Incomplete Features
When this image was assembled, these features were not yet completed. Therefore, only the Jira Cards included here are part of this release
Epic Goal
- Enable Image Registry to use Azure Blob Storage from AzureStackCloud
Why is this important?
- While certifying Azure Stack Hub as OCP provider we need to ensure all the required components for UPI/IPI deployments are ready to be used
Scenarios
- Create an OCP cluster is Azure Stack Hub and use Internal Registry with Azure Blob Storage from AzureStackCloud
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Story: As an OpenShift admin I want the internal registry of the cluster use storage from Azure Stack Hub so that I can run a fully supported OpenShift environment on that infrastructure provider.
As a cluster administrator,
I want OpenShift to include a recent CoreDNS version,
so that I have the latest available performance and security fixes.
We should strive to follow upstream CoreDNS releases by bumping openshift/coredns with every OpenShift 4.y release, so that OpenShift benefits from upstream performance and security fixes, and so that we avoid large version-number jumps when an urgently needed change necessitates bumping CoreDNS to the latest upstream release. This bump should happen as early as possible in the OpenShift release cycle, so as to maximize soak time.
For OpenShift 4.9, this means bumping from CoreDNS 1.8.1 to 1.8.3, or possibly a later release should one ship before we do the bump.
Note that CoreDNS upstream does not maintain release branches—that is, once CoreDNS is released, there will be no further 1.8.z releases—so we may be better off updating to 1.9 as soon as it is released, rather than staying on the 1.8 series which would then be unmaintained.
We may consider bumping CoreDNS again during the OpenShift 4.9 release cycle if upstream ships additional releases during the 4.9 development cycle. However, we will need to weigh the risks and available remaining soak time in the release schedule before doing so, should that contingency arise.
Feature Overview
We drive OpenShift cross-market customer success and new customer adoption with constant improvements and feature additions to the existing capabilities of our OpenShift Core Networking (SDN and Network Edge). This feature captures that natural progression of the product.
Goals
- Feature enhancements (performance, scale, configuration, UX, ...)
- Modernization (incorporation and productization of new technologies)
Requirements
- Core Networking Stability
- Core Networking Performance and Scale
- Core Neworking Extensibility (Multus CNIs)
- Core Networking UX (Observability)
- Core Networking Security and Compliance
In Scope
- Network Edge (ingress, DNS, LB)
- SDN (CNI plugins, openshift-sdn, OVN, network policy, egressIP, egress Router, ...)
- Networking Observability
Out of Scope
There are definitely grey areas, but in general:
- CNV
- Service Mesh
- CNF
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Feature Overview
Plugin teams need a mechanism to extend the OCP console that is decoupled enough so they can deliver at the cadence of their projects and not be forced in to the OCP Console release timelines.
The OCP Console Dynamic Plugin Framework will enable all our plugin teams to do the following:
- Extend the Console
- Deliver UI code with their Operator
- Work in their own git Repo
- Deliver at their own cadence
Goals
-
- Operators can deliver console plugins separate from the console image and update plugins when the operator updates.
- The dynamic plugin API is similar to the static plugin API to ease migration.
- Plugins can use shared console components such as list and details page components.
- Shared components from core will be part of a well-defined plugin API.
- Plugins can use Patternfly 4 components.
- Cluster admins control what plugins are enabled.
- Misbehaving plugins should not break console.
- Existing static plugins are not affected and will continue to work as expected.
Out of Scope
-
- Initially we don't plan to make this a public API. The target use is for Red Hat operators. We might reevaluate later when dynamic plugins are more mature.
- We can't avoid breaking changes in console dependencies such as Patternfly even if we don't break the console plugin API itself. We'll need a way for plugins to declare compatibility.
- Plugins won't be sandboxed. They will have full JavaScript access to the DOM and network. Plugins won't be enabled by default, however. A cluster admin will need to enable the plugin.
- This proposal does not cover allowing plugins to contribute backend console endpoints.
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| UI to enable and disable plugins | YES | |
| Dynamic Plugin Framework in place | YES | |
| Testing Infra up and running | YES | |
| Docs and read me for creating and testing Plugins | YES | |
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
We need to support localization of dynamic plugins. The current proposal is to have one i18n namespace per dynamic plugin with a fixed name: `${plugin-name}-plugin`. Since console will know the list of plugins on startup, it can add these namespaces to the i18next config.
The console backend will need to implement an endpoint at the i18next load path. The endpoint will see if the namespace matches the known plugin namespaces. If so, it will proxy to the plugin. Otherwise it will serve the static file from the local filesystem.
