Reservation in upstream CAPZ (PR). The same support is needed to be added downstream also. Please refer the upstream PR for adding support downstream.
Slack discussion regarding the same: https://redhat-internal.slack.com/archives/CBZHF4DHC/p1713249202780119?thread_ts=1712582367.529309&cid=CBZHF4DHC_
Steps
- Add the validation for "CapacityReservationGroupID" to "AzureMachineProviderSpec"
- Add tests to validate.
Stakeholders
- Cluster Infra
- CFE
User Story
As a developer I want to add the field "CapacityReservationGroupID" to "AzureMachineProviderSpec" in openshift/api so that Azure capacity reservation can be supported.
Background
CFE-1036 adds the support of Capacity Reservation in upstream CAPZ (PR). The same support is needed to be added downstream also. Please refer the upstream PR for adding support downstream.
Slack discussion regarding the same: https://redhat-internal.slack.com/archives/CBZHF4DHC/p1713249202780119?thread_ts=1712582367.529309&cid=CBZHF4DHC_
Steps
- Add the field "CapacityReservationGroupID" to "AzureMachineProviderSpec"
- The new field should be immutable. Add validations for the same.
- Add tests to validate the immutability.
Stakeholders
- Cluster Infra
- CFE
Definition of Done
- The PR should be reviewed and approved.
- Docs
- Add appropriate godoc for the field explaining its purpose
- Testing
- Add tests to validate the immutability.
Market Problem
- As an OpenShift cluster administrator for a self-managed standalone OpenShift cluster, I want to use the Priority based expander for cluster-autoscaler to select instance types based on priorities assigned by a user to scaling groups.
The Configuration is based on the values stored in a ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-autoscaler-priority-expander
namespace: kube-system
data:
priorities: |-
10:
- .*t2\.large.*
- .*t3\.large.*
50:
- .*m4\.4xlarge.*
Expected Outcomes
- When creating a MachineSet, customers would like to define their preferred instance types with priorities so that if one is not available a fallback instance type option is available down the list.
https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/expander/priority/readme.md
Epic Goal
- Allow users to choose the "priority" and "least-waste" expanders when creating a ClusterAutoscaler resource.
Why is this important?
- The priority expander gives users the capability to instruct the cluster autoscaler about preferred node groups that it should expand. In this manner, a user can dictate to the cluster autoscaler which MachineSets should take priority when scaling up the cluster.
- The least-waste expander gives users the capability to instruct the cluster autoscaler to choose instance sizes which will have the least amount of cpu and memory resource wastage when choosing for pending pods. It is a great supplement the priority expander to give backup option when multiple instance sizes might work.
Scenarios
- As a user I would like the cluster autoscaler to prefer MachineSets that use spot instances as it will lower my costs. By using the priority expander, I can indicate to the cluster autoscaler which MachineSets should be utilized first when scaling up the cluster.
- As a user I wan the autoscaler to prefer instance sizes which produce the least amount of wasted cpu and memory resources. By using the least-waste expander I can instruct the autoscaler to make this decision.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- New e2e tests added to exercise this functionality
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- Is there any automation we want to add to the CAO to make this easier for users? (eg a new field on MachineAutoscaler to indicate a priority)
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story
As a user, I would like to specify different expanders for the cluster autoscaler. Having an API field on the ClusterAutoscaler resource to specify the expanders and their precedence will solve this issue for me.
Background
The cluster autoscaler allows users to specify a list of expanders to use when creating new nodes. This list is expressed as a command line flag that takes multiple comma-separated options, eg "--expander=priority,least-waste,random".
We need to add a new field to the ClusterAutoscaler resource that allows users to specify an ordered list of expanders to use. We should limit values in that list to "priority", "least-waste", and "random" only. We should limit the length of the list to 3 items.
Steps
- add a new API field for expander options
- write unit tests to confirm behavior in CAO
Stakeholders
- openshift eng
Definition of Done
- user can express priority, least-waste, and random expanders through the ClusterAutoscaler resource
- Docs
- need docs on the expanders, what they are, how to select them
- need docs describing how to configure the priority expander
- Testing
- we will add unit tests in this card, e2e tests will follow in another card
Feature Overview (aka. Goal Summary)
Due to historical reasons, the etcd operator uses a static definition of an 8GB limit. Nowadays, customers with dense cluster configurations regularly reach the limit. OpenShift should provide a mechanism for increasing the database size while maintaining a validated configuration.
Goals (aka. expected user outcomes)
This feature aims to provide validated selectable sizes for the etcd database, allowing cluster admins to opt-in for larger sizes.
Requirements (aka. Acceptance Criteria):
Since using larger etcd database sizes may impact the defragmentation process, causing more noticeable transaction "pauses", this should be an opt-in configuration.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Yes |
| Classic (standalone cluster) | Yes |
| Hosted control planes | No |
| Multi node, Compact (three node), or Single node (SNO), or all | Yes |
| Connected / Restricted Network | Yes |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | Yes |
| Operator compatibility | N/A |
| Backport needed (list applicable versions) | N/A |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | No |
| Other (please specify) | N/A |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Epic Goal*
Provide a way to change the etcd database size limit from the default 8GB which is non-configurable.
https://etcd.io/docs/v3.5/dev-guide/limit/#storage-size-limit
This will likely be done through the API as a new field in the `cluster` `etcds.operator.openshift.io` CustomResouce object. Similar to the etcd latency tuning profiles which allow a selectable set of configurations this limit should also be bound within reasonable limits or levels.
Why is this important? (mandatory)
Due to historical reasons, the etcd operator uses a static definition of an 8GB limit. Nowadays, customers with dense cluster configurations regularly reach the limit. OpenShift should provide a mechanism for increasing the database size while maintaining a validated configuration.
The 8GB limit was due to historical limitations of the bbolt store which have been improved upon for a while and there are examples and discussion upstream to suggest that the quota limit can be set higher.
See:
- https://github.com/etcd-io/website/issues/588
- https://github.com/etcd-io/etcd/issues/15354
- https://github.com/etcd-io/etcd/issues/12690
- https://github.com/etcd-io/etcd/issues/9771
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- As an admin I can increase the etcd database size via the openshift etcd API
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - etcd team
- Documentation - etcd docs team
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
This is to track changes in OCP API for custom etcd db size https://issues.redhat.com/browse/ETCD-513
Include the version of the oc binary used, and the logs generated by the command into the must-gather directory when running the oc adm must-gather command.
- The version of the oc binary can help to identify if an issue could be caused because the oc version is different than the version of the cluster.
- The logs generated by the oc adm must-gather command will help to identify if some information could not be collected, and also the exact image used (while the image used is currently in the directory name, I think it could be better to use a short directory name, specially for customers running oc on Windows, as the too long directory name can cause issues there).
The version of the oc binary could be included in the oc adm must-gather output [1], and if it's 2 or more minor versions than the running cluster, a warning should be shown.
1. Proposed title of this feature request
Include additional info into must-gather directory
2. What is the nature and description of the request?
Include the version of the oc binary used, and the logs generated by the command into the must-gather directory when running the oc adm must-gather command.
The version of the oc binary can help to identify if an issue could be caused because the oc version is different than the version of the cluster.
The logs generated by the oc adm must-gather command will help to identify if some information could not be collected, and also the exact image used
4. List any affected packages or components.
oc
Include logs generated by the command into the must-gather directory when running the oc adm must-gather command.
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
The Azure File CSI driver currently lacks cloning and snapshot restore features. The goal of this feature is to support the cloning feature as technology preview. This will help support snapshots restore in a future release
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
As a user I want to easily clone Azure File volume by creating a new PVC with spec.DataSource referencing origin volume.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
This feature only applies to OCP running on Azure / ARO and File CSI.
The usual CSI cloning CI must pass.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | both |
| Classic (standalone cluster) | yes |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | all although SNO is rare on Azure |
| Connected / Restricted Network | both |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86 |
| Operator compatibility | Azure File CSI operator |
| Backport needed (list applicable versions) | No |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | No |
| Other (please specify) | ship downstream images with from forked azcopy |
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Restoring snapshots are out of scope for now.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Update the CSI capability matrix and any language that mentions that Azure File CSI does not support cloning.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Not impact but benefit Azure / ARO customers.
Epic Goal*
Azure File added support for cloning volumes which relies on azcopy command upstream. We need to fork azcopy so we can build and ship downstream images with from forked azcopy. AWS driver does the same with efs-utils.
Upstream repo: https://github.com/Azure/azure-storage-azcopy
NOTE: using snapshots as a source is currently not supported: https://github.com/kubernetes-sigs/azurefile-csi-driver/blob/7591a06f5f209e4ef780259c1631608b333f2c20/pkg/azurefile/controllerserver.go#L732
Why is this important? (mandatory)
This is required for adding Azure File cloning feature support.
Scenarios (mandatory)
1. As a user I want to easily clone Azure File volume by creating a new PVC with spec.DataSource referencing origin volume.
Dependencies (internal and external) (mandatory)
1) Write OpenShift enhancement (STOR-1757)
2) Fork upstream repo (STOR-1716)
3) Add ART definition for OCP Component (STOR-1755)
- prerequisite: Onboard image with DPTP/CI (
STOR-1752) - prerequisite: Perform a threat model assessment (
STOR-1753) - prerequisite: Establish common understanding with Product Management / Docs / QE / Product Support (
STOR-1753) - requirement: ProdSec Review (
STOR-1756)
4) Use the new image as base image for Azure File driver (STOR-1794)
5) Ensure e2e cloning tests are in CI (STOR-1818)
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - yes
- Documentation - yes
- QE - yes
- PX - ???
- Others - ART
Acceptance Criteria (optional)
Downstream Azure File driver image must include azcopy and cloning feature must be tested.
Drawbacks or Risk (optional)
No risks detected so far.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be "Release Pending"
Once the azure-file clone is supported, we should add clone test in our pre-submit/periodic CI.
The "pvcDataSource: true" should be added.
Feature Overview (aka. Goal Summary)
Add support for standalone secondary networks for HCP kubevirt.
Advanced multus integration involves the following scenarios
1. Secondary network as single interface for VM
2. Multiple Secondary Networks as multiple interfaces for VM
Goals (aka. expected user outcomes)
Users of HCP KubeVirt should be able to create a guest cluster that is completely isolated on a secondary network outside of the default pod network.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
<enter general Feature acceptance here>
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | self-managed |
| Classic (standalone cluster) | na |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | na |
| Connected / Restricted Network | yes |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86 |
| Operator compatibility | na |
| Backport needed (list applicable versions) | na |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | na |
| Other (please specify) | na |
Documentation Considerations
ACM documentation should include how to configure secondary standalone networks.
This is a continuation of CNV-33392.
Multus Integration for HCP KubeVirt has three scenarios.
1. Secondary network as single interface for VM
2. Multiple Secondary Networks as multiple interfaces for VM
3. Secondary network + pod network (default for kubelet) as multiple interfaces for VM
Item 3 is the simplest use case because it does not require any addition considerations for ingress and load balancing. This scenario [item 3] is covered by CNV-33392.
Items [1,2] are what this epic is tracking, which we are considering advanced use cases.
Now that the hypershift kubevirt provider has a way to expose secondary network services generating endpointslices we should document it.
Also enable --attach-default-network option at "hcp" command tool is needed.
When creating a cluster with secondary network the ingress is broken since the created service cannot access the VMs secondary addresses.
We need to create a controller that manually create and update the service endpoints so it's always pointing to the VMs IPs.
When no default pod network is used, we need the LB mirroring that cloud-provider-kubevirt preforms to create custom endpoints that map to the secondary network. This will allow the LB service to route to the secondary network. Otherwise, the LB service will not be able to pass traffic if the pod network interface is not attached to the VM.
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Workload partitioning currently does not support mutating containers that have cpu limits. That can cause platform/control plane components use the wrong core budget (application instead of platform).
Goals (aka. expected user outcomes)
Apply the workload paritioning also for containers that have cpu limits.
Requirements (aka. Acceptance Criteria):
1) Add another annotation to the crio drop in to represent the limit, "cpuquota"
[crio.runtime.workloads.management]
activation_annotation = "target.workload.openshift.io/management"
annotation_prefix = "resources.workload.openshift.io"
resources = { "cpushares" = 0, "cpuquota"=0, "cpuset" = "0-1,52-53" }
2) Modify the admission plugin to take cpu limits and add a cpuquota annotation. The cpu limits would be stripped. A new annotation or extend the existing one i.e.
annotations:
resources.workload.openshift.io/foo: {"cpushares": 20, "cpuquota": 50}
3) Modify crio to set cfs.quota for the contatiner to the value of cpuquota
Questions to Answer (Optional):
- Any consideration needed for upgrades from previous versions?
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
n/a
Background
The original premise was that all ocp pods did not set limits, however it has been found that at least one klusteret containers does set limits. This will be worked around in 4.8 but in 4.9 a proper solution is required to deal with these exceptions. In addition, the desire in the future is to support different workload types which would require limit support.
Customer Considerations
Requested by telco customers
Documentation Considerations
No docs changed expected
Interoperability Considerations
No impact on other projects expected
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
Workload partitioning currently does not support mutating containers that have cpu limits. The workload partitioning admission plugin will skip those over those containers.
The original premise was that all ocp pods did not set limits, however it has been found that at least one klusteret containers does set limits. This will be worked around in 4.8 but in 4.9 a proper solution is required to deal with these exceptions. In addition, the desire in the future is to support different workload types which would require limit support.
Summary of changes:
1) Add another annotation to the crio drop in to represent the limit, "cpuquota"
[crio.runtime.workloads.management]
activation_annotation = "target.workload.openshift.io/management"
annotation_prefix = "resources.workload.openshift.io"
resources = { "cpushares" = 0, "cpuquota"=0, "cpuset" = "0-1,52-53" }
2) Modify the admission plugin to take cpu limits and add a cpuquota annotation. The cpu limits would be stripped. A new annotation or extend the existing one i.e.
annotations:
resources.workload.openshift.io/foo: {"cpushares": 20, "cpuquota": 50}
3) Modify crio to set cfs.quota for the contatiner to the value of cpuquota
Assumption:
4.8 -> 4.9 SNO upgrades are not supported therefore the upgrades scenario will not have to be dealt with.
Why is this important?
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- All SNO CI jobs must be at 95% pass rate or better.
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions:
Done Checklist
- CI - CI is running, tests are automated and merged.
Feature Overview (aka. Goal Summary)
The default OpenShift installation on AWS uses multiple IPv4 public IPs which Amazon will start charging for starting in February 2024. As a result, there is a requirement to find an alternative path for OpenShift to reduce the overall cost of a public cluster while this is deployed on AWS public cloud.
Goals (aka. expected user outcomes)
Provide an alternative path to reduce the new costs associated with public IPv4 addresses when deploying OpenShift on AWS public cloud.
Requirements (aka. Acceptance Criteria):
There is a new path for "external" OpenShift deployments on AWS public cloud where the new costs associated with public IPv4 addresses have a minimum impact on the total cost of the required infrastructure on AWS.
Background
Ongoing discussions on this topic are happening in Slack in the #wg-aws-ipv4-cost-mitigation private channel
Documentation Considerations
Usual documentation will be required in case there are any new user-facing options available as a result of this feature.
Epic Goal
- Implement support in the install config to receive a Public IPv4 Pool ID and create resources* which consumes Public IP when publish strategy is "External".
- The implementation must cover the installer changes in Terraform to provision the infrastructure
*Resources which consumes public IPv4: bootstrap, API Public NLB, Nat Gateways
Why is this important?
- The default OpenShift installation on AWS uses multiple IPv4 public IPs which Amazon will start charging for starting in February 2024.
Scenarios
- As a customer with BYO Public IPv4 pools in AWS, I would like to install OpenShift cluster on AWS consuming public IPs for my own CIDR blocks, so I can have control of IPs used by my the services provided by me and will not be impacted by AWS Public IPv4 charges
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- Will the terraform implementation be backported to supported releases to be used in CI for previous e2e test infra?
- Is there a method to use the pool by default for all Public IPv4 claims from a given VPC/workload? So the implementation doesn't need to create EIP and associations for each resource and subnet/zone.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
USER STORY:
- As a customer with custom Public IPv4 blocks presented in AWS, I would like to install OpenShift clusters on AWS with publish strategy Public consuming public IPv4 blocks from my own pool, so I will not be impacted by additional Public IPv4 charges
DESCRIPTION:
<!--
Provide as many details as possible, so that any team member can pick it up
and start to work on it immediately without having to reach out to you.
-->
Required:
- e2e workflow with a presubmit job testing the new configuration
Nice to have:
...
ACCEPTANCE CRITERIA:
- Installer PR reviewed, accepted and merged
- e2e step testing the PR
- Presubmit job testing that flow (frequency should be defined by Test platform team)
ENGINEERING DETAILS:
-
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
Support EgressIP feature with ExternalTrafficPolicy=Local and External2Pod direct routing in OVNKubernetes.
Why is this important?
We see a lot of customers using Multi-Egress Gateway with EgressIP.
Currently, connections which reaches pod via the OVN routing gateway are send back via EgressIP if it is associated with the specific namespace.
Multiple bugs have been reported by customers:
https://issues.redhat.com/browse/OCPBUGS-16792
https://issues.redhat.com/browse/OCPBUGS-7454
https://issues.redhat.com/browse/OCPBUGS-18400
Also, resulting in filing RFE, as it was too complicated to be fixed via a bug.
https://issues.redhat.com/browse/RFE-4614
https://issues.redhat.com/browse/RFE-3944
This is observed by multiple customers using MetalLB and F5 load balancers. We haven't really tested this combination.
From the initial discussion, looks like the fix is needed in OVN. Request the team to expedite this fix, given it has bunch of customers hitting it.
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
 Priority+ is set by engineering
Priority+ is set by engineering- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
- OVN team has to do https://issues.redhat.com/browse/FDP-42 and only then can we consume that into OVNKubernetes
- Design discussions Doc: https://docs.google.com/document/d/1VgDuEhkDzNOjIlPtwfIhEGY1Odatp-rLF6Pmd7bQtt0/edit
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview{}
Rename OpenShift update channels:
- Reposition Conditional Update Risks as “Known Issues”, and reduce UX differentiation
- Remove references to “supported but not recommended” in UX and CLI
- Conditional update experience improved in the UX
Do not hide conditional updates. Better to show all the OCP versions in the UI and not hide them.
Epic Goal*
Rename “supported but not recommended” to "known issues"
Why is this important? (mandatory)
What are the benefits to the customer or Red Hat? Does it improve security, performance, supportability, etc? Why is work a priority?
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Tests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Other
oc adm upgrade {}include-not-recommended{-} today includes a Supported but not recommended updates: header when introducing those updates. It also renders the Recommended condition. OTA-1191 is about what to do with the -include-not-recommended flag. This ticket is about addressing the header and possibly about adjusting/contextualizing/something the Recommended condition type.
Here is a current output
$ oc adm upgrade --include-not-recommended Cluster version is 4.10.0-0.nightly-2021-12-23-153012 Upstream: https://raw.githubusercontent.com/wking/cincinnati-graph-data/cincinnati-graph-for-targeted-edge-blocking-demo/cincinnati-graph.json Channel: stable-4.10 Recommended updates: VERSION IMAGE 4.10.0-always-recommended quay.io/openshift-release-dev/ocp-release@sha256:0000000000000000000000000000000000000000000000000000000000000000 Supported but not recommended updates: Version: 4.10.0-conditionally-recommended Image: quay.io/openshift-release-dev/ocp-release@sha256:1111111111111111111111111111111111111111111111111111111111111111 Recommended: Unknown Reason: EvaluationFailed Message: Exposure to SomeChannelThing is unknown due to an evaluation failure: client-side throttling: only 16.3µs has elapsed since the last match call completed for this cluster condition backend; this cached cluster condition request has been queued for later execution On clusters with the channel set to 'buggy', this imaginary bug can happen. https://bug.example.com/b Version: 4.10.0-fc.2 Image: quay.io/openshift-release-dev/ocp- release@sha256:85c6ce1cffe205089c06efe363acb0d369f8df7ad48886f8c309f474007e4faf Recommended: False Reason: ModifiedAWSLoadBalancerServiceTags Message: On AWS clusters for Services in the openshift-ingress namespace… This will not cause issues updating between 4.10 releases. This conditional update is just a demonstration of the conditional update system. https://bugzilla.redhat.com/show_bug.cgi?id=2039339
Definition of done:
- Replace "Supported but not recommended updates" with "Updates with known issues" https://github.com/openshift/oc/blob/79dc671bdaeafa74b92f14ad9f6d84e344608034/pkg/cli/admin/upgrade/upgrade.go#L455
- Should we also remove the "Recommended: False" or "Recommended: Unknown" from the output?
After this change the output will look similar to below
$ oc adm upgrade --include-not-recommended Cluster version is 4.10.0-0.nightly-2021-12-23-153012 Upstream: https://raw.githubusercontent.com/wking/cincinnati-graph-data/cincinnati-graph-for-targeted-edge-blocking-demo/cincinnati-graph.json Channel: stable-4.10 Recommended updates: VERSION IMAGE 4.10.0-always-recommended quay.io/openshift-release-dev/ocp-release@sha256:0000000000000000000000000000000000000000000000000000000000000000 Updates with known issues: Version: 4.10.0-conditionally-recommended Image: quay.io/openshift-release-dev/ocp-release@sha256:1111111111111111111111111111111111111111111111111111111111111111 Recommended: Unknown Reason: EvaluationFailed Message: Exposure to SomeChannelThing is unknown due to an evaluation failure: client-side throttling: only 16.3µs has elapsed since the last match call completed for this cluster condition backend; this cached cluster condition request has been queued for later execution On clusters with the channel set to 'buggy', this imaginary bug can happen. https://bug.example.com/b Version: 4.10.0-fc.2 Image: quay.io/openshift-release-dev/ocp-release@sha256:85c6ce1cffe205089c06efe363acb0d369f8df7ad48886f8c309f474007e4faf Recommended: False Reason: ModifiedAWSLoadBalancerServiceTags Message: On AWS clusters for Services in the openshift-ingress namespace… This will not cause issues updating between 4.10 releases. This conditional update is just a demonstration of the conditional update system. https://bugzilla.redhat.com/show_bug.cgi?id=2039339
Feature Overview
OCP 4 clusters still maintain pinned boot images. We have numerous clusters installed that have boot media pinned to first boot images as early as 4.1. In the future these boot images may not be certified by the OEM and may fail to boot on updated datacenter or cloud hardware platforms. These "pinned" boot images should be updateable so that customers can avoid this problem and better still scale out nodes with boot media that matches the running cluster version.
In phase 1 provided tech preview for GCP.
In phase 2, GCP support goes to GA. Support for other IPI footprints is new and tech preview.
Requirements
This will pick up stories left off from the initial Tech Preview(Phase 1): https://issues.redhat.com/browse/MCO-589
We'll want to add some tests to make sure the managing bootimages hasn't broken our existing functionality and that our new feature works. Proposed flow:
- opt in an existing machineset to updates
- update a GCP machineset with a dummy "bootimage"
- wait for machineset to be reconciled
- check if the machineset is restored to original value
- if it matches -> success
1/30/24: Updated based on enhancement discussions
This is the MCO side of the changes. Once the API PR lands, the MSBIC should start watching for the new API object.
It is also important to note that MachineSets having an ownerreference should not opted in to this mechanism, even if they are opt-ed in via the API. See discussion here: https://github.com/openshift/enhancements/pull/1496#discussion_r1463386593
Done when:
- user has a way to switch update mechanism on and off
- MachineSets with an OwnerRef are ignored.
Update 3/26/24 - Moved ValidatingAdmissionPolicy bit into a separate story as that got a bit more involved.
The MachineSetBootImage Controller will create an alert if there are excessive failures to patch a MachineSet.
This will be implemented via a global knob in the API. This is required in addition to the feature gate as we expect customers to still want to toggle this feature when it leave tech preview.
Done when:
- a new API object is created for opting in machine resources
A ValidatingAdmissionPolicy should be implemented(via an MCO manifest) for changes to this new API object, so that the feature is not turned on in unsupported platforms. The only platform currently supported is GCP. The ValidationAdmissionPolicy is kube native and is behind its own feature gate, so this will have to be checked while applying these manifests. Here is what the YAML of what these manifests would look like:
--- apiVersion: admissionregistration.k8s.io/v1beta1 kind: ValidatingAdmissionPolicy metadata: name: "managed-bootimages-platform-check" spec: failurePolicy: Fail paramKind: apiVersion: config.openshift.io/v1 kind: Infrastructure matchConstraints: resourceRules: - apiGroups: ["operator.openshift.io"] apiVersions: ["v1"] operations: ["CREATE", "UPDATE"] resources: ["MachineConfiguration"] validations: - expression: "has(object.spec.ManagedBootImages) && param.status.platformStatus.Type == `GCP`" message: "This feature is only supported on these platforms: GCP" --- apiVersion: admissionregistration.k8s.io/v1beta1 kind: ValidatingAdmissionPolicyBinding metadata: name: "managed-bootimages-platform-check-binding" spec: policyName: "managed-bootimages-platform-check" validationActions: [Deny] paramRef: name: "cluster" parameterNotFoundAction: "Deny"
In 4.15, before conducting the live migration, CNO will check if a cluster is managed by the SD team. We need to remove this checking for supporting unmanaged clusters.
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
As a cluster administrator, I would like to migrate my existing (that does not currently use Azure AD Workload Identity) cluster to use Azure AD Workload Identity
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
Many customers would like to migrate to Azure AD Workload Identity with minimal downtime but have numerous existing clusters and an aversion to supporting two concurrent operational requirements. Therefore they would like to migrate existing Azure clusters to take advantage of using Many customers would like to migrate to Azure Managed Identity but have numerous existing clusters and an aversion to supporting two concurrent operational requirements. Therefore they would like to migrate existing Azure clusters to Managed Identity in a safe manner after they have been upgraded to a version of OCP supporting that feature (4.14+) in a safe manner after they have been upgraded to a version of OCP supporting that feature (4.14+).
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Provide a documented method for migration to Azure AD Workload Identity for OpenShift 4.14+ with minimal downtime, and without customers having to start over with a new cluster using AZ Workload Identity and migrating over their workload. If there is risk of workload disruptive or downtime, we will keep to inform customers of this risk and have them accept this risk.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Self-managed |
| Classic (standalone cluster) | Classic |
| Hosted control planes | N/A |
| Multi node, Compact (three node), or Single node (SNO), or all | All |
| Connected / Restricted Network, or all | All |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | All applicable architectures |
| Operator compatibility | |
| Backport needed (list applicable versions) | 4.14+ |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | N/A |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Goal
Spike to evaluate if we can provide an automated way to support migration to Azure Managed Identity (preferred), or alternatively a manual method (second option) for customers to perform the migration themselves that is documented and supported, or not at all.
This spike will evaluate, scope the level of effort (sizing), and make recommendation on next steps.
Feature request
Support migration to Azure Managed Identity
Feature description
Many customers would like to migrate to Azure Managed Identity but have numerous existing clusters and an aversion to supporting two concurrent operational requirements. Therefore they would like to migrate existing Azure clusters to Managed Identity in a safe manner after they have been upgraded to a version of OCP supporting that feature (4.14+).
Why?
Provide a uniform operational experience for all clusters running versions which support Azure Managed Identity without having to decommission long running clusters
Other considerations
- Disruption to customer's workload.
- Has to be closely coordinated with update effort to minimize disruption.
- Tokenized operators and other layered products - work not yet done (OCP 4.15/4.16 plans) and has to be manually done for now and may not cover the full set.
- If we grant this for Azure MI/WI, we will likely will need to also do this for STS and GCP WIF.
- If we grant this, would we do this for self-managed and managed OpenShift (ARO)?
The cloud-credential-operator repository documentation can be updated for installing and/or migrating a cluster with Azure workload identity integration.
- The document currently uses manually numbered lists, which creates more work when we want to add/remove steps. Migrating the document to use dynamically numbered lists where each number is (1.) will remove this extra work in future changes.
- During installation, we can take advantage of the new(ish) --included parameter in the `oc adm extract release-images` command by creating an install-config prior to executing the command.
- During migration, we can take advantage of the new(ish) `reboot-machine-config-pool` sub-command of `oc adm` to restart all of the pods on a cluster to reduce the risks. The sub-command restarts each node in series resulting in highly available services being restarted one pod at a time.
Feature Overview (aka. Goal Summary)
Add support for Johannesburg, South Africa (africa-south1) in GCP
Goals (aka. expected user outcomes)
As a user I'm able to deploy OpenShift in Johannesburg, South Africa (africa-south1) in GCP and this region is fully supported
Requirements (aka. Acceptance Criteria):
A user can deploy OpenShift in GCP Johannesburg, South Africa (africa-south1) using all the supported installation tools for self-managed customers.
The support of this region is backported to the previuos OpenShift EUS release.
Background
Google Cloud has added support for a new region in their public cloud offering and this region needs to be supported for OpenShift deployments as other regions.
Documentation Considerations
The information of the new region needs to be added to the documentation so this is supported.
Goal of this feature is to add support to
- telemetry
- nmstate ipv6
- nmstate net2net
Why is this important?
- without API, customers are forced to use MCO. this brings with it a set of limitations (mainly reboot per change and the fact that config is shared among each pool, can't do per node configuration)
- better upgrade solution will give us the ability to support a single host based implementation
- telemetry will give us more info on how widely is ipsec used.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Must allow for the possibility of offloading the IPsec encryption to a SmartNIC.
- nmstate
- k8s-nmstate
- easier mechanism for cert injection (??)
- telemetry
- improve ci and test coverage
Dependencies (internal and external)
- nmstate tasks
Related:
- ITUP-44 - OpenShift support for North-South OVN IPSec
HATSTRAT-33- Encrypt All Traffic to/from Cluster (aka IPSec as a Service)
Previous Work (Optional):
SDN-717- Support IPSEC on ovn-kubernetesSDN-3604- Fully supported non-GA N-S IPSec implementation using machine config.
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- telemetry
- nmstate ipv6
- nmstate net2net
Why is this important?
- without API, customers are forced to use MCO. this brings with it a set of limitations (mainly reboot per change and the fact that config is shared among each pool, can't do per node configuration)
- better upgrade solution will give us the ability to support a single host based implementation
- telemetry will give us more info on how widely is ipsec used.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Must allow for the possibility of offloading the IPsec encryption to a SmartNIC.
- nmstate
- k8s-nmstate
- easier mechanism for cert injection (??)
- telemetry
- improve ci and test coverage
Dependencies (internal and external)
- nmstate tasks
Related:
- ITUP-44 - OpenShift support for North-South OVN IPSec
HATSTRAT-33- Encrypt All Traffic to/from Cluster (aka IPSec as a Service)
Previous Work (Optional):
SDN-717- Support IPSEC on ovn-kubernetesSDN-3604- Fully supported non-GA N-S IPSec implementation using machine config.
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
Add support for Dammam, Saudi Arabia, Middle East (me-central2) region in GCP
Goals (aka. expected user outcomes)
As a user I'm able to deploy OpenShift in Dammam, Saudi Arabia, Middle East (me-central2) region in GCP and this region is fully supported
Requirements (aka. Acceptance Criteria):
A user can deploy OpenShift in GCP Dammam, Saudi Arabia, Middle East (me-central2) region using all the supported installation tools for self-managed customers.
The support of this region is backported to the previuos OpenShift EUS release.
Background
Google Cloud has added support for a new region in their public cloud offering and this region needs to be supported for OpenShift deployments as other regions.
Documentation Considerations
The information of the new region needs to be added to the documentation so this is supported.
For more details: https://redhat-internal.slack.com/archives/C01CQA76KMX/p1710302543729539
Epic Goal*
Drive the technical part of the Kubernetes 1.29 upgrade, including rebasing openshift/kubernetes repositiry and coordination across OpenShift organization to get e2e tests green for the OCP release.
Why is this important? (mandatory)
OpenShift 4.17 cannot be released without Kubernetes 1.30
Scenarios (mandatory)
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
PRs:
- https://github.com/openshift/api/pull/1813
- https://github.com/openshift/client-go/pull/277
- https://github.com/openshift/library-go/pull/1695
- https://github.com/openshift/apiserver-library-go/pull/129
- https://github.com/openshift/cluster-kube-apiserver-operator/pull/1666
- https://github.com/openshift/cluster-kube-scheduler-operator/pull/540
- https://github.com/openshift/cluster-kube-controller-manager-operator/pull/803
- https://github.com/openshift/kubernetes/pull/1953
Feature Overview (aka. Goal Summary)
Base RHCOS for OpenShift 4.16 on RHEL 9.4 content.
Goals (aka. expected user outcomes)
New RHEL minors bring additional features and performance optimizations, and most importantly, new hardware enablement. Customers and partners need to be able to install on the latest hardware.
We want to start looking at testing OpenShift on RHCOS built from RHEL 9.4 packages. While it is currently possible to do most of that testing work using OKD-SCOS, only the x86_64 architecture is available there. We'll publish OCP release images and boot images that include RHCOS builds made out of CentOS Stream packages to prepare for the RHEL 9.4 release.
Summary of the steps:
1. Add manifests for a new rhel-9.4 variant in openshift/os, based on the existing manifests for rhel-9.2 and c9s. We'll use as much C9S packages as possible and re-use existing OpenShift specific packages.
2. Update the staging pipeline configuration to add a 4.15-9.4 stream.
3. Trigger an RHCOS build and use it to replace an existing image from a nightly OCP release image. Upload this release image to the rhcos-devel namespace on registry.ci.openshift.org
4. Ask for as many people as possible to test this release image. Write an email to aos-devel, publish updated instructions in this Epic, publish the same instructions in the Slack channel.
5. Repeat steps 3 and 4 every two weeks
Discussed this with Michael Nguyen
This would work and ensure that we don't promote a release publicly with 9.4 GA content prior to RHEL 9.4 GA on April 30th
- April 23 4.16.0-ec.6 nightly selected, RHCOS is based on public 9.4 Beta
- April 24-25 RHCOS switches from 9.4 Beta repos to 9.4 GA repos
- April 26 4.16.0-ec.6 promoted and 4.16 branched from master assuming green 4.17 nightlies
- April 30 - RHEL 9.4 GA
- May 03 fist 4.16 RC on RHEL 9.4 GA
The thing we want to be careful about is checking in selection of 4.16.0-ec.6 which should be tracked via https://issues.redhat.com/browse/FDN-623 but we could just reach out to TRT team on #forum-ocp-release-oversight to confirm. This is because we don't want to switch to 9.4 GA content until the EC build which will be made public ahead of 9.4 GA has been selected.
Feature Overview (aka. Goal Summary)
Graduate the etcd tuning profiles feature delivered in https://issues.redhat.com/browse/ETCD-456 to GA
Goals (aka. expected user outcomes)
Remove the feature gate flag and ,ake the feature accessible to all customers
Requirements (aka. Acceptance Criteria):
Requires fixes to apiserver to handle etcd client retries correctly
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | yes |
| Classic (standalone cluster) | yes |
| Hosted control planes | no |
| Multi node, Compact (three node), or Single node (SNO), or all | Multi node and compact clusters |
| Connected / Restricted Network | Yes |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | Yes |
| Operator compatibility | N/A |
| Backport needed (list applicable versions) | N/A |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | N/A |
| Other (please specify) | N/A |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Epic Goal*
Graduate the etcd tuning profiles feature delivered in https://issues.redhat.com/browse/ETCD-456 to GA
https://github.com/openshift/api/pull/1538
https://github.com/openshift/enhancements/pull/1447
Why is this important? (mandatory)
Graduating the feature to GA makes it accessible to all customers and not hidden behind a feature gate.
As further outlined in the linked stories the major roadblock for this feature to GA is to ensure that the API server has the necessary capability to configure its etcd client for longer retries on platforms with slower latency profiles. See: https://issues.redhat.com/browse/OCPBUGS-18149
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- As an openshift admin I can change the latency profile of the etcd cluster without causing any downtime to the control-plane availability
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - etcd
- Documentation - etcd docs team
- QE - etcd qe
- PX -
- Others -
Acceptance Criteria (optional)
Once the cluster is installed, we should be able to change the default latency profile on the API to a slower one and verify that etcd is rolled out with the updated leader election and heartbeat timeouts. During this rollout there should be no disruption or unavailability to the control-plane.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
The linked issue was slated to be released in 4.16, but missed the branch date due to a late merge conflict. This bug tracks the backporting of this slated feature to 4.16
Once https://issues.redhat.com/browse/ETCD-473 is done this story will track the work required to move the "operator/v1 etcd spec.hardwareSpeed" field from behind the feature gate to GA.
Feature Overview (aka. Goal Summary)
Graduate the etcd tuning profiles feature delivered in https://issues.redhat.com/browse/ETCD-456 to GA
Goals (aka. expected user outcomes)
Remove the feature gate flag and ,ake the feature accessible to all customers
Requirements (aka. Acceptance Criteria):
Requires fixes to apiserver to handle etcd client retries correctly
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | yes |
| Classic (standalone cluster) | yes |
| Hosted control planes | no |
| Multi node, Compact (three node), or Single node (SNO), or all | Multi node and compact clusters |
| Connected / Restricted Network | Yes |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | Yes |
| Operator compatibility | N/A |
| Backport needed (list applicable versions) | N/A |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | N/A |
| Other (please specify) | N/A |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
<your text here>
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
<your text here>
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
<your text here>
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
Feature Overview (aka. Goal Summary)
Enable Hosted Control Planes guest clusters to support up to 500 worker nodes. This enable customers to have clusters with large amount of worker nodes.
