Complete Epics
This section includes Jira cards that are linked to an Epic, but the Epic itself is not linked to any Feature. These epics were completed when this image was assembled
Epic Goal
- Improve CI testing of the image registry components.
Why is this important?
- The image registry, image API and the image pruner had a lot of tests removed during transition 4.0. This may make the platform less stable and/or slow down the team.
Scenarios
- ...
Acceptance Criteria
- CI - tests should be more stable and have broader coverage
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
In the image-registry, we have packages origin-common and kubernetes-common. The problem is that this code doesn't get updates. We can replace them with more supported library-go.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- ...
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
The console requires to know the network type capabilities to show/hide some Network Policy form fields.
As a result of https://issues.redhat.com/browse/NETOBSERV-27, this logic is implemented as a features document inside the console code. The console fetches the network type from the network operator and checks the supported features towards this document.
However, this limits the feature to admin users, as other logged-in users do not have permissions to fetch the network type.
This task aims to modify the current Cluster Network Operator to expose the network capabilities as an `sdn-public` Config Map, writeable only by the SDN, readable by any `system:authenticated` user.
Enhancement Proposal PR: https://github.com/openshift/enhancements/pull/875
We want to configure 'default' and 'allowed' values in validation webhook for Guest Accelerators field in GCPProviderSpec. Also revendor it to include newly added Guest Accelerators field.
This can be done after https://github.com/openshift/cluster-api-provider-gcp/pull/172 is merged.
DoD:
- Make sure that validations return errors on issues with GPU configuration
- Ensure the unit tests for the webhooks are updated
T-shirt size: M
Goal:
Provide an easy and successful experience for front end developers to build and deploy their applications
Why is it important?
Currently, the front end dev experience is not positive. It's much easier for them to use other platforms. Improving the front end dev experience will enable us to gain more marketshare
Use cases:
- Need to be able to override the npm command when using Node Builder Image
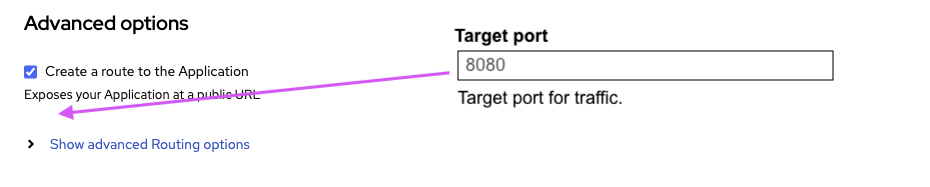
- Need to expose target port
- Need access to the URL to access my application
Although we provide the ability for 2 & 3 today, the current journey does not match with the mental model of the front end developer
Acceptance criteria:
- When importing an app, I should be able to easily provide the npm build and run commands
- When opting in to create a route, the target port should be exposed without having to open any Advanced Options
- After importing my app, if a route is exposed, I should be able to access/copy that URL
Dependencies (External/Internal):
Design Artifacts:
Desired UX experience
- enable user to provide the *Build Command* when Node Builder image is being used
- enable user to provide the *Run Command* when Node Builder image is being used
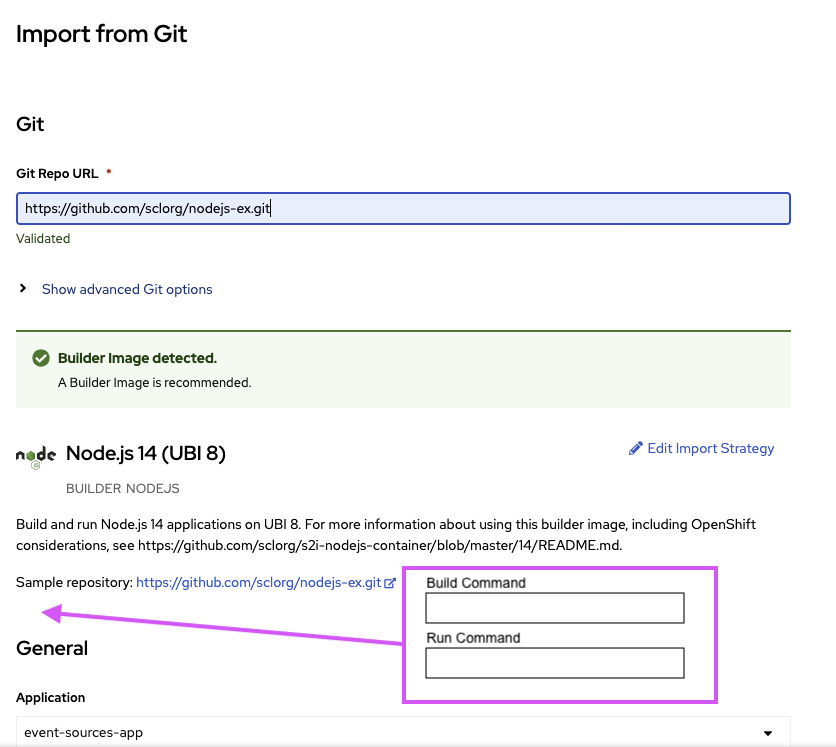
- expose the Target Port under the *Create a route to the Application *rather than inside Show advanced Routing options
- NEED TO FINALIZE HOW TO PROVIDE THE ROUTE TO EASILY COPY – Inline Notification maybe? As well as side panel?
Note:
Description
As a user, I want have the option to add additional labels to a Route, as I could do in OCP3. See RFE-622
The additional labels should only be added to the route, not the service or other components. The advanced option "Labels" should not be touched and these labels are added to all components.
As an small additional we should also show always the "Target port" since it also defines the Service port and to make this more clear, the "Target port" should be shown before the "Create a route to the Application" checkbox.
Acceptance Criteria
The following changes should be applied to the Import flow (from Git, from Container, ...) and to the Edit page as well:
- Move the option "Target port" before the checkbox "Create a route to the Application" and do not hide the "Target port" when the checkbox is disabled
- Add a new "Additional route labels" option, with a label input field to the "Advanced Routing options"
- Save (Import) and update (Edit) the labels to the Route resource. When editing a Deployment with a Route the route labels should not show the shared labels.