The dynamic plugins enhancement describes a `disable-plugins` query parameter for disabling specific console plugins.
- ?disable-plugins or ?disable-plugins= prevents loading of any dynamic plugins (disable all)
- ?disable-plugins=foo,bar prevents loading of dynamic plugins named foo or bar (disable selectively)
This has no effect on static plugins, which are built into the Console application.
We need a UI for enabling and disabling dynamic plugins. The plugins will be discovered either through a custom resource or an annotation on the operator CSV. The enabled plugins will be persisted through the operator config (consoles.operator.openshift.io).
This story tracks enabling and disabling the plugin during operator install through Cluster Settings. This is needed in the future if a plugin is installed outside of an OLM operator.
UX design: https://github.com/openshift/openshift-origin-design/pull/536
Feature Overview
- This Section:* High-Level description of the feature ie: Executive Summary
- Note: A Feature is a capability or a well defined set of functionality that delivers business value. Features can include additions or changes to existing functionality. Features can easily span multiple teams, and multiple releases.
Goals
- This Section:* Provide high-level goal statement, providing user context and expected user outcome(s) for this feature
- …
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
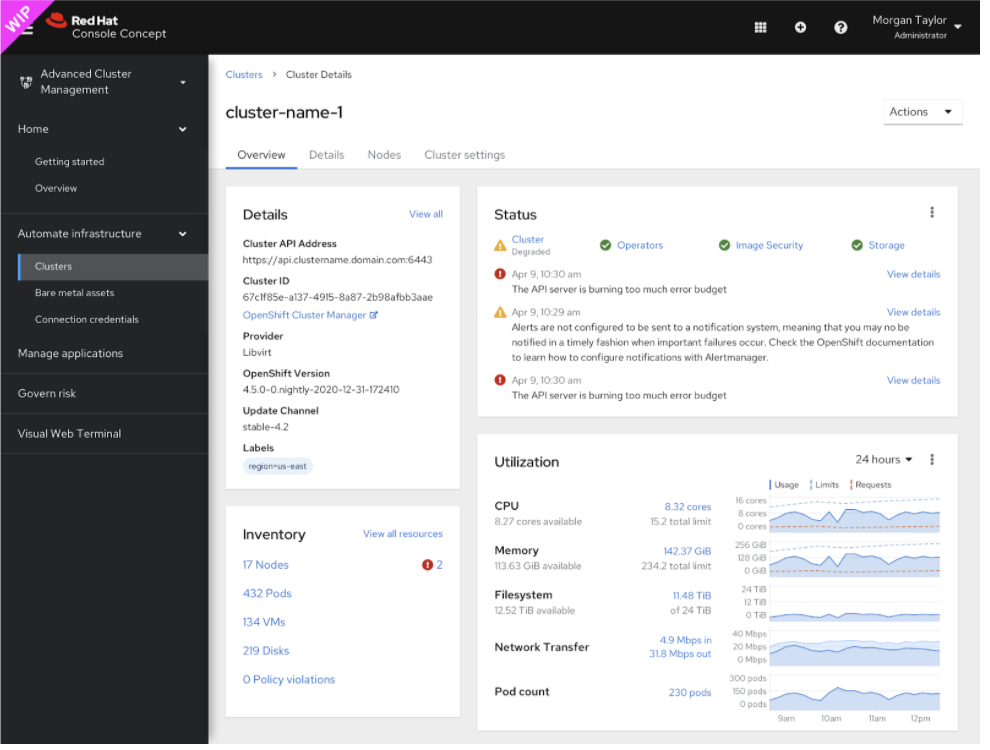
Goal
By default the Cluster Utilization card should not include metrics from `master` nodes in its queries for CPU, Memory, Filesystem, Network, and Pod count.
A new filter option should allow users to toggle between a combined view of what is seen on the Cluster Utilization card today, which is mostly useful on small clusters where masters are schedulable for user workloads.
Assets
- Marvel with two scenarios:
- Windows nodes exist
- Windows nodes do not exist
Background
As discussed in this thread, the`kube_node_role` metric available since 4.3 should allow us to filter the card's PromQL queries to not include master node metrics.
This filtered view would likely make the card's data more useful for users who aren't running their workloads on masters, like OpenShift Dedicated users.
As noted by some folks during design discussions, this filter isn't perfect, and wouldn't filter out the data from "Infra" nodes that users may have set up using labels/taints. Until we determine a good way to provide more advanced filtering, this basic "Include masters" checkbox is still more flexible than what the card offers today.