Goals (aka. expected user outcomes)
Max cluster size 250+ worker nodes (mainly about control plane). See XCMSTRAT-371 for additional information.
Service components should not be overwhelmed by additional customer workloads and should use larger cloud instances and when worker nodes are lesser than the threshold it should use smaller cloud instances.
Requirements (aka. Acceptance Criteria):
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Managed |
| Classic (standalone cluster) | N/A |
| Hosted control planes | Yes |
| Multi node, Compact (three node), or Single node (SNO), or all | N/A |
| Connected / Restricted Network | Connected |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | x86_64 ARM |
| Operator compatibility | N/A |
| Backport needed (list applicable versions) | N/A |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | N/A |
| Other (please specify) |
Questions to Answer (Optional):
Check with OCM and CAPI requirements to expose larger worker node count.
Documentation:
- Design document detailing the autoscaling mechanism and configuration options
- User documentation explaining how to configure and use the autoscaling feature.
Acceptance Criteria
- Configure max-node size from CAPI
- Management cluster nodes automatically scale up and down based on the hosted cluster's size.
- Scaling occurs without manual intervention.
- A set of "warm" nodes are maintained for immediate hosted cluster creation.
- Resizing nodes should not cause significant downtime for the control plane.
- Scaling operations should be efficient and have minimal impact on cluster performance.
Goal
- Dynamically scale the serving components of control planes
Why is this important?
- To be able to have clusters with large amount of worker nodes
Scenarios
- A hosted cluster amount of worker nodes increases past X amount, the serving components are moved to larger cloud instances
- A hosted cluster amount of workers falls below a threshold, the serving components are moved to smaller cloud instances.
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Description of problem:
HyperShift operator crashes with size tagging enabled and a clustersizingconfiguration that does not have an effects section under the size configuration.
Version-Release number of selected component (if applicable):
4.16.0
How reproducible:
Always
Steps to Reproduce:
1. Install hypershift operator with size tagging enabled
2. Create a hosted cluster with request serving isolation topology
3.
Actual results:
HyperShift operator crashes
Expected results:
Cluster creation succeeds
Additional info:
User Story:
When a HostedCluster is given a size label, it needs to ensure that request serving nodes exist for that size label and when they do, reschedule request serving pods to the appropriate nodes.
Acceptance Criteria:
Description of criteria:
- HostedClusters reconcile the content of hypershift.openshift.io/request-serving-node-additional-selector label
- Reschedule the request serving pods to run to instances matching the label
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
Description of problem
When provisioning an HCP on an MC enabled with sizing enabled (that has no existing HCPs) HCP install can be stuck trying to schedule the kube-apiserver for the hosted control plane. It seems the the placeholder deployment cannot be created, because of an empty selector value in the NodeAffinity:
operator-56b7ccb598-4hqz4 operator {"level":"error","ts":"2024-04-23T13:35:42Z","msg":"Reconciler error","controller":"DedicatedServingComponentSchedulerAndSi zer","controllerGroup":"hypershift.openshift.io","controllerKind":"HostedCluster","HostedCluster":{"name":"dry3","namespace":"ocm-staging-2aqkcjamdtbcmjtp0lk1 il3vo9hfd4n1"},"namespace":"ocm-staging-2aqkcjamdtbcmjtp0lk1il3vo9hfd4n1","name":"dry3","reconcileID":"0772c093-ceef-46c1-a450-6bc8184ba633","error":"failed t o ensure placeholder deployment: Deployment.apps \"ocm-staging-2aqkcjamdtbcmjtp0lk1il3vo9hfd4n1-dry3\" is invalid: spec.template.spec.affinity.nodeAffinity.re quiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms[0].matchExpressions[0].values: Required value: must be specified when `operator` is 'In' or 'No tIn'","stacktrace":"sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).reconcileHandler\n\t/opt/app-root/src/vendor/sigs.k8s.io/controller-r untime/pkg/internal/controller/controller.go:329\nsigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).processNextWorkItem\n\t/opt/app-root/sr c/vendor/sigs.k8s.io/controller-runtime/pkg/internal/controller/controller.go:266\nsigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).Start. func2.2\n\t/opt/app-root/src/vendor/sigs.k8s.io/controller-runtime/pkg/internal/controller/controller.go:227"}
This appears to be due the the In selector of the nodeAffinity being populated with an empty list in the source: https://github.com/openshift/hypershift/blob/main/hypershift-operator/controllers/scheduler/dedicated_request_serving_nodes.go#L704
The value of unavailableNodePairs can be an empty list in the case that no HCPs exist on the cluster already, and therefore no nodes are labelled with both a cluster and a serving pair label. In this case, the empty list is passed in the NodeAffinity and results in the error above
User Story:
As a service provider, I want to be able to:
- Configure priority and fairness settings per HostedCluster size and force these settings to be applied on the resulting hosted cluster.
so that I can achieve
- Prevent user of hosted cluster from bringing down the HostedCluster kube apiserver with their workload.
Acceptance Criteria:
Description of criteria:
- HostedCluster priority and fairness settings should be configurable per cluster size in the ClusterSizingConfiguration CR
- Any changes in priority and fairness inside the HostedCluster should be prevented and overridden by whatever is configured on the provider side.
- With the proper settings, heavy use of the API from user workloads should not result in the KAS pod getting OOMKilled due to lack of resources.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Description of problem:
When a single placeholder is created for a request serving node (because a previous node existed of the same size), no machineset scale up occurs.
Version-Release number of selected component (if applicable):
4.16.0
How reproducible:
Always
Steps to Reproduce:
1. Setup a management cluster with request serving and autoscaling machinesets
2. Create a HostedCluster of size small
3. Manually scale up the corresponding large machineset (in same osdfleetmanager pair)
4. Increase the HostedCluster size to large
Actual results:
The large machinesets are never scaled up for the cluster
Expected results:
The hosted cluster moves up to large machines for request serving
Additional info:
When a single placeholder is created for request serving nodes, no machineset scale up occurs.
Description of problem:
For large cluster sizes, non-request serving pods such as OVN, etcd, etc. require more resources. Because these pods live in the same nodes as other hosted cluster's non-request serving pods, we can run into resource exhaustion unless requests for these pods are properly sized.
Version-Release number of selected component (if applicable):
4.16
How reproducible:
Always
Steps to Reproduce:
1. Create large hosted cluster (200+ nodes)
2. Observe resource usage of non-request-serving pods
Actual results:
Resource usage is large, while resource requests remain the same
Expected results:
Resource request grows corresponding to cluster size
Additional info:
User Story:
As the HyperShift scheduler, I want to be able to:
- see the size of each HostedCluster as translated to "t-shirt" sizes
so that I can achieve
- correct scheduling outcomes and warm-node reserve
As the HyperShift administrator, I want to be able to:
- configure how the size of each HostedCluster is translated to "t-shirt" sizes
- configure how often the size of each HostedCluster is translated to "t-shirt" sizes, both as the size gets larger and as it gets smaller
so that I can achieve
- tuning for auto-scaling of my management cluster
Acceptance Criteria:
Description of criteria:
- allow configuration for sizing buckets and sizing change throughput
- document the configuration above
- expose t-shirt sizes of hosted clusters
Engineering Details:
![]() This requires a design proposal.
This requires a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
User Story:
As a HyperShift controller in the management plane, I want to be able to:
- read the capacity of a cluster measured in the count of nodes from a HostedControlPlane or HostedCluster
so that I can achieve
- automation that reacts to the number of cluster workers changing at runtime
Acceptance Criteria:
Description of criteria:
- the count of nodes can be read from the HostedCluster or HostedControlPlane status
Engineering Details:
![]() This requires a design proposal.
This requires a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
Description of problem:
When using cluster size tagging and related request serving node scheduler, if a cluster is deleted while in the middle of resizing its request serving pods, the placeholder deployment that was created for it is not cleaned up.
Version-Release number of selected component (if applicable):
HyperShift main (4.16)
How reproducible:
Always
Steps to Reproduce:
1. Setup a management cluster with request-serving machinesets
2. Create a hosted cluster
3. Add workers to the hosted cluster so that it changes size
4. Delete the hosted cluster after the it's tagged with the new size but before nodes for its corresponding placeholder pods are created.
Actual results:
The placeholder deployment is never removed from the `hypershift-request-serving-autosizing-placeholder` namespace
Expected results:
The placeholder deployment is removed when the cluster is deleted.
Additional info:
Feature Overview (aka. Goal Summary)
Allow supporting RWX block PVCs with kubevirt csi when the underlying infra storageclass supports RWX Block
Goals (aka. expected user outcomes)
Requirements (aka. Acceptance Criteria):
- Allow users to create RWX Block PVCs withing HCP KubeVIrt guest clusters when the underlying infra storage class mapped to the guest supports RWX Block
- Add presubmit and conformance periodics exercising HCP KubeVirt with RWX Block pvcs in guest.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | self-managed |
| Classic (standalone cluster) | no |
| Hosted control planes | yes |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
Questions to Answer (Optional):
Out of Scope
Background
Customer Considerations
Documentation Considerations
This feature should be documented as a capability of HCP OpenShift Virtualization in the ACM HCP docs
Interoperability Considerations
Currently, kubevirt-csi is limited to ReadWriteOnce for the pvcs within the guest cluster. This is true even when the infra storageclass supports RWX.
We should expand the ability for the guest cluster to use RWX block when the underlying infra storage class supports RWX block
Currently, kubevirt-csi is limited to ReadWriteOnce for the pvcs within the guest cluster. This is true even when the infra storageclass supports RWX.
We should expand the ability for the guest cluster to use RWX when the underlying infra storage class supports RWX
Feature Overview
Move to using the upstream Cluster API (CAPI) in place of the current implementation of the Machine API for standalone Openshift
prerequisite work Goals completed in OCPSTRAT-1122
{}Complete the design of the Cluster API (CAPI) architecture and build the core operator logic needed for Phase-1, incorporating the assets from different repositories to simplify asset management.
Phase 1 & 2 covers implementing base functionality for CAPI.
Background, and strategic fit
- Initially CAPI did not meet the requirements for cluster/machine management that OCP had the project has moved on, and CAPI is a better fit now and also has better community involvement.
- CAPI has much better community interaction than MAPI.
- Other projects are considering using CAPI and it would be cleaner to have one solution
- Long term it will allow us to add new features more easily in one place vs. doing this in multiple places.
Acceptance Criteria
There must be no negative effect to customers/users of the MAPI, this API must continue to be accessible to them though how it is implemented "under the covers" and if that implementation leverages CAPI is open
sets up CAPI ecosystem for vSphere
So far we haven't tested this provider at all. We have to run it and spot if there are any issues with it.
Steps:
- Try to run the vSphere provider on OCP
- Try to create MachineSets
- Try various features out and note down bugs
- Create stories for resolving issues up stream and downstream
Outcome:
- Create stories in epic of items for vSphere that need to be resolved
vSphere provider is not present in downstream operator, someone has to add it there.
This will include adding a tech preview e2e job in release repo and going through the process described here https://github.com/openshift/cluster-capi-operator/blob/main/docs/provideronboarding.md
Feature Overview (aka. Goal Summary)
Enable selective management of HostedCluster resources via annotations, allowing hypershift operators to operate concurrently on a management cluster without interfering with each other. This feature facilitates testing new operator versions or configurations in a controlled manner, ensuring that production workloads remain unaffected.
Goals (aka. expected user outcomes)
- Primary User Type/Persona: Cluster Service Providers
- Observable Functionality: Administrators can deploy "test" and "production" hypershift operators within the same management cluster. The "test" operator will manage only those HostedClusters annotated according to a predefined specification, while the "production" operator will ignore these annotated HostedClusters, thus maintaining the integrity of existing workloads.
Requirements (aka. Acceptance Criteria):
- The "test" operator must respond only to HostedClusters that carry a specific annotation defined by the HOSTEDCLUSTERS_SCOPE_ANNOTATION environment variable.
- The "production" operator must ignore HostedClusters with the specified annotation.
- The feature is activated via the ENABLE_HOSTEDCLUSTERS_ANNOTATION_SCOPING environment variable. When not set, the operators should behave as they currently do, without any annotation-based filtering.
- Upstream documentation to describe how to set up and use annotation-based scoping, including setting environment variables and annotating HostedClusters appropriately.
- The solution should not impact the core functionality of HCP for self-managed and cloud-services (ROSA/ARO)
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | |
| Hosted control planes | Applicable |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
- Testing new versions or configurations of hypershift operators without impacting existing HostedClusters.
- Gradual rollout of operator updates to a subset of HostedClusters for performance and compatibility testing.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
- Automatic migration of HostedClusters between "test" and "production" operators.
- Non-IBM integrations (e.g., MCE)
Background
Current hypershift operator functionality does not allow for selective management of HostedClusters, limiting the ability to test new operator versions or configurations in a live environment without affecting production workloads.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
<your text here>
Documentation Considerations
Upstream only for now
Interoperability Considerations
- The solution should not impact the core functionality of HCP for self-managed and cloud-services (ROSA/ARO)
As a mgmt cluster admin, I want to be able to run multiple hypershift-operators that operate on a disjoint set of HostedClusters.
Feature Overview (aka. Goal Summary)
Create an Installer RHEL9-based build for FIPS-enabled OpenShift installations
Goals (aka. expected user outcomes)
As a user, I want to enable FIPS while deploying OpenShift on any platform that supports this standard, so the resultant cluster is compliant with FIPS security standards
Requirements (aka. Acceptance Criteria):
Provide a dynamically linked build of the Installer for RHEL 9 in the release payload
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | both |
| Classic (standalone cluster) | yes |
| Hosted control planes | n/a |
| Multi node, Compact (three node), or Single node (SNO), or all | all |
| Connected / Restricted Network | all |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all |
| Operator compatibility | |
| Backport needed (list applicable versions) | no |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | OCM |
| Other (please specify) |
Documentation Considerations
Docs will need to guide the Installer binary to use for FIPS-enabled clusters
Epic Goal
- Provide a dynamically-linked build of the installer for RHEL 9 in the release payload
Why is this important?
- RHEL 9 is out and users are switching to it
- When the host is in FIPS mode, a dynamically-linked build of the installer is required
- RHEL 8 & 9 have different versions of OpenSSL, so there's no one build that can work on both.
Scenarios
- Installing a FIPS mode cluster with the installer running on RHEL 9 with FIPS enabled
- Installing a baremetal IPI cluster with the installer running on RHEL 9
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- Do we need to build for both RHEL 8 & RHEL 9, or could we just switch the build to RHEL 9 at this point?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
As a user with no FIPS requirement, I want to be able to use the same openshift-installer binary on both RHEL 8 and RHEL 9, as well as other common Linux distributions.
Currently to use baremetal IPI, a user must retrieve the openshift-baremetal-installer binary from the release payload. Historically, this was due to it needing to dynamically link to libvirt. This is no longer the case, so we can make baremetal IPI available in the standard openshift-installer binary.
libvirt is not a supported platform for openshift-installer. Nonetheless, it appears in the platforms list (likely inadvertently?) when running the openshift-baremetal-installer binary because the code for it was enabled in order to link against libvirt.
Now that linking against libvirt is no longer required, there is no reason to continue shipping this unsupported code.
We will need to come up with a separate build tag to distinguish between the openshift-baremetal-install (dynamic) and openshift-install (static) builds. Currently these are distinguished by the libvirt tag.
Allow the user to do oc release extract --command=openshift-install-fips to obtain an installer binary that is FIPS-ready.
The binary extracted will be the same one as is extracted when the command is openshift-baremetal-install; this name is provided for convenience.
As a user, I want to know how to download and use the correct installer binary to install a cluster with FIPS mode enabled. If I use the wrong binary or don't have FIPS enabled, I need instructions at the point I am trying to create a FIPS-mode cluster.
User Story:
As a customer, I want to be able to:
- Have installer binaries in the release payload based on RHEL9
so that I can achieve
- RHEL9 clients showing up on https://access.redhat.com/downloads/content/290/ver=4.13/rhel---9/4.13/x86_64/product-software
- running a 4.16 Installer on a FIPS-enabled RHEL9 host succeeds
Acceptance Criteria:
Description of criteria:
- A new Dockerfile, similar to https://github.com/openshift/installer/blob/master/images/installer-artifacts/Dockerfile.rhel but RHEL9-based
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
Feature Overview
Adding nodes to on-prem clusters in OpenShift in general is a complex task. We have numerous methods and the field keeps adding automation around these methods with a variety of solutions, sometimes unsupported (see "why is this important below"). Making cluster expansions easier will let users add nodes often and fast, leading to an much improved UX.
This feature adds nodes to any on-prem clusters, regardless of their installation method (UPI, IPI, Assisted, Agent), by booting an ISO image that will add the node to the cluster specified by the user, regardless of how the cluster was installed.
Goals and requirements
- Users can install a host on day 2 using a bootable image to an OpenShift cluster.
- At least platforms baremetal, vSphere, none and Nutanix are supported
- Clusters installed with any installation method can be expanded with the image
- Clusters don't need to run any special agent to allow the new nodes to join.
How this workflow could look like
1. Create image:
$ export KUBECONFIG=kubeconfig-of-target-cluster $ oc adm node-image -o agent.iso --network-data=worker-n.nmstate --role=worker
2. Boot image
3. Check progress
$ oc adm add-node
Consolidate options
An important goal of this feature is to unify and eliminate some of the existing options to add nodes, aiming to provide much simpler experience (See "Why is this important below"). We have official and field-documented ways to do this, that could be removed once this feature is in place, simplifying the experience, our docs and the maintenance of said official paths:
- UPI: Adding RHCOS worker nodes to a user-provisioned infrastructure cluster
- This feature will replace the need to use this method for the majority of UPI clusters. The current UPI method consists on many many manual steps. The new method would replace it by a couple of commands and apply to probably more than 90% of UPI clusters.
- Field-documented methods and asks
- Often we are asked about ways to do this or given different ways in which the field is automating this process in their own way. We can't control all aspects of these automations or how many there are, they are usually based on UPI, e.g.
- [gellner/expand-agent1.md|https://gist.github.com/gellner/f1f2928f847355ae80d0867884569109]
WKLD-433
- IPI:
- There are instances were adding a node to an bare metal IPI-deployed cluster can't be done via its BMC. This new feature, while not replacing the day-2 IPI workflow, solves the problem for this use case.
- MCE: Scaling hosts to an infrastructure environment
- This method is the most time-consuming and in many cases overkilling, but currently, along with the UPI method, is one of the two options we can give to users.
- We shouldn't need to ask users to install and configure the MCE operator and its infrastructure for single clusters as it becomes a project even larger than UPI's method and save this for when there's more than one cluster to manage.
With this proposed workflow we eliminate the need of using the UPI method in the vast majority of the cases. We also eliminate the field-documented methods that keep popping up trying to solve this in multiple formats, and the need to recommend using MCE to all on-prem users, and finally we add a simpler option for IPI-deployed clusters.
In addition, all the built-in validations in the assisted service would be run, improving the installation the success rate and overall UX.
This work would have an initial impact on bare metal, vSphere, Nutanix and platform-agnostic clusters, regardless of how they were installed.
Why is this important
This feature is essential for several reasons. Firstly, it enables easy day2 installation without burdening the user with additional technical knowledge. This simplifies the process of scaling the cluster resources with new nodes, which today is overly complex and presents multiple options (https://docs.openshift.com/container-platform/4.13/post_installation_configuration/cluster-tasks.html#adding-worker-nodes_post-install-cluster-tasks).
Secondly, it establishes a unified experience for expanding clusters, regardless of their installation method. This streamlines the deployment process and enhances user convenience.
Another advantage is the elimination of the requirement to install the Multicluster Engine and Infrastructure Operator , which besides demanding additional system resources, are an overkill for use cases where the user simply wants to add nodes to their existing cluster but aren't managing multiple clusters yet. This results in a more efficient and lightweight cluster scaling experience.
Additionally, in the case of IPI-deployed bare metal clusters, this feature eradicates the need for nodes to have a Baseboard Management Controller (BMC) available, simplifying the expansion of bare metal clusters.
Lastly, this problem is often brought up in the field, where examples of different custom solutions have been put in place by redhatters working with customers trying to solve the problem with custom automations, adding to inconsistent processes to scale clusters.
Oracle Cloud Infrastructure
This feature will solve the problem cluster expansion for OCI. OCI doesn't have MAPI and CAPI isn't in the mid term plans. Mitsubishi shared their feedback making solving the problem of lack of cluster expansion a requirement to Red Hat and Oracle.
Existing work
We already have the basic technologies to do this with the assisted-service and the agent-based installer, which already do this work for new clusters, and from which we expect to leverage the foundations for this feature.
Day 2 node addition with agent image.
Yet Another Day 2 Node Addition Commands Proposal
Enable day2 add node using agent-install: AGENT-682
Epic Goal
- Cleanup/carryover work from
AGENT-682for the GA release
Why is this important?
- Address all the required elements for the GA, such as the FIPS compliancy. This will allow a smoother integration of the node-joiner into the oc tool, as planned in
OCPSTRAT-784
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
- None
Previous Work (Optional):
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Modify dev-scripts and add a new job that tries to add a node to an existing cluster (using the scripts)
The first and second CSRs pending approval have the node name (hostname) embedded in their specs. monitor-add-nodes should only show CSRs pending approval for a specific node. Currently it shows all CSRs pending approval.
We can assume the hostname is provided in node-config.yaml. This allows us to tie a hostname to an IP address as both are required in node-config.yaml. If not provided, we can make best efforts to find the ip address of the node name using nslookup or an equivalent in golang.
Feature Overview (aka. Goal Summary)
Promote secure authentication methods in HCP CLI by deprecating the use of long-term `AWS credentials` and favoring STS assume role flows. This change aims to enhance security by encouraging the adoption of short-term token-based authentication, reducing the risk associated with promoting insecure usage patterns.
Goals (aka. expected user outcomes)
- Switch HCP CLI to STS mode to promote secure usage and discourage sudo creds.
Requirements (aka. Acceptance Criteria):
- Implement `sts` mode that strictly uses AWS STS for interacting with infrastructure.
- Deprecate the --aws-creds flag in the HCP CLI to discourage the use of long-term AWS credentials.
- Ensure that the HCP CLI provides clear error messages and guidance when deprecated methods are used
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | self-managed |
| Classic (standalone cluster) | |
| Hosted control planes | Yes |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | all |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | CLI |
| Other (please specify) |
Use Cases (Optional):
Admin initiates a setup command via the HCP CLI. The CLI automatically uses STS to assume a temporary role that has permission to create the necessary roles and policies for the new environment. Once the roles are in place, the CLI seamlessly continues the setup process.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Background
In light of security best practices and evolving compliance requirements, transitioning to STS assume role flows is important. This shift aims to align the HCP CLI with industry standards and security best practices.
Customer Considerations
Support must be provided to assist customers in transitioning from using long-term AWS credentials to STS. This includes comprehensive documentation and responsive support channels.
Documentation Considerations
Revise documentation sections related to authentication to remove references to long-term credential usage `--aws-creds` / deprecate it and emphasize STS assume role processes. Include examples and common troubleshooting tips.
Goal
- Promote secure authentication methods in HCP CLI by deprecating the use of long-term `AWS credentials` and favoring STS assume role flows. This change aims to enhance security by encouraging the adoption of short-term token-based authentication, reducing the risk associated with promoting insecure usage patterns.
Why is this important?
- promote secure usage and discourage sudo creds.
Scenarios
- ...
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
- Deprecate the --aws-creds flag and replace with --session-token and --role-arn
- Create/destroy command should use --session-token and --role-arn to call the AssumeRole API and acquire temp credentials to use when calling AWS services.
- collect/document all the permissions the CLI needs for create + destroy commands.
- create a new cmd to automate the creation of a role with the required permissions.
Feature Overview
With this feature MCE will be an additional operator ready to be enabled with the creation of clusters for both the AI SaaS and disconnected installations with Agent.
Currently 4 operators have been enabled for the Assisted Service SaaS create cluster flow: Local Storage Operator (LSO), OpenShift Virtualization (CNV), OpenShift Data Foundation (ODF), Logical Volume Manager (LVM)
The Agent-based installer doesn't leverage this framework yet.
Goals
When a user performs the creation of a new OpenShift cluster with the Assisted Installer (SaaS) or with the Agent-based installer (disconnected), provide the option to enable the multicluster engine (MCE) operator.
The cluster deployed can add itself to be managed by MCE.
Background, and strategic fit
Deploying an on-prem cluster 0 easily is a key operation for the remaining of the OpenShift infrastructure.
While MCE/ACM are strategic in the lifecycle management of OpenShift, including the provisioning of all the clusters, the first cluster where MCE/ACM are hosted, along with other supporting tools to the rest of the clusters (GitOps, Quay, log centralisation, monitoring...) must be easy and with a high success rate.
The Assisted Installer and the Agent-based installers cover this gap and must present the option to enable MCE to keep making progress in this direction.
Assumptions
MCE engineering is responsible for adding the appropriate definition as an olm-operator-plugins
See https://github.com/openshift/assisted-service/blob/master/docs/dev/olm-operator-plugins.md for more details
Feature Goal
As an OpenShift administrator I want to deploy OpenShift clusters with Assisted Installer that have the Multicluster Engine Operator (MCE) enabled with support for managing bare metal clusters.
As an OpenShift administrator I want to have the bare metal clusters deployed with the Assisted Installer managed by MCE, i.e. MCE managing its local cluster.
Definition of Done
- Assisted Installer allows enabling the MCE operator and configure it with the Infrastructure Operator
- The deployed clusters can deploy bare metal clusters from MCE successfully
- The deployed clusters are managed by MCE
- Documentation exists.
Feature Origin
MCE is strategic to OpenShift adoption in different scenarios. For Edge use cases it has ZTP to automate the provisioning of OpenShift clusters from a central cluster (hub cluster). MCE is also key for lifecycle management of OpenShift clusters. MCE is also available with the OpenShift subscriptions to every customer.
Additionally MCE will be key in the deployment of Hypershift, so it serves a double strategic purpose.
Lastly, day-2 operations on newly deployed clusters (without the need to manage multiple clusters), can be covered with MCE too.
We expect MCE to enable our customers to grow their OpenShift installation-base more easily and manage their lifecycle.
Reasoning
When enabling the MCE operator in the Assisted Installer we need to add the required storage with the installation to be able to use the Infrastructure Operator to create bare metal/vSphere/Nutanix clusters.
Automated storage configuration workflows
The Infrastructure Operator, a dependency of MCE to deploy bare metal, vSphere and Nutanix clusters, requires storage.
There are multiple scenarios:
- Install with ODF:
- ODF is the ideal storage for clusters but requires an additional subscriptions.
-
- When selected along with MCE it will be configured as the storage required by the Infrastructure Operator and the Infrastructure Operator will be deployed along with MCE.
- Install on SNO
- If the user also chooses ODF then ODF is used for the Infrastructure Opertor
-
- If ODF isn't configured then LVMS is enabled and the Infrastructure Operator will use it.
- User doesn't install ODF or a SNO cluster
- They have to choose their storage and then install the Infrastructure Operator in day-2 and we don't configure storage with the installation (details of this need to be reviewed).
Note from planning: Alternative we can use a new feature in install-config that allows enabling some operators in day-2 and let the user configure it this
when MCE and a storage operator is selected, enable infrastructure operator
Feature Overview (aka. Goal Summary)
RedHat allows following roles for system:anonymous user and system:unauthenticated group:
oc get clusterrolebindings -o json | jq '.items[] | select(.subjects[]?.kind
== "Group" and .subjects[]?.name == "system:unauthenticated") |
.metadata.name' | uniq
Returns what unauthenticated users can do, which is the following:
"self-access-reviewers"
"system:oauth-token-deleters"
"system:openshift:public-info-viewer"
"system:public-info-viewer"
"system:scope-impersonation"
"system:webhooks"
Customers would like to minimize the allowed permissions to unauthenticated groups and users.
It was determined after initial analysis that following roles are necessary for OIDC access and version information and will not change
"system:openshift:public-info-viewer"
"system:public-info-viewer"
Workaround available: Gating the access with policy engines
Expected: Minimize the allowed roles for unauthenticated access
Goals (aka. expected user outcomes)
Reduce use of cluster-wide permissions for system:anonymous user and system:unauthenticated group for following roles
"self-access-reviewers"
"system:oauth-token-deleters"
"system:scope-impersonation"
"system:webhooks"
Requirements (aka. Acceptance Criteria):
Customers would like to minimize the allowed permissions to unauthenticated groups and users.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | |
| Classic (standalone cluster) | Yes |
| Hosted control planes | tbd |
| Multi node, Compact (three node), or Single node (SNO), or all | |
| Connected / Restricted Network | |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | |
| Operator compatibility | |
| Backport needed (list applicable versions) | |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | |
| Other (please specify) |
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
<your text here>
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
<your text here>
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
It was determined that following roles will not change
"system:openshift:public-info-viewer"
"system:public-info-viewer"
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Many security teams have flagged anonymous access on apiserver as a security risk. Reducing the permissions granted at cluster level helps in hardening access to apiserver.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
This feature should not impact upgrade from previous versions.
This feature will allow enabling the new functionality for fresh installs.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Impact to existing usecases should be documented
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
<your text here>
RedHat allows following roles for system:anonymous user and system:unauthenticated group:
oc get clusterrolebindings -o json | jq '.items[] | select(.subjects[]?.kind
== "Group" and .subjects[]?.name == "system:unauthenticated") |
.metadata.name' | uniq
Returns what unauthenticated users can do, which is the following:
"self-access-reviewers"
"system:oauth-token-deleters"
"system:openshift:public-info-viewer"
"system:public-info-viewer"
"system:scope-impersonation"
"system:webhooks"
Customers would like to minimize the allowed permissions to unauthenticated groups and users.
Workaround available: Gating the access with policy engines
Outcome: Minimize the allowed roles for unauthenticated access
Goals of spike:
- Investigate impact of disabling the roles listed above for new and existing clusters
- Document risks and feasibility
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer - specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision GCP infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The GCP IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing GCP Terraform provider. Specifically, we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Provision GCP infrastructure without the use of Terraform
Why is this important?
- Removing Terraform from Installer
Scenarios
- The new provider should aim to provide the same results as the existing GCP
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
In order to SSH to the bootstrap node, we'll need to create a firewall rule. This should be cleaned up with bootstrap destroy.
Feature Overview (aka. Goal Summary)
As a product manager or business owner of OpenShift Lightspeed. I want to track who is using what feature of OLS and WHY. I also want to track the product adoption rate so that I can make decision about the product ( add/remove feature , add new investment )
Requirements (aka. Acceptance Criteria):
- Gaurav and Jan are working to come up with a list of KPIs to track https://miro.com/app/board/uXjVKIhVw5U=/
Notes:
- Once finalized all this KPI will converted to what metrics and based on that build a dashboard that can help in visualize the those KPI progress
- Here is an example of how ALS has build their dashboard : https://app.amplitude.com/analytics/redhat/space/574rvc9/all
Enable moniotring of OLS by defult when a user install OLS operator ---> check the box by defualt
Users will have the ability to disable the monitoring by . ----> in check the box
Refer to this slack conversation :https://redhat-internal.slack.com/archives/C068JAU4Y0P/p1723564267962489

Description of problem:
When installing the OpenShift Lightspeed operator, cluster monitoring should be enabled by default.
Version-Release number of selected component (if applicable):
How reproducible:
Always
Steps to Reproduce:
1. Click OpenShift Lightspeed in operator catalog
2. Click Install
Actual results:
"Enable Operator recommended cluster monitoring on this Namespace" checkbox is not selected by default.
Expected results:
"Enable Operator recommended cluster monitoring on this Namespace" checkbox should be selected by default.
Additional info:
In this feature will follow up OCPBU-186 Image mirroring by tags.
OCPBU-186 implemented new API ImageDigestMirrorSet and ImageTagMirrorSet and rolling of them through MCO.
This feature will update the components using ImageContentSourcePolicy to use ImageDigestMirrorSet.
The list of the components: https://docs.google.com/document/d/11FJPpIYAQLj5EcYiJtbi_bNkAcJa2hCLV63WvoDsrcQ/edit?usp=sharing.
Migrate OpenShift Components to use the new Image Digest Mirror Set (IDMS)
This doc list openshift components currently use ICSP: https://docs.google.com/document/d/11FJPpIYAQLj5EcYiJtbi_bNkAcJa2hCLV63WvoDsrcQ/edit?usp=sharing
Plan for ImageDigestMirrorSet Rollout :
Epic: https://issues.redhat.com/browse/OCPNODE-521
4.13: Enable ImageDigestMirrorSet, both ICSP and ImageDigestMirrorSet objects are functional
- Document that ICSP is being deprecated and will be unsupported by 4.17 (to allow for EUS to EUS upgrades)
- Reject write to both ICSP and ImageDigestMirrorSet on the same cluster
4.14: Update OpenShift components to use IDMS
4.17: Remove support for ICSP within MCO
- Error out if an old ICSP object is used
As an openshift developer, I want --idms-file flag so that I can fetch image info from alternative mirror if --icsp-file gets deprecated.
Goal:
Support enablement of dual-stack VIPs on existing clusters created as dual-stack but at a time when it was not possible to have both v4 and v6 VIPs at the same time.
Why is this important?
This is a followup to SDN-2213 ("Support dual ipv4 and ipv6 ingress and api VIPs").
We expect that customers with existing dual stack clusters will want to make use of the new dual stack VIPs fixes/enablement, but it's unclear how this will work because we've never supported modifying on-prem networking configuration after initial deployment. Once we have dual stack VIPs enabled, we will need to investigate how to alter the configuration to add VIPs to an existing cluster.
We will need to make changes to the VIP fields in the Infrastructure and/or ControllerConfig objects. Infrastructure would be the first option since that would make all of the fields consistent, but that relies on the ability to change that object and have the changes persist and be propagated to the ControllerConfig. If that's not possible, we may need to make changes just in ControllerConfig.
For epics https://issues.redhat.com/browse/OPNET-14 and https://issues.redhat.com/browse/OPNET-80 we need a mechanism to change configuration values related to our static pods. Today that is not possible because all of the values are put in the status field of the Infrastructure object.
We had previously discussed this as part of https://issues.redhat.com/browse/OPNET-21 because there was speculation that people would want to move from internal LB to external, which would require mutating a value in Infrastructure. In fact, there was a proposal to put that value in the spec directly and skip the status field entirely, but that was discarded because a migration would be needed in that case and we need separate fields to indicate what was requested and what the current state actually is.
There was some followup discussion about that with Joel Speed from the API team (which unfortunately I have not been able to find a record of yet) where it was concluded that if/when we want to modify Infrastructure values we would add them to the Infrastructure spec and when a value was changed it would trigger a reconfiguration of the affected services, after which the status would be updated.
This means we will need new logic in MCO to look at the spec field (currently there are only fields in the status, so spec is ignored completely) and determine the correct behavior when they do not match. This will mean the values in ControllerConfig will not always match those in Infrastructure.Status. That's about as far as the design has gone so far, but we should keep the three use cases we know of (internal/external LB, VIP addition, and DNS record overrides) in mind as we design the underlying functionality to allow mutation of Infrastructure status values.
Depending on how the design works out, we may only track the design phase in this epic and do the implementation as part of one of the other epics. If there is common logic that is needed by all and can be implemented independently we could do that under this epic though.
Infrastructure.Spec will be modified by end-user. CNO needs to validate those changes and if valid, propagate them to Infrastructure.Status
For clusters that are installed as fresh 4.15 o/installer will propagate Infrastructure.Spec and Infrastructure.Status based on the install-config. However for clusters that are upgraded this code in o/installer will never run.
In order to have a consistent state at upgrade, we will make CNO to propagate Status back to Spec when cluster is upgraded to OCP 4.15.
As we have already done it when introducing multiple VIPs (API change that created plural field next to the singular), all the necessary code scaffolding is already in place.
TLDR: cluster-bootstrap and network-operator fight for the same resource using `fieldManager` property of k8s objects. We need to take over everything what has been owned by cluster-bootstrap and manage it ourselves
Tasks to do here
- Revert the revert of API extension
- Revendor API in client-go
- Revendor API in installer
Feature Overview (aka. Goal Summary)
The Agent Based installer is a clean and simple way to install new instances of OpenShift in disconnected environments, guiding the user through the questions and information needed to successfully install an OpenShift cluster. We need to bring this highly useful feature to the IBM Power and IBM zSystem architectures
Goals (aka. expected user outcomes)
Agent based installer on Power and zSystems should reflect what is available for x86 today.
Requirements (aka. Acceptance Criteria):
Able to use the agent based installer to create OpenShift clusters on Power and zSystem architectures in disconnected environments
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
- The goal of this Epic is to enable Agent Based Installer for P/Z
Why is this important?
- The Agent Based installer is a research Spike item for the Multi-Arch team during the 4.12 release and later
Scenarios
1. …
Acceptance Criteria
- See "Definition of Done" below
Dependencies (internal and external)
1. …
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - For new features (non-enablement), existing Multi-Arch CI jobs are not broken by the Epic
- Release Enablement: <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR orf GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - If the Epic is adding a new stream, downstream build attached to advisory: <link to errata>
- QE - Test plans in Test Plan tracking software (e.g. Polarion, RQM, etc.): <link or reference to the Test Plan>
- QE - Automated tests merged: <link or reference to automated tests>
- QE - QE to verify documentation when testing
- DOC - Downstream documentation merged: <link to meaningful PR>
- All the stories, tasks, sub-tasks and bugs that belong to this epic need to have been completed and indicated by a status of 'Done'.