Requirements
- When windows nodes exist in the cluster:
- Node type filter will be added to the Cluster Utilization card that lists all node types available
- It will be pre-filtered to only show Worker nodes
- The filter will be single select and will display the selected item in the toggle.
- When windows nodes do not exist in the cluster:
- Node type filter will be added to the Cluster Utilization card that lists node types available, plus an "all types" item.
- It will be pre-filtered to only show Worker nodes
- The filter will be multi-select
- The badge in the toggle will update as more items are selected
- If the "all nodes" is selected, the other items will automatically become deselected, and the badge will update to "All".
As a admin, I want to be able to access the node logs from the nodes detail page in order to troubleshoot what is going on with the node.
We should support getting node logs for different units for node journal logs and evaluate the other CLI flags.
We currently have a gap with the CLI:
- oc adm node-logs [-l LABELS] [NODE...] [flags]
We need to investigate whether the k8s API supports WebSockets for streaming node logs.
Goal
Currently we are showing system projects within the list view of the Projects page. As stated here https://issues.redhat.com/browse/RFE-185, there are many projects that are considered as system projects that are not important to the user. The value should be remember across sessions, but it something we should be able to toggle directly from the list.
Design assets
Requirements
- The user should be able to hide/show system projects within the project list page (and namespace list page)
- The user should be able to hide/show system projects from the project selector
- The same capability should work from the project list page in the developer perspective
In OpenShift, reserved namespaces are `default`, `openshift`, and those that start with `openshift-`, `kubernetes-`, or `kube-`.
Edge case scenarios
- If the user filters out system projects from the projects or namespaces list view, then filters and there are no results, an empty state will be surfaced with ability to clear filters. (see design assets)
- If the user has hidden system projects from the project selector and has favorited or defaulted system projects in the project selector, those favorited or defaulted system projects will NOT appear in the project selector list. (see design assets)
- If the user has hidden system projects from the project selector, then navigates to some resource page where a system project is selected, the system project name will still appear in the project selector toggle but not within the list of projects in the selector. (see design assets)
Feature Overview
OpenShift console supports new features and elevated experience for Operator Lifecycle Manager (OLM) Operators and Cluster Operators.
Goal:
OCP Console improves the controls and visibility for managing vendor-provided software in customers’ infrastructure and making these solutions available for customers' internal users.
To achieve this,
- Operator Lifecycle Manager (OLM) teams have been introducing new features aiming towards simplification and ease of use for both developers and cluster admins.
- On the Cluster Operators side, the console iteratively improves the visibilities to the resources being associated with the Operators to improve the overall managing experience.
We want to make sure OLM’s and Cluster Operators' new features are exposed in the console so admin console users can benefit from them.
Benefits:
- Cluster admin/Operator consumers:
- Able to see, learn, and interact with OLM managed and/or Cluster Operators associated resources in openShift console.
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| OCP console supports the latest OLM APIs and features | This is a requirement for ALL features. | YES |
| OCP console improves visibility to Cluster Operators related resources and features. | This is a requirement for ALL features. | YES |
(Optional) Use Cases
<--- Remove this text when creating a Feature in Jira, only for reference --->
* Main success scenarios - high-level user stories
* Alternate flow/scenarios - high-level user stories
* ...
Questions to answer...
How will the user interact with this feature?
Which users will use this and when will they use it?
Is this feature used as part of the current user interface?
Out of Scope
<--- Remove this text when creating a Feature in Jira, only for reference --->
# List of non-requirements or things not included in this feature
# ...
Background, and strategic fit
<--- Remove this text when creating a Feature in Jira, only for reference --->
What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
<--- Remove this text when creating a Feature in Jira, only for reference --->
* Are there assumptions being made regarding prerequisites and dependencies?
* Are there assumptions about hardware, software or people resources?
* ...
Customer Considerations
<--- Remove this text when creating a Feature in Jira, only for reference --->
* Are there specific customer environments that need to be considered (such as working with existing h/w and software)?
...
Documentation Considerations
<--- Remove this text when creating a Feature in Jira, only for reference --->
Questions to be addressed:
* What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
* Does this feature have doc impact?
* New Content, Updates to existing content, Release Note, or No Doc Impact
* If unsure and no Technical Writer is available, please contact Content Strategy.
* What concepts do customers need to understand to be successful in [action]?
* How do we expect customers will use the feature? For what purpose(s)?
* What reference material might a customer want/need to complete [action]?
* Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
* What is the doc impact (New Content, Updates to existing content, or Release Note)?
Epic Goal
- OCP console supports devs to easier focus and create Operand/CR instances on the creation form page.
- OCP console supports cluster admins to better see/understand the Operator installation status in the OperatorHub page.
Why is this important?
- OperatorHub page currently shows an Operator as Installed as long as a Subscription object exists for that operator in the current namespace, which can be misleading because the installation could be stalled or require additional interactions from the user (e.g. "manual upgrade approval") in order to complete the installation.
- Some Operator managed services use these advanced properties in their CRD validation schema, but the current form generator in the console ignores/skips them. Hence, those fields on the creation form are missing.
Scenarios
- As a user of OperatorHub, I'd like to have an improved "status display" for Operators being installed before so I can better understand if those Operators actually being successfully installed or require additional actions from me to complete the installation.
- As a user of the OCP console, I'd like to Operand/CR creation form that covers advanced JSONSchema validation properties so I can create a CR instance solely with the form view.
Acceptance Criteria
- Console improves the visibility of Operator installation status on OperatorHub page
- Console operand creation form adds support for `allOf`, `anyOf`, `oneOf`, and `additionalProperties` JSONSchema validation keywords so the creation form UI can render them and not skipping those properties/fields.
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Options
User Story
As a user of OperatorHub, I'd like to have an improved "status display" for Operators being installed before so I can better understand if those Operators actually being successfully installed or require additional actions from me to complete the installation.
Desired Outcome
Improve visibility of Operator installation status on OperatorHub page
Why this is important?
OperatorHub page currently shows an Operator as Installed as long as a Subscription object exists for that operator in the current namespace.
This can be misleading because the installation could be stalled or require additional interactions from the user (e.g. "manual upgrade approval") in order to complete the installation.
The console could potentially have some indication of an "in-between" or "requires attention" state for Operators that are in these states + links to the actual "Installed Operators" page for more details.
Related Info:
1. BZ: https://bugzilla.redhat.com/show_bug.cgi?id=1899359
2. RFE: https://issues.redhat.com/browse/RFE-1691
OLM is adding a property to the CSV to signal that the operator should clean up the operand on operator uninstall. See https://github.com/operator-framework/enhancements/pull/46
Console will need to add a checkbox to the UI to prompt ask the user if the operand should be cleaned up (with strong warnings about what this means). On delete, console should set the `spec.cleanup` property on the CSV to indicate whether cleanup should happen.
Additionally, console needs to be able to show proper status for CSVs that are terminating in the UI so it's clear the operator is being deleted and cleanup is in progress. If there are errors with cleanup, those should be surfaced back through the UI.
Depends on OLM-1733
Current version is 2.5.1, and we are still on 1.x. Updating the package is required to support the additional validation keywords in CONSOLE-2807.
https://github.com/rjsf-team/react-jsonschema-form/releases
Breaking changes are listed in the v2 notes:
https://github.com/rjsf-team/react-jsonschema-form/releases/tag/v2.0.0
Key Objective
Providing our customers with a single simplified User Experience(Hybrid Cloud Console)that is extensible, can run locally or in the cloud, and is capable of managing the fleet to deep diving into a single cluster.
Why customers want this?
- Single interface to accomplish their tasks
- Consistent UX and patterns
- Easily accessible: One URL, one set of credentials
Why we want this?