As the multi-arch engineer, I would like to build an environment and deploy using Agent Based installer, so that I can confirm if the feature works per spec.
Entrance Criteria
- (If there is research) research completed and proven that the feature could be done
Acceptance Criteria
- “Proof” of verification (Logs, etc.)
- If independent test code written, a link to the code added to the JIRA story
Feature Overview:
Ensure CSI Stack for Azure is running on management clusters with hosted control planes, allowing customers to associate a cluster as "Infrastructure only" and move the following parts of the stack:
- Azure Disk CSI driver
- Azure File CSI driver
- Azure File CSI driver operator
Value Statement:
This feature enables customers to run their Azure infrastructure more efficiently and cost-effectively by using hosted control planes and supporting infrastructure without incurring additional charges from Red Hat. Additionally, customers should care most about workloads not the management stack to operate their clusters, this feature gets us closer to this goal.
Goals:
- Ability for customers to associate a cluster as "Infrastructure only" and pack control planes on role=infra nodes.
- Ability to run cluster-storage-operator (CSO) + Azure Disk CSI driver operator + Azure Disk CSI driver control-plane Pods in the management cluster.
- Ability to run the driver DaemonSet in the hosted cluster.
Requirements:
- The feature must ensure that the CSI Stack for Azure is installed and running on management clusters with hosted control planes.
- The feature must allow customers to associate a cluster as "Infrastructure only" and pack control planes on role=infra nodes.
- The feature must enable the Azure Disk CSI driver, Azure File CSI driver, and Azure File CSI driver operator to run on the appropriate clusters.
- The feature must enable the cluster-storage-operator (CSO) + Azure Disk CSI driver operator + Azure Disk CSI driver control-plane Pods to run in the management cluster.
- The feature must enable the driver DaemonSet to run in the hosted cluster.
- The feature must ensure security, reliability, performance, maintainability, scalability, and usability.
Use Cases:
- A customer wants to run their Azure infrastructure using hosted control planes and supporting infrastructure without incurring additional charges from Red Hat. They use this feature to associate a cluster as "Infrastructure only" and pack control planes on role=infra nodes.
- A customer wants to use Azure storage without having to see/manage its stack, especially on a managed service. This would mean that we need to run the cluster-storage-operator (CSO) + Azure Disk CSI driver operator + Azure Disk CSI driver control-plane Pods in the management cluster and the driver DaemonSet in the hosted cluster.
Questions to Answer:
- What Azure-specific considerations need to be made when designing and delivering this feature?
- How can we ensure the security, reliability, performance, maintainability, scalability, and usability of this feature?
Out of Scope:
Non-CSI Stack for Azure-related functionalities are out of scope for this feature.
Workload identity authentication is not covered by this feature - see STOR-1748
Background
This feature is designed to enable customers to run their Azure infrastructure more efficiently and cost-effectively by using HyperShift control planes and supporting infrastructure without incurring additional charges from Red Hat.
Documentation Considerations:
Documentation for this feature should provide clear instructions on how to enable the CSI Stack for Azure on management clusters with hosted control planes and associate a cluster as "Infrastructure only." It should also include instructions on how to move the Azure Disk CSI driver, Azure File CSI driver, and Azure File CSI driver operator to the appropriate clusters.
Interoperability Considerations:
This feature impacts the CSI Stack for Azure and any layered products that interact with it. Interoperability test scenarios should be factored by the layered products.
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
Run Azure File CSI driver operator + Azure File CSI driver control-plane Pods in the management cluster, run the driver DaemonSet in the hosted cluster allowing customers to associate a cluster as "Infrastructure only".
Why is this important? (mandatory)
This allows customers to run their Azure infrastructure more efficiently and cost-effectively by using hosted control planes and supporting infrastructure without incurring additional charges from Red Hat. Additionally, customers should care most about workloads not the management stack to operate their clusters, this feature gets us closer to this goal.
Scenarios (mandatory)
When leveraging Hosted control planes, the Azure File CSI driver operator + Azure File CSI driver control-plane Pods should run in the management cluster. The driver DaemonSet should run on the managed cluster. This deployment model should provide the same feature set as the regular OCP deployment.
Dependencies (internal and external) (mandatory)
Hosted control plane on Azure.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - STOR
- Documentation -
- QE -
- PX -
- Others -
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
We need to make changes to CSO, so as it can run azure-file-operator on hypershift.
As part of this story, we will simply move building and CI of existing code to combined csi-operator.
- https://github.com/openshift/csi-operator/pull/162
- https://github.com/openshift/csi-operator/pull/154
- https://github.com/openshift/csi-operator/pull/162
- https://github.com/openshift/csi-operator/pull/154
- https://github.com/openshift/csi-operator/pull/162
- https://github.com/openshift/csi-operator/pull/154
We need to modify csi-operator so as it be ran as azure-file operator on hypershift and standalone clusters.
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
Run Azure Disk CSI driver operator + Azure Disk CSI driver control-plane Pods in the management cluster, run the driver DaemonSet in the hosted cluster allowing customers to associate a cluster as "Infrastructure only".
Why is this important? (mandatory)
This allows customers to run their Azure infrastructure more efficiently and cost-effectively by using hosted control planes and supporting infrastructure without incurring additional charges from Red Hat. Additionally, customers should care most about workloads not the management stack to operate their clusters, this feature gets us closer to this goal.
Scenarios (mandatory)
When leveraging Hosted control planes, the Azure Disk CSI driver operator + Azure Disk CSI driver control-plane Pods should run in the management cluster. The driver DaemonSet should run on the managed cluster. This deployment model should provide the same feature set as the regular OCP deployment.
Dependencies (internal and external) (mandatory)
Hosted control plane on Azure.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - STOR
- Documentation -
- QE -
- PX -
- Others -
Done - Checklist (mandatory)
As part of this epic, Engineers working on Azure Hypershift should be able to build and use Azure Disk storage on hypershift guests via developer preview custom build images.
For this story, we are going to enable deployment of azure disk driver and operator by default in hypershift environment.
Add a knob in CNO to allow users to modify the changes made in ovn-k
BU Priority Overview
Create custom roles for GCP with minimal set of required permissions.
Goals
Enable customers to better scope credential permissions and create custom roles on GCP that only include the minimum subset of what is needed for OpenShift.
State of the Business
Some of the service accounts that CCO creates, e.g. service account with role roles/iam.serviceAccountUser provides elevated permissions that are not required/used by the requesting OpenShift components. This is because we use predefined roles for GCP that come with bunch of additional permissions. The goal is to create custom roles with only the required permissions.
Execution Plans
TBD
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster Network Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Update GCP Credentials Request manifest of the Cluster Network Operator to use new API field for requesting permissions.
Evaluate if any of the GCP predefined roles in the credentials request manifests of OpenShift cluster operators give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cloud Controller Manager Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of machine api operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster CAPI Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
These are phase 2 items from CCO-188
Moving items from other teams that need to be committed to for 4.13 this work to complete
Epic Goal
- Request to build list of specific permissions to run openshift on GCP - Components grant roles, but we need more granularity - Custom roles now allow ability to do this compared to when permissions capabilities were originally written for GCP
Why is this important?
- Some of the service accounts that CCO creates, e.g. service account with role roles/iam.serviceAccountUser provides elevated permissions that are not required/used by the requesting OpenShift components. This is because we use predefined roles for GCP that come with bunch of additional permissions. The goal is to create custom roles with only the required permissions.
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster Storage Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster Ingress Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Epic Goal
- ...
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster Image Registry Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
Feature Overview
As an Infrastructure Administrator, I want to deploy OpenShift on Nutanix distributing the control plane and compute nodes across multiple regions and zones, forming different failure domains.
As an Infrastructure Administrator, I want to configure an existing OpenShift cluster to distribute the nodes across regions and zones, forming different failure domains.
Goals
Install OpenShift on Nutanix using IPI / UPI in multiple regions and zones.
Requirements (aka. Acceptance Criteria):
- Ensure Nutanix IPI can successfully be deployed with ODF across multiple zones (like we do with vSphere, AWS, GCP & Azure)
- Ensure zonal configuration in Nutanix using UPI is documented and tested
vSphere Implementation
This implementation would follow the same idea that has been done for vSphere. The following are the main PRs for vSphere:
https://github.com/openshift/enhancements/blob/master/enhancements/installer/vsphere-ipi-zonal.md
Existing vSphere documentation
Epic Goal
Nutanix Zonal: Multiple regions and zones support for Nutanix IPI and Assisted Installer
Note
- Nutanix Engineering team is driving this implementation based on the vSphere zonal implementation, led by Yanhua Li .
- The Installer team is expected to just review PRs.
- PRs are expected in these repos:
- https://github.com/openshift/api
- https://github.com/openshift/installer
- https://github.com/openshift/client-go
- https://github.com/openshift/cluster-control-plane-machine-set-operator
- https://github.com/openshift/machine-api-operator
- https://github.com/openshift/machine-api-provider-nutanix
- First PR https://github.com/openshift/api/pull/1578
As a user, I want to be able to spread control plane nodes for an OCP clusters across Prism Elements (zones).
Feature Overview (aka. Goal Summary):
This feature will allow an x86 control plane to function with compute nodes exclusively of type Power in a HyperShift environment.
Goals (aka. expected user outcomes):
Enable an x86 control plane to operate with a Power data-plane in a HyperShift environment.
Requirements (aka. Acceptance Criteria):
- The feature must allow an x86 control plane and a Power data-plane to be used together in a HyperShift environment.
- The feature must provide documentation on how to set up and use the x86 control plane with a Power data-plane in a HyperShift environment.
- The feature must be tested and verified to work reliably and securely in a production environment.
Customer Considerations:
Customers who require a mix of x86 control plane and Power data-plane for their HyperShift environment will benefit from this feature.
Documentation Considerations:
- Documentation should include clear instructions on how to set up and use the x86 control plane with a Power data-plane in a HyperShift environment.
- Documentation will live on docs.openshift.com
Interoperability Considerations:
- This feature should not impact other OpenShift layered products and versions in the portfolio.
Currently only amd64 and arm64 are considered as support processing arch in hypershift, need to add ppc64le as a supported arch with agent platform.
Make it possible to entirely disable the Ingress Operator by leveraging the OCPPLAN-9638 Composable OpenShift capability.
Why is this important?
- For Managed OpenShift on AWS (ROSA), we use the AWS load balancer and don't need the Ingress operator. Disabling the Ingress Operator will reduce our resource consumption on infra nodes for running OpenShift on AWS.
- Customers want to be able to disable the Ingress Operator and use their own component.
Scenarios
- This feature must consider the different deployment footprints including self-managed and managed OpenShift, connected vs. disconnected (restricted and air-gapped), implications for auto scaling, chargeback/showback use scenarios, etc.
- Disabled configuration must persist throughout cluster lifecycle including upgrades
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
Links:
RFE: https://issues.redhat.com/browse/RFE-3395
Enhancement PR: https://github.com/openshift/enhancements/pull/1415
API PR: https://github.com/openshift/api/pull/1516
Ingress Operator PR: https://github.com/openshift/cluster-ingress-operator/pull/950
Background
Feature Goal: Make it possible to entirely disable the Ingress Operator by leveraging the Composable OpenShift capability.
Epic Goal
Implement the ingress capability focusing on the HyperShift users.
Non-Goals
- Fully implement the ingress capability on the standalone OpenShift.
Design
As described in the EP PR.
Why is this important?
- For Managed OpenShift on AWS (ROSA), we use the AWS load balancer and don't need the Ingress operator. Disabling the Ingress Operator will reduce our resource consumption on infra nodes for running OpenShift on AWS.
- Customers want to be able to disable the Ingress Operator and use their own component.
Scenarios
# ...
Acceptance Criteria
* Release Technical Enablement - Provide necessary release enablement details and documents.
* Ingress Operator can be disabled on HyperShift.
- Dependent operators and OpenShift components can tolerate the disabled ingress operator on HyperShift.
Dependencies (internal and external)
# The install-config and ClusterVersion API have been updated with the capability feature.
# The console operator.
Previous Work (Optional):
Open questions:
#
Done Checklist
* CI - CI is running, tests are automated and merged.
* Release Enablement <link to Feature Enablement Presentation>
* DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
* DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
* DEV - Downstream build attached to advisory: <link to errata>
* QE - Test plans in Polarion: <link or reference to Polarion>
* QE - Automated tests merged: <link or reference to automated tests>
* DOC - Downstream documentation merged: <link to meaningful PR>
Context
HyperShift uses the cluster-version-operator (CVO) to manage the part of the ingress operator's payload, namely CRDs and RBACs. The ingress operator's deployment though is reconciled directly by the control plane operator. That's why HyperShift projects the ClusterVersion resource into the hosted cluster and the enabled capabilities have to be set properly to enable/disable the ingress operator's payload and to let users as well as the other operators be aware of the state of the capabilities.
Goal
The goal of this user story is to implement a new capability in the OpenShift API repository. Use this procedure as example.
Goal
The goal of this user story is to add the new (ingress) capability to the cluster operator's payload (manifests: CRDs, RBACs, deployment, etc.).
Out of scope
- CRDs and operands created at runtime (assets: gateway CRDs, controllers, subscription. etc.)
Acceptance criteria
- The ingress capability is known to the openshift installer.
- The new capability does not introduce any new regression to the e2e tests.
Links
Goal
The goal of this user story is to bump the openshift api which contains the ingress capability.
Acceptance criteria
- The ingress capability is known by the cluster version operator.
- The new capability does not introduce any new regression to the openshift CI test (test example).
Links
Epic Goal
- Allow administrators to define which machineconfigs won't cause a drain and/or reboot.
- Allow administrators to define which ImageContentSourcePolicy/ImageTagMirrorSet/ImageDigestMirrorSet won't cause a drain and/or reboot
- Allow administrators to define what services need to be started or restarted after writing the new config file.
Why is this important?
- There is a demonstrated need from customer cluster administrators to push configuration settings and restart system services without restarting each node in the cluster.
- Customers are modifying ICSP/ITMS/IDMS outside post day 1/adding them+
Scenarios
- As a cluster admin, I want to reconfigure sudo without disrupting workloads.
- As a cluster admin, I want to update or reconfigure sshd and reload the service without disrupting workloads.
- As a cluster admin, I want to remove mirroring rules from an ICSP, ITMS, IDMS object without disrupting workloads because the scenario in which this might lead to non-pullable images at a undefined later point in time doesn't apply to me.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This epic is another epic under the "reduce workload disruptions" umbrella.
This is now updated to get us most of the way to MCO-200 (Admin-Defined reboot & drain), but not necessarily with all the final features in place.
This epic aims to create a reboot/drain policy object and a MCO-management apparatus for initial functionality with MachineConfig backed updates, with a restricted set of actions for the user. We also need reboot/drain policy object for ImageContentSourcePolicy, ImageTagMirrorSet and ImageDigestMirrorSet to avoid drains/reboots when admins use these APIs and have other ways of ensuring image integrity.,
This mostly focuses on the user interface for defining reboot/drain policies. We will also need this for the layering "live apply" cases and bifrost-backed updates, to be implemented into a future update.
The MCO's reboot and drain rules are currently hard-coded in the machine-config-daemon here.
Node drains also occur even beyond OCP 4.9 when not just adding but also removing ICSP, ITMS, IDMS objects or single mirroring rules in their configuratuion according to RFE-3667.
This causes at least three problems:
- A user does not know what the rules are unless they read the code (the rules aren't visible to the user)
- The controller can't see the rules to "pre-compute" the effect that a MachineConfig will have on a Node before that MachineConfig is delivered (which makes it hard for a user to know what will actually happen if they apply a config)
- The only way for a template owner to mark their config as "does not require reboot" is to edit the MCD code
Done when:
- A CRD is defined for post config action policies covering both MCO and ICSP/ITMS/IDMS APIs
- The existing daemon rules are broken out into one of these resources
- The reboot/drain policies are visible in the cluster (e.g. "oc get rebootpolicies")
- The drain controller handles processing and validation of the user's policies (and could put the computed post-config actions in the machineconfig's and ICSP/ITMS/IDMS status or the custom image's metadata if layering)
- A template owner has a procedure to mark that their template config changing does/does not require a reboot
Description of problem:
The MCO logic today allows users to not reboot when changing the registries.conf file (through ICSP/IDMS/ITMS objects), but the MCO will sometimes drain the node if the change is deemed "unsafe" (deleting a mirror, for example). This behaviour is very disruptive for some customers who with to make all image registries changes non-disruptive. We will address this long term with admin defined policies via the API properly, but we would like to have a backportable solution (as a support exception) for users to do so
Version-Release number of selected component (if applicable):
4.14->4.16
How reproducible:
Steps to Reproduce:
1.
2.
3.
Actual results:
Expected results:
Additional info:
Have the MCC validate the correctness of user-provided spec, and render the final object into the status for the daemon to use
Have either a separate RebootPolicy or as part of MachineConfiguration spec
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Complete during New status.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
- The goal of this epic is to enable monitoring on the Windows nodes created by Windows Machine Config Operator(WMCO) in an OpenShift cluster.
Why is this important?
- Monitoring is critical to identify issues with nodes, pods and containers running on the nodes. Monitoring enables users to make informed decisions, optimize performance, and strategically manage infrastructure costs. Implementation of this epic will ensure that we have a consistent user experience for monitoring across Linux and Windows.
Scenarios
Display console graphs for the following:
- Windows node metrics.
- Windows pod metrics.
Acceptance Criteria
- CI - MUST be running successfully with tests automated to test that the console graphs are present.
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
- None
Previous Work :
Open questions::
1. Specifics on testing framework- adding tests to https://github.com/openshift/console- pending story creation.
2. Feasibility of https://issues.redhat.com/browse/WINC-530
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User or Developer story
As a WMCO user, I want filesystem graphs to be visible for Windows nodes.
Description
WMCO uses existing console queries to display graphs for Windows nodes. Changes in filesystem queries (https://github.com/openshift/console/pull/7201) on the console side, prevent filesystem graphs to be displayed for Windows nodes.
Engineering Details
The root cause for filesystem queries to not work is windows_exporter does not return any value for `mountpoint` field used in the console queries.
Acceptance Criteria
Filesytem graph is populated for Windows nodes in the OpenShift console.
Description
When inspecting a pod in the OCP console, the metrics tab shows a number of graphs. The networking graphs do not show data for Windows pods.
Engineering Details
Using windows exporter 0.24.0 I am getting `No datapoints found` for the query made by the console:
(sum(irate(container_network_receive_bytes_total{pod='win-webserver-685cd6c5cc-8298l'}[5m])) by (pod, namespace, interface)) + on(namespace,pod,interface) group_left(network_name) (pod_network_name_info)
There is data returned from the query `irate(container_network_receive_bytes_total{pod='windows-machine-config-operator-7c8bcc7b64-sjqxw'}[5m])`
Which makes me believe the error is due to pod_network_name_info not having data for the Windows pods I am looking at.
I'm confirming that by checking in the namespace the workloads are deployed to via the query: pod_network_name_info{namespace="openshift-windows-machine-config-operator"}
I only see metrics for the Linux pods in the namespace.
Looking into this it seems like these metrics are coming from https://github.com/openshift/network-metrics-daemon which runs on each Linux node, and creates a metric for applicable pods running on the node.
Acceptance Criteria
- The pod network graphs shown in the OCP console are populated for Windows pods.
We need to create CI tests to ensure that during the live migration when a cluster has both OVN-K and Openshift-SDN deployed in some nodes. The cluster network can still work as normal. We need run the disruptive tests as we do for upgrde.
In https://issues.redhat.com/browse/OPNET-10 we did some initial investigation of a new design for handling creation of br-ex for OVNK. We successfully came up with a high-level design, but we still need to translate that into an implementable OpenShift feature. The goal for this epic would be to come up with an accepted enhancement. The implementation of the design would likely need to happen in the next release.
Notable obstacles to this work are:
- The inability to do per-node configuration in existing OpenShift operators. In order to support things like static IPs we need a way to provide a separate configuration for each node.
- API team's objections to having NMState configurations represented in the OpenShift API. When we discussed this with them recently they were strongly opposed to NMState as an interface, including the existing baremetal and kubernetes-nmstate cases.
This is the followup epic to https://issues.redhat.com/browse/OPNET-265 Once we have an approved enhancement (which we expect to be a significant piece of work in itself), this will track the implementation. We expect this to happen in 4.15 or later unless things go very smoothly with the enhancement epic in 4.14.
Executive Summary
Image and artifact signing is a key part of a DevSecOps model. The Red Hat-sponsored sigstore project aims to simplify signing of cloud-native artifacts and sees increasing interest and uptake in the Kubernetes community. This document proposes to incrementally invest in OpenShift support for sigstore-style signed images and be public about it. The goal is to give customers a practical and scalable way to establish content trust. It will strengthen OpenShift’s security philosophy and value-add in the light of the recent supply chain security crisis.
CRIO
- Support customer image validation
- Support OpenShift release image validation
https://docs.google.com/document/d/12ttMgYdM6A7-IAPTza59-y2ryVG-UUHt-LYvLw4Xmq8/edit#
User Story:
As a hub cluster admin, I want to be able to:
- Detect when running in managed vs self-managed mode in Azure
so that I can prevent
- Impossible usage of managed service components in self-manage use cases
Acceptance Criteria:
Description of criteria:
- HyperShift controllers are aware of when they run in managed environment
- HyperShift components have a single programmatic way to check in which mode they run
- HyperShift deployment takes the mode in consideration when setting up its components
(optional) Out of Scope:
Implementing managed-only configs is out of scope for this story
Engineering Details:
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
User Story:
As a hub cluster admin, I want to be able to:
- Detect when running in managed vs self-managed mode in Azure
so that I can prevent
- Impossible usage of managed service components in self-manage use cases
Acceptance Criteria:
Description of criteria:
- HyperShift controllers are aware of when they run in managed environment
- HyperShift components have a single programmatic way to check in which mode they run
- HyperShift deployment takes the mode in consideration when setting up its components
(optional) Out of Scope:
Implementing managed-only configs is out of scope for this story
Engineering Details:
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
Goal
We need to be able to install the HO with external DNS and create HCPs on AKS clusters
Why is this important?
- AKS clusters will serve as the management clusters on ARO HCP.
Scenarios
- ...
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
The cloud-network-config-operator is being deployed on HyperShift with `runAsNonRoot` set to true. When HCP is deployed on non-OpenShift management clusters, such as AKS, this needs to be unset so the pod can run as root.
This is currently causing issues deploying this pod on HCP on AKS with the following error:
state:
waiting:
message: 'container has runAsNonRoot and image will run as root (pod: "cloud-network-config-controller-59d4677589-bpkfp_clusters-brcox-hypershift-arm(62a4b447-1df7-4e4a-9716-6e10ec55d8fd)", container: hosted-cluster-kubecfg-setup)'
reason: CreateContainerConfigError
User Story:
As a user of HyperShift on Azure, I want to be able to:
- create HCP with externalDNS setup on AKS clusters
so that I can achieve
- the ability to successfully setup HCPs on AKS for the ARO HCP effort.
Acceptance Criteria:
Description of criteria:
- Upstream documentation on setting up an HCP with externalDNS on AKS
- Any code changes needed to successfully setup HCP with externalDNS on AKS has been peer reviewed and approved
Out of Scope:
- Any private or publicPrivate topology setup.
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
CSI pods are failing to create on HCP on an AKS cluster.
% k get pods | grep -v Running NAME READY STATUS RESTARTS AGE csi-snapshot-controller-cfb96bff7-7tc94 0/1 CreateContainerConfigError 0 17h csi-snapshot-webhook-57f9799848-mlh8k 0/1 CreateContainerConfigError 0 17h
The issue is
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 34m default-scheduler Successfully assigned clusters-brcox-hypershift-arm/csi-snapshot-controller-cfb96bff7-7tc94 to aks-nodepool1-24902778-vmss000001 Normal Pulling 34m kubelet Pulling image "quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:805280104b2cc8d8799b14b2da0bd1751074a39c129c8ffe5fc1b370671ecb83" Normal Pulled 34m kubelet Successfully pulled image "quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:805280104b2cc8d8799b14b2da0bd1751074a39c129c8ffe5fc1b370671ecb83" in 3.036610768s (10.652709193s including waiting) Warning Failed 32m (x12 over 34m) kubelet Error: container has runAsNonRoot and image will run as root (pod: "csi-snapshot-controller-cfb96bff7-7tc94_clusters-brcox-hypershift-arm(45ab89f2-9c00-4afa-bece-7846505edbfc)", container: snapshot-controller)
User Story:
As a HyperShift CLI user, I want to be able to:
- include my pull secret when installing the HyperShift operator with an externalDNS setup
so that I can achieve
- the ability to pull the Red Hat version of the externalDNS image.
Acceptance Criteria:
Description of criteria:
- The ability to include the pull secret on a HyperShift operator installation is available in the HyperShift CLI
Out of Scope:
- Any additional changes needed to install HCPs on AKS
Engineering Details:
- N/A
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview
As of OpenShift 4.14, this functionality is Tech Preview for all platforms but OpenStack, where it is GA. This Feature is to bring the functionality to GA for all remaining platforms.
Feature Description
Allow to configure control plane nodes across multiple subnets for on-premise IPI deployments. With separating nodes in subnets, also allow using an external load balancer, instead of the built-in (keepalived/haproxy) that the IPI workflow installs, so that the customer can configure their own load balancer with the ingress and API VIPs pointing to nodes in the separate subnets.
Goals
I want to install OpenShift with IPI on an on-premise platform (high priority for bare metal and vSphere) and I need to distribute my control plane and nodes across multiple subnets.
I want to use IPI automation but I will configure an external load balancer for the API and Ingress VIPs, instead of using the built-in keepalived/haproxy-based load balancer that come with the on-prem platforms.
Background, and strategic fit
Customers require using multiple logical availability zones to define their architecture and topology for their datacenter. OpenShift clusters are expected to fit in this architecture for the high availability and disaster recovery plans of their datacenters.
Customers want the benefits of IPI and automated installations (and avoid UPI) and at the same time when they expect high traffic in their workloads they will design their clusters with external load balancers that will have the VIPs of the OpenShift clusters.
Load balancers can distribute incoming traffic across multiple subnets, which is something our built-in load balancers aren't able to do and which represents a big limitation for the topologies customers are designing.
While this is possible with IPI AWS, this isn't available with on-premise platforms installed with IPI (for the control plane nodes specifically), and customers see this as a gap in OpenShift for on-premise platforms.
Functionalities per Epic
| Epic | Control Plane with Multiple Subnets | Compute with Multiple Subnets | Doesn't need external LB | Built-in LB |
|---|---|---|---|---|
| ✓ | ✓ | ✓ | ✓ | |
| ✓ | ✓ | ✓ | ✕ | |
| ✓ | ✓ | ✓ | ✓ | |
| ✓ | ✓ | ✓ | ✓ | |
| ✓ | ✓ | ✓ | ||
| ✓ | ✓ | ✓ | ✕ | |
| ✓ | ✓ | ✓ | ✕ | |
| ✓ | ✓ | ✓ | ✓ | |
| ✕ | ✓ | ✓ | ✓ | |
| ✕ | ✓ | ✓ | ✓ | |
| ✕ | ✓ | ✓ | ✓ |
Previous Work
Workers on separate subnets with IPI documentation
We can already deploy compute nodes on separate subnets by preventing the built-in LBs from running on the compute nodes. This is documented for bare metal only for the Remote Worker Nodes use case: https://docs.openshift.com/container-platform/4.11/installing/installing_bare_metal_ipi/ipi-install-installation-workflow.html#configure-network-components-to-run-on-the-control-plane_ipi-install-installation-workflow
This procedure works on vSphere too, albeit no QE CI and not documented.
External load balancer with IPI documentation
- Bare Metal: https://docs.openshift.com/container-platform/4.11/installing/installing_bare_metal_ipi/ipi-install-post-installation-configuration.html#nw-osp-configuring-external-load-balancer_ipi-install-post-installation-configuration
- vSphere: https://docs.openshift.com/container-platform/4.11/installing/installing_vsphere/installing-vsphere-installer-provisioned.html#nw-osp-configuring-external-load-balancer_installing-vsphere-installer-provisioned
Scenarios
- vSphere: I can define 3 or more networks in vSphere and distribute my masters and workers across them. I can configure an external load balancer for the VIPs.
- Bare metal: I can configure the IPI installer and the agent-based installer to place my control plane nodes and compute nodes on 3 or more subnets at installation time. I can configure an external load balancer for the VIPs.
Acceptance Criteria
- Can place compute nodes on multiple subnets with IPI installations
- Can place control plane nodes on multiple subnets with IPI installations
- Can configure external load balancers for clusters deployed with IPI with control plane and compute nodes on multiple subnets
- Can configure VIPs to in external load balancer routed to nodes on separate subnets and VLANs
- Documentation exists for all the above cases
Currently o/installer validates that ELB is used only in TechPreview clusters. This validation needs to be removed so that ELB can be consumed from GA.
Goal:
Enable and support Multus CNI for microshift.
Background:
Customers with advanced networking requirement need to be able to attach additional networks to a pod, e.g. for high-performance requirements using SR-IOV or complex VLAN setups etc.
Requirements:
- opt-in approach: customers can add multus if needed, e.g. by installing/adding "microshift-networking-multus" rpm package to their installation.
- if possible, it would be good to be able to add multus an existing installation. If that requires a restart/reboot, that is acceptable. If not possible, it has to be clearly documented.
- it is acceptable that once multus has been added to an installation, it can not be removed. If removal can be implemented easily, that would be good. If not possible, then it has to be clearly documented.
- Regarding additional networks:
- As part of the MVP, the Bridge plugin must be fully supported
- As stretch goal, macvlan and ipvlan plugins should be supported
- Other plugins, esp. host device and sr-iov are out of scope for the MVP, but will be added with a later version.
- Multiple additional networks need to be configurable, e.g. two different bridges leading to two different networks, each consumed by different pods.
- IP V6 with bridge plugin. Secondary NICs passed to a container via the bridge plugin should work with IP V6, if the consuming pod does support V6. See also "out of scope"
- Regarding IPAM CNI support for IP address provisioning, static and DHCP must be supported.
Documentation:
- In the existing "networking" book, we need a new chapter "4. Multiple networks". It can re-use a lot content from OCP doc "https://docs.openshift.com/container-platform/4.14/networking/multiple_networks/understanding-multiple-networks.html", but needs an extra chapter in the beginning "Installing support for multiple networks"{}
Testing:
- A simple "smoke test" that multus can be added, and a 2nd nic added to a pod (e.g. using host device) is sufficient. No need to replicate all the multus tests from OpenShift, as we assume that if it works there, it works with MicroShift.
Customer Considerations:
- This document contains the MVP requirements of a MicroShift EAP customer that need to be considered.
Out of scope:
- Other plugins, esp. host device and sr-iov are out of scope for the MVP, but will be added with a later version.
- IP V6 support with OVN-K. That is scope of feature
OCPSTRAT-385
Epic Goal
- Provide optional Multus CNI for MicroShift
Why is this important?
- Customers need to add extra interfaces directly to Pods
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
- thin plugin
- only RHEL9
(contacting ART to setup image build is another task)
It should include all CNIs (bridge, macvlan, ipvlan, etc.) - if we decide to support something, we'll just update scripting to copy those CNIs
It needs to include IPAMs: static, dynamic (DHCP), host-local (we might just not copy it to host)
RHEL9 binaries only to save space
Feature Overview (aka. Goal Summary)
Unify and update hosted control planes storage operators so that they have similar code patterns and can run properly in both standalone OCP and HyperShift's control plane.
Goals (aka. expected user outcomes)
- Simplify the operators with a unified code pattern
- Expose metrics from control-plane components
- Use proper RBACs in the guest cluster
- Scale the pods according to HostedControlPlane's AvailabilityPolicy
- Add proper node selector and pod affinity for mgmt cluster pods
Requirements (aka. Acceptance Criteria):
- OCP regression tests work in both standalone OCP and HyperShift
- Code in the operators looks the same
- Metrics from control-plane components are exposed
- Proper RBACs are used in the guest cluster
- Pods scale according to HostedControlPlane's AvailabilityPolicy
- Proper node selector and pod affinity is added for mgmt cluster pods
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal*
Our current design of EBS driver operator to support Hypershift does not scale well to other drivers. Existing design will lead to more code duplication between driver operators and possibility of errors.
Why is this important? (mandatory)
An improved design will allow more storage drivers and their operators to be added to hypershift without requiring significant changes in the code internals.
Scenarios (mandatory)
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Out CSI driver YAML files are mostly copy-paste from the initial CSI driver (AWS EBS?).
As OCP engineer, I want the YAML files to be generated, so we can keep consistency among the CSI drivers easily and make them less error-prone.
It should have no visible impact on the resulting operator behavior.
Finally switch both CI and ART to the refactored aws-ebs-csi-driver-operator.
The functionality and behavior should be the same as the existing operator, however, the code is completely new. There could be some rough edges. See https://github.com/openshift/enhancements/blob/master/enhancements/storage/csi-driver-operator-merge.md
Ci should catch the most obvious errors, however, we need to test features that we do not have in CI. Like:
- custom CA bundles
- cluster-wide proxy
- custom encryption keys used in install-config.yaml
- government cluster
- STS
- SNO
- and other
Add the DNSNameResolver Controller to Cluster DNS Operator as proposed in the enhancement https://github.com/openshift/enhancements/pull/1335
Implement the changes in Cluster DNS Operator as proposed in the enhancement https://github.com/openshift/enhancements/pull/1335
Make the changes as per the proposed enhancement https://github.com/openshift/enhancements/pull/1335
- To add the support of DNSNameResolver CRD in OVN-K, add the flag --enable-dns-name-resolver to the corresponding OVN-K pods.
Note: The flag should be added to OVN-K after checking if the feature-gate DNSNameResolver is enabled.
- Add rbac permissions for DNSNameResolver resources to ovn-kubernetes. The following permissions should be added to 002-rbac-node.yaml, 003-rbac-controller.yaml and 004-rbac-control-plane.yaml files in bindata/network/ovn-kubernetes/common/ directory
- apiGroups: ["network.openshift.io"]
resources:
- dnsnameresolvers
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
- Update the 001-crd.yaml file in bindata/network/ovn-kubernetes/common/ directory with the latest EgressFirewall CRD.
Add the new external plugin from https://github.com/openshift/coredns-ocp-dnsnameresolver to CoreDNS as proposed in the enhancement https://github.com/openshift/enhancements/pull/1335
While trying to block requests going from the pods to different domain names, for example:
- registry.access.redhat.com
- registry.access.redhat.com.edgekey.net
- registry-1.docker.io
Here, the egressnetworkpolicy is working out for `registry.access.redhat.com` and `registry.access.redhat.com.edgekey.net`, however, for `registry-1.docker.io`, it is not denying access despite giving the deny entry.
"Domain name updates are polled based on the TTL (time to live) value of the domain returned by the local non-authoritative servers. The pod should also resolve the domain from the same local nameservers when necessary, otherwise, the IP addresses for the domain perceived by the egress network policy controller and the pod will be different, and the egress network policy may not be enforced as expected. Since egress network policy controller and pod are asynchronously polling the same local nameserver, there could be a race condition where pod may get the updated IP before the egress controller. Due to this current limitation, domain name usage in EgressNetworkPolicy is only recommended for domains with infrequent IP address changes."
Aim of this feature is to fix this and also support wildcard entries for EgressNetwork Policy
Goal
As an OpenShift installer I want to update the firmware of the hosts I use for OpenShift on day 1 and day 2.
As an OpenShift installer I want to integrate the firmware update in the ZTP workflow.
Description
The firmware updates are required in BIOS, GPUs, NICs, DPUs, on hosts that will often be used as DUs in Edge locations (commonly installed with ZTP).
Acceptance criteria
- Firmware can be updated (upgrade/downgrade)
- Existing firmware version can be checked
Out of Scope
- Day 2 host firmware upgrade
Description of problem:
After running a firmware update the new version is not displayed in the status of the HostFirmwareComponents
Version-Release number of selected component (if applicable):
How reproducible:
100%
Steps to Reproduce:
1. Execute a firmware update, after it succeeds check the Status to find the information about the new version installed.
Actual results:
Status only show the initial information about the firmware components.
Expected results:
Status should show the newer information about the firmware components.
Additional info:
When executing a firmware update for BMH, there is a problem updating the Status of the HostFirmwareComponents CRD, causing the BMH to repeat the update multiple times since it stays in Preparing state.
As a customer of self managed OpenShift or an SRE managing a fleet of OpenShift clusters I should be able to determine the progress and state of an OCP upgrade and only be alerted if the cluster is unable to progress. Support a cli-status command and status-API which can be used by cluster-admin to monitor the progress. status command/API should also contain data to alert users about potential issues which can make the updates problematic.
Feature Overview (aka. Goal Summary)
Here are common update improvements from customer interactions on Update experience
- Show nodes where pod draining is taking more time.
Customers have to dig deeper often to find the nodes for further debugging.