- Shared code - improve the velocity of both teams and most importantly ensure consistency of the experience at the code level
- Pre-built PF4 components
- Accessibility & i18n
- Remove barriers for enabling ACM
Phase 1 Goal: Get something to market (OCP 4.8, ACM 2.3)
Phase 1 —> OCP deploys ACM Hub Operator —> ACM Perspective becomes available —> User can switch between ACM multi-cluster view and local OCP Console —> No SSO user has to login in twice
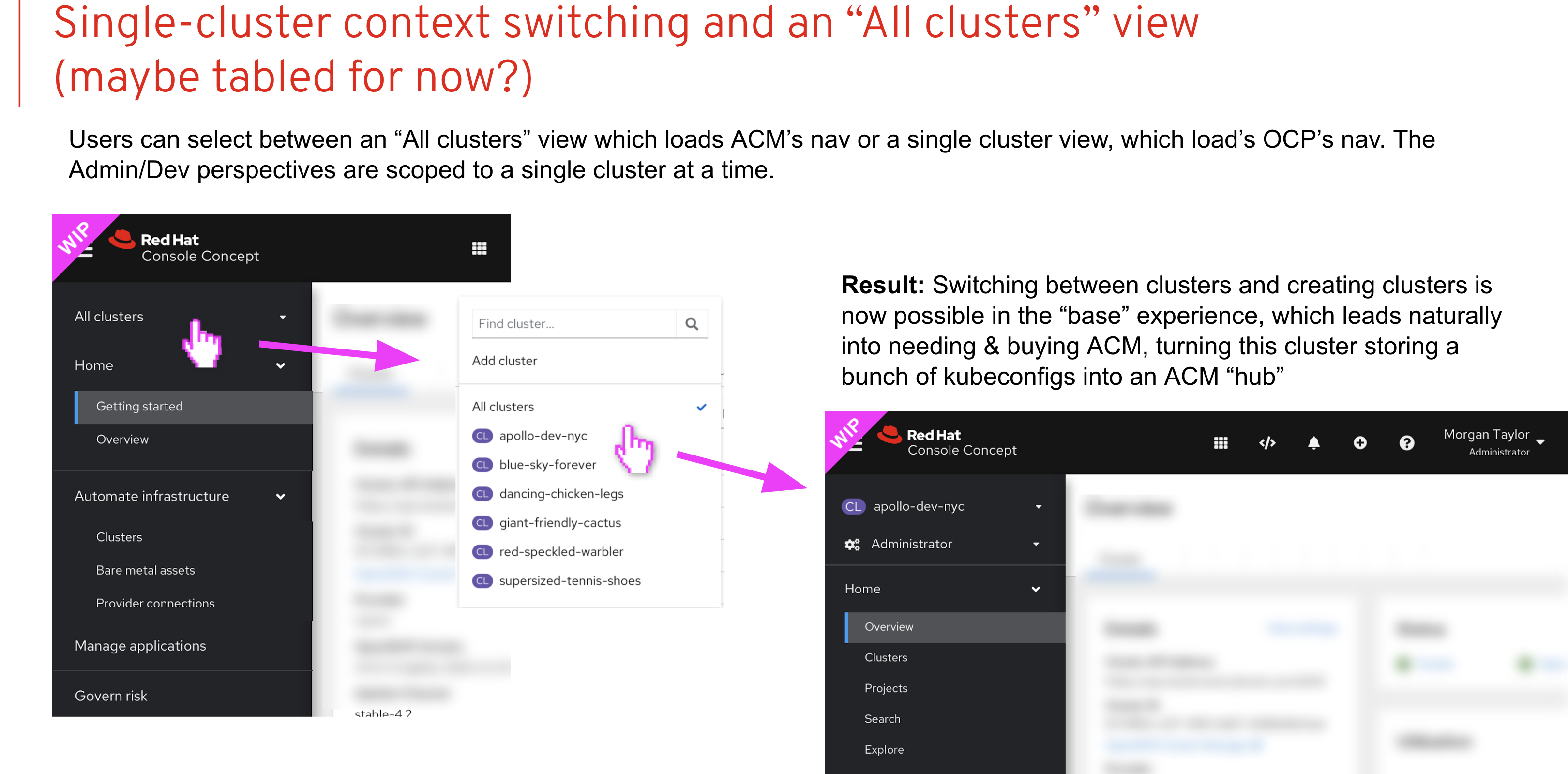
Phase 2 Goal: Productization of the united Console (OCP 4.9, ACM 2.4)
- Enable user to quickly change context from fleet view to single cluster view
- Add Cluster selector with “All Cluster” Option. “All Cluster” = ACM
- Shared SSO across the fleet
- Hub OCP Console can connect to remote clusters API
- When ACM Installed the user starts from the fleet overview aka “All Clusters”
- Share UX between views
- ACM Search —> resource list across fleet -> resource details that are consistent with single cluster details view
- Add Cluster List to OCP —> Create Cluster
Phase 2 Use Cases:
- As a user, I want to be able to quickly switch context from the Fleet view(ACM) to any spoke cluster Console view all from the same web browser tab.
- ACM Hub Operator deployed to OCP—> Cluster picker become available, with “All cluster option”= ACM —> Single cluster user will get perspective picker(Admin, Dev) —> User needs the ability to quickly change context to single cluster —> All clusters should be linked via shared SSO
- As a user, I should be able to drill down into resources in the ACM view and get the OCP resource details page
- ACM Hub Operator deployed to OCP—> User Searches for pods from the ACM view("All clusters")--> Single pod is selected --> OCP pod detail page
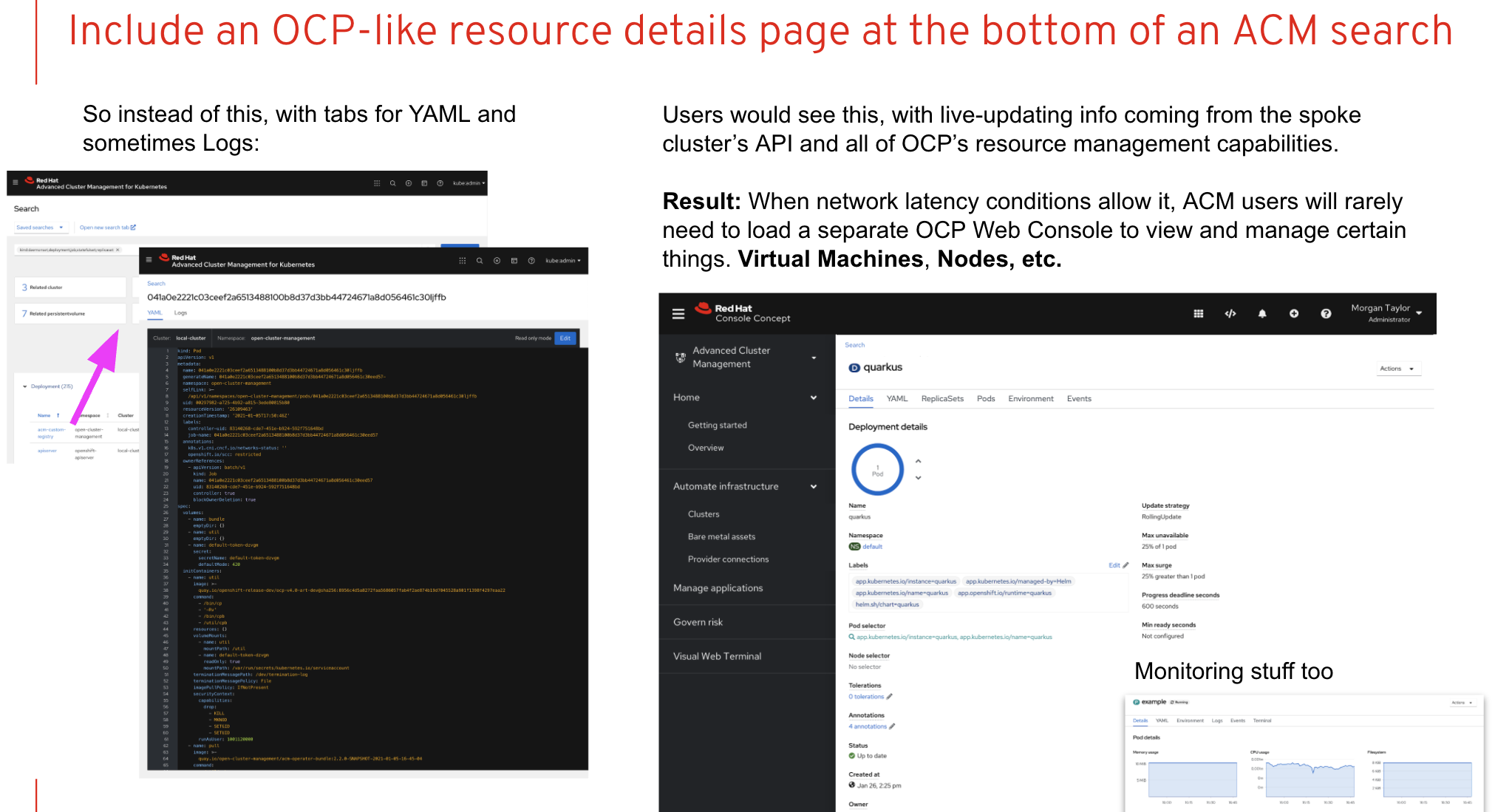
We need to coordinate with the ACM team so that the masthead looks the same when switching between contexts. This might require us to consume a common masthead component in OCP console.
The ACM team will need to honor our custom branding configuration so that the logo does not change when switching contexts.
Known differences:
- Branding customization
- Console link CRDs
- Global notifications
- Import button
- Notification drawer
- Language preferences
- Search link (ACM only)
- Web terminal (ACM only)
Open questions:
- How do we handle alerts in the notification drawer across cluster contexts?
OCP/Telco Definition of Done
Feature Template descriptions and documentation.