The ask has been to bubble up this on the update progress window. - oc update status ?
From the UI we can see the progress of the update. From oc cli we can see this from "oc get cvo"
But the ask is to show more details in a human-readable format.
Know where the update has stopped. Consider adding at what run level it has stopped.
oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.12.0 True True 16s Working towards 4.12.4: 9 of 829 done (1% complete)
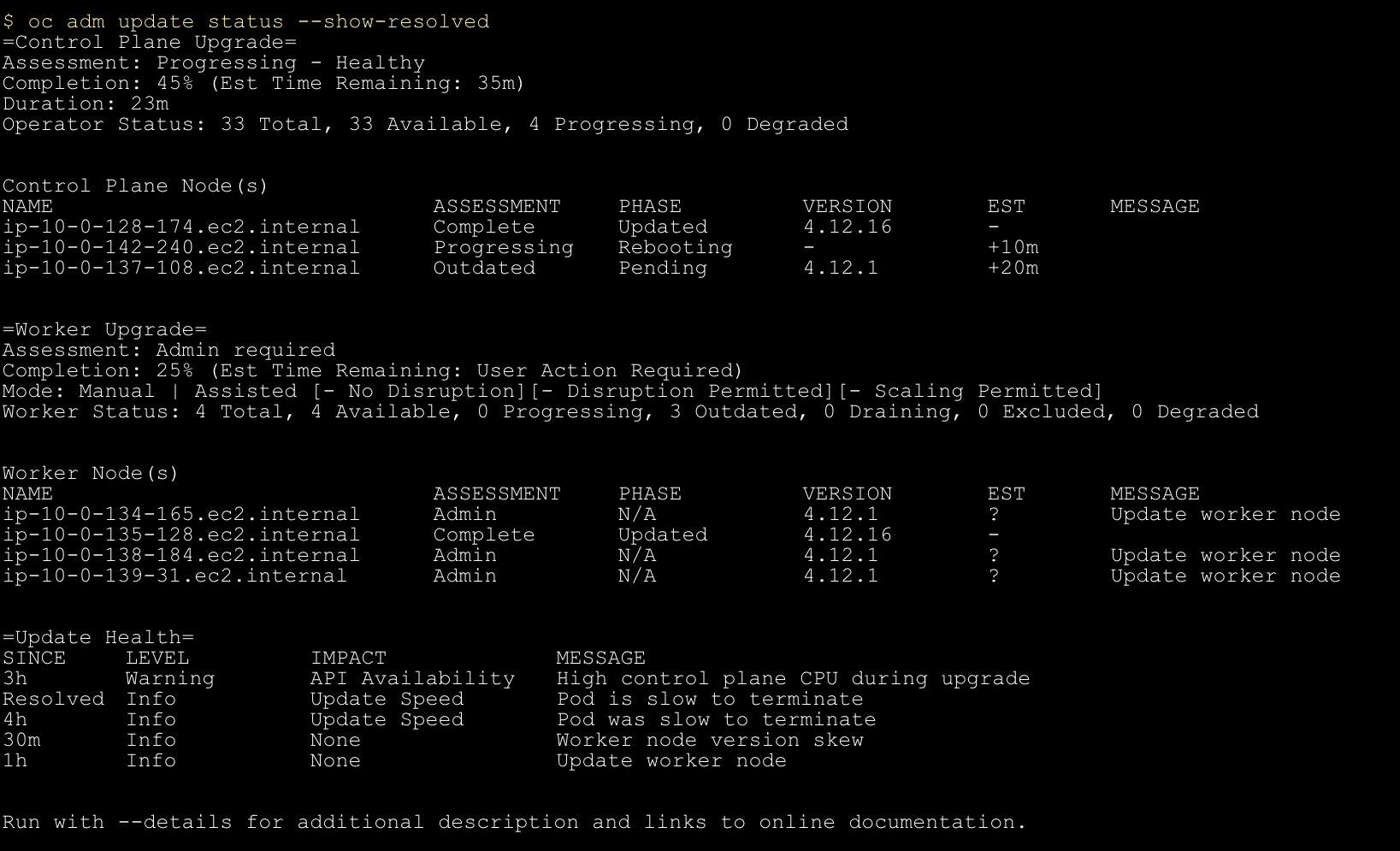
Documentation Considerations
Update docs for UX and CLI changes
Reference : https://docs.google.com/presentation/d/1cwxN30uno_9O8RayvcIAe8Owlds-5Wjr970sDxn7hPg/edit#slide=id.g2a2b8de8edb_0_22
Epic Goal*
Add a new command `oc adm upgrade status` command which is backed by an API. Please find the mock output of the command output attached in this card.
Why is this important? (mandatory)
- From the UI we can see the progress of the update. Using OC CLI we can see some of the information using "oc get clusterversion" but the output is not readable and it is a lot of extra information to process.
- Customer as asking us to show more details in a human-readable format as well provide an API which they can use for automation.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Tests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Other
Add node status as mentioned in the sample output to "oc adm upgrade status" in OpenShift Update Concepts
With this output, users will be able to see the state of the nodes that are not part of the master machine config pool and what version of RHCOS they are currently on. I am not sure if it is possible to also show corresponding OCP version. If possible we should display that as well.
=Worker Upgrade= Worker Pool: openshift-machine-api/machineconfigpool/worker Assessment: Admin required Completion: 25% (Est Time Remaining: N/A - Manual action required) Mode: Manual | Assisted [- No Disruption][- Disruption Permitted][- Scaling Permitted] Worker Status: 4 Total, 4 Available, 0 Progressing, 3 Outdated, 0 Draining, 0 Excluded, 0 Degraded Worker Pool Node(s) NAME ASSESSMENT PHASE VERSION EST MESSAGE ip-10-0-134-165.ec2.internal Manual N/A 4.12.1 ? Awaiting manual reboot ip-10-0-135-128.ec2.internal Complete Updated 4.12.16 - ip-10-0-138-184.ec2.internal Manual N/A 4.12.1 ? Awaiting manual reboot ip-10-0-139-31.ec2.internal Manual N/A 4.12.1 ? Awaiting manual reboot
Definition of done:
- Add code to get similar output as listed above. if a particular field/column needs more work, create separate Jira cards.
- This output should be shown even when control plane already updated but workers are not yet (as of Jan 2024, the status command will say that the cluster is not upgrading in such case)
- Output should take into account that there can be multiple worker pools
- We should capture fixtures for the following to scenarios:
- cluster that finished control plane update but is still upgrading worker nodes
- cluster that finished control plane update but is still upgrading worker nodes and there’s a restrictive PDB that prohibits draining
CVO story: persistence for "how long has this ClusterOperator been updating?". For a first pass, we can just hold this in memory in the CVO, and possibly expose it to our managers via the ResourceReconcilliationIssues structure created in OTA-1159. But to persist between CVO restarts, we could have the CVO annotate the ClusterOperator with "here's when I first precreated this ClusterOperator during update $KEY". Update keys are probably (a hash of?) (startTime, targetImage). And the CVO would set the annotation when it pre-created the cluster operator for the release, unless an annotation already existed with the same update key. And the reconciling-mode CVO could clear off the annotations.
We are not sure yet whether we want to do this with CO annotations or OTA-1159 "result of work", we defer this decision to after we implement OTA-1159.
I ended up doing this via the OTA-1159 result-of-work route, and I just did the "expose" side. If we want to cover persistence between CVO-container-restarts, we'd need a follow-up ticket for that. The CVO is only likely to restart when machine-config is moving though, and giving that component a bit more time doesn't seem like a terrible thing, so we might not need a follow-up ticket at all.
Add node status as mentioned in the sample output to "oc adm upgrade status".
With this output, users will be able to see the state of the nodes that are part of the master machine config pool and what version of RHCOS they are currently on. I am not sure if it is possible to also show corresponding OCP version. If possible we should display that as well.
Control Plane Node(s) NAME ASSESSMENT PHASE VERSION ip-10-0-128-174.ec2.internal Complete Updated 4.12.16 ip-10-0-142-240.ec2.internal Progressing Rebooting - ip-10-0-137-108.ec2.internal Outdated Pending 4.12.1
Definition of done:
- Add code to get similar output as listed above. if a particular field/column needs more work, create separate Jira cards.
Current state
= Control Plane = ... Operator Status: 33 Total, 31 Available, 1 Progressing, 4 Degraded
Improvement opportunities
1. "33 Total" confuses people into thinking this number is a sum of the others (e.g. OCPBUGS-24643)
2. "Available" is useless most of the time: in happy path it equals total, in error path the "unavailable" would be more useful, we should not require the user to do a mental subtraction when we can just tell them
3. "1 Progressing" does not mean much, I think we can relay similar information by saying "1 upgrading" on the completion line (see OTA-1153)
4. "0 degraded" is not useful (and 0 unavailable would be too), we can hide it on happy path
5. somehow relay that operators can be both unavailable and degraded
Definition of Done
// Happy path, all is well Operator status: 33 Healthy // Two operators Available=False Operator status: 31 Healthy, 2 Unavailable // Two operators Available=False, one degraded Operator status: 30 Healthy, 2 Unavailable, 1 Available but degraded // Two operators Available=False, one degraded, one both => unavailable trumps degraded Operator status: 29 Healthy, 3 Unavailable, 1 Available but degraded
Open questions
1. How to handle COs briefly unavailable / degraded? OTA-1087 PoC does not show insights about them if they are briefly down / degraded to avoid noise, so we can either be inconsistent between counts and health, or between "adm status" and "get co". => extracted to OTA-1175
This is a clone of issue OCPBUGS-33898. The following is the description of the original issue:
—
The mockup output does not contain the version the cluster is being upgraded to. Existing CVO condition shows it, so we should find a place for it in the output (or explicitly decide we dont want it)
Definition of Done:
oc adm upgrade status tells that cluster is upgrading from x'.y'.z' (to partial intermediate version...) to x.y.z version.
For example, with a history like:
- Completed 4.15.0
- Partial 4.15.2
- Partial 4.15.3
- Completed 4.15.5
we might show something that mentioned 4.15.0, 4.15.2, 4.15.3, and 4.15.5. Or we could decide that those mid-update retargets are rare enough to not be worth spending code-time on, and only mention 4.15.0 and 4.15.5?
OpenShift Update Concepts proposes a --details option that should supply the insights with SOP/documentation links, but does not give an example of how the output would look like:
=Update Health= SINCE LEVEL IMPACT MESSAGE 3h Warning API Availability High control plane CPU during upgrade Resolved Info Update Speed Pod is slow to terminate 4h Info Update Speed Pod was slow to terminate 30m Info None Worker node version skew 1h Info None Update worker node Run with --details for additional description and links to online documentation.
Justin's design ideas contain a remediation struct for this which I like.
Definition of Done:
- With --details, every insight will have two more fields - description and remediation URL (runbook, documentation...). Both mandatory.
- Output will not be a table, but a oc describe -like tree output
- For CO insights, we stop putting the (potentially long) CO condition message into insight message, but place it in new description field instead.
- We can use the links to generic alert runbooks that someone asks us to do in alerts (OCPBUGS-14246)
Implementing RFE-928 would help a number of update-team use-cases:
- OTA-368,
OSDOCS-2427, and other tickets that are mulling over rendering update-related alerts when folks are trying to decide whether to launch an update. OTA-1021's update status subcommand could use these to help admins discover and respond to update-related issues in their updating clusters.
The updates team is not well positioned to maintain oc access long-term; that seems like a better fit for the monitoring team (who maintain Alertmanager) or the workloads team (who maintain the bulk of oc). But we can probably hack together a proof-of-concept which we could later hand off to those teams, and in the meantime it would unblock our work on tech-preview commands consuming the firing-alert information.
The proof-of-concept could follow the following process:
- Get alertmanager URL from route alertmanager-main in openshift-monitoring namespace
- Use the $ALERTMANAGER/api/v1/alerts endpoint to get data about alerts (see https://github.com/prometheus/alertmanager#api)
- The endpoint is authenticated via bearer token, same as against apiserver (possible Role for this mentioned in
MON-3396OBSDA-530)
Definition of done:
$ OC_ENABLE_CMD_INSPECT_ALERTS=true oc adm inspect-alerts ...dump of firing alerts...
and a backing Go function that other subcommands like oc adm upgrade status can consume internally.
oc adm upgrade status currently renders Progressing and Failing!=False directly, instead of feeding them in through updateInsight. OTA-1154 is removing those. But Failing has useful information about the cluster-version operator's direct dependents which isn't available via ClusterOperator, MachineConfigPools, or the other resources we consume. This ticket is about adding logic to assessControlPlaneStatus to convert Failing!=False into an updateInsight, so it can be rendered via the consolidated insights-rendering pathways, and not via the one-off printout.
This is a clone of issue OCPBUGS-33896. The following is the description of the original issue:
—
Using the alerts-in-CLI PoC OTA-1080 show relevant firing alerts in the OTA-1087 section. Probably do not show all firing alerts.
I propose showing
- Alerts that started to fire during the upgrade
- Allow list of alerts that we know are relevant during upgrades? Insight severity can match alert severity.
Impact can be probably simple alertname -> impact type classifier. Message can be "Alert name: Alert message":
=Update Health= SINCE LEVEL IMPACT MESSAGE 3h Warning API Availability KubeDaemonSetRolloutStuck: DaemonSet openshift-ingress-canary/ingress-canary has not finished or progressed for at least 30 minutes.
Definition of done
- Alerts that started firing during the upgrade are shown as a upgrade health insight in upgrade health section
- Alerts that started firing before the upgrade but are present on an allowlist (hardcoded for now) of alerts relevant for update
- Create an allow list for alerts (structure) which will show the alerts in this section.
- We do not plan to decide which alerts should be in the allow list as part of this card (as this is a future card)
In https://github.com/openshift/oc/pull/1554 we scaffolded the status command with existing CVO condition message. We should stop printing this message once the standard command output relays this information well enough.
An update is in progress for 59m13s: Unable to apply 4.14.1: the cluster operator control-plane-machine-set is not available Failing=True: Reason: ClusterOperatorNotAvailable Message: Cluster operator control-plane-machine-set is not available
The above is CVO condition message: we should remove once all information it presents is presented in the actual new status output.
Definition of Done
None of this specially processed CVO / ClusterVersion condition content is emitted, the first section in the output is "= Control Plane =". We should only do this if any of its possible content is already surfaced via an assessment or a health insight.
As a PoC (proof of concept), warn about Available=False and Degraded=True ClusterOperators, smoothing flapping conditions (like discussed on a refinement call on Nov 29).
Follow Justin's direction from design ideas, make this easily pluggable for more "warnings"
Example Output
=Update Health= SINCE LEVEL IMPACT MESSAGE 3h Warning API Availability High control plane CPU during upgrade Resolved Info Update Speed Pod is slow to terminate 4h Info Update Speed Pod was slow to terminate 30m Info None Worker node version skew 1h Info None Update worker node
This is a clone of issue OCPBUGS-33903. The following is the description of the original issue:
—
Description of problem:
The cluster version is not updating (Progressing=False). Reason: <none> Message: Cluster version is 4.16.0-0.nightly-2024-05-08-222442
When cluster is outside of update it shows Failing=True condition content which is potentially confusing. I think we can just show "The cluster version is not updating ".
Expose 'Result of work' as structured JSON in a ClusterVersion condition (ResourceReconciliationIssues? ReconciliationIssues). This would allow oc to explain what the CVO is having trouble with, without needing to reach around the CVO and look at ClusterOperators directly (avoiding the risk of latency/skew between what the CVO thinks it's waiting on and the current ClusterOperator content). And we could replace the current Progressing string with more information, and iterate quickly on the oc side. Although if we find ways we like more to stringify this content, we probably want to push that back up to the CVO so all clients can benefit.
We want to do this work behind a feature gate OTA-1169.
Definition of Done
- All code added for this effort must be conditional on the UpgradeStatus feature gate (added in https://github.com/openshift/api/pull/1725 so we will need to bump o/api in CVO).
- CVO will have a new .status.conditions item with type==ReconciliationIssues
- When CVO encounters an "issue" (more details on issues below) while applying a resource, the condition value is True and message is a JSON with all issues encountered
- Reason values can be invented as necessary
- When no issue is encountered, condition is False
- Reconciliation issue is when CVO cannot reach desired state for the given resource in the given sync loop - this will differ between upgrading and reconciling mode. In upgrading mode CVO needs to report things like waiting on ClusterOperators going out of Available=False/Degraded=True, waiting for deployments to go ready etc. In reconciling mode we should report failures to apply.
Note that a condition with Message containing a JSON instead of a human-readable message is against apimachinery conventions and is VERY poor API method in general. The purpose of this story is simply to experiment with how such API could like, and will inform how we will build it in the future. Do not worry too much about tech debt, this is exploratory code.
Feature Overview (aka. Goal Summary)
Enable support to bring your own encryption key (BYOK) for OpenShift on IBM Cloud VPC.
Goals (aka. expected user outcomes)
As a user I want to be able to provide my own encryption key when deploying OpenShift on IBM Cloud VPC so the cluster infrastructure objects, VM instances and storage objects, can use that user-managed key to encrypt the information.
Requirements (aka. Acceptance Criteria):
The Installer will provide a mechanism to specify a user-managed key that will be used to encrypt the data on the virtual machines that are part of the OpenShift cluster as well as any other persistent storage managed by the platform via Storage Classes.
Background
This feature is a required component for IBM's OpenShift replatforming effort.
Documentation Considerations
The feature will be documented as usual to guide the user while using their own key to encrypt the data on the OpenShift cluster running on IBM Cloud VPC
Epic Goal
- Review and support the IBM engineering team while enabling BYOK support for OpenShift on IBM Cloud VPC
Why is this important?
- As part of the replatform work IBM is doing for their OpenShift managed service this feature is Key for that work
Scenarios
- The installer will allow the user to provide their own key information to be used to encrypt the VMs storage and any storage object managed by OpenShift StorageClass objects
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview
Support deploying an OpenShift cluster across multiple vSphere clusters, i.e. configuring multiple vCenter servers in one OpenShift cluster.
Goals
Multiple vCenter support in the Cloud Provider Interface (CPI) and the Cloud Storage Interface (CSI).
Use Cases
Customers want to deploy OpenShift across multiple vSphere clusters (vCenters) primarily for high availability.
粗文本*h3. *Feature Overview
Support deploying an OpenShift cluster across multiple vSphere clusters, i.e. configuring multiple vCenter servers in one OpenShift cluster.
Goals
Multiple vCenter support in the Cloud Provider Interface (CPI) and the Cloud Storage Interface (CSI).
Use Cases
Customers want to deploy OpenShift across multiple vSphere clusters (vCenters) primarily for high availability.
Done Done Done Criteria
This section contains all the test cases that we need to make sure work as part of the done^3 criteria.
- Clean install of new cluster with multi vCenter configuration
- Clean install of new cluster with single vCenter still working as previously
- VMs / machines can be scaled across all vCenters / Failure Domains
- PVs should be able to be created on all vCenters
Out-of-Scope
This section contains all scenarios that are considered out of scope for this enhancement that will be done via a separate epic / feature / story.
- Migration of single vCenter OCP to a multi vCenter (stretch
User Story
As an OpenShift administrator, I would like the Cluster Config Operator (CCO) to not block the install of a new cluster due to vSphere Multi vCenter feature gate being enabled so that I can begin to install my cluster across multiple vcenters.
Description
The purpose of this story is to perform the needed changes to get CCO allowing the configuration of the new Feature Gate for vSphere Multi vCenter support. This operator takes the infrastructure config by the installer and updates it for the cluster and applies it. The only change to this operator should be updating the version of openshift/api; however, this operator has a lot of legacy code that is being transitioned to openshift/api that is currently causing issues when updating openshift/api version. We will update the version and address any other modifications as need. We will need to work w/ the API team on what can be removed.
Required:
The CCO during installation will need to allow multiple vCenters to be configured. Any other failure reported based on issues performing operator tasks is valid and should be addressed via a new story.
ACCEPTANCE CRITERIA
- multi vcenter enabled: CCO does not prevent bootstrapping when more than one vCenter defined in the infrastructure custom resource.
- multi vcenter disabled: CCO will error out if vCenter count is greater than 1.
ENGINEERING DETAILS
We will need to do the following:
- Update version of openshift/api to be >= version where feature gate exists
- Update all broken aspects of the operator's existing logic dealing w/ legacy handling of features. This may get done by API team, but currently is not updated. The logic is skipped thanks to the --skip-rendering flag that exists in the bootkube.sh logic.
We will need to enhance all logic that has hard coded vCenter size to now look to see if vSphere Multi vCenter feature gate is enabled. If it is enabled, the vCenter count may be larger than 1, else it will still need to fail with the error message of vCenter count may not be greater than 1.
{}USER STORY:{}
As an OpenShift user, I need to span my clusters across multiple vCenters so that I can take advantage of multi-vCenter support. This will help me achieve better utilization, availability, , and redundancy across vCenter sites.
{}DESCRIPTION:{}
presently, only a single vCenter is allowed to be defined. the maximum number of allowed vCenters will take some thought but let's start with 3 for now.
see: https://github.com/openshift/api/blob/master/config/v1/types_infrastructure.go#L1325-L1334
{}ACCEPTANCE CRITERIA:{}
- Payload testing passes for the following job types:
- IPI tech-preview and non-tech-preview vSphere jobs
- UPI tech-preview and non-tech-preview vSphere jobs
{}ADDITIONAL INFORMATION:{}
Goal
As an OpenShift on vSphere administrator, I want to specify static IP assignments to my VMs.
As an OpenShift on vSphere administrator, I want to completely avoid using a DHCP server for the VMs of my OpenShift cluster.
Why is this important?
Customers want the convenience of IPI deployments for vSphere without having to use DHCP. As in bare metal, where METAL-1 added this capability, some of the reasons are the security implications of DHCP (customers report that for example depending on configuration they allow any device to get in the network). At the same time IPI deployments only require to our OpenShift installation software, while with UPI they would need automation software that in secure environments they would have to certify along with OpenShift.
Acceptance Criteria
- I can specify static IPs for node VMs at install time with IPI
Previous Work
Bare metal related work:
METAL-1- https://github.com/openshift/enhancements/blob/master/enhancements/network/baremetal-ipi-network-configuration.md
CoreOS Afterburn:
https://github.com/coreos/afterburn/blob/main/src/providers/vmware/amd64.rs#L28
https://github.com/openshift/installer/blob/master/upi/vsphere/vm/main.tf#L34
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Goal
As an OpenShift on vSphere administrator, I want to specify static IP assignments to my VMs.
As an OpenShift on vSphere administrator, I want to completely avoid using a DHCP server for the VMs of my OpenShift cluster.
Why is this important?
Customers want the convenience of IPI deployments for vSphere without having to use DHCP. As in bare metal, where METAL-1 added this capability, some of the reasons are the security implications of DHCP (customers report that for example depending on configuration they allow any device to get in the network). At the same time IPI deployments only require to our OpenShift installation software, while with UPI they would need automation software that in secure environments they would have to certify along with OpenShift.
Acceptance Criteria
- I can specify static IPs for node VMs at install time with IPI
Previous Work
Bare metal related work:
METAL-1- https://github.com/openshift/enhancements/blob/master/enhancements/network/baremetal-ipi-network-configuration.md
CoreOS Afterburn:
https://github.com/coreos/afterburn/blob/main/src/providers/vmware/amd64.rs#L28
https://github.com/openshift/installer/blob/master/upi/vsphere/vm/main.tf#L34
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
We need to ensure that when vSphere static IP IPI install is being performed, we need to make sure the masters that are generated are treated as valid machines and do not get recreated by CPMS operator.
{}USER STORY:{}
As a system admin, I would like the static IP support for vSphere to use IPAddressClaims to provide IP address during installation so that after the install, the machines are defined in a way that is intended for use with IPAM controllers.
{}DESCRIPTION:{}
Currently the installer for vSphere will directly set the static IPs into the machine object yaml files. We would like to enhance the installer to create IPAddress, IPAddressClaim for each machine as well as update the machinesets to use addressesFromPools to request the IPAddress. Also, we should create a custom CRD that is the basis for the pool defined in the addressesFromPools field.
{}ACCEPTANCE CRITERIA:{}
After installing static IP for vSphere IPI, the cluster should contain machines, machinesets, crd, ipaddresses and ipaddressclaims related to static IP assignment.
{}ENGINEERING DETAILS:{}
These changes should all be contained in the installer project. We will need to be sure to cover static IP for zonal and non-zonal installs. Additionally, we need to have this work for all control-plane and compute machines.
Feature Overview
Add authentication to the internal components of the Agent Installer so that the cluster install is secure.
Goals
- Day1: Only allow agents booted from the same agent ISO to register with the assisted-service and use the agent endpoints
- Day2: Only allow agents booted from the same node ISO to register with the assisted-service and use the agent endpoints
Only allow access to write endpoints to the internal servicesUse authentication to read endpoints
Epic Goal
- This epic scope was originally to encompass both authentication and authorization but we have split the expanding scope into a separate epic.
- We want to add authorization to the internal components of Agent Installer so that the cluster install is secure.
Why is this important?
- The Agent Installer API server (assisted-service) has several methods for Authorization but none of the existing methods are applicable tothe Agent Installer use case.
- During the MVP of Agent Installer we attempted to turn on the existing authorization schemes but found we didn't have access to the correct API calls.
- Without proper authorization it is possible for an unauthorized node to be added to the cluster during install. Currently we expect this to be done as a mistake rather than maliciously.
Brainstorming Notes:
Requirements
- Allow only agents booted from the same ISO to register with the assisted-service and use the agent endpoints
- Agents already know the InfraEnv ID, so if read access requires authentication then that is sufficient in some existing auth schemes.
- Prevent access to write endpoints except by the internal systemd services
- Use some kind of authentication for read endpoints
Ideally use existing credentials - admin-kubeconfig client cert and/or kubeadmin-password
(Future) Allow UI access in interactive mode only
Are there any requirements specific to the auth token?
- Ephemeral
- Limited to one cluster:
Reuse the existing admin-kubeconfig client cert
Actors:
- Agent Installer: example wait-for
- Internal systemd: configurations, create cluster infraenv, etc
UI: interactive userUser: advanced automation user (not supported yet)
Do we need more than one auth scheme?
Agent-admin - agent-read-write
Agent-user - agent-read
Options for Implementation:
- New auth scheme in assisted-service
Reverse proxy in front of assisted-service APIUse an existing auth scheme in assisted-service
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Previous Work (Optional):
AGENT-60Originally we wanted to just turn on local authorization for Agent Installer workflows. It was discovered this was not sufficient for our use case.
Open questions::
- Which API endpoints do we need for the interactive flow?
- What auth scheme does the Assisted UI use if any?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a user, when running agent create image, agent create pxe-files and agent create config iso commands, I want to be able to:
- generate ECDSA private key Generating ECDSA key pair and save it to asset store
- generate ECDSA public key Generating ECDSA key pair and save it to asset store
- set generated public/priv keys into appropriate env var EC_PUBLIC_KEY_PEM , EC_PRIVATE_KEY_PEM
- pass env var to assisted service.
so that I can achieve
- authentication for the APIs.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a user, when running agent create image, agent create pxe-files and agent create config iso commands, I want to be able to:
- generate non-expiring local JWT tokens and save it in asset store. Generating JWTs using ECDSA private key
so that I can achieve
- authentication for the APIs.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Epic Goal
- Update all images that we ship with OpenShift to the latest upstream releases and libraries.
- Exact content of what needs to be updated will be determined as new images are released upstream, which is not known at the beginning of OCP development work. We don't know what new features will be included and should be tested and documented. Especially new CSI drivers releases may bring new, currently unknown features. We expect that the amount of work will be roughly the same as in the previous releases. Of course, QE or docs can reject an update if it's too close to deadline and/or looks too big.
Traditionally we did these updates as bugfixes, because we did them after the feature freeze (FF).
Why is this important?
- We want to ship the latest software that contains new features and bugfixes.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Update all OCP and kubernetes libraries in storage operators to the appropriate version for OCP release.
This includes (but is not limited to):
- Kubernetes:
- client-go
- controller-runtime
- OCP:
- library-go
- openshift/api
- openshift/client-go
- operator-sdk
Operators:
- aws-ebs-csi-driver-operator (in csi-operator)
- aws-efs-csi-driver-operator
- azure-disk-csi-driver-operator
- azure-file-csi-driver-operator
- openstack-cinder-csi-driver-operator
- gcp-pd-csi-driver-operator
- gcp-filestore-csi-driver-operator
- csi-driver-manila-operator
- vmware-vsphere-csi-driver-operator
- alibaba-disk-csi-driver-operator
- ibm-vpc-block-csi-driver-operator
- csi-driver-shared-resource-operator
- ibm-powervs-block-csi-driver-operator
- secrets-store-csi-driver-operator
- cluster-storage-operator
- cluster-csi-snapshot-controller-operator
- local-storage-operator
- vsphere-problem-detector
EOL, do not upgrade:
- github.com/oVirt/csi-driver-operator
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Goal
Hardware RAID support on Dell, Supermicro and HPE with Metal3.
Why is this important
Setting up RAID devices is a common operation in the hardware for OpenShift nodes. While there's been work at Fujitsu for configuring RAID in Fujitsu servers with Metal3, we don't support any generic interface with Redfish to extend this support and set it up it in Metal3.
Dell, Supermicro and HPE, which are the most common hardware platforms we find in our customers environments are the main target.
Goal
Hardware RAID support on Dell with Metal3.
Why is this important
Setting up RAID devices is a common operation in the hardware for OpenShift nodes. While there's been work at Fujitsu for configuring RAID in Fujitsu servers with Metal3, we don't support any generic interface with Redfish to extend this support and set it up it in Metal3 for Dell, which are the most common hardware platforms we find in our customers environments.
Before implementing generic support, we need to understand the implications of enabling an interface in Metal3 to allow it on multiple hardware types.
Scope questions
- Changes in Ironic?
- Maybe, but it should be there?
- Changes in Metal3?
- Hopefully small, it should be there for Fujitsu
- Changes in OpenShift?
- Hopefully small, it should be there for Fujitsu
- Spec/Design/Enhancements?
- Ironic: no (supports this already)
- Metal3: no (ditto)
- OpenShift:
https://github.com/openshift/enhancements/blob/master/enhancements/baremetal/baremetal-config-raid-and-bios.md
- Dependencies on other teams?
- No
While rendering BMO in https://issues.redhat.com/browse/METAL-829 the node cpu_arch was hardcoded to x86_64
We should use bmh.Spec.Architecture instead to be more future proof
Feature Overview
- As a Cluster Administrator, I want to opt-out of certain operators at deployment time using any of the supported installation methods (UPI, IPI, Assisted Installer, Agent-based Installer) from UI (e.g. OCP Console, OCM, Assisted Installer), CLI (e.g. oc, rosa), and API.
- As a Cluster Administrator, I want to opt-in to previously-disabled operators (at deployment time) from UI (e.g. OCP Console, OCM, Assisted Installer), CLI (e.g. oc, rosa), and API.
- As a ROSA service administrator, I want to exclude/disable Cluster Monitoring when I deploy OpenShift with HyperShift — using any of the supported installation methods including the ROSA wizard in OCM and rosa cli — since I get cluster metrics from the control plane. This configuration should be persisted through not only through initial deployment but also through cluster lifecycle operations like upgrades.
- As a ROSA service administrator, I want to exclude/disable Ingress Operator when I deploy OpenShift with HyperShift — using any of the supported installation methods including the ROSA wizard in OCM and rosa cli — as I want to use my preferred load balancer (i.e. AWS load balancer). This configuration should be persisted through not only through initial deployment but also through cluster lifecycle operations like upgrades.
Goals
- Make it possible for customers and Red Hat teams producing OCP distributions/topologies/experiences to enable/disable some CVO components while still keeping their cluster supported.
Scenarios
- This feature must consider the different deployment footprints including self-managed and managed OpenShift, connected vs. disconnected (restricted and air-gapped), supported topologies (standard HA, compact cluster, SNO), etc.
- Enabled/disabled configuration must persist throughout cluster lifecycle including upgrades.
- If there's any risk/impact of data loss or service unavailability (for Day 2 operations), the System must provide guidance on what the risks are and let user decide if risk worth undertaking.
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This part of the overall multiple release Composable OpenShift (OCPPLAN-9638 effort), which is being delivered in multiple phases:
Phase 1 (OpenShift 4.11): OCPPLAN-7589 Provide a way with CVO to allow disabling and enabling of operators
CORS-1873Installer to allow users to select OpenShift components to be included/excludedOTA-555Provide a way with CVO to allow disabling and enabling of operatorsOLM-2415Make the marketplace operator optionalSO-11Make samples operator optionalMETAL-162Make cluster baremetal operator optionalOCPPLAN-8286CI Job for disabled optional capabilities
Phase 2 (OpenShift 4.12): OCPPLAN-7589 Provide a way with CVO to allow disabling and enabling of operators
CONSOLE-3160Make console operator optionalCCXDEV-8079Make Insights operator optionalCNF-5645Make storage operator optionalCNF-5646Make csi-snapshot-controller optional
Phase 3 (OpenShift 4.13): OCPBU-117
OTA-554Make oc aware of cluster capabilitiesPSAP-741Make Node Tuning Operator (including PAO controllers) optional
Phase 4 (OpenShift 4.14): OCPSTRAT-36 (formerly OCPBU-236)
OCPBU-352Make Ingress Operator optionalCCO-186ccoctl support for credentialing optional capabilitiesMCO-499MCD should manage certificates via a separate, non-MC path (formerlyIR-230Make node-ca managed by CVO)CNF-5642Make cluster autoscaler optionalCNF-5643- Make machine-api operator optionalWRKLDS-695- Make DeploymentConfig API + controller optionalCNV-16274OpenShift Virtualization on the Red Hat Application Cloud (not applicable)
Phase 4 (OpenShift 4.14): OCPSTRAT-36 (formerly OCPBU-236)
CCO-186ccoctl support for credentialing optional capabilitiesMCO-499MCD should manage certificates via a separate, non-MC path (formerlyIR-230Make node-ca managed by CVO)CNF-5642Make cluster autoscaler optionalCNF-5643- Make machine-api operator optionalWRKLDS-695- Make DeploymentConfig API + controller optionalCNV-16274OpenShift Virtualization on the Red Hat Application Cloud (not applicable)CNF-9115- Leverage Composable OpenShift feature to make control-plane-machine-set optionalBUILD-565- Make Build v1 API + controller optionalCNF-5647Leverage Composable OpenShift feature to make image-registry optional (replacesIR-351- Make Image Registry Operator optional)
Phase 5 (OpenShift 4.15): OCPSTRAT-421 (formerly OCPBU-519)
OCPVE-634- Leverage Composable OpenShift feature to make olm optionalCCO-419(OCPVE-629) - Leverage Composable OpenShift feature to make cloud-credential optional
Phase 6 (OpenShift 4.16): OCPSTRAT-731
OCPSTRAT-346(OCPBU-352) Make Ingress Operator optionalOCPCLOUD-2151(OCPVE-628) - Leverage Composable OpenShift feature to make cloud-controller-manager optional
Phase 7 (OpenShift 4.17): OCPSTRAT-1308
- MON-3152 (OBSDA-242) Optional built-in monitoring
- IR-400 - Remove node-ca from CIRO*
- CNF-9116 Leverage Composable OpenShift feature to machine-auto-approver optional
- CCO-493 Make Cloud Credential Operator optional for remaining providers and topologies (non-SNO topologies)
References
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Feature Overview
Extend OpenShift on IBM Cloud integration with additional features to pair the capabilities offered for this provider integration to the ones available in other cloud platforms.
Goals
Extend the existing features while deploying OpenShift on IBM Cloud.
Background, and strategic fit
This top level feature is going to be used as a placeholder for the IBM team who is working on new features for this integration in an effort to keep in sync their existing internal backlog with the corresponding Features/Epics in Red Hat's Jira.
Epic Goal
- Enable installation of disconnected clusters on IBM Cloud. This epic will track associated work.
Why is this important?
- Would like to support this at GA. It is an 'optional' feature that will be pursued after completing private cluster installation support ( https://issues.redhat.com/browse/SPLAT-731 ).
Scenarios
- Install a disconnected cluster on IBM Cloud.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
User Story:
A user currently is not able to create a Disconnected cluster, using IPI, on IBM Cloud.
Currently, support for BYON and Private clusters does exist on IBM Cloud, but support to override IBM Cloud Service endpoints does not exist, which is required to allow for Disconnected support to function (reach IBM Cloud private endpoints).
Description:
IBM dependent components of OCP will need to add support to use a set of endpoint override values in order to reach IBM Cloud Services in Disconnected environments.
The Image Registry components will need to be able to allow all API calls to IBM Cloud Services, be directed to these endpoint values, in order to communicate in environments where the Public or default IBM Cloud Service endpoint is not available.