Feature Overview
- Connect OpenShift workloads to Google services with Google Workload Identity
Enable customers to access Google services from workloads on OpenShift clusters using Google Workload Identity (aka WIF)
https://cloud.google.com/kubernetes-engine/docs/concepts/workload-identity
Goals
- Customers want to be able to manage and operate OpenShift on Google Cloud Platform with workload identity, much like they do with AWS + STS or Azure + workload identity.
- Customers want to be able to manage and operate operators and customer workloads on top of OCP on GCP with workload identity.
Requirements
- Add support to CCO for the Installation and Upgrade using both UPI and IPI methods with GCP workload identity.
- Support install and upgrades for connected and disconnected/restriction environments.
- Support the use of Operators with GCP workload identity with minimal friction.
- Support for HyperShift and non-HyperShift clusters.
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Epic Goal
- Complete the implementation for GCP workload identity, including support and documentation.
Why is this important?
- Many customers want to follow best security practices for handling credentials.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
Open questions:
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Investigate if this will work for OpenShift components similar to how we implemented STS.
Can we distribute credentials fashion that is transparent to the callers (as to whether it is normal service account of a short lived token) like we did for AWS?
What changes would be required for operators?
Can ccoctl do the heavy lifting as we did for AWS?
Feature Overview
Enable sharing ConfigMap and Secret across namespaces
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| Secrets and ConfigMaps can get shared across namespaces | YES |
Questions to answer…
NA
Out of Scope
NA
Background, and strategic fit
Consumption of RHEL entitlements has been a challenge on OCP 4 since it moved to a cluster-based entitlement model compared to the node-based (RHEL subscription manager) entitlement mode. In order to provide a sufficiently similar experience to OCP 3, the entitlement certificates that are made available on the cluster (OCPBU-93) should be shared across namespaces in order to prevent the need for cluster admin to copy these entitlements in each namespace which leads to additional operational challenges for updating and refreshing them.
Documentation Considerations
Questions to be addressed:
* What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
* Does this feature have doc impact?
* New Content, Updates to existing content, Release Note, or No Doc Impact
* If unsure and no Technical Writer is available, please contact Content Strategy.
* What concepts do customers need to understand to be successful in [action]?
* How do we expect customers will use the feature? For what purpose(s)?
* What reference material might a customer want/need to complete [action]?
* Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
* What is the doc impact (New Content, Updates to existing content, or Release Note)?
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Allow ConfigMaps and Secrets (resources) to be mounted as volumes in a build
Why is this important?
- Secrets and ConfigMaps can be added to builds as "source" code that can leak into the resulting container image
- When using sensitive credentials in a build, accessing secrets as a mounted volume ensure that these credentials are not present in the resulting container image.
Scenarios
- Access private artifact repositories (Artifactory, jFrog, Mavein)
- Download RHEL packages in a build
Acceptance Criteria
- Builds can mount a Secret or ConfigMap in a build
- Content in the secret or ConfigMap are not present in the resulting container image.
Dependencies (internal and external)
- Buildah - support mounting of volumes when building with a Dockerfile
Previous Work (Optional):
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
Reduce the OpenShift platform and associated RH provided components to a single physical core on Intel Sapphire Rapids platform for vDU deployments on SingleNode OpenShift.
Goals
- Reduce CaaS platform compute needs so that it can fit within a single physical core with Hyperthreading enabled. (i.e. 2 CPUs)
- Ensure existing DU Profile components fit within reduced compute budget.
- Ensure existing ZTP, TALM, Observability and ACM functionality is not affected.
- Ensure largest partner vDU can run on Single Core OCP.
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
| Provide a mechanism to tune the platform to use only one physical core. |
Users need to be able to tune different platforms. | YES |
| Allow for full zero touch provisioning of a node with the minimal core budget configuration. | Node provisioned with SNO Far Edge provisioning method - i.e. ZTP via RHACM, using DU Profile. | YES |
| Platform meets all MVP KPIs | YES |
(Optional) Use Cases
- Main success scenario: A telecommunications provider uses ZTP to provision a vDU workload on Single Node OpenShift instance running on an Intel Sapphire Rapids platform. The SNO is managed by an ACM instance and it's lifecycle is managed by TALM.
Questions to answer...
- N/A
Out of Scope
- Core budget reduction on the Remote Worker Node deployment model.
Background, and strategic fit
Assumptions
- The more compute power available for RAN workloads directly translates to the volume of cell coverage that a Far Edge node can support.
- Telecommunications providers want to maximize the cell coverage on Far Edge nodes.
- To provide as much compute power as possible the OpenShift platform must use as little compute power as possible.
- As newer generations of servers are deployed at the Far Edge and the core count increases, no additional cores will be given to the platform for basic operation, all resources will be given to the workloads.
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Administrators must know how to tune their Far Edge nodes to make them as computationally efficient as possible.
- Does this feature have doc impact?
- Possibly, there should be documentation describing how to tune the Far Edge node such that the platform uses as little compute power as possible.
- New Content, Updates to existing content, Release Note, or No Doc Impact
- Probably updates to existing content
- If unsure and no Technical Writer is available, please contact Content Strategy. What concepts do customers need to understand to be successful in [action]?
- Performance Addon Operator, tuned, MCO, Performance Profile Creator
- How do we expect customers will use the feature? For what purpose(s)?
- Customers will use the Performance Profile Creator to tune their Far Edge nodes. They will use RHACM (ZTP) to provision a Far Edge Single-Node OpenShift deployment with the appropriate Performance Profile.
- What reference material might a customer want/need to complete [action]?
- Performance Addon Operator, Performance Profile Creator
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- N/A
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
- Likely updates to existing content / unsure
Goals
- Expose a mechanism to allow the Monitoring stack to be more a "collect and forward" stack instead of a full E2E Monitoring solution.
- Expose a corresponding configuration to allow sending alerts to a remote Alertmanager in case a local Alertmanager is not needed.
- Support proxy environments with also proxy envs.
- The overall goal is to fit all platform components into 1 core (2 HTs, 2 CPUs) for single node openshift deployments. The monitoring stack is one of the largest cpu consumers on single node openshift consuming ~ 200 mc at steady state, primarilty prometheus and the node exporter. This epic would track optimizations to the monitoring stack to reduce this usage as much as possible. Two items to be explored:
- Reducing the scrape interval
- Reducing the number of series to be scraped
Non-Goals
- Switching off all Monitoring components.
- Reducing metrics from any component not owned by the Monitoring team.
Motivation
Currently, OpenShift Monitoring is a full E2E solution for monitoring infrastructure and workloads locally inside a single cluster. It comes with everything that an SRE needs from allowing to configure scraping of metrics to configuring where alerts go.
With deployment models like Single Node OpenShift and/or resource restricted environments, we now face challenges that a lot of the functions are already available centrally or are not necessary due to the nature of a specific cluster (e.g. Far Edge). Therefore, you don't need to deploy components that expose these functions.
Also, Grafana is not FIPS compliant, because it uses PBKDF2 from x/crypto to derive a 32 byte key from a secret and salt, which is then used as the encryption key. Quoting https://bugzilla.redhat.com/show_bug.cgi?id=1931408#c10 "it may be a problem to sell Openshift into govt agencies if
grafana is a required component."
Alternatives
We could make the Monitoring stack as is completely optional and provide a more "agent-like" component. Unfortunately, that would probably take much more time and in the end just reproduce what we already have just with fewer components. It would also not reduce the amount of samples scraped which has the most impact on CPU usage.
Acceptance Criteria
- Verify that all alerts fire against a remote Alertmanager when a user configures that option.
- Verify that Alertmanager is not deployed when a user configures that option in the cluster-monitoring-operator configmap.
- Verify that if you have a local Alertmanager deployed and a user decides to use a remote Alertmanager, the Monitoring stack sends alerts to both destinations.
- Verify that Grafana is not deployed when a user configures that option in the cluster-monitoring-operator configmap.
- Verify that Prometheus fires alerts against an external Alertmanager in proxy environments (1) configure proxy settings inside CMO and (2) cluster-wide proxy settings through ENV.
Risk and Assumptions
Documentation Considerations
- Any additions to our ConfigMap API and their possible values.
Open Questions
If we set a URL for a remote Alertmanager, how are we handle authentication?- Configuration of remote Alertmanagers would support whatever Prometheus supports (basic auth, client TLS auth and bearer token)
Additional Notes
Use cases like single-node deployments (e.g. far-edge) don't need to deploy a local Alertmanager cluster because alerts are centralized at the core (e.g. hub cluster), running Alertmanager locally takes resources from user workloads and adds management overhead. Cluster admins should be able to not deploy Alertmanager as a day-2 operation.
DoD
- Alertmanager isn't deployed when switched off in the CMO configmap.
- The OCP console handles the situation gracefully when Alertmanager isn't installed informing users that it can't manage the local Alertmanager configuration and resources.
- Silences page
- Alertmanager config editor