The endpoint overrides are available via the infrastructure/cluster (.status.platformStatus.ibmcloud.serviceEndpoints) resource, which is how a majority of components are consuming cluster specific configurations (Ingress, MAPI, etc.). It will be structured as such
apiVersion: config.openshift.io/v1 kind: Infrastructure metadata: creationTimestamp: "2023-10-04T22:02:15Z" generation: 1 name: cluster resourceVersion: "430" uid: b923c3de-81fc-4a0e-9fdb-8c4c337fba08 spec: cloudConfig: key: config name: cloud-provider-config platformSpec: type: IBMCloud status: apiServerInternalURI: https://api-int.us-east-disconnect-21.ipi-cjschaef-dns.com:6443 apiServerURL: https://api.us-east-disconnect-21.ipi-cjschaef-dns.com:6443 controlPlaneTopology: HighlyAvailable cpuPartitioning: None etcdDiscoveryDomain: "" infrastructureName: us-east-disconnect-21-gtbwd infrastructureTopology: HighlyAvailable platform: IBMCloud platformStatus: ibmcloud: dnsInstanceCRN: 'crn:v1:bluemix:public:dns-svcs:global:a/fa4fd9fa0695c007d1fdcb69a982868c:f00ac00e-75c2-4774-a5da-44b2183e31f7::' location: us-east providerType: VPC resourceGroupName: us-east-disconnect-21-gtbwd serviceEndpoints: - name: iam url: https://private.us-east.iam.cloud.ibm.com - name: vpc url: https://us-east.private.iaas.cloud.ibm.com/v1 - name: resourcecontroller url: https://private.us-east.resource-controller.cloud.ibm.com - name: resourcemanager url: https://private.us-east.resource-controller.cloud.ibm.com - name: cis url: https://api.private.cis.cloud.ibm.com - name: dnsservices url: https://api.private.dns-svcs.cloud.ibm.com/v1 - name: cis url: https://s3.direct.us-east.cloud-object-storage.appdomain.cloud type: IBMCloud
The CCM is currently relying on updates to the openshift-cloud-controller-manager/cloud-conf configmap, in order to override its required IBM Cloud Service endpoints, such as:
data: config: |+ [global] version = 1.1.0 [kubernetes] config-file = "" [provider] accountID = ... clusterID = temp-disconnect-7m6rw cluster-default-provider = g2 region = eu-de g2Credentials = /etc/vpc/ibmcloud_api_key g2ResourceGroupName = temp-disconnect-7m6rw g2VpcName = temp-disconnect-7m6rw-vpc g2workerServiceAccountID = ... g2VpcSubnetNames = temp-disconnect-7m6rw-subnet-compute-eu-de-1,temp-disconnect-7m6rw-subnet-compute-eu-de-2,temp-disconnect-7m6rw-subnet-compute-eu-de-3,temp-disconnect-7m6rw-subnet-control-plane-eu-de-1,temp-disconnect-7m6rw-subnet-control-plane-eu-de-2,temp-disconnect-7m6rw-subnet-control-plane-eu-de-3 iamEndpointOverride = https://private.iam.cloud.ibm.com g2EndpointOverride = https://eu-de.private.iaas.cloud.ibm.com rmEndpointOverride = https://private.resource-controller.cloud.ibm.com
Acceptance Criteria:
Installer validates and injects user provided endpoint overrides into cluster deployment process and the Image Registry components use specified endpoints and start up properly.
Note: phase 2 target is tech preview.
Feature Overview
In the initial delivery of CoreOS Layering, it is required that administrators provide their own build environment to customize RHCOS images. That could be a traditional RHEL environment or potentially an enterprising administrator with some knowledge of OCP Builds could set theirs up on-cluster.
The primary virtue of an on-cluster build path is to continue using the cluster to manage the cluster. No external dependency, batteries-included.
On-cluster, automated RHCOS Layering builds are important for multiple reasons:
- One-click/one-command upgrades of OCP are very popular. Many customers may want to make one or just a few customizations but also want to keep that simplified upgrade experience.
- Customers who only need to customize RHCOS temporarily (hotfix, driver test package, etc) will find off-cluster builds to be too much friction for one driver.
- One of OCP's virtues is that the platform and OS are developed, tested, and versioned together. Off-cluster building breaks that connection and leaves it up to the user to keep the OS up-to-date with the platform containers. We must make it easy for customers to add what they need and keep the OS image matched to the platform containers.
Goals & Requirements
- The goal of this feature is primarily to bring the 4.14 progress (
OCPSTRAT-35) to a Tech Preview or GA level of support. - Customers should be able to specify a Containerfile with their customizations and "forget it" as long as the automated builds succeed. If they fail, the admin should be alerted and pointed to the logs from the failed build.
- The admin should then be able to correct the build and resume the upgrade.
- Intersect with the Custom Boot Images such that a required custom software component can be present on every boot of every node throughout the installation process including the bootstrap node sequence (example: out-of-box storage driver needed for root disk).
- Users can return a pool to an unmodified image easily.
- RHEL entitlements should be wired in or at least simple to set up (once).
- Parity with current features – including the current drain/reboot suppression list, CoreOS Extensions, and config drift monitoring.
Allow attaching an ISO image that will be used for data on an already provisioned system using a BMH.
Currently this can be achieved using the existing BMH.Spec.Image fields, but this attempts to change the boot order of the system and relies on the host to fallback to the installed system when booting the image fails.
Scope questions:
- Changes in Ironic?
- Can we introduce an actual Ironic API for this (instead of vendor passhtru)?
- Dmitry probed the community, the initial reaction was positive.
- The functionality is probably mostly there but needs to be exposed
We'll likely also need to add support for this into Sushy- We expect the machine will already be provisioned when the ISO is attached
- Can we introduce an actual Ironic API for this (instead of vendor passhtru)?
- Changes in Metal3?
- Yes, we'll need new functionality in the BMH
- Changes in OpenShift?
- no install-config or installer change
- Spec/Design/Enhancements?
- Ironic: probably not, but an RFE for sure
- Metal3: probably yes, an API addition
- OpenShift: no
- Dependencies on other teams?
- Telco field folks to help us bring hardware we can validate the approach on?
- We can test on our hardware after a normal deployment
- Telco field folks to help us bring hardware we can validate the approach on?
Neither logging nor node.last_error is handled.
while the basic implementation of the API is done, we need to add the functionality to the redfish driver
Feature Overview
Create a GCP cloud specific spec.resourceTags entry in the infrastructure CRD. This should create and update tags (or labels in GCP) on any openshift cloud resource that we create and manage. The behaviour should also tag existing resources that do not have the tags yet and once the tags in the infrastructure CRD are changed all the resources should be updated accordingly.
Tag deletes continue to be out of scope, as the customer can still have custom tags applied to the resources that we do not want to delete.
Due to the ongoing intree/out of tree split on the cloud and CSI providers, this should not apply to clusters with intree providers (!= "external").
Once confident we have all components updated, we should introduce an end2end test that makes sure we never create resources that are untagged.
Goals
- Functionality on GCP GA
- inclusion in the cluster backups
- flexibility of changing tags during cluster lifetime, without recreating the whole cluster
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
List any affected packages or components.
- Installer
- Cluster Infrastructure
- Storage
- Node
- NetworkEdge
- Internal Registry
- CCO
Installer creates below list of gcp resources during create cluster phase and these resources should be applied with the user defined tags.
Resources List
| Resource | Terraform API |
|---|---|
| VM Instance | google_compute_instance |
| Storage Bucket | google_storage_bucket |
Acceptance Criteria:
- Code linting, validation and best practices adhered to
- List of gcp resources created by installer should have user defined labels and as well as the default OCP label.
Enhancement proposed for GCP tags support in OCP, requires machine-api-provider-gcp to add azure userTags available in the status sub resource of infrastructure CR, to the gcp virtual machine resources created.
Acceptance Criteria
- Code linting, validation and best practices adhered to
- UTs and e2e are added/updated
This Feature covers effort in person-weeks of meetings in #wg-managed-ocp-versions where OTA helped SD refine how their doing OCM work would help, and what that OCM work might look like https://issues.redhat.com/browse/OTA-996?focusedId=25608383&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-25608383.
Background.
Currently the ROSA/ARO versions are not managed by OTA team.
This Feature covers the engineering effort to take the responsibility of management of OCP version management in OSD, ROSA and ARO from SRE-P to OTA.
Here is the design document for the effort: https://docs.google.com/document/d/1hgMiDYN9W60BEIzYCSiu09uV4CrD_cCCZ8As2m7Br1s/edit?skip_itp2_check=true&pli=1
Here are some objectives :
- Managed clusters would get update recommendations from Red Hat hosted OSUS directly without much middle layers like ClusterImageSet.
- The new design should reduce the cost of maintaining versions for managed clusters including Hypershift hosted control planes.
Presentation from Jeremy Eder :
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
This epic is to transfer the responsibility of OCP version management in OSD, ROSA and ARO from SRE-P to OTA.
- The responsibility of management of OCP versions available to all self-managed OCP customers lies with the OTA team.
- This responsibility makes the OTA team the center of excellence around version health.
- The responsibility of management of OCP versions available to managed customers lies with the SRE-P team. Why do this project:
- The SREP team took on version management responsibility out of necessity. Code was written and maintained to serve a service-tailored "version list". This code requires effort to maintain.
- As we begin to sell more managed OCP, it makes sense to move this responsibility back to the OTA team as this is not an "SRE" focused activity.
- As the CoE for version health, the OTA team has the most comprehensive overview of code health.
- The OTA team would benefit by coming up to speed on managed OCP-specific lifecycles/policies as well as become aware of the "why" for various policies where they differ from self-managed OCP.
Why is this important? (mandatory)
What are the benefits to the customer or Red Hat? Does it improve security, performance, supportability, etc? Why is work a priority?
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Tests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Other
To deliver RFE-5160 without passing data through the customer-accessible ClusterVersion resource (which lives in the hosted Kubernetes API), the cluster-version operator should grow a new command-line switch that allows its caller to override ClusterVersion with a custom upstream.
Definition of done:
- The CVO can be executed with --upstream-update-service https://example.com. When set, the CVO will ignore spec.upstream in ClusterVersion and instead use the value passed in via the command-line option.
Or similar knob to deliver RFE-5160, attaching the new parameter to OTA-1210's command-line flag.
Definition of done:
Management cluster admins can set spec.updateService on HostedCluster and have their status.version.availableUpdates and similar populated based on advice from that upstream. At no point in the implementation is the update service data pulled from anywhere accessible from the hosted cluster.
Epic Goal
- Enable users to install a host as day2 using agent based installer
Why is this important?
- Enable easy day2 installation without requiring additional knowledge from the user
- Unified experience for day1 and day2 installation for the agent based installer
- Unified experience for day1 and day2 installation for appliance workflow
- Eliminate the requirement of installing MCE that have high requirements (requires 4 cores and 16GB RAM for a multi-node cluster, and if the infrastructure operator is included then it will require storage as well)
- Eliminate the requirement of nodes having a BMC available to expand bare metal clusters (see docs).
- Simplify adding compute nodes based on the the UPI method or other method implemented in the field such as
WKLD-433or other automations that try to solve this problem
Scenarios
- User installed day1 cluster with agent based install and want to add workers or replace failed nodes, currently alternative is to install MCE or, if connected, use SAAS.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
- N/A
Previous Work (Optional):
ABI is using assisted installer + kube-api or any other client that communicate with the service, all the building blocks related to day2 installation exist in those components
Assisted installer can create installed cluster and use it to perform day2 operations
A doc that explains how it's done with kube-api
Parameters that are required from the user:
- Cluster name,Domain name - used to get the url that will be used to pull ignition
- Kubeconfig to day1 cluster
- Openshift version
- Network configuration
Actions required from the user
- Post reboot the user will need to manually approve the node on the day1 cluster
Implementation suggestion:
To keep similar flow between day1 and day2 i suggest to run the service on each node that user is trying to add, it will create the cluster definition and start the installation, after first reboot it will pull the ignition from the day1 cluster
Open questions::
- How should ABI detect an existing day1 cluster? Yes
- Using a provided kubeconfig file? Yes
- If so, should it be added to the config-image API (i.e. included in the ISO) - question to the agent team
- Should we add a new command for day2 in agent-installer-client? E.g. question to the agent team
- So this command would import the existing day1 cluster and add the day2 node. It means that every day2 node should run an assisted-service first
 Yes, those instances are not depending on each other
Yes, those instances are not depending on each other
It will need to create the container, set it up with an appropriate kubeconfig, extract and appropriately direct the output (ISO+any errors or streamed status), and delete the container again when complete. Initially could be a script, but potentially could be implemented directly in the code. To be distributed within the installer image
It will need to create the container, set it up with an appropriate kubeconfig, extract and appropriately direct the output (ISO+any errors or streamed status), and delete the container again when complete. Initially could be a script, but potentially could be implemented directly in the code. To be distributed within the installer image
Deploy a command to generate a suitable ISO for adding a node to an existing cluster
Not all the required info are provided by the user (in reality, we do want to minimize as much as possible the amount of configuration provided by the user). Some of the required info needs to be extracted from the existing cluster, or from the existing kubeconfig. A dedicated asset could be useful for such operation.
The ignition assets currently assembles the ignition file with the requires files and services to install a cluster. In case of add node, this needs to be modified to support the new workflow.
A new workflow will be required to talk to assisted-service to import an existing cluster / add the node.New services could be required in the ignition assets to handle properly that
Usually the manifests assets (ClusterImageSet / AgentPullSecret / InfraEnv / NMStateConfig / AgentClusterInstall / ClusterDeployment) depends on OptionInstallConfig (or eventually a file on the asset dir, in case of ZTP manifests). We'll need to change the assets code so that it could be possible to retrieve the required info from ClusterInfo asset instead of OptionalInstallConfig). This may impact the asset framework itself.
Another approach could be to stick this info directly into OptionalInstallConfig, if possible
Create a new asset to manage the content of the nodes-config.yaml file
The two commands, one for adding the nodes (ISO generation) and the other to monitor the process, should be exposed by a new cli tool (name to be defined) built using the installer source. This task will be used to add the main of the cli tool and the two (empty) commands entry points
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
With ovn-ic we have multiple actors (zones) setting status on some CRs. We need to make sure individual zone statuses are reported and then optionally merged to a single status
Why is this important?
Without that change zones will overwrite each others statuses.
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
 Priority+ is set by engineering
Priority+ is set by engineering- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Background
The MCO does not reap any old rendered machineconfigs. Each time a user or controller applies a new machineconfig, there are new rendered configs for each affected machineconfigpool. Over time, this leads to a very large number of rendered configs which are a UX annoyance but also could possibly contribute to space and performance issues with etcd.
Goals (aka. expected user outcomes)
Administrators should have a simple way to set a maximum number of rendered configs to maintain, but there should also be a minimum set as there are many cases where support or engineering needs to be able to look back at previous configs.
This story involves implementing the main "deletion" command for rendered machineconfigs under the oc adm prune subcommand. It will only support deleting rendered MCs that are not in use.
It would support the following options to start:
- Pool name, which indicates the owner of the rendered MCs to target. This argument is not required. If not set, all pools will be evaluated.
- Count, which describes a max number of rendered MCs to delete, oldest first. This argument is not required.
- Confirm flag, which will cause the prune to take place. If not set, the command will be run in dry run mode. This argument is not required.
Important: If the admin specifies options that select any rendered MCs that are in use by an MCP, it should not be deleted. In such cases, the output should indicate why the rendered MC has been skipped over for deletion.
Sample user workflow:
$ oc adm prune renderedmachineconfigs --pool-name=worker # lists and deletes all unused rendered MCs for the worker pool in a dry run mode $ oc adm prune renderedmachineconfigs --count=10 --pool-name=worker # lists and deletes 10 oldest unused rendered MCs for the worker pool in a dry run mode $ oc adm prune renderedmachineconfigs --count=10 --pool-name=worker --confirm # actually deletes the rendered configs with the above options
< High-Level description of the feature ie: Executive Summary >
Goals
Cluster administrators need an in-product experience to discover and install new Red Hat offerings that can add high value to developer workflows.
Requirements
| Requirements | Notes | IS MVP |
| Discover new offerings in Home Dashboard | Y | |
| Access details outlining value of offerings | Y | |
| Access step-by-step guide to install offering | N | |
| Allow developers to easily find and use newly installed offerings | Y | |
| Support air-gapped clusters | Y |
< What are we making, for who, and why/what problem are we solving?>
Out of scope
Discovering solutions that are not available for installation on cluster
Dependencies
No known dependencies
Background, and strategic fit
Assumptions
None
Customer Considerations
Documentation Considerations
Quick Starts
What does success look like?
QE Contact
Impact
Related Architecture/Technical Documents
Done Checklist
- Acceptance criteria are met
- Non-functional properties of the Feature have been validated (such as performance, resource, UX, security or privacy aspects)
- User Journey automation is delivered
- Support and SRE teams are provided with enough skills to support the feature in production environment
Problem:
Cluster admins need to be guided to install RHDH on the cluster.
Goal:
Enable admins to discover RHDH, be guided to installing it on the cluster, and verifying its configuration.
Why is it important?
RHDH is a key multi-cluster offering for developers. This will enable customers to self-discover and install RHDH.
Acceptance criteria:
- Show RHDH card in Admin->Dashboard view
- Enable link to RHDH documentation from the card
- Quick start to install RHDH operator
- Guided flow to installation and configuration of operator from Quick Start
- RHDH UI link in top menu
- Successful log in to RHDH
Dependencies (External/Internal):
RHDH operator
Design Artifacts:
Exploration:
Note:
Description of problem:
The OpenShift Console QuickStarts that promotes RHDH was written in generic terms and doesn't include some information on how to use the CRD-based installation.
We have removed this specific information because the operator wasn't ready at that time. As soon as the RHDH operator is available in the OperatorHub we should update the QuickStarts with some more detailed information.
With a simple CR example and some info on how to customize the base URL or colors.
Version-Release number of selected component (if applicable):
4.15
How reproducible:
Always
Steps to Reproduce:
Just navigate to Quick starts and select the "Install Red Hat Developer Hub (RHDH) with an Operator" quick starts
Actual results:
The RHDH Operator Quick start exists but is written in a generic way.
Expected results:
The RHDH Operator Quick start should contain some more specific information.
Additional info:
Initial PR: https://github.com/openshift/console-operator/pull/806
Description of problem:
The OpenShift Console QuickStarts promotes RHDH but also includes Janus IDP information.
The Janus IDP quick starts should be removed and all information about Janus IDP should be removed.
Version-Release number of selected component (if applicable):
4.15
How reproducible:
Always
Steps to Reproduce:
Just navigate to Quick starts and select the "Install Red Hat Developer Hub (RHDH) with an Operator" quick starts
Actual results:
- The RHDH Operator Quick start contains some information and links to Janus IDP.
- The Janus IDP Quick start exists and is similar to the RHDH one.
Expected results:
- The RHDH Operator Quick start must not contain information about Janus IDP.
- The Janus IDP Quick start should be removed
Additional info:
Initial PR: https://github.com/openshift/console-operator/pull/806
DoD
We need to ensure we have parity with OCP and support heterogeneous clusters
https://github.com/openshift/enhancements/pull/1014
- Define UX for multi arch NodePool input. E.g always enforce multi arch image, this might not be possible because of impact for image registry on disconnected clusters https://github.com/openshift/enhancements/pull/1014#discussion_r798444099.
Goal
- Provide a way to install with varied architecture NodePools with the ability to autoscale
- Define UX for multi arch NodePool input. E.g always enforce multi arch image, this might not be possible because of impact for image registry on disconnected clusters https://github.com/openshift/enhancements/pull/1014#discussion_r798444099.
Why is this important?
- Necessary to enable workloads with different architectures in the same Hosted Clusters.
- Cost savings brought by more cost effective ARM instances
Scenarios
- I have an x86 hosted cluster and I want to have at least one NodePool running ARM workloads
- I have an ARM hosted cluster and I want to have at least one NodePool running x86 workloads
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
Dependencies (internal and external)
- The management cluster must use a multi architecture payload image.
- The target architecture is in the OCP payload
- MCE has builds for the architecture used by the worker nodes of the management cluster
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Goal
- As a user of the HyperShift, I would like the CLI or HyperShift API to fail early when:
-
- the release image is not multi-arch AND
- the management cluster's CPU architecture is not the same as the NodePool's CPU architecture
so that we can prevent a HostedCluster or a NodePool from being created that will have errors due mismatches between the release image, management cluster's CPU architecture, and NodePool's CPU architecture.
Why is this important?
- This improves the UX of using multi-arch HyperShift by preventing a user from utilizing the wrong release image when creating a HostedCluster or NodePool.
Scenarios
- Scenarios That Should Succeed
- Using a mgmt cluster of CPU arch 'A', create a HostedCluster with the CLI with a multi-arch release image
- Using a mgmt cluster of CPU arch 'A', create a HostedCluster with a yaml spec with a multi-arch release image
- Using a mgmt cluster of CPU arch 'A', create a NodePool with the CLI with a multi-arch release image
- Using a mgmt cluster of CPU arch 'A', create a NodePool with a yaml spec with a multi-arch release image
- Scenarios That Should Fail
- Using a mgmt cluster of CPU arch 'A', create a HostedCluster with the CLI with a single arch release image from CPU arch 'B'
- Using a mgmt cluster of CPU arch 'A', create a HostedCluster with a yaml spec with a single arch release image from CPU arch 'B'
- Using a mgmt cluster of CPU arch 'A', create a NodePool with the CLI with a single arch release image from CPU arch 'B'
- Using a mgmt cluster of CPU arch 'A', create a NodePool with a yaml spec with a single arch release image from CPU arch 'B'
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a user of the HyperShift CLI, I would like the CLI to fail early if these conditions are all true:
- the release image is not multi-arch
- the management cluster's CPU architecture is not the same as the NodePool's CPU architecture
so that we can prevent a HostedCluster from being created that will have errors due mismatches between the release image, management cluster's CPU architecture, and NodePool's CPU architecture.
Acceptance Criteria:
- The HyperShift CLI fails to create a cluster when the release image is not multi-arch and the management cluster's CPU architecture does not match the NodePool's CPU architecture.
- There is documentation providing information the CLI will fail when it meets the conditions above.
(optional) Out of Scope:
This should be done for the API as well but will be covered thru HOSTEDCP-1105.
Engineering Details:
- HyperShift CLI currently defaults to a multi-arch image in version.go.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a user of the HCP CLI, I want to be able to specify a NodePools arch from a flag so that I can easily create NodePools of different CPU architectures in AWS HostedClusters.
Acceptance Criteria:
- The HCP CLI contains a `arch` flag for the create cluster command for AWS.
- The HCP CLI contains a `arch` flag for the create nodepool command for AWS.
- The HCP CLI contains a `multi-arch` flag for the create cluster command for AWS.
- The only valid values for the arch flag are:
- amd64
- arm64
Out of Scope:
Other CPU arches are not being considered for the arch flag since they are unavailable in AWS.
Engineering Details:
- N/A
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a user of the HyperShift, I would like the API to fail early if these conditions are all true:
- the release image is not multi-arch
- the management cluster's CPU architecture is not the same as the NodePool's CPU architecture
so that we can prevent a HostedCluster from continuing to be created that will have errors due mismatches between the release image, management cluster's CPU architecture, and NodePool's CPU architecture.
Acceptance Criteria:
- The HyperShift API fails to create a cluster when the release image is not multi-arch and the management cluster's CPU architecture does not match the NodePool's CPU architecture.
- There is documentation providing information the API will fail when it meets the conditions above.
Out of Scope:
This should be done for the CLI as well but will be covered thru HOSTEDCP-1104.
Engineering Details:
- HyperShift CLI currently defaults to a multi-arch image in version.go.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
Using a multi-arch Node requires the HC to be multi arch as well. This is an good to recipe to let users shoot on their foot. We need to automate the required input via CLI to multi-arch NodePool to work, e.g. on HC creation enabling a multi-arch flag which sets the right release image
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
Using a multi-arch Node requires the HC to be multi arch as well. This is an good to recipe to let users shoot on their foot. We need to automate the required input via CLI to multi-arch NodePool to work, e.g. on HC creation enabling a multi-arch flag which sets the right release image
Acceptance Criteria:
- Upstream documentation
- HyperShift CLI accomplishes design specified in the document in the Engineering Details section
- HCP CLI accomplishes design specified in the document in the Engineering Details section
Out of Scope:
Engineering Details:
User Story:
As a user of multi-arch HyperShift, I would like a CEL validation to be added to the NodePool types to prevent the arch field from being changed from `amd64` when the platform is not supported (AWS is currently the only supported platform).
Acceptance Criteria:
Description of criteria:
- CEL added to the arch field for NodePools which will error if a user tries to change the arch field from `amd64` for any other platform other than AWS.
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
Migrate every occurrence of iptables in OpenShift to use nftables, instead.
Goals (aka. expected user outcomes)
Implement a full migration from iptables to nftables within a series of "normal" upgrades of OpenShift with the goal of not causing any more network disruption than would normally be required for an OpenShift upgrade. (Different components may migrate from iptables to nftables in different releases; no coordination is needed between unrelated components.)
Requirements (aka. Acceptance Criteria):
- Discover what components are using iptables (directly or indirectly, e.g. via ipfailover) and reduce the “unknown unknowns”.
- Port components away from iptables.
Use Cases (Optional):
Questions to Answer (Optional):
- Do we need a better “warning: you are using iptables” warning for customers? (eg, per-container rather than per-node, which always fires because OCP itself is using iptables). This could help provide improved visibility of the issue to other components that aren't sure if they need to take action and migrate to nftables, as well.
Out of Scope
- Non-OVN primary CNI plug-in solutions
Background
- RHEL's iptables (including the ipset and iptables-nft packages) have been deprecated in RHEL 9 and will be removed in the next major release.
- See also: https://access.redhat.com/solutions/6739041
Customer Considerations
- What happens to clusters that don't migrate all iptables use to nftables?
- In RHEL 9.x it will generate a single log message during node startup on every OpenShift node. There are Insights rules that will trigger on all OpenShift nodes.
- In RHEL 10 iptables will just no longer work at all. Neither the command-line tools nor the kernel modules will be present.
Documentation Considerations
Interoperability Considerations
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
- OCP needs to detect when customer workloads are making use of iptables, and present this information to the customer (e.g. via alerts, metrics, insights, etc)
- The RHEL 9 kernel logs a warning if iptables is used at any point anywhere in the system, but this is not helpful because OCP itself still uses iptables, so the warning is always logged.
- We need to avoid false positives due to OCP's own use of iptables in pod namespaces (e.g. the rules to block access to the MCS). Porting those rules to nftables sooner rather than later is one solution.
Why is this important?
- iptables will not exist in RHEL 10, so if customers are depending on it, they need to be warned.
- Contrariwise, we are getting questions from customers who are not using iptables in their own workload containers, who are confused about the kernel warning. Clearer messaging should help reduce confusion here.
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
- Priority+ is set by engineering
- Epic must be Linked to a +Parent Feature
- Target version+ must be set
- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Feature Overview (aka. Goal Summary)
Consolidated Enhancement of HyperShift/KubeVirt Provider Post GA
This feature aims to provide a comprehensive enhancement to the HyperShift/KubeVirt provider integration post its GA release.
By consolidating CSI plugin improvements, core improvements, and networking enhancements, we aim to offer a more robust, efficient, and user-friendly experience.
Goals (aka. expected user outcomes)
- User Persona: Cluster service providers / SRE
- Functionality:
- Expanded CSI capabilities.
- Improved core functionalities of the KubeVirt Provider
- Enhanced networking capabilities.
Goal
Post GA quality of life improvements for the HyperShift/KubeVirt core
User Stories
Non-Requirements
Notes
- Any additional details or decisions made/needed
Done Checklist
| Who | What | Reference |
|---|---|---|
| DEV | Upstream roadmap issue (or individual upstream PRs) | <link to GitHub Issue> |
| DEV | Upstream documentation merged | <link to meaningful PR> |
| DEV | gap doc updated | <name sheet and cell> |
| DEV | Upgrade consideration | <link to upgrade-related test or design doc> |
| DEV | CEE/PX summary presentation | label epic with cee-training and add a <link to your support-facing preso> |
| QE | Test plans in Polarion | <link or reference to Polarion> |
| QE | Automated tests merged | <link or reference to automated tests> |
| DOC | Downstream documentation merged | <link to meaningful PR> |
Currently there is no option to influence on the placement of the VMs of an hosted cluster with kubevirt provider. the existing NodeSelector in HostedCluster are influencing only the pods in the hosted control plane namespace.
The goal is to introduce an new field in .spec.platform.kubevirt stanza in NodePool for node selector, propagate it to the VirtualMachineSpecTemplate, and expose this in the hypershift and hcp CLIs.
the rbac required for external infra needs to be documented on this page.
https://hypershift-docs.netlify.app/how-to/kubevirt/external-infrastructure/
Technology Preview of the oc mirror enclaves support (Dev Preview was OCPSTRAT-765 in OpenShift 4.15).
Feature description
oc-mirror already focuses on mirroring content to disconnected environments for installing and upgrading OCP clusters.
This specific feature addresses use cases where mirroring is needed for several enclaves (disconnected environments), that are secured behind at least one intermediate disconnected network.
In this context, enclave users are interested in:
- being able to mirror content for several enclaves, and centralizing it in a single internal registry. Some customers are interested in running security checks on the mirrored content, vetting it before allowing mirroring to downstream enclaves.
- being able to mirror contents directly from the internal centralized registry to enclaves without having to restart the mirroring from internet for each enclave
- keeping the volume of data transfered from one network stage to the other to a strict minimum, avoiding to transfer a blob or an image more than one time from one stage to another.
This epic covers the work for RFE-3800 (includes RFE-3393 and RFE-3733) for mirroring operators and additonal images
The full description / overview of the enclave support is best described here
The design document can be found here
Architecture Overview (diagram)
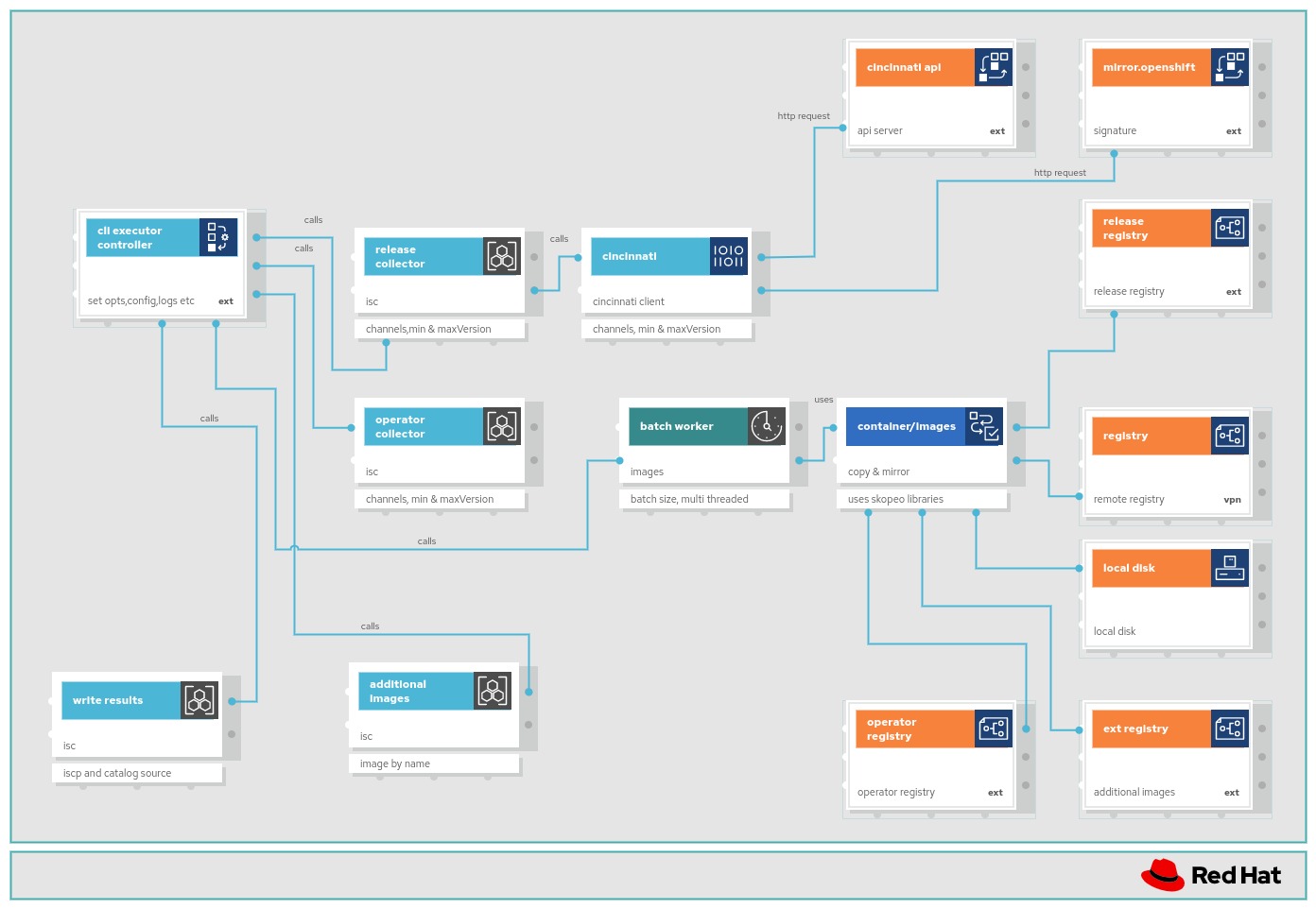
User Stories
All user stories are in the form :
- Role (As a ...)
- Goal (I want ..)
- Reason (So that ..)
Acceptance Criteria
- Compatible with current V1
OCI for ibm
Overview
Consider this as part of the separate discussions and design of the upgrade path/introspection tool
Acceptance Criteria{}
- All tests pass (80%) coverage
- Documentation approved by docs team
- All tests QE approved
- Well documented README/HOWTO/OpenShift documentation
- Best effort (but better than v1)
- Change the ImageSetConfiguration schema to accept a list of bundles
- Get related images from a specific bundle/s names and packages stated in the imagesetconfig (using v1alpha3 version of the ISC spec)
- Any other associations bundles and other filtering that is not package is not allowed
Tasks
- Implement V2 versioning as discussed in the EP document
- Implement code to filter bundles according to ImageSetConfig criteria.
- Implement unit tests
Acceptance Criteria
- Ensure all unit tests pass
- Ensure code coverage is above 80%
- Ensure golanglint-ci has no errors
- All tests QE approved
- Show the results in code base README
Tasks
- Spike to asses current MVP gaps
- Implement unit tests for v2
I need an interface and implementation that can read the history file and present it in a map of digests
If the archived content exceeds the max size specified, oc-mirror shall generate as many archive chunks as needed .
Clear out all tars before starting the next mirrorToDisk
so that after newly generated archives are not mixed with archives generated in previous runs
Reducing the amount of changes for end users, we should maybe consider reusing the existing --dry-run flag
Today the --help is not aligned with how v2 is working. It is necessary to update it to avoid confusing customers.
Acceptance Criteria
- All tests pass (80%) coverage
- Documentation approved by docs team
- All tests QE approved
- Well documented README/HOWTO/OpenShift documentation
Tasks
- Implement V2 versioning as discussed in the EP document
- Implement code to generate artifacts IDMS ITMS and audit data (
CFE-817) - keep in mind that IDMS generation might be needed for v1
- Implement code to generate CatalogSource
- Implement unit tests
- Acceptance Criteria
- Create e2e test plan for MVP with QE sign-off
- All e2e tests pass
- Documentation approved by docs team
- All tests QE approved
- Well documented README/HOWTO/OpenShift documentation
- Tasks
- Implement e2e testing for MVP according to test plan
- Document the e2e process
- Check index manifest and compare to the one on disk
- shortestPath
- provide a way to override the pgp key that is provided as a constant in cincinnati.go L24
Acceptance Criteria
- All unit tests pass (80% coverage)
- Multi arch functionality works for catalogs and additional images for all mirroring scenarios
- Documentation approved by docs team
- All tests QE approved
- Well documented README/HOWTO/OpenShift documentation
Tasks
- Implement multi arch (manifest list) functionality and code
- Implement unit tests
- TargetCatalog and TargetTag
- Check index manifest and compare to the one on disk
Handle cases where /configs contains a single index.json vs /configs containing several folders (1 per package), with several index.json files.Rebuild catalogs?Redefine the default channel (OCPBUGS-7465, also requested by Verizon)
Overview
Ensure that the current v2 respects the v1 TargetCatalog and TargetTag fields (if set) for oci catalog and registry catalogs.
Also TargetCatalog and TargetTag should not be mutually exclusive.
Invalid example:
kind: ImageSetConfiguration apiVersion: mirror.openshift.io/v1alpha2 mirror: operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.14 targetCatalog: abc/def:v5.5 packages: - name: aws-load-balancer-operator
Valid example:
kind: ImageSetConfiguration apiVersion: mirror.openshift.io/v1alpha2 mirror: operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.14 targetCatalog: abc/def targetTag: v4.4 packages: - name: aws-load-balancer-operator
Acceptance Criteria
- All tests pass (80%) coverage
- Documentation approved by docs team
- All tests QE approved
- Well documented README/HOWTO/OpenShift documentation
Tasks
- Implement V2 versioning as discussed in the EP document
- Implement code to bulk (use concurrency) delete images functionality
- Consider deleting relevant images in cache
- Implement unit tests
Acceptance Criteria
- All tests pass (80%) coverage
- Documentation approved by docs team
- All tests QE approved
- Well documented README/HOWTO/OpenShift documentation
Tasks
- Implement the scenario where the operator catalog is only one file instead of multiple files (catalog.json) see comment here
- Investigate if the operator catalog for IBM is all in one json only or multiple
- Implement unit tests
Acceptance Criteria
- All tests pass (80%) coverage
- Documentation approved by docs team
- All tests QE approved
- Well documented README/HOWTO/OpenShift documentation
- Best effort (but better than v1)
- Take into account targetCatalog, targetTag
- Catalogs mirrored by tag should be pulled when a minor version is detected (we should not rely only on existence of the folder in the cache)
Tasks
- Implement V2 versioning as discussed in the EP document
- Implement code to filter catalogs , channels and bundles according to ImageSetConfig criteria.
- Implement unit tests
Consume the newly introduced API and apply the scheduling configuration (taints and node selectors) to network-check-source and network-check-target.
In order to avoid an increased support overhead once the license changes at the end of the year, we should replace the instances in which metal IPI uses Terraform.
When we used Terraform to provision the control plane, the Terraform deployment could eventually time out and report an error. The installer was monitoring the Terraform output and could pass the error on to the user, e.g.
level=debug msg=ironic_node_v1.openshift-master-host[0]: Still creating... [2h9m1s elapsed]
level=error
level=error msg=Error: could not inspect: inspect failed , last error was 'timeout reached while inspecting the node'
level=error
level=error msg= with ironic_node_v1.openshift-master-host[2],
level=error msg= on main.tf line 13, in resource "ironic_node_v1" "openshift-master-host":
level=error msg= 13: resource "ironic_node_v1" "openshift-master-host" {
Now that provisioning is managed by Metal³, we have nothing monitoring it for errors:
level=info msg=Waiting up to 1h0m0s (until 1:05AM UTC) for bootstrapping to complete...
level=debug msg=Bootstrap status: complete
By this stage the bootstrap API is up (and this is a requirement for BMO to do its thing). The installer is capable of monitoring the API for the appearance of the bootstrap complete ConfigMap, so it is equally capable of monitoring the BaremetalHost status. This should actually be an improvement on Terraform, as we can monitor in real time as the hosts progress through the various stages, and report on errors and retries.
We will re-implement the functionality of terraform-provider-libvirt using Go libraries.
What we do in static mode, we need to do in k8s mode.
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision vSphere infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The vSphere IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing vSphere Terraform provider. Specifically, _we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Provision vsphere infrastructure without the use of Terraform
Why is this important?
- Removing Terraform from Installer
Scenarios
- The new provider should aim to provide the same results as the existing vSphere terraform provider.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
level=info msg=Running process: vsphere infrastructure provider with args [-v=2 --metrics-bind-addr=0 --health-addr=127.0.0.1:37167 --webhook-port=38521 --webhook-cert-dir=/tmp/envtest-serving-certs-445481834 --leader-elect=false] and env [...]
may contain sensitive data - passwords, logins etc. It should be filtered
Causes password leaking in CI.
Replace https://github.com/openshift/installer/tree/master/upi/vsphere with powercli. Keep terraform in place until powercli installations are working.
- Update UPI image with powershell and powercli
- Backport change through all supported releases
- Update installer repo with powercli scripts
- Update installer repo to remove UPI terraform
example of updates to be made to the upi image:
~~~
FROM upi-installer-image
RUN curl https://packages.microsoft.com/config/rhel/8/prod.repo | tee
/etc/yum.repos.d/microsoft.repo
RUN yum install -y powershell
RUN pwsh -Command 'Install-Module VMware.PowerCLI -Force -Scope
CurrentUser'
~~~
Description of problem:
the installer download the rhcos image locally to cache multiple times when using failure domains
Version-Release number of selected component (if applicable):
4.16
How reproducible:
always
Steps to Reproduce:
1.
2.
3.
Actual results:
time="2024-02-22T14:34:42-05:00" level=debug msg="Generating Cluster..." time="2024-02-22T14:34:42-05:00" level=warning msg="FeatureSet \"CustomNoUpgrade\" is enabled. This FeatureSet does not allow upgrades and may affect the supportability of the cluster." time="2024-02-22T14:34:42-05:00" level=info msg="Creating infrastructure resources..." time="2024-02-22T14:34:43-05:00" level=debug msg="Obtaining RHCOS image file from 'https://rhcos.mirror.openshift.com/art/storage/prod/streams/4.16-9.4/builds/416.94.202402130130-0/x86_64/rhcos-416.94.202402130130-0-vmware.x86_64.ova?sha256=fb823b5c31afbb0b9babd46550cb9fe67109a46f48c04ce04775edbb6a309dd3'" time="2024-02-22T14:34:43-05:00" level=debug msg="The file was found in cache: /home/ngirard/.cache/openshift-installer/image_cache/rhcos-416.94.202402130130-0-vmware.x86_64.ova. Reusing..." time="2024-02-22T14:36:02-05:00" level=debug msg="Obtaining RHCOS image file from 'https://rhcos.mirror.openshift.com/art/storage/prod/streams/4.16-9.4/builds/416.94.202402130130-0/x86_64/rhcos-416.94.202402130130-0-vmware.x86_64.ova?sha256=fb823b5c31afbb0b9babd46550cb9fe67109a46f48c04ce04775edbb6a309dd3'" time="2024-02-22T14:36:02-05:00" level=debug msg="The file was found in cache: /home/ngirard/.cache/openshift-installer/image_cache/rhcos-416.94.202402130130-0-vmware.x86_64.ova. Reusing..." time="2024-02-22T14:37:22-05:00" level=debug msg="Obtaining RHCOS image file from 'https://rhcos.mirror.openshift.com/art/storage/prod/streams/4.16-9.4/builds/416.94.202402130130-0/x86_64/rhcos-416.94.202402130130-0-vmware.x86_64.ova?sha256=fb823b5c31afbb0b9babd46550cb9fe67109a46f48c04ce04775edbb6a309dd3'" time="2024-02-22T14:37:22-05:00" level=debug msg="The file was found in cache: /home/ngirard/.cache/openshift-installer/image_cache/rhcos-416.94.202402130130-0-vmware.x86_64.ova. Reusing..." time="2024-02-22T14:38:39-05:00" level=debug msg="Obtaining RHCOS image file from 'https://rhcos.mirror.openshift.com/art/storage/prod/streams/4.16-9.4/builds/416.94.202402130130-0/x86_64/rhcos-416.94.202402130130-0-vmware.x86_64.ova?sha256=fb823b5c31afbb0b9babd46550cb9fe67109a46f48c04ce04775edbb6a309dd3'" time="2024-02-22T14:38:39-05:00" level=debug msg="The file was found in cache: /home/ngirard/.cache/openshift-installer/image_cache/rhcos-416.94.202402130130-0-vmware.x86_64.ova. Reusing..." time="2024-02-22T14:39:33-05:00" level=debug msg="Obtaining RHCOS image file from 'https://rhcos.mirror.openshift.com/art/storage/prod/streams/4.16-9.4/builds/416.94.202402130130-0/x86_64/rhcos-416.94.202402130130-0-vmware.x86_64.ova?sha256=fb823b5c31afbb0b9babd46550cb9fe67109a46f48c04ce04775edbb6a309dd3'" time="2024-02-22T14:39:33-05:00" level=debug msg="The file was found in cache: /home/ngirard/.cache/openshift-installer/image_cache/rhcos-416.94.202402130130-0-vmware.x86_64.ova. Reusing..." time="2024-02-22T14:39:33-05:00" level=error msg="failed to fetch Cluster: failed to generate asset \"Cluster\": failed to create cluster: failed during pre-provisioning: unable to initialize folders and templates: failed to import ova: failed to lease wait: The name 'ngirard-dev-pr89z-rhcos-us-west-us-west-1a' already exists."
Expected results:
should only download once
Additional info:
okd required guestinfo domain
and
stealclock accounting
{}USER STORY:{}
The assisted installer should be able to use CAPI-based vsphere installs without requiring access to vcenter.
{}DESCRIPTION:{}
The installer makes calls to vcenter to determine the networks, which are required for CAPI based installs, but vcenter access is not guaranteed in the assisted installer.
See:
which were lovingly lifted from this slack thread.
{}Required:{}
In cases where the installer calls vcenter to obtain values to populate manifests, the installer should leave empty fields (or a default value) if it is unable to access vcenter. It should produce partial manifests, rather than throw an error.
{}Nice to have:{}
...
{}ACCEPTANCE CRITERIA:{}
Continued compatibility with agent installer, particularly producing capi manifests when access to vcenter fails.
{}ENGINEERING DETAILS:{}
<!--
Any additional information that might be useful for engineers: related
repositories or pull requests, related email threads, GitHub issues or
other online discussions, how to set up any required accounts and/or
environments if applicable, and so on.
-->
WARNING FeatureSet "CustomNoUpgrade" is enabled. This FeatureSet does not allow upgrades and may affect the supportability of the cluster.
INFO Creating infrastructure resources...
DEBUG Obtaining RHCOS image file from 'https://rhcos.mirror.openshift.com/art/storage/prod/streams/4.16-9.4/builds/416.94.202402130130-0/x86_64/rhcos-416.94.202402130130-0-vmware.x86_64.ova?sha256=fb823b5c31afbb0b9babd46550cb9fe67109a46f48c04ce04775edbb6a309dd3'
DEBUG The file was found in cache: /home/jcallen/.cache/openshift-installer/image_cache/rhcos-416.94.202402130130-0-vmware.x86_64.ova. Reusing...
<very long pause here with no indication>
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision Azure infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The Azure IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing Azure Terraform provider. Specifically, we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Provision Azure infrastructure without the use of Terraform
Why is this important?
- Removing Terraform from Installer
Scenarios
- The new provider should aim to provide the same results as the existing Azure
- terraform provider.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Launch a cluster provisioned with CAPI usining a minimal (mostly default) install config.
User Story:
As a developer, I want to:
- Create machine manifests for Azure CAPI implementation
so that I can achieve
- Create control plane and bootstrap machines using CAPZ
Acceptance Criteria:
Description of criteria:
- Control plane and bootstrap machines are created using CAPI
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
The `image` field in the AzureMachineSpec needs to point to an RHCOS image. For marketplace images, those images should already be available.
For non-marketplace images, we need to create an image for the users, using the VHD from the RHCOS stream.
The image could created in the PreProvision hook: https://github.com/openshift/installer/blob/master/pkg/infrastructure/clusterapi/types.go#L26
Technicaly it could also be done in the InfraAvailable hook, if that is needed.
Create private zone and DNS records in the resource group specified by baseDomainResourceGroupName. The records should be cleaned up with destroy cluster.
The ControlPlaneEndpoint will be available in the Cluster spec and can be used to populate the DNS records.
Currently we create both A and CNAME records in different scenarios: https://github.com/openshift/installer/blob/master/data/data/azure/cluster/dns/dns.tf
Ideally we do this in the InfraReady hook, before machine creation, so that control plane machines can pull ignition immediately.
The install config allows users to specify a `diskEncryptionSet` in machinepools.
CAPZ has existing support for disk encryption sets:
Note that CAPZ says the encryption set must belong to the same subscription, whereas our docs may not indicate that. We should point this out to the docs team.
In the ignition hook, we need to upload the bootstrap ignition data to the bootstrap storage account (created to hold the rhcos image). Then create an ignition stub containing the SAS link for the object.
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
To avoid an increased support overhead once the license changes at the end of the year, we want to provision Nutanix infrastructure without the use of Terraform.
Requirements (aka. Acceptance Criteria):
- The Nutanix IPI Installer no longer contains or uses Terraform.
- The new provider should aim to provide the same results and have parity with the existing Nutanix Terraform provider. Specifically, _we should aim for feature parity against the install config and the cluster it creates to minimize impact on existing customers' UX.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Feature Overview
Console enhancements based on customer RFEs that improve customer user experience.
Goals
- This Section:* Provide high-level goal statement, providing user context and expected user outcome(s) for this feature
- …
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
RFE: https://issues.redhat.com/browse/RFE-1772
In OpenShift v3 we have been displaying pod's last termination state and we need to display the same info in v4. Here is the v3 html interpretation of the kubernetes-object-describe-container-state directive.
AC: Add the Last State login into the pod's details page by rewritting the v3 implementation.
Based on the this old feature request
https://issues.redhat.com/browse/RFE-1530
we do have impersonation in place for gaining access to other user's permissions via the console. But the only documentation we currently have is how to impersonate system:admin via the CLI see
https://docs.openshift.com/container-platform/4.14/authentication/impersonating-system-admin.html
Please provide documentation for the console feature and the required prerequisites for the users/groups accordingly.
AC:
- Create a ConsoleQuickStart CR that would help user with impersonate access understand the impersonation workflow and functionality
- This quickstart should be available only to user with impersonate
- Created CR should be placed in the console-operator's repo, where the default quickstarts are placed
More info on the impersonate access role - https://github.com/openshift/console/pull/13345/files
Implement a toast notification feature in the console UI to notify the user that their action for creating/updating a resource violated a warn policy though the request was allowed.
See theConfigure OpenShift Console to display warnings from apiserver when creating/updating resources spike on how to reproduce the warn policy response in `oc` CLI
A.C.
Display a warning toast notification after create/update resource action for a resource
Add support for returning `response.header` in `consoleFetchCommon` function in the dynamic-plugin-sdk package
Problem:
The `consoleFetchCommon function in the dynamic-plugin-sdk package lack the support for retrieving HTTP `response.header`.
Justification:
The policy warning responses are visible in the `oc cli` but not visible on the console UI. The customer wants a similar behavior on the UI. The policy warning responses are returned in the HTTP `response.header` which is not implemented in the `consoleFetchCommon` function currently.
Proposed Solution
Add logic for extracting all `response.headers` along with `response.json` in the `consoleFetchCommon` function using `options` or something else.
A.C.
Add an option parameter to `consoleFetchCommon` to conditionally return full `response` or `response.json` so that the k8s functions like "K8sCreate` consume either, preventing breaking change for dynamic plugins
Feature Overview (aka. Goal Summary)
A guest cluster can use an external OIDC token issuer. This will allow machine-to-machine authentication workflows
Goals (aka. expected user outcomes)
A guest cluster can configure OIDC providers to support the current capability: https://kubernetes.io/docs/reference/access-authn-authz/authentication/#openid-connect-tokens and the future capability: https://github.com/kubernetes/kubernetes/blob/2b5d2cf910fd376a42ba9de5e4b52a53b58f9397/staging/src/k8s.io/apiserver/pkg/apis/apiserver/types.go#L164 with an API that
- allows fixing mistakes
- alerts the owner of the configuration that it's likely that there is a misconfiguration (self-service)
- makes distinction between product failure (expressed configuration not applied) from configuration failure (the expressed configuration was wrong), easy to determine
- makes cluster recovery possible in cases where the external token issuer is permanently gone
- allow (might not require) removal of the existing oauth server
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
A guest cluster can use an external OIDC token issuer. This will allow machine-to-machine authentication workflows
Goals (aka. expected user outcomes)
A guest cluster can configure OIDC providers to support the current capability: https://kubernetes.io/docs/reference/access-authn-authz/authentication/#openid-connect-tokens and the future capability: https://github.com/kubernetes/kubernetes/blob/2b5d2cf910fd376a42ba9de5e4b52a53b58f9397/staging/src/k8s.io/apiserver/pkg/apis/apiserver/types.go#L164 with an API that
- allows fixing mistakes
- alerts the owner of the configuration that it's likely that there is a misconfiguration (self-service)
- makes distinction between product failure (expressed configuration not applied) from configuration failure (the expressed configuration was wrong), easy to determine
- makes cluster recovery possible in cases where the external token issuer is permanently gone
- allow (might not require) removal of the existing oauth server
Goal
- Provide API for configuring external OIDC to management cluster components
- Stop creating oauth server deployment
- Stop creating oauth-apiserver
- Stop registering oauth-apiserver backed apiservices
- See what breaks next
Why is this important?
- need API starting point for ROSA CLI and OCM
- need cluster that demonstrates what breaks next for us to fix
Scenarios
- ...
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Description of problem:
When issuerCertificateAuthority is set, kube-apiserver pod is CrashLoopBackOff. Tried RCA debugging, found the cause is: the path /etc/kubernetes/certs/oidc-ca/ca.crt is incorrect. The expected path should be /etc/kubernetes/certs/oidc-ca/ca-bundle.crt .
Version-Release number of selected component (if applicable):
4.16.0-0.nightly-2024-03-13-061822
How reproducible:
Always
Steps to Reproduce:
1. Create fresh HCP cluster.
2. Create keycloak as OIDC server exposed as a Route which uses cluster's default ingress certificate as the serving certificate.
3. Configure clients necessarily on keycloak admin UI.
4. Configure external OIDC:
$ oc create configmap keycloak-oidc-ca --from-file=ca-bundle.crt=router-ca/ca.crt --kubeconfig $MGMT_KUBECONFIG -n clusters
$ oc patch hc $HC_NAME -n clusters --kubeconfig $MGMT_KUBECONFIG --type=merge -p="
spec:
configuration:
authentication:
oidcProviders:
- claimMappings:
groups:
claim: groups
prefix: 'oidc-groups-test:'
username:
claim: email
prefixPolicy: Prefix
prefix:
prefixString: 'oidc-user-test:'
issuer:
audiences:
- $AUDIENCE_1
- $AUDIENCE_2
issuerCertificateAuthority:
name: keycloak-oidc-ca
issuerURL: $ISSUER_URL
name: keycloak-oidc-server
oidcClients:
- clientID: $CONSOLE_CLIENT_ID
clientSecret:
name: $CONSOLE_CLIENT_SECRET_NAME
componentName: console
componentNamespace: openshift-console
type: OIDC
"
5. Check pods should be renewed, but new pod is CrashLoopBackOff:
$ oc get po -n clusters-$HC_NAME --kubeconfig $MGMT_KUBECONFIG --sort-by metadata.creationTimestamp | tail -n 4
openshift-apiserver-65f8c5f545-x2vdf 3/3 Running 0 5h8m
community-operators-catalog-57dd5886f7-jq25f 1/1 Running 0 4h1m
kube-apiserver-5d75b5b848-c9c8r 4/5 CrashLoopBackOff 25 (3m9s ago) 107m
$ oc logs --timestamps -n clusters-$HC_NAME --kubeconfig $MGMT_KUBECONFIG -c kube-apiserver kube-apiserver-5d75b5b848-gk2t8
...
2024-03-18T09:11:14.836540684Z I0318 09:11:14.836495 1 dynamic_cafile_content.go:119] "Loaded a new CA Bundle and Verifier" name="client-ca-bundle::/etc/kubernetes/certs/client-ca/ca.crt"
2024-03-18T09:11:14.837725839Z E0318 09:11:14.837695 1 run.go:74] "command failed" err="jwt[0].issuer.certificateAuthority: Invalid value: \"<omitted>\": data does not contain any valid RSA or ECDSA certificates"
Actual results:
5. New kube-apiserver pod is CrashLoopBackOff. `oc explain` for issuerCertificateAuthority says the configmap data should use ca-bundle.crt. But I also tried to use ca.crt in configmap's data, got same result.
Expected results:
6. No CrashLoopBackOff.
Additional info:
Below is my RCA for the CrashLoopBackOff kube-apiserver pod:
Check if it is valid RSA certificate, it is valid:
$ openssl x509 -noout -text -in router-ca/ca.crt | grep -i rsa
Signature Algorithm: sha256WithRSAEncryption
Public Key Algorithm: rsaEncryption
Signature Algorithm: sha256WithRSAEncryption
So, the CA certificate has no issue.
Above pod logs show "/etc/kubernetes/certs/oidc-ca/ca.crt" is used. Double checked the configmap:
$ oc get cm auth-config -n clusters-$HC_NAME --kubeconfig $MGMT_KUBECONFIG -o jsonpath='{.data.auth\.json}' | jq | ~/auto/json2yaml.sh
---
kind: AuthenticationConfiguration
apiVersion: apiserver.config.k8s.io/v1alpha1
jwt:
- issuer:
url: https://keycloak-keycloak.apps..../realms/master
certificateAuthority: "/etc/kubernetes/certs/oidc-ca/ca.crt"
...
Then debug the CrashLoopBackOff pod:
The used path /etc/kubernetes/certs/oidc-ca/ca.crt does not exist! The correct path should be /etc/kubernetes/certs/oidc-ca/ca-bundle.crt:
$ oc debug -n clusters-$HC_NAME --kubeconfig $MGMT_KUBECONFIG -c kube-apiserver kube-apiserver-5d75b5b848-gk2t8 Starting pod/kube-apiserver-5d75b5b848-gk2t8-debug-kpmlf, command was: hyperkube kube-apiserver --openshift-config=/etc/kubernetes/config/config.json -v2 --encryption-provider-config=/etc/kubernetes/secret-encryption/config.yaml sh-5.1$ cat /etc/kubernetes/certs/oidc-ca/ca.crt cat: /etc/kubernetes/certs/oidc-ca/ca.crt: No such file or directory sh-5.1$ ls /etc/kubernetes/certs/oidc-ca/ ca-bundle.crt sh-5.1$ cat /etc/kubernetes/certs/oidc-ca/ca-bundle.crt -----BEGIN CERTIFICATE----- MIIDPDCCAiSgAwIBAgIIM3E0ckpP750wDQYJKoZIhvcNAQELBQAwJjESMBAGA1UE ...
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
$ oc logs --previous --timestamps -n openshift-console console-64df9b5bcb-8h8xk
2024-03-22T11:17:07.824396015Z I0322 11:17:07.824332 1 main.go:210] The following console plugins are enabled:
2024-03-22T11:17:07.824574844Z I0322 11:17:07.824558 1 main.go:212] - monitoring-plugin
2024-03-22T11:17:07.824613918Z W0322 11:17:07.824603 1 authoptions.go:99] Flag inactivity-timeout is set to less then 300 seconds and will be ignored!
2024-03-22T11:22:07.828873678Z I0322 11:22:07.828819 1 main.go:634] Binding to [::]:8443...
2024-03-22T11:22:07.828982852Z I0322 11:22:07.828967 1 main.go:636] using TLS
2024-03-22T11:22:07.833771847Z E0322 11:22:07.833726 1 asynccache.go:62] failed a caching attempt: Get "https://keycloak-keycloak.apps.xxxx/realms/master/.well-known/openid-configuration": tls: failed to verify certificate: x509: certificate signed by unknown authority
2024-03-22T11:22:10.831644728Z I0322 11:22:10.831598 1 metrics.go:128] serverconfig.Metrics: Update ConsolePlugin metrics...
2024-03-22T11:22:10.848238183Z I0322 11:22:10.848187 1 metrics.go:138] serverconfig.Metrics: Update ConsolePlugin metrics: &map[monitoring:map[enabled:1]] (took 16.490288ms)
2024-03-22T11:22:12.829744769Z I0322 11:22:12.829697 1 metrics.go:80] usage.Metrics: Count console users...
2024-03-22T11:22:13.236378460Z I0322 11:22:13.236318 1 metrics.go:156] usage.Metrics: Update console users metrics: 0 kubeadmin, 0 cluster-admins, 0 developers, 0 unknown/errors (took 406.580502ms)
The cause is that the HCCO is not copying the issuerCertificateAuthority configmap into the openshift-config namespace of the HC.
Description of problem:
HCP does not honor the oauthMetadata field of hc.spec.configuration.authentication, making console crash and oc login fail.
Version-Release number of selected component (if applicable):
HyperShift management cluster: 4.16.0-0.nightly-2024-01-29-233218 HyperShift hosted cluster: 4.16.0-0.nightly-2024-01-29-233218
How reproducible:
Always
Steps to Reproduce:
1. Install HCP env. Export KUBECONFIG:
$ export KUBECONFIG=/path/to/hosted-cluster/kubeconfig
2. Create keycloak applications. Then get the route:
$ KEYCLOAK_HOST=https://$(oc get -n keycloak route keycloak --template='{{ .spec.host }}')
$ echo $KEYCLOAK_HOST
https://keycloak-keycloak.apps.hypershift-ci-18556.xxx
$ curl -sSk "$KEYCLOAK_HOST/realms/master/.well-known/openid-configuration" > oauthMetadata
$ cat oauthMetadata
{"issuer":"https://keycloak-keycloak.apps.hypershift-ci-18556.xxx/realms/master"
$ oc create configmap oauth-meta --from-file ./oauthMetadata -n clusters --kubeconfig /path/to/management-cluster/kubeconfig
...
3. Set hc.spec.configuration.authentication:
$ CLIENT_ID=openshift-test-aud
$ oc patch hc hypershift-ci-18556 -n clusters --kubeconfig /path/to/management-cluster/kubeconfig --type=merge -p="
spec:
configuration:
authentication:
oauthMetadata:
name: oauth-meta
oidcProviders:
- claimMappings:
...
issuer:
audiences:
- $CLIENT_ID
issuerCertificateAuthority:
name: keycloak-oidc-ca
issuerURL: $KEYCLOAK_HOST/realms/master
name: keycloak-oidc-test
type: OIDC
"
Check KAS indeed already picks up the setting:
$ oc logs -c kube-apiserver kube-apiserver-5c976d59f5-zbrwh -n clusters-hypershift-ci-18556 --kubeconfig /path/to/management-cluster/kubeconfig | grep "oidc-"
...
I0130 08:07:24.266247 1 flags.go:64] FLAG: --oidc-ca-file="/etc/kubernetes/certs/oidc-ca/ca.crt"
I0130 08:07:24.266251 1 flags.go:64] FLAG: --oidc-client-id="openshift-test-aud"
...
I0130 08:07:24.266261 1 flags.go:64] FLAG: --oidc-issuer-url="https://keycloak-keycloak.apps.hypershift-ci-18556.xxx/realms/master"
...
Wait about 15 mins.
4. Check COs and check oc login. Both show the same error:
$ oc get co | grep -v 'True.*False.*False'
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
console 4.16.0-0.nightly-2024-01-29-233218 True True False 4h57m SyncLoopRefreshProgressing: Working toward version 4.16.0-0.nightly-2024-01-29-233218, 1 replicas available
$ oc get po -n openshift-console
NAME READY STATUS RESTARTS AGE
console-547cf6bdbb-l8z9q 1/1 Running 0 4h55m
console-54f88749d7-cv7ht 0/1 CrashLoopBackOff 9 (3m18s ago) 14m
console-54f88749d7-t7x96 0/1 CrashLoopBackOff 9 (3m32s ago) 14m
$ oc logs console-547cf6bdbb-l8z9q -n openshift-console
I0130 03:23:36.788951 1 metrics.go:156] usage.Metrics: Update console users metrics: 0 kubeadmin, 0 cluster-admins, 0 developers, 0 unknown/errors (took 406.059196ms)
E0130 06:48:32.745179 1 asynccache.go:43] failed a caching attempt: request to OAuth issuer endpoint https://:0/oauth/token failed: Head "https://:0": dial tcp :0: connect: connection refused
E0130 06:53:32.757881 1 asynccache.go:43] failed a caching attempt: request to OAuth issuer endpoint https://:0/oauth/token failed: Head "https://:0": dial tcp :0: connect: connection refused
...
$ oc login --exec-plugin=oc-oidc --client-id=openshift-test-aud --extra-scopes=email,profile --callback-port=8080
error: oidc authenticator error: oidc discovery error: Get "https://:0/.well-known/openid-configuration": dial tcp :0: connect: connection refused
error: oidc authenticator error: oidc discovery error: Get "https://:0/.well-known/openid-configuration": dial tcp :0: connect: connection refused
Unable to connect to the server: getting credentials: exec: executable oc failed with exit code 1
5. Check root cause, the configured oauthMetadata is not picked up well:
$ curl -k https://a6e149f24f8xxxxxx.elb.ap-east-1.amazonaws.com:6443/.well-known/oauth-authorization-server
{
"issuer": "https://:0",
"authorization_endpoint": "https://:0/oauth/authorize",
"token_endpoint": "https://:0/oauth/token",
...
}
Actual results:
As above steps 4 and 5, the configured oauthMetadata is not picked up well, causing console and oc login hit the error.
Expected results:
The configured oauthMetadata is picked up well. No error.
Additional info:
For oc, if I manually use `oc config set-credentials oidc --exec-api-version=client.authentication.k8s.io/v1 --exec-command=oc --exec-arg=get-token --exec-arg="--issuer-url=$KEYCLOAK_HOST/realms/master" ...` instead of using `oc login --exec-plugin=oc-oidc ...`, oc authentication works well. This means my configuration is correct. $ oc whoami Please visit the following URL in your browser: http://localhost:8080 oidc-user-test:xxia@redhat.com
Description of problem:
In https://issues.redhat.com/browse/OCPBUGS-28625?focusedId=24056681&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-24056681 , Seth Jennings states "It is not required to set the oauthMetadata to enable external OIDC".
Today having a chance to try without setting oauthMetadata, hit oc login fails with the error:
$ oc login --exec-plugin=oc-oidc --client-id=$CLIENT_ID --client-secret=$CLIENT_SECRET_VALUE --extra-scopes=email --callback-port=8080 error: oidc authenticator error: oidc discovery error: Get "https://:0/.well-known/openid-configuration": dial tcp :0: connect: connection refused error: oidc authenticator error: oidc discovery error: Get "https://:0/.well-known/openid-configuration": dial tcp :0: connect: connection refused Unable to connect to the server: getting credentials: exec: executable oc failed with exit code 1
Console login can succeed, though.
Note, OCM QE also encounters this when using ocm cli to test ROSA HCP external OIDC. Either oc or HCP, or anywhere (as a tester I'm not sure TBH ![]() ), worthy to have a fix, otherwise oc login is affected.
), worthy to have a fix, otherwise oc login is affected.
Version-Release number of selected component (if applicable):
[xxia@2024-03-01 21:03:30 CST my]$ oc version --client Client Version: 4.16.0-0.ci-2024-03-01-033249 Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3 [xxia@2024-03-01 21:03:50 CST my]$ oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.0-0.ci-2024-02-29-213249 True False 8h Cluster version is 4.16.0-0.ci-2024-02-29-213249
How reproducible:
Always
Steps to Reproduce:
1. Launch fresh HCP cluster.
2. Login to https://entra.microsoft.com. Register application and set properly.
3. Prepare variables.
HC_NAME=hypershift-ci-267920
MGMT_KUBECONFIG=/home/xxia/my/env/xxia-hs416-2-267920-4.16/kubeconfig
HOSTED_KUBECONFIG=/home/xxia/my/env/xxia-hs416-2-267920-4.16/hypershift-ci-267920.kubeconfig
AUDIENCE=7686xxxxxx
ISSUER_URL=https://login.microsoftonline.com/64dcxxxxxxxx/v2.0
CLIENT_ID=7686xxxxxx
CLIENT_SECRET_VALUE="xxxxxxxx"
CLIENT_SECRET_NAME=console-secret
4. Configure HC without oauthMetadata.
[xxia@2024-03-01 20:29:21 CST my]$ oc create secret generic console-secret -n clusters --from-literal=clientSecret=$CLIENT_SECRET_VALUE --kubeconfig $MGMT_KUBECONFIG
[xxia@2024-03-01 20:34:05 CST my]$ oc patch hc $HC_NAME -n clusters --kubeconfig $MGMT_KUBECONFIG --type=merge -p="
spec:
configuration:
authentication:
oauthMetadata:
name: ''
oidcProviders:
- claimMappings:
groups:
claim: groups
prefix: 'oidc-groups-test:'
username:
claim: email
prefixPolicy: Prefix
prefix:
prefixString: 'oidc-user-test:'
issuer:
audiences:
- $AUDIENCE
issuerURL: $ISSUER_URL
name: microsoft-entra-id
oidcClients:
- clientID: $CLIENT_ID
clientSecret:
name: $CLIENT_SECRET_NAME
componentName: console
componentNamespace: openshift-console
type: OIDC
"
Wait pods to renew:
[xxia@2024-03-01 20:52:41 CST my]$ oc get po -n clusters-$HC_NAME --kubeconfig $MGMT_KUBECONFIG --sort-by metadata.creationTimestamp
...
certified-operators-catalog-7ff9cffc8f-z5dlg 1/1 Running 0 5h44m
kube-apiserver-6bd9f7ccbd-kqzm7 5/5 Running 0 17m
kube-apiserver-6bd9f7ccbd-p2fw7 5/5 Running 0 15m
kube-apiserver-6bd9f7ccbd-fmsgl 5/5 Running 0 13m
openshift-apiserver-7ffc9fd764-qgd4z 3/3 Running 0 11m
openshift-apiserver-7ffc9fd764-vh6x9 3/3 Running 0 10m
openshift-apiserver-7ffc9fd764-b7znk 3/3 Running 0 10m
konnectivity-agent-577944765c-qxq75 1/1 Running 0 9m42s
hosted-cluster-config-operator-695c5854c-dlzwh 1/1 Running 0 9m42s
cluster-version-operator-7c99cf68cd-22k84 1/1 Running 0 9m42s
konnectivity-agent-577944765c-kqfpq 1/1 Running 0 9m40s
konnectivity-agent-577944765c-7t5ds 1/1 Running 0 9m37s
5. Check console login and oc login.
$ export KUBECONFIG=$HOSTED_KUBECONFIG
$ curl -ksS $(oc whoami --show-server)/.well-known/oauth-authorization-server
{
"issuer": "https://:0",
"authorization_endpoint": "https://:0/oauth/authorize",
"token_endpoint": "https://:0/oauth/token",
...
}
Check console login, it succeeds, console upper right shows correctly user name oidc-user-test:xxia@redhat.com.
Check oc login:
$ rm -rf ~/.kube/cache/oc/
$ oc login --exec-plugin=oc-oidc --client-id=$CLIENT_ID --client-secret=$CLIENT_SECRET_VALUE --extra-scopes=email --callback-port=8080
error: oidc authenticator error: oidc discovery error: Get "https://:0/.well-known/openid-configuration": dial tcp :0: connect: connection refused
error: oidc authenticator error: oidc discovery error: Get "https://:0/.well-known/openid-configuration": dial tcp :0: connect: connection refused
Unable to connect to the server: getting credentials: exec: executable oc failed with exit code 1
Actual results:
Console login succeeds. oc login fails.
Expected results:
oc login should also succeed.
Additional info:{}
Description of problem:
Updating oidcProviders does not take effect. See details below.
Version-Release number of selected component (if applicable):
4.16.0-0.nightly-2024-02-26-155043
How reproducible:
Always
Steps to Reproduce:
1. Install fresh HCP env and configure external OIDC as steps 1 ~ 4 of https://issues.redhat.com/browse/OCPBUGS-29154 (to avoid repeated typing those steps, only referencing as is here).
2. Pods renewed:
$ oc get po -n clusters-$HC_NAME --kubeconfig $MGMT_KUBECONFIG --sort-by metadata.creationTimestamp
...
network-node-identity-68b7b8dd48-4pvvq 3/3 Running 0 170m
oauth-openshift-57cbd9c797-6hgzx 2/2 Running 0 170m
kube-controller-manager-66f68c8bd8-tknvc 1/1 Running 0 164m
kube-controller-manager-66f68c8bd8-wb2x9 1/1 Running 0 164m
kube-controller-manager-66f68c8bd8-kwxxj 1/1 Running 0 163m
kube-apiserver-596dcb97f-n5nqn 5/5 Running 0 29m
kube-apiserver-596dcb97f-7cn9f 5/5 Running 0 27m
kube-apiserver-596dcb97f-2rskz 5/5 Running 0 25m
openshift-apiserver-c9455455c-t7prz 3/3 Running 0 22m
openshift-apiserver-c9455455c-jrwdf 3/3 Running 0 22m
openshift-apiserver-c9455455c-npvn5 3/3 Running 0 21m
konnectivity-agent-7bfc7cb9db-bgrsv 1/1 Running 0 20m
cluster-version-operator-675745c9d6-5mv8m 1/1 Running 0 20m
hosted-cluster-config-operator-559644d45b-4vpkq 1/1 Running 0 20m
konnectivity-agent-7bfc7cb9db-hjqlf 1/1 Running 0 20m
konnectivity-agent-7bfc7cb9db-gl9b7 1/1 Running 0 20m
3. oc login can succeed:
$ oc login --exec-plugin=oc-oidc --client-id=$CLIENT_ID --client-secret=$CLIENT_SECRET_VALUE --extra-scopes=email --callback-port=8080
Please visit the following URL in your browser: http://localhost:8080
Logged into "https://a4af9764....elb.ap-southeast-1.amazonaws.com:6443" as "oidc-user-test:xxia@redhat.com" from an external oidc issuer.You don't have any projects. Contact your system administrator to request a project.
4. Update HC by changing claim: email to claim: sub:
$ oc edit hc $HC_NAME -n clusters --kubeconfig $MGMT_KUBECONFIG
...
username:
claim: sub
...
Update is picked up:
$ oc get authentication.config cluster -o yaml
...
spec:
oauthMetadata:
name: tested-oauth-meta
oidcProviders:
- claimMappings:
groups:
claim: groups
prefix: 'oidc-groups-test:'
username:
claim: sub
prefix:
prefixString: 'oidc-user-test:'
prefixPolicy: Prefix
issuer:
audiences:
- 76863fb1-xxxxxx
issuerCertificateAuthority:
name: ""
issuerURL: https://login.microsoftonline.com/xxxxxxxx/v2.0
name: microsoft-entra-id
oidcClients:
- clientID: 76863fb1-xxxxxx
clientSecret:
name: console-secret
componentName: console
componentNamespace: openshift-console
serviceAccountIssuer: https://xxxxxx.s3.us-east-2.amazonaws.com/hypershift-ci-267402
type: OIDC
status:
oidcClients:
- componentName: console
componentNamespace: openshift-console
conditions:
- lastTransitionTime: "2024-02-28T10:51:17Z"
message: ""
reason: OIDCConfigAvailable
status: "False"
type: Degraded
- lastTransitionTime: "2024-02-28T10:51:17Z"
message: ""
reason: OIDCConfigAvailable
status: "False"
type: Progressing
- lastTransitionTime: "2024-02-28T10:51:17Z"
message: ""
reason: OIDCConfigAvailable
status: "True"
type: Available
currentOIDCClients:
- clientID: 76863fb1-xxxxxx
issuerURL: https://login.microsoftonline.com/xxxxxxxx/v2.0
oidcProviderName: microsoft-entra-id
4. Check pods again:
$ oc get po -n clusters-$HC_NAME --kubeconfig $MGMT_KUBECONFIG --sort-by metadata.creationTimestamp
...
kube-apiserver-596dcb97f-n5nqn 5/5 Running 0 108m
kube-apiserver-596dcb97f-7cn9f 5/5 Running 0 106m
kube-apiserver-596dcb97f-2rskz 5/5 Running 0 104m
openshift-apiserver-c9455455c-t7prz 3/3 Running 0 102m
openshift-apiserver-c9455455c-jrwdf 3/3 Running 0 101m
openshift-apiserver-c9455455c-npvn5 3/3 Running 0 100m
konnectivity-agent-7bfc7cb9db-bgrsv 1/1 Running 0 100m
cluster-version-operator-675745c9d6-5mv8m 1/1 Running 0 100m
hosted-cluster-config-operator-559644d45b-4vpkq 1/1 Running 0 100m
konnectivity-agent-7bfc7cb9db-hjqlf 1/1 Running 0 99m
konnectivity-agent-7bfc7cb9db-gl9b7 1/1 Running 0 99m
No new pods renewed.
5. Check login again, it does not use "sub", still use "email":
$ rm -rf ~/.kube/cache/
$ oc login --exec-plugin=oc-oidc --client-id=$CLIENT_ID --client-secret=$CLIENT_SECRET_VALUE --extra-scopes=email --callback-port=8080
Please visit the following URL in your browser: http://localhost:8080
Logged into "https://xxxxxxx.elb.ap-southeast-1.amazonaws.com:6443" as "oidc-user-test:xxia@redhat.com" from an external oidc issuer.
You don't have any projects. Contact your system administrator to request a project.
$ cat ~/.kube/cache/oc/* | jq -r '.id_token' | jq -R 'split(".") | .[] | @base64d | fromjson'
...
{
...
"email": "xxia@redhat.com",
"groups": [
...
],
...
"sub": "EEFGfgPXr0YFw_ZbMphFz6UvCwkdFS20MUjDDLdTZ_M",
...
Actual results:
Steps 4 ~ 5: after editing HC field value from "claim: email" to "claim: sub", even if `oc get authentication cluster -o yaml` shows the edited change is propagated: 1> The pods like kube-apiserver are not renewed. 2> After clean-up ~/.kube/cache, `oc login ...` relogin still prints 'Logged into "https://xxxxxxx.elb.ap-southeast-1.amazonaws.com:6443" as "oidc-user-test:xxia@redhat.com" from an external oidc issuer', i.e. still uses old claim "email" as user name, instead of using the new claim "sub".
Expected results:
Steps 4 ~ 5: Pods like kube-apiserver pods should renew after HC editing that changes user claim. The login should print that the new claim is used as user name.
Additional info:
Epic Goal
- Add an API extension for North-South IPsec.
- close gaps from
SDN-3604- mainly around upgrade - add telemetry
Why is this important?
- without API, customers are forced to use MCO. this brings with it a set of limitations (mainly reboot per change and the fact that config is shared among each pool, can't do per node configuration)
- better upgrade solution will give us the ability to support a single host based implementation
- telemetry will give us more info on how widely is ipsec used.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Must allow for the possibility of offloading the IPsec encryption to a SmartNIC.
- nmstate
- k8s-nmstate
- easier mechanism for cert injection (??)
- telemetry
Dependencies (internal and external)
Related:
- ITUP-44 - OpenShift support for North-South OVN IPSec
HATSTRAT-33- Encrypt All Traffic to/from Cluster (aka IPSec as a Service)
Previous Work (Optional):
SDN-717- Support IPSEC on ovn-kubernetesSDN-3604- Fully supported non-GA N-S IPSec implementation using machine config.
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This card tracks removing feature gate and making it GA in OCP.
Tracks work for https://github.com/kubernetes-sigs/network-policy-api/pull/209 AND then to consume that in OVNKubernetes
Card tracks getting anp and banp in must-gather
This card adds support for implementing ANP.Egress.Networks Peer in OVNKubernetes:
- vendoring in api from netpol api repo
- designing the ovnk pieces into the existing controller
- writing unit tests
- bringing in the conformance tests from upstream
Feature Overview (aka. Goal Summary)
oc, the openshift CLI, needs as close to feature parity as we can get without the built-in oauth server and its associated user and group management. This will enable scripts, documentation, blog posts, and knowledge base articles to function across all form factors and the same form factor with different configurations.
Goals (aka. expected user outcomes)
CLI users and scripts should be usable in a consistent way regardless of the token issuer configuration.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
oc login needs to work without the embedded oauth server
Why is this important? (mandatory)
We are removing the embedded oauth-server and we utilize a special oauthclient in order to make our login flows functional
This allows documentation, scripts, etc to be functional and consistent with the last 10 years of our product.
This may require vendoring entire CLI plugins. It may require new kubeconfig shapes.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Description of problem:
Separate oidc certificate authority and cluster certificate authority.
Version-Release number of selected component (if applicable):
oc 4.16 / 4.15
How reproducible:
Always
Steps to Reproduce:
1. Launch HCP external OIDC cluster. The external OIDC uses keycloak. The keycloak server is created outside of the cluster and its serving certificate is not trusted, its CA is separate than cluster's any CA. 2. Test oc login $ curl -sSI --cacert $ISSUER_CA_FILE $ISSUER_URL/.well-known/openid-configuration | head -n 1 HTTP/1.1 200 OK $ oc login --exec-plugin=oc-oidc --issuer-url=$ISSUER_URL --client-id=$CLI_CLIENT_ID --extra-scopes=email,profile --callback-port=8080 --certificate-authority $ISSUER_CA_FILE The server uses a certificate signed by an unknown authority. You can bypass the certificate check, but any data you send to the server could be intercepted by others. Use insecure connections? (y/n): n error: The server uses a certificate signed by unknown authority. You may need to use the --certificate-authority flag to provide the path to a certificate file for the certificate authority, or --insecure-skip-tls-verify to bypass the certificate check and use insecure connections.
Actual results:
2. oc login with --certificate-authority pointing to $ISSUER_CA_FILE fails. The reason is, oc login not only communicates with the oidc server, but also communicates the test cluster's kube-apiserver which is also self signed. Need more action for the --certificate-authority flag, i.e. need combine test cluster's kube-apiserver's CA and $ISSUER_CA_FILE: $ grep certificate-authority-data $KUBECONFIG | grep -Eo "[^ ]+$" | base64 -d > hostedcluster_kubeconfig_ca.crt $ cat $ISSUER_CA_FILE hostedcluster_kubeconfig_ca.crt > combined-ca.crt $ oc login --exec-plugin=oc-oidc --issuer-url=$ISSUER_URL --client-id=$CLI_CLIENT_ID --extra-scopes=email,profile --callback-port=8080 --certificate-authority combined-ca.crt Please visit the following URL in your browser: http://localhost:8080
Expected results:
For step 2, per https://redhat-internal.slack.com/archives/C060D1W96LB/p1711624413149659?thread_ts=1710836566.326359&cid=C060D1W96LB discussion, separate trust like:
$ oc login api-server --oidc-certificate-auhority=$ISSUER_CA_FILE [--certificate-authority=hostedcluster_kubeconfig_ca.crt]
The [--certificate-authority=hostedcluster_kubeconfig_ca.crt] should be optional if it is included in $KUBECONFIG's certificate-authority-data already.
Description of problem:
Introduce --issuer-url flag in oc login .
Version-Release number of selected component (if applicable):
[xxia@2024-03-01 21:03:30 CST my]$ oc version --client Client Version: 4.16.0-0.ci-2024-03-01-033249 Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3 [xxia@2024-03-01 21:03:50 CST my]$ oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.0-0.ci-2024-02-29-213249 True False 8h Cluster version is 4.16.0-0.ci-2024-02-29-213249
How reproducible:
Always
Steps to Reproduce:
1. Launch fresh HCP cluster.
2. Login to https://entra.microsoft.com. Register application and set properly.
3. Prepare variables.
HC_NAME=hypershift-ci-267920
MGMT_KUBECONFIG=/home/xxia/my/env/xxia-hs416-2-267920-4.16/kubeconfig
HOSTED_KUBECONFIG=/home/xxia/my/env/xxia-hs416-2-267920-4.16/hypershift-ci-267920.kubeconfig
AUDIENCE=7686xxxxxx
ISSUER_URL=https://login.microsoftonline.com/64dcxxxxxxxx/v2.0
CLIENT_ID=7686xxxxxx
CLIENT_SECRET_VALUE="xxxxxxxx"
CLIENT_SECRET_NAME=console-secret
4. Configure HC without oauthMetadata.
[xxia@2024-03-01 20:29:21 CST my]$ oc create secret generic console-secret -n clusters --from-literal=clientSecret=$CLIENT_SECRET_VALUE --kubeconfig $MGMT_KUBECONFIG
[xxia@2024-03-01 20:34:05 CST my]$ oc patch hc $HC_NAME -n clusters --kubeconfig $MGMT_KUBECONFIG --type=merge -p="
spec:
configuration:
authentication:
oauthMetadata:
name: ''
oidcProviders:
- claimMappings:
groups:
claim: groups
prefix: 'oidc-groups-test:'
username:
claim: email
prefixPolicy: Prefix
prefix:
prefixString: 'oidc-user-test:'
issuer:
audiences:
- $AUDIENCE
issuerURL: $ISSUER_URL
name: microsoft-entra-id
oidcClients:
- clientID: $CLIENT_ID
clientSecret:
name: $CLIENT_SECRET_NAME
componentName: console
componentNamespace: openshift-console
type: OIDC
"
Wait pods to renew:
[xxia@2024-03-01 20:52:41 CST my]$ oc get po -n clusters-$HC_NAME --kubeconfig $MGMT_KUBECONFIG --sort-by metadata.creationTimestamp
...
certified-operators-catalog-7ff9cffc8f-z5dlg 1/1 Running 0 5h44m
kube-apiserver-6bd9f7ccbd-kqzm7 5/5 Running 0 17m
kube-apiserver-6bd9f7ccbd-p2fw7 5/5 Running 0 15m
kube-apiserver-6bd9f7ccbd-fmsgl 5/5 Running 0 13m
openshift-apiserver-7ffc9fd764-qgd4z 3/3 Running 0 11m
openshift-apiserver-7ffc9fd764-vh6x9 3/3 Running 0 10m
openshift-apiserver-7ffc9fd764-b7znk 3/3 Running 0 10m
konnectivity-agent-577944765c-qxq75 1/1 Running 0 9m42s
hosted-cluster-config-operator-695c5854c-dlzwh 1/1 Running 0 9m42s
cluster-version-operator-7c99cf68cd-22k84 1/1 Running 0 9m42s
konnectivity-agent-577944765c-kqfpq 1/1 Running 0 9m40s
konnectivity-agent-577944765c-7t5ds 1/1 Running 0 9m37s
5. Check console login and oc login.
$ export KUBECONFIG=$HOSTED_KUBECONFIG
$ curl -ksS $(oc whoami --show-server)/.well-known/oauth-authorization-server
{
"issuer": "https://:0",
"authorization_endpoint": "https://:0/oauth/authorize",
"token_endpoint": "https://:0/oauth/token",
...
}
Check console login, it succeeds, console upper right shows correctly user name oidc-user-test:xxia@redhat.com.
Check oc login:
$ rm -rf ~/.kube/cache/oc/
$ oc login --exec-plugin=oc-oidc --client-id=$CLIENT_ID --client-secret=$CLIENT_SECRET_VALUE --extra-scopes=email --callback-port=8080
error: oidc authenticator error: oidc discovery error: Get "https://:0/.well-known/openid-configuration": dial tcp :0: connect: connection refused
error: oidc authenticator error: oidc discovery error: Get "https://:0/.well-known/openid-configuration": dial tcp :0: connect: connection refused
Unable to connect to the server: getting credentials: exec: executable oc failed with exit code 1
Actual results:
Console login succeeds. oc login fails.
Expected results:
oc login should also succeed.
Additional info:{}
Feature Overview (aka. Goal Summary)
When the internal oauth-server and oauth-apiserver are removed and replaced with an external OIDC issuer (like azure AD), the console must work for human users of the external OIDC issuer.
Goals (aka. expected user outcomes)
An end user can use the openshift console without a notable difference in experience. This must eventually work on both hypershift and standalone, but hypershift is the first priority if it impacts delivery
Requirements (aka. Acceptance Criteria):
- User can log in and use the console
- User can get a kubeconfig that functions on the CLI with matching oc
- Both of those work on hypershift
- both of those work on standalone.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- When the oauthclient API is not present, the operator must stop creating the oauthclient
Why is this important?
- This is preventing the operator from creating its deployment
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Console needs to be able to auth agains external OIDC IDP. For that console-operator need to set configure it in that order.
AC:
- bump console-operator API pkg
- sync oauth client secret from OIDC configuration for auth type OIDC
- add OIDC config to the console configmap
- add auth server CA to the deployment annotations and volumes when auth type OIDC
- consume OIDC configuration in the console configmap and deployment
- fix roles for oauthclients and authentications watching
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- When installed with external OIDC, the clientID and clientSecret need to be configurable to match the external (and unmanaged) OIDC server
Why is this important?
- Without a configurable clientID and secret, I don't think the console can identify the user.
- There must be a mechanism to do this on both hypershift and openshift, though the API may be very similar.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
The web console should behave like a generic OIDC client when requesting tokens from an OIDC provider.
User API may not always be available. K8S now has a stable API to query for user information - https://github.com/kubernetes/enhancements/tree/master/keps/sig-auth/3325-self-subject-attributes-review-api. See if it can be used and replace all `user/~` calls with it.
Feature Overview (aka. Goal Summary)
Enable a "Break Glass Mechanism" in ROSA (Red Hat OpenShift Service on AWS) and other OpenShift cloud-services in the future (e.g., ARO and OSD) to provide customers with an alternative method of cluster access via short-lived certificate-based kubeconfig when the primary IDP (Identity Provider) is unavailable.
Goals (aka. expected user outcomes)
- Enhance cluster reliability and operational flexibility.
- Minimize downtime due to IDP unavailability or misconfiguration.
- The primary personas here are OpenShift Cloud Services Admins and SREs as part of the shared responsibility.
- This will be an addition to the existing ROSA IDP capabilities.
Requirements (aka. Acceptance Criteria)
- Enable the generation of short-lived client certificates for emergency cluster access.
- Ensure certificates are secure and conform to industry standards.
- Functionality to invalidate short-lived certificates in case of an exploit.
Better UX
- User Interface within OCM to facilitate the process.
- SHOULD have audit capabilities.
- Minimal latency when generating and using certificates (to reduce time without access to cluster).
Use Cases (Optional)
- A customer's IDP is down, but they successfully use the break-glass feature to gain cluster access.
- SREs use their own break-glass feature to perform critical operations on a customer's cluster.
Questions to Answer (Optional)
- What is the lifetime of generated certificates? 7 days life and 1 day rotation?
- What security measures are in place for certificate generation and storage?
- What are the audit requirements?
Out of Scope
- Replacement of primary IDP functionality.
- Use of break-glass mechanism for routine operations (i.e., this is emergency/contingency mechanism)
Customer Considerations
- The feature is not a replacement for the primary IDP.
- Customers must understand the security implications of using short-lived certificates.
Documentation Considerations
- How-to guides for using the break-glass mechanism.
- FAQs addressing common concerns and troubleshooting.
- Update existing ROSA IDP documentation to include this new feature.
Interoperability Considerations
- Compatibility with existing ROSA, OSD (OpenShift Dedicated), and ARO (Azure Red Hat OpenShift) features.
- Interoperability tests should include scenarios where both IDP and break-glass mechanism are engaged simultaneously for access.
Goal
- Be able to provide the customer of managed OpenShift with a cluster-admin kubeconfig that allows them to access the cluster in the event that their identity provider (IdP or external OIDC) becomes unavailable or misconfigured.
Why is this important?
- Managed OpenShift customers need to be able to access/repair their clusters without RH intervention (i.e. opening a ticket) in the case of an identity provider outage or misconfiguration.
Scenarios
- ...
Acceptance Criteria
- Dev - Has a valid enhancement if necessary
- CI - MUST be running successfully with tests automated
- QE - covered in Polarion test plan and tests implemented
- Release Technical Enablement - Must have TE slides
- ...
Dependencies (internal and external)
- Coordination with OCM to make the kubeconfig available to customers upon request
Previous Work (Optional):
- …
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Customers need to be able to request the revocation of the signer cert for their break-glass credentials and know when it's been done. See design here: https://docs.google.com/document/d/19l48HB7-4_8p96b2kvlpYFpbZXCh5eXN_tEmM8QhaIc/edit#heading=h.1a08yt9sno82 and diagram here: https://miro.com/app/board/uXjVNUPFcQA=/
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
As part of the deprecation progression of the openshift-sdn CNI plug-in, remove it as an install-time option for new 4.15+ release clusters.
Goals (aka. expected user outcomes)
The openshift-sdn CNI plug-in is sunsetting according to the following progression:
- deprecation notice delivered at 4.14 (Release Notes, What's Next presentation)
- removal as an install-time option at 4.15+
- removal as an option and EOL support at 4.17 GA
Requirements (aka. Acceptance Criteria):
- The openshift-sdn CNI plug-in will no longer be an install-time option for newly installed 4.15+ clusters across installation options.
- Customer clusters currently using openshift-sdn that upgrade to 4.15 or 4.16 with openshift-sdn will remain fully supported.
- EUS customers using openshift-sdn on an earlier release (e.g. 4.12 or 4.14) will still be able to upgrade to 4.16 and receive full support of the openshift-sdn plug-in.
Questions to Answer (Optional):
- Will clusters using openshift-sdn and upgrading from earlier versions to 4.15 and 4.16 still be supported?
- YES
- My customer has a hard requirement for the ability to install openshift-sdn 4.15 clusters. Is there any exceptions to support that?
- Customers can file a Support Exception for consideration, and the reason for the requirement (expectation: rare) must be clarified.
Out of Scope
Background
All development effort is directed to the default primary CNI plug-in, ovn-kubernetes, which has feature parity with the older openshift-sdn CNI plug-in that has been feature frozen for the entire 4.x timeframe. In order to best serve our customers now and in the future, we are reducing our support footprint to the dominant plug-in, only.
Documentation Considerations
- Product Documentation updates to reflect the install-time option change.
Epic Goal
The openshift-sdn CNI plug-in is sunsetting according to the following progression:
- deprecation notice delivered at 4.14 (Release Notes, What's Next presentation)
- removal as an install-time option at 4.15+
- removal as an option and EOL support at 4.17 GA
Why is this important?
All development effort is directed to the default primary CNI plug-in, ovn-kubernetes, which has feature parity with the older openshift-sdn CNI plug-in that has been feature frozen for the entire 4.x timeframe. In order to best serve our customers now and in the future, we are reducing our support footprint to the dominant plug-in, only.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- The openshift-sdn CNI plug-in will no longer be an install-time option for newly installed 4.15+ clusters across installation options.
- Customer clusters currently using openshift-sdn that upgrade to 4.15 or 4.16 with openshift-sdn will remain fully supported.
- EUS customers using openshift-sdn on an earlier release (e.g. 4.12 or 4.14) will still be able to upgrade to 4.16 and receive full support of the openshift-sdn plug-in.
Open questions::
- Will clusters using openshift-sdn and upgrading from earlier versions to 4.15 and 4.16 still be supported?
- YES
- My customer has a hard requirement for the ability to install openshift-sdn 4.15 clusters. Is there any exceptions to support that?
- Customers can file a Support Exception for consideration, and the reason for the requirement (expectation: rare) must be clarified.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
The openshift-sdn CNI plug-in is sunsetting according to the following progression:
- deprecation notice delivered at 4.14 (Release Notes, What's Next presentation)
- removal as an install-time option at 4.15+
- removal as an option and EOL support at 4.17 GA
Why is this important?
All development effort is directed to the default primary CNI plug-in, ovn-kubernetes, which has feature parity with the older openshift-sdn CNI plug-in that has been feature frozen for the entire 4.x timeframe. In order to best serve our customers now and in the future, we are reducing our support footprint to the dominant plug-in, only.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- The openshift-sdn CNI plug-in will no longer be an install-time option for newly installed 4.15+ clusters across installation options.
- Customer clusters currently using openshift-sdn that upgrade to 4.15 or 4.16 with openshift-sdn will remain fully supported.
- EUS customers using openshift-sdn on an earlier release (e.g. 4.12 or 4.14) will still be able to upgrade to 4.16 and receive full support of the openshift-sdn plug-in.
Open questions::
- Will clusters using openshift-sdn and upgrading from earlier versions to 4.15 and 4.16 still be supported?
- YES
- My customer has a hard requirement for the ability to install openshift-sdn 4.15 clusters. Is there any exceptions to support that?
- Customers can file a Support Exception for consideration, and the reason for the requirement (expectation: rare) must be clarified.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Have OpenShiftSDN (openshift-sdn CNI plug-in) no longer be an option for networkType, making the only supported value for the network OVNKubernetes
so that I can achieve
- The removal of the openshift-sdn CNI plug-in at install-time for 4.15+
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional)[ https://github.com/openshift/enhancements/blob/master/enhancements/network/sdn-live-migration.md#rollback|https://github.com/openshift/enhancements/blob/master/enhancements/network/sdn-live-migration.md#rollback]
- https://github.com/openshift/installer/blob/f60ebb065b4242586f7afacc5f2be8afddbdfbde/pkg/types/validation/installconfig.go#L333C1-L333C85
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview
Users of the OpenShift Console leverage a streamlined, visual experience when discovering and installing OLM-managed operators in clusters that run on cloud providers with support for short-lived token authentication enabled. Users are intuitively becoming aware when this is the case and are put on the happy path to configure OLM-managed operators with the necessary information to support GCP Workload Identify Foundation (WIF).
Goals:
Customers do not need to re-learn how to enable GCP WIF authentication support for each and every OLM-managed operator that supports it. The experience is standardized and repeatable so customers spend less time with initial configuration and more team implementing business value. The process is so easy that OpenShift is perceived as enabler for an increased security posture.
Requirements:
- based on
OCPSTRAT-922, the installation and configuration experience for any OLM-managed operator using short-lived token authentication is streamlined using the OCP console in the form of a guided process that avoids misconfiguration or unexpected behavior of the operators in question - the OCP Console helps in detecting when the cluster itself is already using GCP WIF for core functionality
- the OCP Console helps discover operators capable of GCP WIF authentication and their IAM permission requirements
- the OCP Console has a filtering capability for operators capable of GCP WIF authentication in the main catalog tile view
- the OCP Console drives the collection of the required information for GCP WIF authentication at the right stages of the installation process and stops the process when the information is not provided
- the OCP Console implements this process with minimal differences across different cloud providers and is capable of adjusting the terminology depending on the cloud provider that the cluster is running on
Use Cases:
- A cluster admin browses the OperatorHub catalog and looks at the details view of a particular operator, there they discover that the cluster is configured for GCP WIF
- A cluster admin browsing the OperatorHub catalog content can filter for operators that support the GCP WIF flow described in
OCPSTRAT-922 - A cluster admin reviewing the details of a particular operator in the OperatorHub view can discover that this operator supports GCP WIF authentication
- A cluster admin installing a particular operator can get information about the GCP IAM permission requirements the operator has
- A cluster admin installing a particular operator is asked to provide GCP ServiceAccount that is required for GCP WIF prior to the actual installation step and is prevented from continuing without this information
- A cluster admin reviewing an installed operators with support for GCP WIF can discover the related CredentialRequest object that the operator created in an intuitive way (not generically via related objects that have an ownership reference or as part of the InstallPlan)
Out of Scope
- update handling and blocking in case of increased permission requirements in the next / new version of the operator
- more complex scenarios with multiple IAM roles/service principals resulting in multiple CredentialRequest objects used by a single operator
Background
The OpenShift Console today provides little to no support for configuring OLM-managed operators for short-lived token authentication. Users are generally unaware if their cluster runs on a cloud provider and is set up to use short-lived tokens for its core functionality and users are not aware which operators have support for that by implementing the respective flows defined in OCPSTRAT-922.
Customer Considerations
Customers may or may not be aware about short-lived token authentication support. They need to proper context and pointers to follow-up documentation to explain the general concept and the specific configuration flow the Console supports. It needs to become clear that the Console cannot 100% automate the overall process and some steps need to be run outside of the cluster/Console using Cloud-provider specific tooling.
Epic Goal
- Transparently support old and new infrastructure annotations format delivered by OLM-packaged operators
Why is this important?
- As part of part of OCPSTRAT-288 we are looking to improve the metadata quality of Red Hat operators in OpenShift
- via
PORTENABLE-525we are defining a new metadata format that supports the aforementioned initiative with more robust detection of individual infrastructure features via boolean data types
Scenarios
- A user can use the OCP console to browse through the OperatorHub catalog and filter for all the existing and new annotations defined in
PORTENABLE-525 - A user reviewing an operator's detail can see the supported infrastructures transparently regardless if the operator uses the new or the existing annotations format
Acceptance Criteria
- the new annotation format is supported in operatorhub filtering and operator details pages
- the old annotation format keeps being supported in operatorhub filtering and operator details pages
- the console will respect both the old and the new annotations format
- when for a particular feature both the operator denotes data in both the old and new annotation format, the annotations in the newer format take precedence
- the newer infrastructure features from
PORTENABLE-525tls-profiles and token-auth/* do not have equivalents in the old annotation format and evaluation doesn't need to fall back as described in the previous point
Dependencies (internal and external)
- none
Open Questions
- due to the non-intrusive nature of this feature, can we ship it in a 4.14.z patch release?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
https://issues.redhat.com/browse/PORTENABLE-525 adds new annotations, including features.operators.openshift.io/token-auth-gcp, but console does not yet support this new annotation. We need to determine what changes are necessary to support this new annotation and implement them.
AC:
- Uncomment auth token GCP annotation related code, which has been added in https://github.com/openshift/console/pull/13183/files
- Add "Auth Token GCP" filter (TBD) to Infrastructure features filter section in the operator hub
https://issues.redhat.com/browse/PORTENABLE-525 adds new annotations, including features.operators.openshift.io/tls-profiles, but console does not yet support this new annotation. We need to determine what changes are necessary to support this new annotation and implement them.
AC:
- Uncomment TLS annotation related code, which has been added in https://github.com/openshift/console/pull/13183/files
- Add "Configurable TLS ciphers" filter to Infrastructure features filter section in the operator hub
Address technical debt around self-managed HCP deployments, including but not limited to
- CA ConfigMaps into the trusted bundle for both the CPO and Ignition Server, improving trust and security.
- Create dual stack clusters through CLI with or without default values, ensuring flexibility and user preference in network management.
- Utilize CLI commands to disable default sources, enhancing customizability.
- Benefit from less intrusive remote write failure modes,.
- ...
The CLI cannot create dual stack clusters with the default values. We need to create the proper flags to enable the HostedCluster to be a dual stack one using the default values
Users are encountering an issue when attempting to "Create hostedcluster on BM+disconnected+ipv6 through MCE." This issue is related to the default settings of `--enable-uwm-telemetry-remote-write` being true. Which might mean that that in the default case with disconnected and whatever is configured in the configmap for UWM e.g ( minBackoff: 1s url: https://infogw.api.openshift.com/metrics/v1/receive Is not reachable with disconneced. So we should look into reporting the issue and remdiating vs. Fataling on it for disconnected scenarios.
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1. 2. 3.
Actual results:
Expected results:
Additional info:
In MCE 2.4, we currently document to disable `--enable-uwm-telemetry-remote-write` if the hosted control plane feature is used in a disconnected environment. https://github.com/stolostron/rhacm-docs/blob/lahinson-acm-7739-disconnected-bare-[…]s/hosted_control_planes/monitor_user_workload_disconnected.adoc Once this Jira is fixed, the documentation needs to be removed, users do not need to disable `--enable-uwm-telemetry-remote-write`. The HO is expected to fail gracefully on `--enable-uwm-telemetry-remote-write` and continue to be operational.
This can be based on the exising CAPI agent provider workflow which already has an env var flag for disconnected
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Goal of this epic is to capture all the amount of required work and efforts that take to update the openshift control plane with the upstream kubernetes v1.29
Why is this important?
- Rebase is a must process for every ocp release to leverage all the new features implemented upstream
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- Following epic captured the previous rebase work of k8s v1.28
https://issues.redhat.com/browse/STOR-1425
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
While monitoring the payload job failures, open a parallel openshift/origin bump.
Note: There is a high chance of job failures in openshift/origin bump until the openshift/kubernetes PR merges as we only update the test and not the actual kube.
Benefit of opening this PR before ocp/k8s merge is to identify and fix the issues beforehand.
Follow the rebase doc[1] and update the spreadsheet[2] that tracks the required commits to be cherry-picked. Rebase the o/k repo with the "merge=ours" strategy as mentioned in the rebase doc.
Save the last commit id in the spreadsheet for future references.
Update the rebase doc if required.
[1] https://github.com/openshift/kubernetes/blob/master/REBASE.openshift.md
[2] https://docs.google.com/spreadsheets/d/10KYptJkDB1z8_RYCQVBYDjdTlRfyoXILMa0Fg8tnNlY/edit#gid=1957024452
Prev. Ref:
https://github.com/openshift/kubernetes/pull/1646
- https://github.com/openshift/cluster-kube-apiserver-operator/pull/1608
- https://github.com/openshift/cluster-kube-apiserver-operator/pull/1596
- https://github.com/openshift/kubernetes/pull/1888
- https://github.com/openshift/kubernetes/pull/1858
- https://github.com/openshift/kubernetes/pull/1845
- https://github.com/openshift/kubernetes/pull/1849
- https://github.com/openshift/kubernetes/pull/1848
- https://github.com/openshift/kubernetes/pull/1846
- https://github.com/openshift/kubernetes/pull/1840
- https://github.com/openshift/kubernetes/pull/1815
- https://github.com/openshift/origin/pull/28465
- https://github.com/openshift/origin/pull/28458
Bump the following libraries in an order with the latest kube and the dependent libraries
- openshift/api
- openshift/client-go
- openshift/library-go
- openshift/apiserver-library-go
- kube-openapi (if required)
Prev Ref:
https://github.com/openshift/api/pull/1534
https://github.com/openshift/client-go/pull/250
https://github.com/openshift/library-go/pull/1557
https://github.com/openshift/apiserver-library-go/pull/118
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned CAPI components should be running on Kubernetes 1.28
- target is 4.16 since CAPI is always a release behind upstream
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.16 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
This epic will own all of the usual update, rebase and release chores which must be done during the OpenShift 4.16 timeframe for Custom Metrics Autoscaler, Vertical Pod Autoscaler and Cluster Resource Override Operator
Shepherd and merge operator automation PR https://github.com/openshift/vertical-pod-autoscaler-operator/pull/151
Update operator like was done in https://github.com/openshift/vertical-pod-autoscaler-operator/pull/146
Shepherd and merge operand automation PR https://github.com/openshift/kubernetes-autoscaler/pull/277
Coordinate with cluster autoscaler team on upstream rebase as in https://github.com/openshift/kubernetes-autoscaler/pull/250
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned components should be running on Kubernetes 1.29
- This includes
- The cluster autoscaler (+operator)
- Machine API operator
- Machine API controllers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Machine API controllers for:
- Cloud Controller Manager Operator
- Cloud controller managers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Cloud controller managers for:
- Cluster Machine Approver
- Cluster API Actuator Package
- Control Plane Machine Set Operator
Why is this important?
- ...
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.16 release, dependencies need to be updated to 1.29. This should be done by rebasing/updating as appropriate for the repository
This should be the last SDN Kube rebase, but we need to work with the windows team to find a way for them to get the latest Kube-Proxy without depending on this rebase as SDN is deprecated
- https://github.com/openshift/oc/pull/1661
- https://github.com/openshift/oc/pull/1655
- https://github.com/openshift/cluster-openshift-controller-manager-operator/pull/324
- https://github.com/openshift/cluster-policy-controller/pull/146
- https://github.com/openshift/openshift-controller-manager/pull/283
- https://github.com/openshift/route-controller-manager/pull/38
Epic Goal
- The goal of this epic is to upgrade all OpenShift and Kubernetes components that MCO uses to v1.29 which will keep it on par with rest of the OpenShift components and the underlying cluster version.
Why is this important?
- Uncover any possible issues with the openshift/kubernetes rebase before it merges.
- MCO continues using the latest kubernetes/OpenShift libraries and the kubelet, kube-proxy components.
- MCO e2e CI jobs pass on each of the supported platform with the updated components.
Acceptance Criteria
- All stories in this epic must be completed.
- Go version is upgraded for MCO components.
- CI is running successfully with the upgraded components against the 4.16/master branch.
Dependencies (internal and external)
- ART team creating the go 1.29 image for upgrade to go 1.29.
- OpenShift/kubernetes repository downstream rebase PR merge.
Open questions::
- Do we need a checklist for future upgrades as an outcome of this epic?-> yes, updated below.
Done Checklist
- Step 1 - Upgrade go version to match rest of the OpenShift and Kubernetes upgraded components.
- Step 2 - Upgrade Kubernetes client and controller-runtime dependencies (can be done in parallel with step 3)
- Step 3 - Upgrade OpenShift client and API dependencies
- Step 4 - Update kubelet and kube-proxy submodules in MCO repository
- Step 5 - CI is running successfully with the upgraded components and libraries against the master branch.
This story relates to this PR https://github.com/openshift/machine-config-operator/pull/4275
A new PR has been opened to investigate the issues found in the original PR (this is the link to the new PR): https://github.com/openshift/machine-config-operator/pull/4306
The original PR exceeded the watch request limits when merged. When discovered, the CNTO team needed to revert it. (see https://redhat-internal.slack.com/archives/C01CQA76KMX/p1711711538689689).
To investigate if exceeding the watch request limit was introduced from the API bump and its associated changes, or the kubeconfig changes, an additional PR was opened just for looking at removing the hardcoded values from the kubelet template, and payload tests were run against it: https://github.com/openshift/machine-config-operator/pull/4270. The payload tests passed, and it was concluded that the watch request limit issue was introduced in the portion of the PR that included the API bump and its associated changes.
It was discovered that the CNTO team was using an outdated form of openshift deps, so they were asked to bump. https://redhat-internal.slack.com/archives/CQNBUEVM2/p1712171079685139?thread_ts=1711712855.478249&cid=CQNBUEVM2
https://github.com/openshift/cluster-node-tuning-operator/pull/990
was opened in the past to address the kube bump (this just merged), and https://github.com/openshift/cluster-node-tuning-operator/pull/1022
was opened as well (still open)
CURRENT STATUS: waiting for https://github.com/openshift/cluster-node-tuning-operator/pull/1022 to merge so we can rerun payload tests against the revert PR open.
User or Developer story
As a MCO developer, I want to pick up the openshift/kubernetes updates for the 1.29 k8s rebase to track the k8s version as rest of the OpenShift 1.29 cluster.
Engineering Details
- Update the go.mod, go.sum and vendor dependencies pointing to the kube1.29 libraries. This includes all direct kubernetes related libraries as well as openshift/api , openshift/client-go, openshift/library-go and openshift/runtime-utils
Acceptance Criteria:
- All k8s.io related dependencies should be upgraded to 1.29.
- openshift/api , openshift/client-go, openshift/library-go and openshift/runtime-utils should be upgraded to latest commit from master branch
- All ci tests must be passing
This feature is now re-opened because we want to run z-rollback CI. This feature doesn't block the release of 4.17.This is not going to be exposed as a customer-facing feature and will not be documented within OpenShift documentation. This is strictly going to be covered as a RH Support guided solution with KCS article providing guidance. A public facing KCS will basically point to contacting Support for help on Z-stream rollback, and Y-stream rollback is not supported.
NOTE:
Previously this was closed as "won't do" because didn't have a plan to support y-stream and z-stream rollbacks is standalone openshift.
For Single node openshift please check TELCOSTRAT-160 . "won't do" decisions was after further discussion with leadership.
The e2e tests https://docs.google.com/spreadsheets/d/1mr633YgQItJ0XhbiFkeSRhdLlk6m9vzk1YSKQPHgSvw/edit?gid=0#gid=0 We have identified a few bugs that need to be resolved before the General Availability (GA) release. Ideally, these should be addressed in the final month before GA when all features are development complete. However, asking component teams to commit to fixing critical rollback bugs during this time could potentially delay the GA date.
------
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Red Hat Support assisted z-stream rollback from 4.16+
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Include the anticipated primary user type/persona and which existing features, if any, will be expanded. Complete during New status.
Red Hat Support may, at their discretion, assist customers with z-stream rollback once it’s determined to be the best option for restoring a cluster to the desired state whenever a z-stream rollback compromises cluster functionality.
Engineering will take a “no regressions, no promises” approach, ensuring there are no major regressions between z-streams, but not testing specific combinations or addressing case-specific bugs.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
- Public Documentation (or KCS?) that explains why we do not advise unassisted z-stream rollback and what to do when a cluster experiences loss of functionality associated with a z-stream upgrade.
- Internal KCS article that provides a comprehensive plan for troubleshooting and resolving issues introduced after applying a z-stream update, up to and including complete z-stream rollback.
- Should include alternatives such as limited component rollback (single operator, RHCOS, etc) and workaround options
- Should include incident response and escalation procedures for all issues incurred during application of a z-stream update so that even if rollback is performed we’re tracking resolution of defects with highest priority
- Foolproof command to initiate z-stream rollback with Support’s approval, aka a hidden command that ensures we don’t typo the pull spec or initiate A->B->C version changes, only A->B->A
- Test plan and jobs to ensure that we have high confidence in ability to rollback a z-stream along happy paths
- Need not be tested on all platforms and configurations, likely metal or vSphere and one foolproof platform like AWS
- Test should not monitor for disruption since it’s assumed disruption is tolerable during an emergency rollback provided we achieve availability at the end of the operation
- Engineering agrees to fix bugs which inhibit rollback completion before the current master branch release ships, aka they’ll be filed as blockers for the current master branch release. This means bugs found after 4.N branches may not be fixed until the next release without discussion.
Anyone reviewing this Feature needs to know which deployment configurations that the Feature will apply to (or not) once it's been completed. Describe specific needs (or indicate N/A) for each of the following deployment scenarios. For specific configurations that are out-of-scope for a given release, ensure you provide the OCPSTRAT (for the future to be supported configuration) as well.
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed | all |
| Multi node, Compact (three node) | all |
| Connected and Restricted Network | all |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | all |
| Release payload only | all |
| Starting with 4.16, including all future releases | all |
While this feature applies to all deployments we will only run a single platform canary test on a high success rate platform, such as AWS. Any specific ecosystems which require more focused testing should bring their own testing.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
As an admin who has determined that a z-stream update has compromised cluster functionality I have clear documentation that explains that unassisted rollback is not supported and that I should consult with Red Hat Support on the best path forward.
As a support engineer I have a clear plan for responding to problems which occur during or after a z-stream upgrade, including the process for rolling back specific components, applying workarounds, or rolling the entire cluster back to the previously running z-stream version.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Should we allow rollbacks whenever an upgrade doesn’t complete? No, not without fully understanding the root cause. If it’s simply a situation where workers are in process of updating but stalled, that should never yield a rollback without credible evidence that rollback will fix that.
Similar to our “foolproof command” to initiate rollback to previous z-stream should we also craft a foolproof command to override select operators to previous z-stream versions? Part of the goal of the foolproof command is to avoid potential for moving to an unintended version, the same risk may apply at single operator level though impact would be smaller it could still be catastrophic.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Non-HA clusters, Hosted Control Planes – those may be handled via separately scoped features
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Occasionally clusters either upgrade successfully and encounter issues after the upgrade or may run into problems during the upgrade. Many customers assume that a rollback will fix their concerns but without understanding the root cause we cannot assume that’s the case. Therefore, we recommend anyone who has encountered a negative outcome associated with a z-stream upgrade contact support for guidance.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
It’s expected that customers should have adequate testing and rollout procedures to protect against most regressions, i.e. roll out a z-stream update in pre-production environments where it can be adequately tested prior to updating production environments.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
This is largely a documentation effort, i.e. we should create either a KCS article or new documentation section which describes how customers should respond to loss of functionality during or after an upgrade.
KCS Solution : https://access.redhat.com/solutions/7083335
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Given we test as many upgrade configurations as possible and for whatever reason the upgrade still encounters problems, we should not strive to comprehensively test all configurations for rollback success. We will only test a limited set of platforms and configurations necessary to ensure that we believe the platform is generally able to roll back a z-stream update.
Epic Goal
- Validate z-stream rollbacks in CI starting with 4.10 by ensuring that a rollback completes unassisted and e2e testsuite passes
- Provide internal documentation (private KCS article) that explains when this is the best course of action versus working around a specific issue
- Provide internal documentation (private KCS article) that explains the expected cluster degradation until the rollback is complete
- Provide internal documentation (private KCS article) outlining the process and any post rollback validation
Why is this important?
- Even if upgrade success is 100% there's some chance that we've introduced a change which is incompatible with a customer's needs and they desire to roll back to the previous z-stream
- Previously we've relied on backup and restore here, however due to many problems with time travel, that's only appropriate for disaster recovery scenarios where the cluster is either completely shut down already or it's acceptable to do so while also accepting loss of any workload state change (PVs that were attached after the backup was taken, etc)
- We believe that we can reasonably roll back to a previous z-stream
Scenarios
- Upgrade from 4.10.z to 4.10.z+n
- oc adm upgrade rollback-z-stream – which will initially be hidden command, this will look at clusterversion history and rollback to the previous version if and only if that version is a z-stream away
- Rollback from 4.10.z+n to exactly 4.10.z, during which the cluster may experience degraded service and/or periods of service unavailability but must eventually complete with no further admin action
- Must pass 4.10.z e2e testsuite
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Fix all bugs listed here
project = "OpenShift Bugs" AND affectedVersion in( 4.12, 4.14, 4.15) AND labels = rollback AND status not in (Closed ) ORDER BY status DESC
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- At least today we indend to only surface this process internally and work through it with customers actively engaged with support, where do we put that?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
- The OC command should start update to the previous z stream from the history.
- This should be hidden command at this point of time.
Feature Overview (Goal Summary):
Identify and fill gaps related to CI/CD for HyperShift-ARO integration.
Goals (Expected User Outcomes):
- Establish a consistent and automated testing pipeline that reduces the risk of regressions and improves code quality.
- Enhance the user experience by ensuring that HyperShift's integration with Azure is thoroughly tested and reliable.
Requirements (Acceptance Criteria):
- Develop and integrate an Azure-specific testing suite that can be run as part of the pres-ubmit checks.
- Implement a schedule for periodic conformance tests on ARO.
- Maintain documentation that guides contributors on how to write and run tests within the ARO ecosystem.
Use Cases
- A developer submits a pull request to HyperShift’s codebase, which automatically triggers the Azure-specific presubmit tests.
- Scheduled conformance tests run automatically at predetermined intervals, providing ongoing assurance of ARO's integration with Azure.
We want to make sure ARO/HCP development happens while satisfying e2e expectations
Acceptance Criteria:
There's a running, blocking test for azure in presubmits
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- Discussed creating a HC on our root CI cluster that would have an Azure HC which would be used as our Azure mgmt cluster. We would need to
- Manually create the Azure HC on the root CI
- Capture the manifests for that and put them in contrib
- Configure the IDP
- Setup credentials
![]() This does not require a design proposal.
This does not require a design proposal.
![]() This does not require a feature gate.
This does not require a feature gate.
User Story:
As a (user persona), I want to be able to:
- Create ARO HCs off an ARO MGMT cluster
so that I can achieve
- Better Dev flow
- Enable pre-submit e2e testing for ARO dev work
Acceptance Criteria:
Description of criteria:
- ARO mgmt cluster exists.
- Documents to reproduce mgmt cluster env exist.
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Currently when creating the resource group it will be deleted after 24 hours. We can change this by setting an expiry tag on the resource group once created.
The ability to set this expiry tag when creating the resource group as part of the cluster creation command would be nice
Feature Overview
OCP 4 clusters still maintain pinned boot images. We have numerous clusters installed that have boot media pinned to first boot images as early as 4.1. In the future these boot images may not be certified by the OEM and may fail to boot on updated datacenter or cloud hardware platforms. These "pinned" boot images should be updateable so that customers can avoid this problem and better still scale out nodes with boot media that matches the running cluster version.
Phase one: GCP tech preview
The bootimage references are currently saved off in the machineset by the openshift installer and is thereafter unmanaged. This machineset object is not updated on an upgrade, so any node scaled up using it will boot up with the original “install” bootimage.
The “new” boot image references are available in a configmap/coreos-bootimages in the MCO namespace. Here is the PR that implemented this, it’s basically a CVO manifest that pulls from this file in the installer binary. Hence, they are updated on an upgrade. It can also be printed out to console by the following command on the installer: /openshift-install coreos print-stream-json.
Implementing this portion should be as simple as iterating through each machineset, and updating the new disk image by crossreferencing the configmap, architecture, region and the platform used in the machineset. This is where the installer figures out the bootimage during an install, so we could model a bit after this.
It looks like we have Machine API objects for every platform specific providerSpec(formally called providerConfig) we support here. We'd still have to special case the image/ami actual portion of this, but we should be able to leverage some of the work done in the installer(to generate machinesets, for example, GCP) to understand how the image reference is stored for every platform.
Done when:
For MVP, the goal is to
- add a new sub controller within the MCC. This subcontroller can be triggered by a listener on the machinesets and if any changes happen to the "golden" configmap mentioned above
- We'll support GCP to start. I'll make a follow-up card for the other platforms, but I'm open to adding more here if needed!
Feature Overview (Goal Summary)
This feature is dedicated to enhancing data security and implementing encryption best practices across control-planes, Etcd, and nodes for HyperShift with Azure. The objective is to ensure that all sensitive data, including secrets is encrypted, thereby safeguarding against unauthorized access and ensuring compliance with data protection regulations.
User Story:
- As a service provider/consumer I want to make sure secrets are encrypted with key owned by the consumer
Acceptance Criteria:
Expose and propagate input for kms secret encryption similar to what we do in AWS.
See related discussion:
https://redhat-internal.slack.com/archives/CCV9YF9PD/p1696950850685729
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a user of HCP on Azure, I would like to be able to pass a customer-managed key when creating a HC so that the disks for the VMs in the NodePool are encrypted.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a user of HCP on Azure, I want to be able to provide a DiskEncryptionSet ID to encrypt the OS disks for the VMs in the NodePool so that the data on the OS disks will be protected by encryption.
Acceptance Criteria:
Description of criteria:
- Upstream documentation add on what is needed for the Azure Key Vault and how to encrypt the OS disks thru both the CLI and through the CR spec.
- HyperShift CLI lets a user provide a DiskEncryptionSet ID to encrypt the OS disk.
- Ability to encrypt the OS disks through the HyperShift CLI.
- Ability to encrypt the OS disks through the HC CR.
- Any applicable unit tests.
Out of Scope:
N/A
Engineering Details:
- BYO resource group is required for this story.
- This story programmatically implements this Azure demo of using customer keys to encrypt the OS disk - https://learn.microsoft.com/en-us/azure/virtual-machines/disks-enable-host-based-encryption-portal?tabs=azure-powershell#deploy-a-vm-with-customer-managed-keys
Epic Goal*
There was an epic / enhancement to create a cluster-wide TLS config that applies to all OpenShift components:
https://issues.redhat.com/browse/OCPPLAN-4379
https://github.com/openshift/enhancements/blob/master/enhancements/kube-apiserver/tls-config.md
For example, this is how KCM sets --tls-cipher-suites and --tls-min-version based on the observed config:
https://issues.redhat.com/browse/WRKLDS-252
https://github.com/openshift/cluster-kube-controller-manager-operator/pull/506/files
The cluster admin can change the config based on their risk profile, but if they don't change anything, there is a reasonable default.
We should update all CSI driver operators to use this config. Right now we have a hard-coded cipher list in library-go. See OCPBUGS-2083 and OCPBUGS-4347 for background context.
Why is this important? (mandatory)
This will keep the cipher list consistent across many OpenShift components. If the default list is changed, we get that change "for free".
It will reduce support calls from customers and backport requests when the recommended defaults change.
It will provide flexibility to the customer, since they can set their own TLS profile settings without requiring code change for each component.
Scenarios (mandatory)
As a cluster admin, I want to use TLSSecurityProfile to control the cipher list and minimum TLS version for all CSI driver operator sidecars, so that I can adjust the settings based on my own risk assessment.
Dependencies (internal and external) (mandatory)
None, the changes we depend on were already implemented.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be "Release Pending"
Feature Overview (Goal Summary)
This feature introduces automatic Etcd snapshot functionality for self-managed hosted control planes, expanding control and flexibility for users. Unlike managed hosted control planes, self-managed environments allow for customized configurations. This feature aims to enable users to leverage any S3-compatible storage for etcd snapshot storage, ensuring high availability and resilience for their OpenShift clusters.
Goals (Expected User Outcomes)
- Primary User Persona: Cluster Service Providers
- User Benefit: Enhanced data protection and quicker disaster recovery for Hosted Clusters clusters through automated etcd snapshots.
Requirements (Acceptance Criteria)
- Automatic Snapshot Creation: Etcd snapshots must be taken automatically at regular intervals.
- S3 Storage: Support for any S3-compatible storage for snapshot storage.
- Snapshot Rotation and Retention Policy: Snapshots are rotated/removed after a specified period to manage storage efficiently.
- Restoration SOP: Standard Operating Procedures for Etcd restoration should be established, targeting a recovery time objective (RTO) of approximately 1 hour at max. Preferrearbly automated as well.
- Metrics: Track Mean Time to Recovery (MTTR) for improved reliability. Do we have metrics?
Goal
- Prescriptive guide for leveraging OADP/Velero to perform hosted cluster back up and restore
Why is this important?
- Customers need guidance on how they can perform back up and restore using OADP and what can and can't be done.
Scenarios
- Disaster recovery
- Migration
Acceptance Criteria
- Dev - Documentation
- CI - Test that backs up and restores a non empty hosted cluster
- QE - covered in Polarion test plan and tests implemented
- DOCS - Inclusion in the release documentation
Dependencies (internal and external)
- OADP
- Velero
Open questions:
- What is the maximum scope that can be done without plugins?
- What is and is not backed up?
- Ordering considerations
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Technical Enablement <link to Feature Enablement Presentation>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Enhancement merged: <link to meaningful PR or GitHub Issue>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
As an engineer I need to perform a spike over backup and restore proceduers on HostedCluster using OADP, in order to know if that could be an alternative or a resource in the new ETCD Backup API for HCP.
Goal:
As an administrator, I would like to use my own managed DNS solution instead of only specific openshift-install supported DNS services (such as AWS Route53, Google Cloud DNS, etc...) for my OpenShift deployment.
Problem:
While cloud-based DNS services provide convenient hostname management, there's a number of regulatory (ITAR) and operational constraints customers face prohibiting the use of those DNS hosting services on public cloud providers.
Why is this important:
- Provides customers with the flexibility to leverage their own custom managed ingress DNS solutions already in use within their organizations.
- Required for regions like AWS GovCloud in which many customers may not be able to use the Route53 service (only for commercial customers) for both internal or ingress DNS.
- OpenShift managed internal DNS solution ensures cluster operation and nothing breaks during updates.
Dependencies (internal and external):
- DNS work for KNI
- https://docs.google.com/document/d/1VsukDGafynKJoQV8Au-dvtmCfTjPd3X9Dn7zltPs8Cc/edit
- This is a prerequisite for the internal clusters epic: https://docs.google.com/document/d/1gxtIW6OlasVQtQLTyOl6f9H9CMuxiDNM5hQFNd3xubE/edit#
Prioritized epics + deliverables (in scope / not in scope):
- Ability to bootstrap cluster without an OpenShift managed internal DNS service running yet
- Scalable, cluster (internal) DNS solution that's not dependent on the operation of the control plane (in case it goes down)
- Ability to automatically propagate DNS record updates to all nodes running the DNS service within the cluster
- Option for connecting cluster to customers ingress DNS solution already in place within their organization
Estimate (XS, S, M, L, XL, XXL):
Previous Work:
Open questions:
Link to Epic: https://docs.google.com/document/d/1OBrfC4x81PHhpPrC5SEjixzg4eBnnxCZDr-5h3yF2QI/edit?usp=sharing
Append Infra CR with only the GCP PlatformStatus field (without any other fields esp the Spec) set with the LB IPs at the end of the bootstrap ignition. The theory is that when Infra CR is applied from the bootstrap ignition, first the infra manifest is applied. As we progress through all the other assets in the ignition files, Infra CR appears again but with only the LB IPs set. That way it will update the existing Infra CR already applied to the cluster.
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- At this point in the feature, we would have a working in-cluster CoreDNS pod capable of resolving API and API-Int URLs.
This Epic details that work required to augment this CoreDNS pod to also resolve the *.apps URL. In addition, it will include changes to prevent Ingress Operator from configuring the cloud DNS after the ingress LBs have been created.
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- https://github.com/openshift/api/pull/1685 introduced updates that allows the LB IPs to be added to GCPPlatformStatus along with the state of DNS for the cluster.
- Update cluster-ingress-operator to add the Ingress LB IPs when DNSType is `ClusterHosted`
- In this state, Within https://github.com/openshift/api/blob/master/operatoringress/v1/types.go set the DNSManagementPolicy to Unmanaged within the DNSRecordSpec when the DNS manifest has customer Managed DNS enabled.
- With the DNSManagementPolicy set to Unmanaged, the IngressController should not try to configure DNS records.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
Stop generating long-lived service account tokens. Long-lived service account tokens are currently generated in order to then create an image pull secret for the internal image registry. This feature calls for using the TokenRequest API to generate a bound service account token for use in the image pull secret.
Goals (aka. expected user outcomes)
Use TokenRequest API to create image pull secrets.
{}Performance benefits:
One less secret created per service account. This will result in at least three less secrets generated per namespace.
Security benefits:
Long lived tokens which are no longer recommended as they present a possible security risk.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
The upstream test `ServiceAccounts no secret-based service account token should be auto-generated` was previously patched to allow for the internal image registry's managed image pull secret to be present in the `Secrets` field. This will not longer be the case as of 4.16.
Post merge of API-1644, we can remove the patch entirely.
*Executive Summary *
Provide mechanisms for the builder service account to be made optional in core OpenShift.
Goals
< Who benefits from this feature, and how? What is the difference between today’s current state and a world with this feature? >
- Let cluster administrators disable the automatic creation of the "builder" service account when the Build capability is disabled on the cluster. This reduces potential attack vectors for clusters that do not run build or other CI/CD workloads. Example - fleets for mission-critical applications, edge deployments, security-sensitive environments.
- Let cluster administrators enable/disable the generation of the "builder" service account at will. Applies to new installations with the "Build" capability enabled as well as upgraded clusters. This helps customers who are not able to easily provision new OpenShift clusters and block usage of the Build system through other means (ex: RBAC, 3rd party admission controllers (ex OPA, Kyverno)).
Requirements
| Requirements | Notes | IS MVP |
| Disable service account controller related to Build/BuildConfig when Build capability is disabled | When the API is marked as removed or disabled, stop creating the "builder" service account and its associated RBAC | Yes |
| Option to disable the "builder" service account | Even if the Build capability is enabled, allow admins to disable the "builder" service account generation. Admins will need to bring their own service accounts/RBAC for builds to work | Yes |
(Optional) Use Cases
< What are we making, for who, and why/what problem are we solving?>
- Build as an installation capability - see
WRKLDS-695 - Disabling the Build system through RBAC or admission controllers. The "builder" service account is the only thing that RBAC and admission control cannot block without significant cluster impact.
Out of scope
<Defines what is not included in this story>
- Disabling the Build API separately from the capabilities feature
Dependencies
< Link or at least explain any known dependencies. >
- Build capability:
WRKLDS-695 - Separate controllers for default service accounts: API-1651
Background, and strategic fit
< What does the person writing code, testing, documenting need to know? >
- In OCP 4.14, "Build" was introduced as an optional installation capability. This means that the BuildConfig API and subsystems are not guaranteed to be present on new clusters.
- The "builder" service account is granted permission to push images to the OpenShift internal registry via a controller. There is risk that the service account can be used as an attack vector to overwrite images in the internal registry.
- OpenShift has an existing API to configure the build system. See OCP documentation on the current supported options. The current OCP build test suite includes checks for these global settings. Source code.
- Customers with larger footprints typically separate "CI/CD clusters" from "application clusters" that run production workloads. This is because CI/CD workloads (and building container images in particular) can have "noisy" consumption of resources that risk destabilizing running applications.
Assumptions
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Customer Considerations
< Are there specific customer environments that need to be considered (such as working with existing h/w and software)?>
- Must work for new installations as well as upgraded clusters.
Documentation Considerations
< What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)? >
- Update the "Build configurations" doc so admins can understand the new feature.
- Potential updates to "Understanding BuildConfig" doc doc to include references to the serviceAccount option in the spec, as well as a section describing the permissions granted to the "builder" service account.
What does success look like?
< Does this feature have doc impact? Possible values are: New Content, Updates to existing content, Release Note, or No Doc Impact?>
QE Contact
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Impact
< If the feature is ordered with other work, state the impact of this feature on the other work>
Related Architecture/Technical Documents
- Disabling OCM Controllers (slides). Note that the controller names may be a bit out of date once API-1651 is done.
- Install capabilities - OCP docs
Done Checklist
- Acceptance criteria are met
- Non-functional properties of the Feature have been validated (such as performance, resource, UX, security or privacy aspects)
- User Journey automation is delivered
- Support and SRE teams are provided with enough skills to support the feature in production environment
Story (Required)
As a cluster admin trying to disable the Build, DeploymentConfig, and Image Registry capabilities I want the RBAC controllers for the builder and deployer service accounts and default image-registry rolebindings disabled when their respective capability is disabled.
<Describes high level purpose and goal for this story. Answers the questions: Who is impacted, what is it and why do we need it? How does it improve the customer's experience?>
Background (Required)
<Describes the context or background related to this story>
In WRKLDS-695, ocm-o was enhanced to disable the Build and DeploymentConfig controllers when the respective capability was disabled. This logic should be extended to include the controllers that set up the service accounts and role bindings for these respective features.
Out of scope
<Defines what is not included in this story>
Approach (Required)
<Description of the general technical path on how to achieve the goal of the story. Include details like json schema, class definitions>
- Ensure that all the controllers (builder, deployer, image-puller rolebinding controllers) are specified in the api/*/types.go as well as in controllerInitializers, so that the controller is initiated when capability is enabled.
- Map the controllers introduced with
BUILD-725to respective capabilities in ocm-operator.- This helps to avoid running controllers when capabilities are disabled.
- The relevant clusterVersionCapability is available here
- The OpenShift CI has no check for cluster deployment with capabilities disabled. Looked through https://github.com/openshift/release/tree/master/ci-operator/step-registry/ipi/conf/capability
-
- Needs manual testing (OpenShift cluster deployed with all/some capabilities disabled).
Dependencies
<Describes what this story depends on. Dependent Stories and EPICs should be linked to the story.>
Acceptance Criteria (Mandatory)
- Build and DeploymentConfig systems remain functional when the respective capability is enabled.
- Build, DeploymentConfig, and Image-Puller RoleBinding controllers are not started when the respective capability is disabled.
INVEST Checklist
Dependencies identified
Blockers noted and expected delivery timelines set
Design is implementable
Acceptance criteria agreed upon
Story estimated
- Engineering: 5
- QE: 2
- Doc: 2
Legend
Unknown
Verified
Unsatisfied
Done Checklist
- Code is completed, reviewed, documented and checked in
- Unit and integration test automation have been delivered and running cleanly in continuous integration/staging/canary environment
- Continuous Delivery pipeline(s) is able to proceed with new code included
- Customer facing documentation, API docs etc. are produced/updated, reviewed and published
- Acceptance criteria are met
Story (Required)
As an OpenShift engineer trying to use capabilities to enable/disable the Build and DeploymentConfig systems, I want to refactor the default rolebindings controller so that each respective capability runs a separate controller.
<Describes high level purpose and goal for this story. Answers the questions: Who is impacted, what is it and why do we need it? How does it improve the customer’s experience?>
Background (Required)
<Describes the context or background related to this story>
OpenShift has a controller that automatically creates role-bindings for service accounts in every namespace. Though only one controller operates, its logic contains forks that are specific to the Build and DepoymentConfig systems.
The goal is to refactor this into separate controllers so that individual ones can be disabled by the cluster-openshift-controller-manager-operator.
Out of scope
<Defines what is not included in this story>
- Disabling the rolebindings controller via an operator.
- Cleaning up rolebindings that are "orphaned" if the controller is disabled.
Approach (Required)
<Description of the general technical path on how to achieve the goal of the story. Include details like json schema, class definitions>
Dependencies
<Describes what this story depends on. Dependent Stories and EPICs should be linked to the story.>
- API-1651 - this was refactoring work taken on by the apiserver/auth team.
Acceptance Criteria (Mandatory)
<Describe edge cases to consider when implementing the story and defining tests>
<Provides a required and minimum list of acceptance tests for this story. More is expected as the engineer implements this story>
- Separate rolebinding controllers exist for the builder and deployer service account rolebindings.
- Build and DeploymentConfig systems remain functional when the respective capability is enabled.
- The "image puller" role binding must continue to be created/reconciled.
INVEST Checklist
![]() Dependencies identified
Dependencies identified
![]() Blockers noted and expected delivery timelines set
Blockers noted and expected delivery timelines set
![]() Design is implementable
Design is implementable
![]() Acceptance criteria agreed upon
Acceptance criteria agreed upon
![]() Story estimated
Story estimated
- Eng: 3
Legend
![]() Unknown
Unknown
![]() Verified
Verified
![]() Unsatisfied
Unsatisfied
Done Checklist
- Code is completed, reviewed, documented and checked in
- Unit and integration test automation have been delivered and running cleanly in continuous integration/staging/canary environment
- Continuous Delivery pipeline(s) is able to proceed with new code included
- Customer facing documentation, API docs etc. are produced/updated, reviewed and published
- Acceptance criteria are met
Problem statement
A 5G Core cluster communicates with many other clusters and remote hosts, aka remote sites. And these remote are added, and sometime removed temporarily or definitively from the telecom operator network. As of today, we need to add static routes on OCP nodes to be able to reach those remote sites, and updating static routes for each and every remote site change is unacceptable for Telco Operators, in particular as they do not have to configure static routes anywhere in their network as they rely on BGP to propage routes across their network. They do want OCP nodes to learn those BGP routes rather than to create a "script" that will translate BGP announces into an NMSTATE configuration to be pushed on OCP nodes.

More insights in (recording link on the title page) https://docs.google.com/presentation/d/1zW0-wmvtrU7dbApIaNWfvMbSZvLxoSMLa_gzRYn0Y3Y/edit#slide=id.gfb215b3717_0_3299
Vocabulary, definition
VRF: in this feature, a VRF is a Network VRF, not a Linux kernel VRF. A Network VRF is often implemented as a VLAN in a datacenter, but this is a pure logical entity on the routers/DCGW and are not visible on the OCP nodes. Please do not be confused with another Feature that relies on Linux VRFs to map the Network VRFs on OCP nodes (https://issues.redhat.com/browse/TELCOSTRAT-76).
More insights in (recording link on the title page) https://docs.google.com/presentation/d/1zW0-wmvtrU7dbApIaNWfvMbSZvLxoSMLa_gzRYn0Y3Y/edit#slide=id.gfb215b3717_0_3299
e description, scope
Any Kubernetes object/component learning/announcing routes, including pods, is not in this feature scope. This feature is about OCP nodes (==Linux host) to learn routes via BGP, and to eventually monitor their next hop with BFD (datacenter router, DCGW, fabric leaf, ...).
Routes next hop can be on any OCP node interface (any VLAN, bond, physical NIC): next hop are not necessarily reachable from the baremetal network. This means that we will have one BGP Peer per VRF.
We want to be able to learn routes with the same weight/local-preference, translating to ECMP routes on the OCP nodes, and also routes with different weight/local-preference, translating to active/backup routes on OCP nodes. In all cases, we want to be able to monitor the routes via BFD as BGP timeouts are too high for some customers.
Illustration for active/backup - note that there can be more than two routers

Illustration for active/active (ECMP) - note that there can be more than two routers

Routing protocol scope
This feature is limited to BGP and BFP, and must support IPv4, IPv6, and the commonly used BGP attributes, typically the ones supported by metalLB: https://docs.openshift.com/container-platform/4.12/networking/metallb/metallb-configure-bgp-peers.html#nw-metallb-bgppeer-cr_configure-metallb-bgp-peers
The OCP nodes will learn routes but will not announce routes, except the metalLB ones.
Scale requirements
Expectation is to have 3 VRFs and two routers per VRF. We should scale beyond, in particular for the number of VRFs, but the number of routers per VRF should be 4 at a maximum as best and sane practices are 2 and we do not want to encourage faulty/wrong network designs. Of course, we can amend this Feature scope for future evolution if best practices evolves.
Interoperability requirements
FRR is interoperable with all/most existing routers, and as Red Hat is upstream based, interoperability tests are not required but any interoperability issue will be fixed (upstream first, like for any code change at Red Hat).
Assumption
This feature is only relevant for local gateway mode (not shared gateway).
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Have FRR-K8s as another BGP backend for MetalLB
- Have the MetalLB Operator deploy both MetalLB and the FRR-K8s daemon
- Having the users configure the frr instance running on each node beyond the capabilities offered by metallb
Why is this important?
- There are a few telco users that want to accept routes on the nodes
- MetalLB's purpouse is to advertise routes.
- There are a lot of reasons why having a single frr instance per node is better than having one inside metallb and one external (see https://docs.google.com/document/d/1vH4OmjNPgB-HG9mz7-O2l-Zqs4_fATNm3h4OXQTyvxw/edit )
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
Telecommunications providers look to displace Physical Network Functions (PNFs) with modern Virtual Network Functions (VNFs) at the Far Edge. Single Node OpenShift, as a the CaaS layer in the vRAN vDU architecture, must achieve a higher standard in regards to OpenShift upgrade speed and efficiency, as in comparison to PNFs.
Telecommunications providers currently deploy Firmware-based Physical Network Functions (PNFs) in their RAN solutions. These PNFs can be upgraded quickly due to their monolithic nature and image-based download-and-reboot upgrades. Furthermore they often have the ability to retry upgrades and to rollback to the previous image if the new image fails. These Telcos are looking to displace PNFs with virtual solutions, but will not do so unless the virtual solutions have comparable operational KPIs to the PNFs.
Goals
Service Downtime
Service (vDU) Downtime is the time when the CNF is not operational and therefore no traffic is passing through the vDU. This has a significant impact as it degrades the customer’s service (5G->4G) or there’s an outright service outage. These disruptions are scheduled into Maintenance Windows (MW), but the Telecommunications Operators primary goal is to keep service running, so getting vRAN solutions with OpenShift to near PNF-like Service Downtime is and always will be a primary requirement.
Upgrade Duration
Upgrading OpenShift is only one of many operations that occur during a Maintenance Window. Reducing the CaaS upgrade duration is meaningful to many teams within a Telecommunications Operators organization as this duration fits into a larger set of activities that put pressure on the duration time for Red Hat software. OpenShift must reduce the upgrade duration time significantly to compete with existing PNF solutions.
Failure Detection and Remediation
As mentioned above, the Service Downtime disruption duration must be as small as possible, this includes when there are failures. Hardware failures fall into a category called Break+Fix and are covered by TELCOSTRAT-165. In the case of software failures must be detected and remediation must occur.
Detection includes monitoring the upgrade for stalls and failures and remediation would require the ability to rollback to the previously well-known-working version, prior to the failed upgrade.
Implicit Requirements
Upgrade To Any Release
The OpenShift product support terms are too short for Telco use cases, in particular vRAN deployments. The risk of Service Downtime drives Telecommunications Operators to a certify-deploy-and-then-don’t-touch model. One specific request from our largest Telco Edge customer is for 4 years of support.
These longer support needs drive a misalignment with the EUS->EUS upgrade path and drive the requirement that the Single Node OpenShift deployment can be upgraded from OCP X.y.z to any future [X+1].[y+1].[z+1] where X+1 and x+1 are decided by the Telecommunications Operator depending on timing and the desired feature-set and x+1 is determined through Red Hat, vDU vendor and custom maintenance and engineering validation.
Alignment with Related Break+Fix and Installation Requirements
Red Hat is challenged with improving multiple OpenShift Operational KPIs by our telecommunications partners and customers. Improved Break+Fix is tracked in TELCOSTRAT-165 and improved Installation is tracked in TELCOSTRAT-38.
Seamless Management within RHACM
Whatever methodology achieves the above requirements must ensure that the customer has a pleasant experience via RHACM and Red Hat GitOps. Red Hat’s current install and upgrade methodology is via RHACM and any new technologies used to improve Operational KPIs must retain the seamless experience from the cluster management solution. For example, after a cluster is upgraded it must look the same to a RHACM Operator.
Seamless Management when On-Node Troubleshooting
Whatever methodology achieves the above requirements must ensure that a technician troubleshooting a Single Node OpenShift deployment has a pleasant experience. All commands issued on the node must return output as it would before performing an upgrade.
Requirements
Y-Stream
- CaaS Upgrade must complete in <2 hrs (single MW) (20 mins for PNF)
- Minimize service disruption (customer impact) < 30 mins [cumulative] (5 mins for PNF)
- Support In-Place Upgrade without vDU redeployment
- Support backup/restore and rollback to known working state in case of unexpected upgrade failures
Z-Stream
- CaaS Patch Release (z-release) Upgrade Requirements:
- CaaS Upgrade must complete <15 mins
- Minimize service disruption (customer impact) < 5 mins
- Support In-Place Upgrade without vDU redeployment
- Support backup/restore and rollback to known working state in case
Rollback
- Restore and Rollback functionality must complete in 30 minutes or less.
Upgrade Path
- Allow for upgrades to any future supported OCP release.
References
Run tuneD on a container on a one-shot mode and read the output kernel arguments to apply them using a MachineConfig (MC).
This would be run in the bootstrap procedure of the Openshift Installer, just before the MachineConfigOperator(MCO) procedure here
Initial considerations: https://docs.google.com/document/d/1zUpcpFUp4D5IM4GbM4uWbzbjr57h44dS0i4zP-hek2E/edit
Webhooks created during bootstrap-in-place will lead to failure in applying their admission subject resources. A permanent solution will be provided by resolving https://issues.redhat.com/browse/OCPBUGS-28550
We need a temporary workaround to unblock the development. This is easiest to do by changing the validating webhook failure policy to "Ignore"
Feature goal (what are we trying to solve here?)
A systemd service that runs on a golden image first boot and configure the following:
1. networking ( the internal IP address require special attention)
2. Update the hostname (MGMT-15775)
3. Execute recert (regenereate certs, Cluster name and base domain MGMT-15533)
4. Start kubelet
5. Apply the personalization info:
- Pull Secret
- Proxy
- ICSP
- DNS server
- SSH keys
DoD (Definition of Done)
- The API for configuring the networking, hostname, personalization manifests and executing recert is well defined
- The service configures the required attributes and start a functional OCP cluster
- CI job that reconfigures a golden image and form a functional cluster
Does it need documentation support?
If the answer is "yes", please make sure to check the corresponding option.
Feature origin (who asked for this feature?)
-
-
- This is required as part of https://issues.redhat.com/browse/OCPSTRAT-620
- This is required as part of https://issues.redhat.com/browse/OCPSTRAT-620
-
The following features depend on this functionality:
Competitor analysis reference
- Do our competitors have this feature?
- Yes, they have it and we can have some reference
- No, it's unique or explicit to our product
- No idea. Need to check
Feature usage (do we have numbers/data?)
- We have no data - the feature doesn’t exist anywhere
- Related data - the feature doesn’t exist but we have info about the usage of associated features that can help us
- Please list all related data usage information
- We have the numbers and can relate to them
- Please list all related data usage information
Feature availability (why should/shouldn't it live inside the UI/API?)
- Please describe the reasoning behind why it should/shouldn't live inside the UI/API
- If it's for a specific customer we should consider using AMS
- Does this feature exist in the UI of other installers?
In IBI and IBU flows we need a way to change nodeip-configuration hint file without reboot and before mco even starts. In order for MCO to be happy we need to remove this file from it's management to make it we will stop using machine config and move to ignition
Currently the behavior is to only use the default security group if no security groups were specified for a NodePool. This makes it difficult to implement additional security groups in ROSA because there is no way to know the default security group on cluster creation. By always appending the default security group, any security groups specified on the NodePool become additional security groups.
User Story
As a ROSA HyperShift customer I want to enforce that IMDSv2 is always the default, to ensure that I have the most secure setting by default.
Acceptance Criteria
- IMDSv2 should be configured in HyperShift clusters by default
Default Done Criteria
- All existing/affected SOPs have been updated.
- New SOPs have been written.
- Internal training has been developed and delivered.
- The feature has both unit and end to end tests passing in all test
pipelines and through upgrades. - If the feature requires QE involvement, QE has signed off.
- The feature exposes metrics necessary to manage it (VALET/RED).
- The feature has had a security review.* Contract impact assessment.
- Service Definition is updated if needed.* Documentation is complete.
- Product Manager signed off on staging/beta implementation.
Dates
Integration Testing:
Beta:
GA:
Current Status
GREEN | YELLOW | RED
GREEN = On track, minimal risk to target date.
YELLOW = Moderate risk to target date.
RED = High risk to target date, or blocked and need to highlight potential
risk to stakeholders.
References
Links to Gdocs, github, and any other relevant information about this epic.